本文目录
1. 基础概念
1.1. 缺失值分类
1.2. 缺失值处理方法
2. 缺失观测及其类型
2.1. 了解缺失信息
2.2. 三种缺失符号
2.3. Nullable类型与NA符号
2.4. NA的特性
2.5. convert_dtypes方法
3. 缺失数据的运算与分组
3.1. 加号与乘号规则
3.2. groupby方法中的缺失值
4. 填充与剔除
4.1. fillna方法
4.2. dropna方法
5. 插值
5.1. 线性插值
5.2. 高级插值方法
5.3. interpolate中的限制参数
基础概念
1.1缺失值的分类
按照数据缺失机制可分为:
可忽略的缺失
完全随机缺失(missing completely at random, MCAR),所缺失的数据发生的概率既与已观察到的数据无关,也与未观察到的数据无关
随机缺失(missing at random, MAR),假设缺失数据发生的概率与所观察到的变量是有关的,而与未观察到的数据的特征是无关的。
不可忽略的缺失(non-ignorable missing ,NIM) 或非随机缺失(not missing at random, NMAR, or, missing not at random, MNAR),如果不完全变量中数据的缺失既依赖于完全变量又依赖于不完全变量本身,这种缺失即为不可忽略的缺失。
【注意】:Panda读取的数值型数据,缺失数据显示“NaN”(not a number)。
1.2数据值的处理方法
主要就是两种方法:
删除存在缺失值的个案;
缺失值插补。
【注意】缺失值的插补只能用于客观数据。由于主观数据受人的影响,其所涉及的真实值不能保证。
1、删除含有缺失值的个案(2种方法)
(1)简单删除法
简单删除法是对缺失值进行处理的最原始方法。它将存在缺失值的个案删除。如果数据缺失问题可以通过简单的删除小部分样本来达到目标,那么这个方法是最有效的。
(2)权重法
当缺失值的类型为非完全随机缺失的时候,可以通过对完整的数据加权来减小偏差。把数据不完全的个案标记后,将完整的数据个案赋予不同的权重,个案的权重可以通过logistic或probit回归求得。
如果解释变量中存在对权重估计起决定行因素的变量,那么这种方法可以有效减小偏差。如果解释变量和权重并不相关,它并不能减小偏差。
对于存在多个属性缺失的情况,就需要对不同属性的缺失组合赋不同的权重,这将大大增加计算的难度,降低预测的准确性,这时权重法并不理想。
2、可能值插补缺失值
【思想来源】:以最可能的值来插补缺失值比全部删除不完全样本所产生的信息丢失要少。
(1)均值插补
属于单值插补。数据的属性分为定距型和非定距型。如果缺失值是定距型的,就以该属性存在值的平均值来插补缺失的值;如果缺失值是非定距型的,就用该属性的众数来补齐缺失的值。
(2)利用同类均值插补
属于单值插补。用层次聚类模型预测缺失变量的类型,再以该类型的均值插补。
