ChatGPT 火了。
整个 LLM 和搜索领域都已经在过去几个月内发生了翻天覆地的变化。ChatGPT 不再是一个玩具,它开始被微软、谷歌集成在搜索以及各个 SaaS 服务中,且取得了令人惊叹的效果。
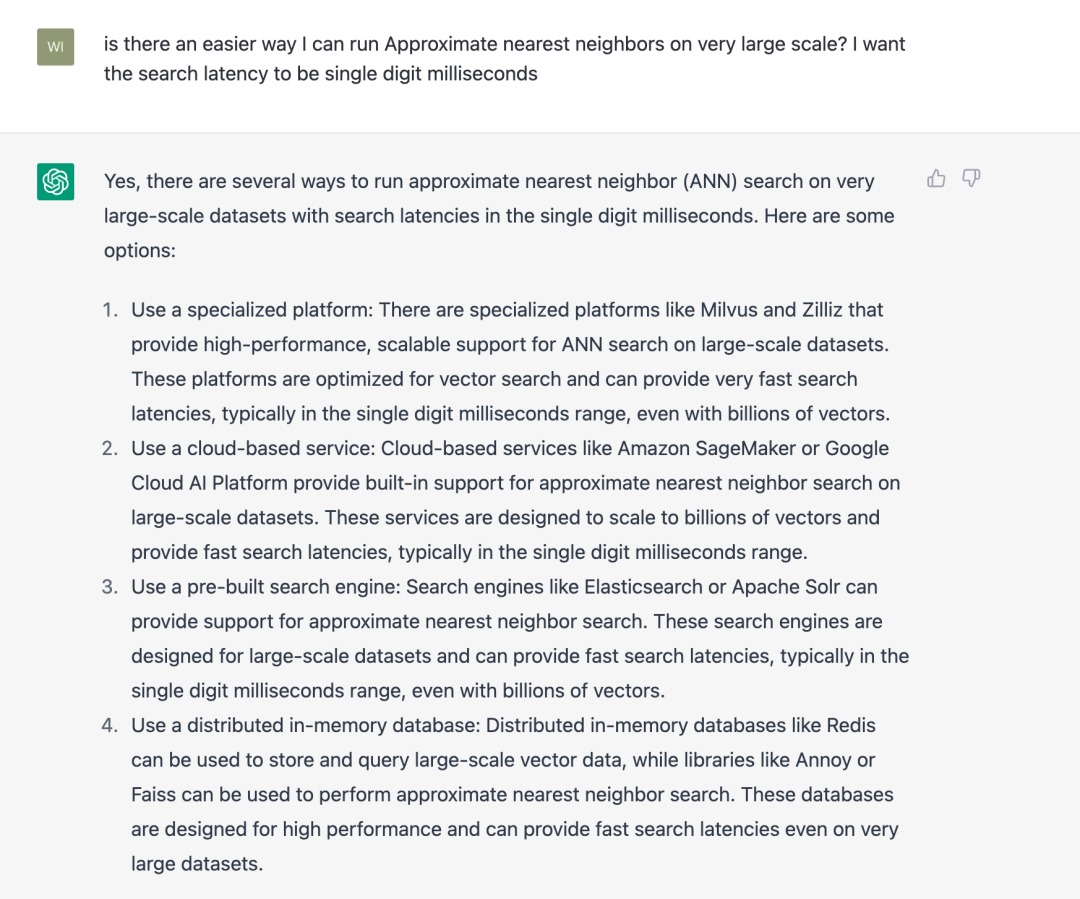
我尝试着使用 ChatGPT 回答过去一个月搜索过的 30 个问题,ChatGPT 提供的结果大概有 60% 在体感上优于 Google Search。当我询问“如何从十亿规模的向量数据找到最详细的结果”时,Google 给出的回答是一些向量检索库和向量数据库的软文链接,而 ChatGPT 则秀出了一段相当惊艳的回答:

你甚至可以追问“有没有更加便捷的向量检索方式”, 其回答也保持了相当的水平。但很显然,ChatGPT 认为 Milvus 和 Zilliz 都是一种自定义的 Platform,因此,我们还需要给它更多的语料进行训练。
在热闹气氛的渲染下,有关 ChatGPT 即将替代 NLP、替代搜索领域、替代各种内容生成岗位的言论甚嚣尘上,就连从不关心技术的亲戚朋友也会在茶余饭后聊上几句。
对此,我的观点是:
ChatGPT 是工程的巨大成功,但不是黑魔法,ChatGPT is not all you need。
搜索领域在 ChatGPT 的加持下会发生很大的变化,但传统搜索技术不会完全被其取代,最底层的逻辑是 ChatGPT 的信息密度不够,需要通过搜索技术补充信息。
搜索的商业模式将会发生巨大变化,如果用户更喜欢问答式的交互方式,基于 page rank 和竞价排名的搜索引擎付费模式将会受到巨大冲击。
01.