假设为信息完全的变量,为存在缺失值的变量,那么首先对或其子集行聚类,然后按缺失个案所属类来插补不同类的均值。
如果在以后统计分析中还需以引入的解释变量和做分析,那么这种插补方法将在模型中引入自相关,给分析造成障碍。
(3)极大似然估计(Max Likelihood ,ML)
在缺失类型为随机缺失的条件下,假设模型对于完整的样本是正确的,那么通过观测数据的边际分布可以对未知参数进行极大似然估计(Little and Rubin)。
这种方法也被称为忽略缺失值的极大似然估计,对于极大似然的参数估计实际中常采用的计算方法是期望值最大化(Expectation Maximization,EM)。
该方法比删除个案和单值插补更有吸引力,前提是适用于大样本,有效样本的数量足够以保证ML估计值是渐近无偏的并服从正态分布。这种方法可能会陷入局部极值,收敛速度也不是很快,并且计算很复杂。
(4)多重插补(Multiple Imputation,MI)
多值插补的思想来源于贝叶斯估计,认为待插补的值是随机的,它的值来自于已观测到的值。具体实践上通常是估计出待插补的值,然后再加上不同的噪声,形成多组可选插补值。根据某种选择依据,选取最合适的插补值。
多重插补方法的三个步骤:
为每个空值产生一套可能的插补值,这些值反映了无响应模型的不确定性;每个值都可以被用来插补数据集中的缺失值,产生若干个完整数据集合。
每个插补数据集合都用针对完整数据集的统计方法进行统计分析。
对来自各个插补数据集的结果,根据评分函数进行选择,产生最终的插补值。
多重插补方法举例:
假设一组数据,包括三个变量 ,它们的联合分布为正态分布,将这组数据处理成三组,A组保持原始数据,B组仅缺失
,它们的联合分布为正态分布,将这组数据处理成三组,A组保持原始数据,B组仅缺失 ,C组缺失
,C组缺失 和
和 。在多值插补时,对A组将不进行任何处理,对B组产生的一组估计值(作关于,的回归),对C组作和产生和的一组成对估计值(作,关于的回归)。
。在多值插补时,对A组将不进行任何处理,对B组产生的一组估计值(作关于,的回归),对C组作和产生和的一组成对估计值(作,关于的回归)。
当用多值插补时,对A组将不进行处理,对B、C组将完整的样本随机抽取形成为m组(m为可选择的m组插补值),每组个案数只要能够有效估计参数就可以了。对存在缺失值的属性的分布作出估计,然后基于这m组观测值,对于这m组样本分别产生关于参数的m组估计值,给出相应的预测即,这时采用的估计方法为极大似然法,在计算机中具体的实现算法为期望最大化法(EM)。对B组估计出一组的值,对C将利用 它们的联合分布为正态分布这一前提,估计出一组(,)。
上例中假定了的联合分布为正态分布。这个假设是人为的,但是已经通过验证(Graham和Schafer于1999),非正态联合分布的变量,在这个假定下仍然可以估计到很接近真实值的结果。
多重插补弥补贝叶斯估计的不足之处:
贝叶斯估计以极大似然的方法估计,极大似然的方法要求模型的形式必须准确,如果参数形式不正确,将得到错误得结论,即先验分布将影响后验分布的准确性。而多重插补所依据的是大样本渐近完整的数据的理论,在数据挖掘中的数据量都很大,先验分布将极小的影响结果,所以先验分布的对结果的影响不大。
贝叶斯估计仅要求知道未知参数的先验分布,没有利用与参数的关系。而多重插补对参数的联合分布作出了估计,利用了参数间的相互关系。
缺失观测及其类型
首先导入数据:
import pandas as pd
import numpy as np
df = pd.read_csv('data/table_missing.csv')
df.head()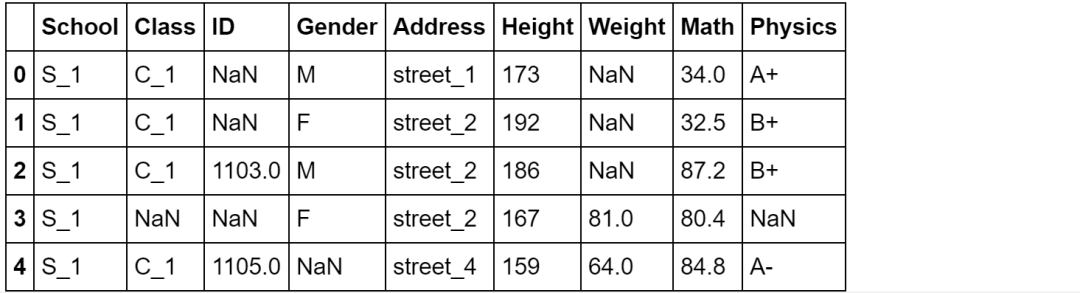
2.1了解缺失信息
1、isna和notna方法
对Series使用会返回布尔列表
df['Physics'].isna().head()
df['Physics'].notna().head()
对DataFrame使用会返回布尔表
df.isna().head()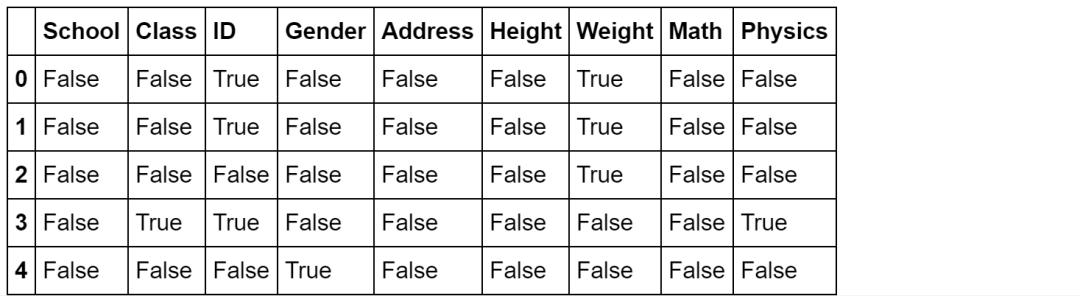
但对于DataFrame我们更关心到底每列有多少缺失值
df.isna().sum()
此外,可以通过第1章中介绍的info函数查看缺失信息
df.info()
2、查看缺失值的所以在行
以最后一列为例,挑出该列缺失值的行
df[df['Physics'].isna()]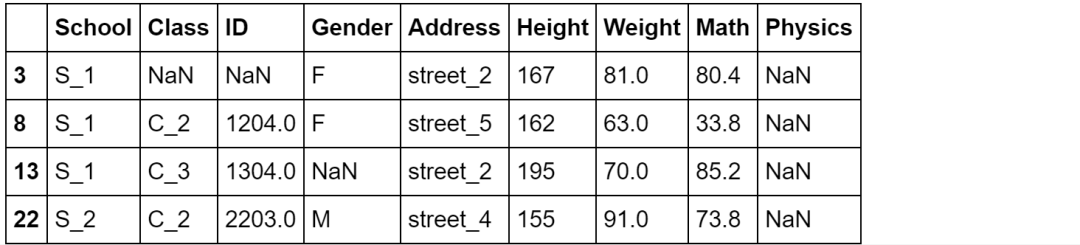
3、挑选出所有非缺失值列
使用all就是全部非缺失值,如果是any就是至少有一个不是缺失值
df[df.notna().all(1)]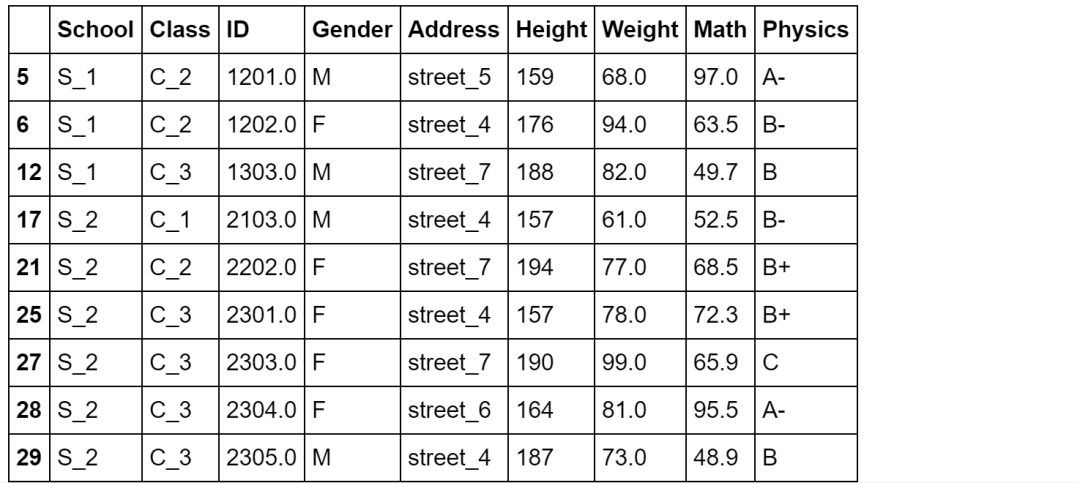
缺失数据的运算与分组
加号与乘号规则
使用加法时,缺失值为0
s = pd.Series([2,3,np.nan,4])s.sum()9.0
使用乘法时,缺失值为1
s.prod()24.0
使用累计函数时,缺失值自动略过
s.cumsum()
s.cumprod()
s.pct_change()
groupby方法中的缺失值
自动忽略为缺失值的组
df_g = pd.DataFrame({'one':['A','B','C','D',np.nan],'two':np.random.randn(5)})df_g
df_g.groupby('one').groups
填充与剔除
4.1 fillna方法
1、值填充与前后向填充(分别与ffill方法和bfill方法等价)
df['Physics'].fillna('missing').head()
df['Physics'].fillna(method='ffill').head()