为什么 ChatGPT 不是黑魔法?
要搞清楚的 ChatGPT 的原理,要先从 NLP 的四次范式转移开始讲起。先看看 ChatGPT 是如何定义 NLP 的四个范式的:
First paradigm: Fully supervised learning in the pre-neural network era (feature engineering). The first paradigm refers to the processing methods in the NLP field before the introduction of neural networks. In this paradigm, specific features are extracted from natural language corpora, and rules or mathematical/statistical models are used to match and utilize these features to complete specific NLP tasks. Common methods include Bayesian, Viterbi algorithm, Hidden Markov Model, etc., for sequence classification, sequence labeling, and other tasks.
Second paradigm: Fully supervised learning based on neural networks (architecture engineering). The second paradigm refers to the research methods in the NLP field after the introduction of neural networks and before the emergence of pre-trained models. In this paradigm, there is no need to manually set features and rules, saving a lot of manpower, but a suitable neural network architecture still needs to be designed to train the dataset. Common methods include CNN, RNN, and Seq2Seq model in machine translation, etc.
Third paradigm: Pre-training and fine-tuning paradigm (objective engineering). The third paradigm refers to the method of pre-training on large unsupervised datasets to learn some general grammatical and semantic features, and then using the pre-trained model for fine-tuning on downstream tasks. Models such as GPT, Bert, and XLNet belong to the third paradigm. The feature of the third paradigm is that it does not require a large amount of downstream task data, and the model is mainly trained on large unsupervised data. Only a small amount of downstream task data is needed to fine-tune a small number of network layers.
Fourth paradigm: Pre-training, prompt, and prediction paradigm (prompt engineering). The fourth paradigm refers to the use of prompts to guide the model to make specific task predictions, based on the third paradigm. This method requires adding additional modules or layers to the pre-trained model to process prompts, and fine-tuning on downstream task-specific datasets. This method can use human expert knowledge to guide the model and improve the performance on specific tasks. The latest NLP models such as GPT-3 and Turing-NLG belong to this paradigm. They can generate human-level natural language text and perform well on specific tasks such as QA, text summarization, and dialogue generation.
简单理解,第一范式是非神经网络时代的特征提取,这一时代通常是用数据的统计信息来解决某一个具体问题。
第二范式开始引入神经网络,通过 CNN、RNN 等模型来对特定的数据集进行训练,这一范式显著降低了人力成本。
第三范式作为广为人知的预训练 + FineTune 模式,GPT、 Bert 和 XLNet 都是其中的典型代表。第三范式基于大量的语料做无监督训练,学习通用的语法知识,因此,只需要 few shot 就可以在对应的任务中取得不错的结果。
第四范式,也就是预训练 + Prompt 的范式,这种能力建立在 GPT3 等大模型非常丰富的训练语料和知识体系。使用 Prompt 是为了让任务跟预训练模型更加贴近,这和Fine tuning 的本质并无不同,但带来的好处是模型训练所需要的数据明显减少,通常情况下 one shot 就可以获得很好的效果。
为什么会进入到第四范式?我自己理解有两个主要的原因:
其一,模型的性能并非随着大小线性而增长,当其增长到一定规模后,会出现突变能力,使得性能急剧增加。此时精调小模型带来的收益不如直接训练大模型来的直接。
其二,精调范式的泛化能力较弱,prompt 使得 AI as a Service 真正变成了可能。
在 NLP 第四范式大模型的基础上,我们才开始正式讨论今天的主角—— ChatGPT。在我看来,ChatGPT 并没有引入突破性的区别,其核心解决的问题是通过强化学习的方式将把人的喜好反馈给了模型,也就是传说中的RLHF(Reinforcement Learning from Human Feedback)。
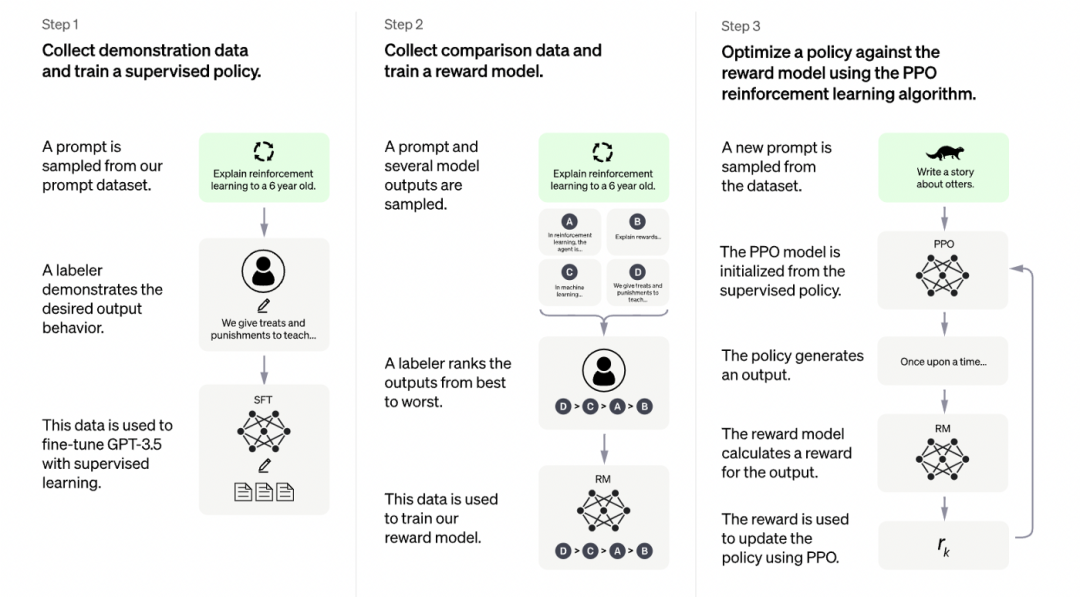
简单理解,ChatGPT 的训练分成了三步:
第一步冷启动,随机抽取 prompt 并由标注人员提供高质量的答案;
第二步,根据第一阶段训练出来的模型生成多个答案,由标注人员进行排序,然后再用排序训练回报模型;
第三步,使用强化学习来增强模型能力,随机抽取新的 prompt,生成答案,然后基于回报模型生成反馈。通过这个过程,预训练模型的能力会不断增强。
听起来 ChatGPT 的原理并没有那么复杂,只要稍微了解 AI 基本原理的同学都可以理解,这也就 ChatGPT 并非“黑魔法”的意思。
然而,迄今为止,ChatGPT 的开源竞品远远达不到对应能力,这里既有 GPT3 本身的原因,同时可以归结于 OpenAI 优秀的数据质量和“钞能力”带来的超过 40 人的高质量标注团队。
事实上,Google 的 PaLM 具备了跟 ChatGPT 非常相近的能力,这意味着 ChatGPT 并非是不可复现的。相信与 ChatGPT 效果近似的开源大模型一定会出现,并且达到跟 ChatGPT 非常相似的能力效果。
不过,我更关注另一件事情,即大模型是否最终能在开发环境下很好的跑起来。只有具备这种能力,围绕 LLM 的学术和创业生态才能更加丰富。FlexGen 是我最近关注到的一个项目,它已经成功将 175B 参数的 OPT 模型在单卡环境上面跑起来了,相信在不久的将来就能看到可以在 Mac 笔记本上运行的超大规模模型。
02.