df['Physics'].fillna(method='backfill').head()
2、填充中的对齐特性
df_f = pd.DataFrame({'A':[1,3,np.nan],'B':[2,4,np.nan],'C':[3,5,np.nan]})df_f.fillna(df_f.mean())
返回的结果中没有C,根据对齐特点不会被填充
df_f.fillna(df_f.mean()[['A','B']])
4.2 dropna方法
1、axis参数
df_d = pd.DataFrame({'A':[np.nan,np.nan,np.nan],'B':[np.nan,3,2],'C':[3,2,1]})df_d
df_d.dropna(axis=0)
df_d.dropna(axis=1)
2、how参数(可以选all或者any,表示全为缺失去除和存在缺失去除)
df_d.dropna(axis=1,how='all')
3、subset参数(即在某一组列范围中搜索缺失值)¶
df_d.dropna(axis=0,subset=['B','C'])
插值
5.1线性插值
1、索引无关的线性插值
默认状态下,interpolate会对缺失的值进行线性插值
s = pd.Series([1,10,15,-5,-2,np.nan,np.nan,28])s
s.interpolate()
s.interpolate().plot()<matplotlib.axes._subplots.AxesSubplot at 0x7fe7df20af50>

此时的插值与索引无关
s.index = np.sort(np.random.randint(50,300,8))s.interpolate()#值不变
s.interpolate().plot()#后面三个点不是线性的(如果几乎为线性函数,请重新运行上面的一个代码块,这是随机性导致的)<matplotlib.axes._subplots.AxesSubplot at 0x7fe7dfc69890>

2、与索引有关的插值
method中的index和time选项可以使插值线性地依赖索引,即插值为索引的线性函数
s.interpolate(method='index').plot()#可以看到与上面的区别<matplotlib.axes._subplots.AxesSubplot at 0x7fe7dca0c4d0>

如果索引是时间,那么可以按照时间长短插值,对于时间序列将在第9章详细介绍
s_t = pd.Series([0,np.nan,10] ,index=[pd.Timestamp('2012-05-01'),pd.Timestamp('2012-05-07'),pd.Timestamp('2012-06-03')])s_t