Generative Search,搜索的新形态
聊了那么多 ChatGPT,让我们回归主题分析下大模型对搜索领域带来的巨大影响。这里我先旗帜鲜明地抛出观点:ChatGPT无法彻底取代搜索引擎,尤其是特定领域的企业级搜索。
第一,尽管 ChatGPT 是大模型,但它的数据量并不足以支撑记录人类有史以来出现的全部信息(大概在 ZB 级别),这一数据量超过 ChatGPT 模型大小几个数量级。熟悉压缩算法的朋友一定知道,有损压缩过的 JPEG 图片看起来跟原始图片看起来没有什么区别,这种微妙的压缩方式在绝对精度不是必须的情况下具备很好的效果,但在某些情况下会造成误导和信息丢失,比如,下图中压缩过的图片中我们已经很难看出原图中背景中的那些枝叶。

ChatGPT 集合了网络上所有的文本信息,像是一个混杂大量模糊图片的视频集合。当你跟 ChatGPT 对话的时候,就像是在快进这个视频。尽管能够看到大量似是而非的回答,但并能不保证的所有的回答是完整精确的。
事实上 ChatGPT 真正令人惊讶的是他的推理能力,尤其是引入思维链和其他详细推理的方式之后,ChatGPT 甚至可以拆解并解决一些复杂的数学问题。而传统搜索很大程度上弥补了 ChatGPT 的记忆能力,其中既包括更多的历史细节数据,也包括了实时数据。众所周知,ChatGPT 只了解 2021 年以前的数据,将搜索结果 + prompt 提供给 ChatGPT 可以补全细节,让 ChatGPT 的回答更加准确。
第二,搜索系统并非只针对单目标的优化,相关性、CTR、多样性、新颖性都是重要的衡量指标,不同任务之间通常要在特定的架构和学习目标下建模,这也导致搜索能力很难泛化。在 ChatGPT 流行之后,开始出现 NLP+ 推荐的相关研究,利用不同 prompt 来进行各种各样的推荐任务,但其核心仍然利用自然语言的描述能力和大模型的推理能力来寻找相关性实现“千人千面”。一旦要加入新的评价指标,我们就需要重新标注数据定义新的 Reward model,而非简单的通过 Prompt Engineering 来找到符合条件的结果。
新颖性也是 ChatGPT 目前还不适用于搜索系统的重要原因,搜广推系统中每天都在发生中模型训练部署上线,索引重新构建的行为,实时性要求越来越高。对于 ChatGPT 这样的超大模型而言,频繁 finetune 来增加新知识很容易导致模型跑飞的情况,充满了挑战和不可控因素。
第三,性能和成本是 ChatGPT 无法替代检索的重要瓶颈,这也是目前 Google 在LLM 应用领域落后于 OpenAI 的关键因素。
抛开成本不谈,大模型对于处理百级别 token 的耗时超过 2 秒,这显然大大超过了很多用户的忍耐范围。想要获得良好的搜索效果,必须给出 ChatGPT 完整有效的 prompt,而这会进一步增大耗时。因此,现在这个阶段 LLM 只能在非时间敏感的系统使用,这也是 Google 为什么选择优化模型更小的 Bard 而不是效果更好的 PaLM 的根本原因。但我相信,随着算力的发展以及对模型的持续优化,大模型和搜索的融合会逐渐成为趋势。
第四,也就是公正性和客观性。搜索作为一个工具,需要提供更加客观的事实,而目前很难证明 ChatGPT 的观点是公正中立的。事实上,稍微花点精力绕过 ChatGPT 表面的限制,就能发现 ChatGPT 的回答在某些问题上是有明显的倾向性。基于 ChatGPT 生成的数据去训练 ChatGPT,是否会导致这一倾向性变得更加严重?
那么这些问题该如何解决?我的答案是 Generative Search,中文翻译过来是生成式检索。生成式检索的主要范式是加载数据、索引预构建、查询语句分析、索引查询、结果生成。

大模型在这套系统中主要承担两个责任:1)交互式工具调用 2)结果归纳、精排。
先聊聊第一个功能,通过 prompt 工程,应该可以引导 ChatGPT 写出调用其他搜索或者工具的代码,Tool Transformer 这篇论文具体介绍了如何将 GPT-J fine tune 成一个可以自己调用 Wikipedia 或者 Calculator 的模型。以 Calculator 举例,我们只需要使用以下 prompt 就可以让 ChatGPT 自己调用计算器:

这种能力意味着搜索的交互模式发生了巨大改变,用户只要描述自己要执行的任务,ChatGPT 便可以借助代码、向量检索、关键词检索等多种方式去寻找数据。
基于关键词检索和向量检索,ChatGPT 可以获得大量事实数据,这些数据的正确性和实时性更加有保证。同时,我们通过增加 Reward 模型的目标来提升 ChatGPT 在输出丰富性、有害性、热度等概念的判断能力,而不仅仅在输出只关注相关性目标的结果。
由于 ChatGPT 的性能对于输入 token 数目高度敏感,这里衍生了新的挑战,即如何从原始材料中提取出足够精炼的信息和上下文交给 ChatGPT 进行最终的结果生成。一种显而易见的方式是多次调用 LLM 进行信息提取、分层、过滤、模型蒸馏、量化等,这些常见手段应该都有助于提升搜索的性能。
基于这一架构的生成式检索,不仅解决了数据的实效性问题和可信度问题,更重要的是可以回答某一具体业务的相关问题。这一架构也可以应用于图片、视频、音频、生物分子式、时序等多模态数据,成为搜索领域大一统的事实标准。
03.
搜索领域商业模式的转换
搜索领域的商业模式,也需要在技术创新和用户体验之间寻找平衡点。
ChatGPT 的出现为搜索带来了全新的用户体验和技术手段,但也带来了商业模式的转换。ChatGPT 在很大程度上改变了搜索用户的使用习惯,用户不再愿意点击链接,而点击链接正是 Google 获取营收的根本。
另一端,竞价排名模型下广告主花了大量的费用保证自己的产品出现在搜索结果的前端,而 ChatGPT 带用户全新的使用体验,不再需要从数以百计的链接中找到自己想要的信息,大模型会帮你整理归纳并提炼出需要的信息点。因此,如何将广告信息有机地融入到搜索结果中,并为广告主提供更精准的投放效果评估,仍是一个亟待解决的问题。
ChatGPT 对于搜索的另一个变化就是入口的改变。为了占据苹果设备搜索入口,Google 每年要花费超过一百亿美金,而随着 ChatGPT 的出现,搜索入口将会变得多元化,不再局限于浏览器,而是分散在各个应用、语音助手、甚至于机器人身上。借助大模型让构建高质量的私域检索成为可能,搜索未来很可能从直接面向用户的入口转为 ToB 侧的 Infra 基础服务。
在这个过程中,技术创新是推动商业模式转换的关键。遥想当年 Google 颠覆 yahoo 黄页,带来了技术上的破坏性创新,其核心在于人力维护信息的黄页成本跟不上数据产生的速度。在这个过程中,Google 大量高效率的基础设施(MapReduce、GFS、Spanner、TensorFlow、Kubernetes)起到了加速作用,最终从迭代速度上战胜了内容为王的 yahoo。今天,大模型技术的发展需要全方位的技术创新,从基础设施、算法、模型训练、部署等方面来看,都存在很大的机会。
04.
大模型 + 搜索引擎,ChatGPT 你怎么看?
当我们把本文讨论的问题抛给 ChatGPT,答案非常具备参考意义。

ChatGPT 可以在查询理解、结果排名、个性化搜索方面帮助传统检索。更为重要的是,传统搜索基于关键词和短语,表达能力比较弱,自然语言的引入可允许用户跟进问题、澄清查询,这将会使得整个搜索的使用体验更加直观和高效。
这种使用体验的提升,意味着 ChatGPT 以及背后的大模型和生成式 AI,可能成为未来颠覆许多行业的系统性机会。这种冲击一定会在接下来的一段时间内慢慢发酵,孵化出大量 AI as a Service 的基础设施公司和基于 AI 构建应用的创业公司。
至少从目前看,搜索技术还不会退出历史的舞台,但它究竟会向着何种方向演进?让我们拭目以待。
参考文献:
https://www.newyorker.com/tech/annals-of-technology/chatgpt-is-a-blurry-jpeg-of-the-web
https://arxiv.org/abs/2203.13366
https://arxiv.org/pdf/2302.04761.pdf
https://www.semianalysis.com/p/the-inference-cost-of-search-disruption
https://bdtechtalks.com/2023/01/16/what-is-rlhf/
https://zhuanlan.zhihu.com/p/589533490


![【项目设计】高并发内存池 (四)[pagecache实现]](https://img-blog.csdnimg.cn/ca656d66a1484fd89961465b5276ba34.png)