s_t.interpolate().plot()<matplotlib.axes._subplots.AxesSubplot at 0x7fe7dc964850>
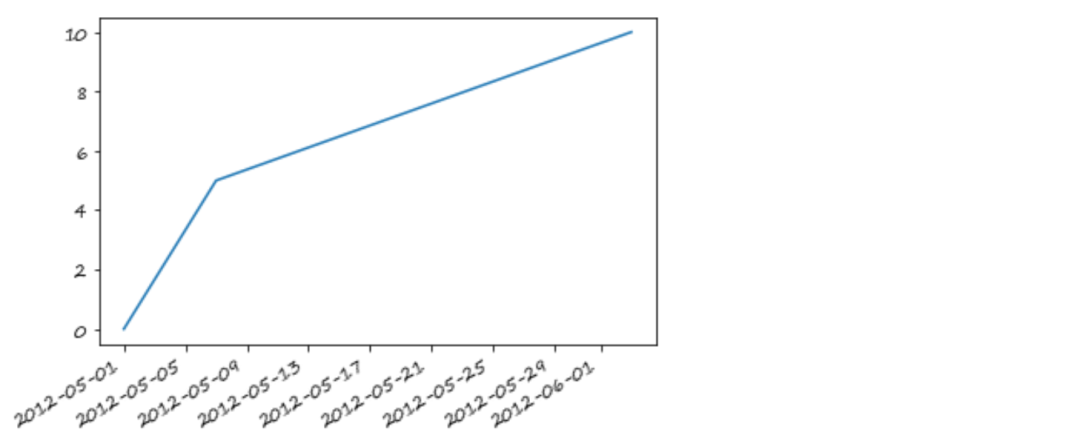
s_t.interpolate(method='time').plot()<matplotlib.axes._subplots.AxesSubplot at 0x7fe7dc8eda10>

5.2 高级插值方法
此处的高级指的是与线性插值相比较,例如样条插值、多项式插值、阿基玛插值等(需要安装Scipy)。
关于这部分仅给出一个官方的例子,因为插值方法是数值分析的内容,而不是Pandas中的基本知识:
ser = pd.Series(np.arange(1, 10.1, .25) ** 2 + np.random.randn(37))missing = np.array([4, 13, 14, 15, 16, 17, 18, 20, 29])ser[missing] = np.nanmethods = ['linear', 'quadratic', 'cubic']df = pd.DataFrame({m: ser.interpolate(method=m) for m in methods})df.plot()<matplotlib.axes._subplots.AxesSubplot at 0x7fe7dc86f810>
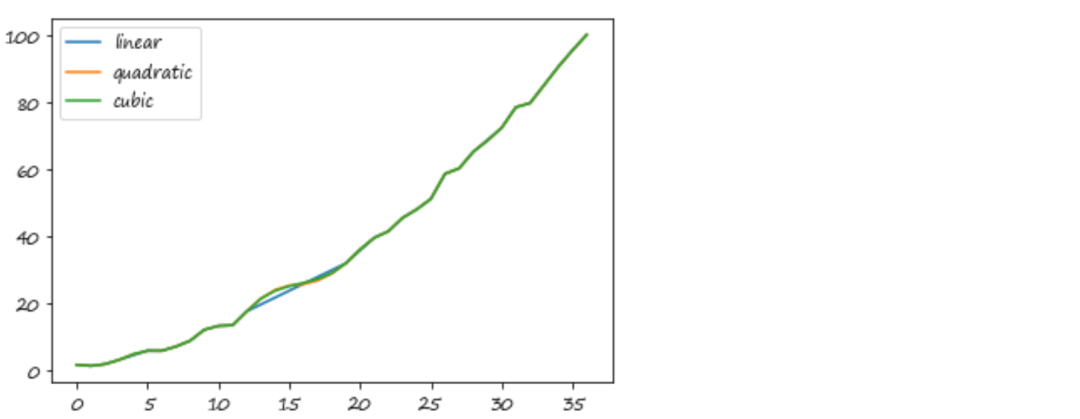
5.3 interpolate中的限制参数
1、limit表示最多插入多少个
s = pd.Series([1,np.nan,np.nan,np.nan,5])s.interpolate(limit=2)
2、limit_direction表示插值方向,可选forward,backward,both,默认前向。
s = pd.Series([np.nan,np.nan,1,np.nan,np.nan,np.nan,5,np.nan,np.nan,])s.interpolate(limit_direction='backward')
3、limit_area表示插值区域,可选inside,outside,默认None
s = pd.Series([np.nan,np.nan,1,np.nan,np.nan,np.nan,5,np.nan,np.nan,])s.interpolate(limit_area='inside')
s = pd.Series([np.nan,np.nan,1,np.nan,np.nan,np.nan,5,np.nan,np.nan,])s.interpolate(limit_area='outside')
声明:部分内容来源于网络,仅供读者学术交流之目的。文章版权归原作者所有。如有不妥,请联系删除。