1.摘要
WebRTC是一个开源的实时交互式音频和视频通信框架。本文讨论了WebRTC中用于处理视频通信路径中数据包丢失的一些机制。讨论了各种系统细节,提出了一种基于时间层的自适应混合NACK/FEC方法。结果显示了该方法如何控制实时视频通信的质量权衡
2.介绍
WebRTC[1]是一个开源项目,它使web浏览器能够进行实时音频和视频通信。
本文介绍了一些底层的视频处理方面的WebRTC,使可靠的实时视频传输在有损网络中成为现实。众所周知,为交互式实时应用(如视频会议)提供高用户体验是很困难的。这些应用受到突变的网络条件(带宽、丢包、网络延迟)和低延迟实时编码要求的限制。
存在各种方法[2]处理多媒体传输期间的分组丢失,例如基于否定确认(NACK),前向纠错(FEC)[3] [4]和参考图片选择(RPS)[5]的分组重传。 。 这些通常通过编解码器的错误恢复方法[2]进行补充,例如内部刷新和错误隐藏。 对于具有严格延迟要求的实时应用,可以使用混合NACK / FEC方案[6]来实现NACK方法的延迟成本和FEC方法的冗余成本之间的某种平衡。
本文介绍了WebRTC中当前用于处理数据包丢失的一组保护工具。 尤其是,提出了一种具有时间层(TL)的自适应混合NACK / FEC方法,作为一种平衡视频质量,渲染平滑度(播放抖动)和端到端延迟的有用方案。 TL指WebRTC中使用的VP8 [7]编解码器中的时间可伸缩性功能。 还讨论了各种系统细节和组件,以突出我们方法的适应性。
WebRTC中视频处理的系统描述将在第2节中讨论。第3节讨论用于量化系统行为的仿真和度量。 3.1-3.3节包含有关混合NACK / FEC,FEC和TL的一些结果和讨论。 结论见第4节。
3.系统描述
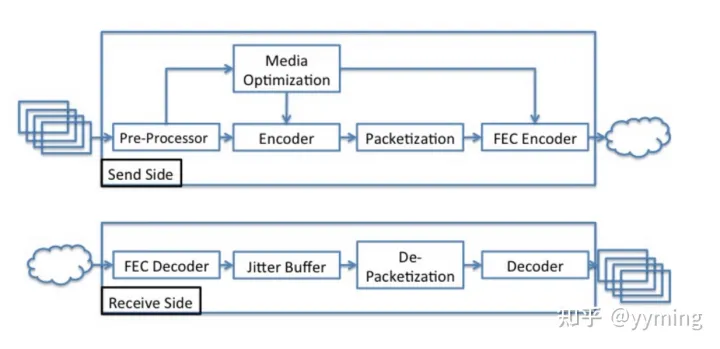
图1: webrtc 系统描述
图1显示了WebRTC视频处理系统图。 进入发送端的原始帧首先经过预处理,然后以给定的目标速率进行编码。 随后,将帧打包,并且在适用时应用FEC编码器。 FEC是基于RFC 5109 [8]的XOR代码。 在接收器端,打包的编码数据由FEC解码器处理,然后由抖动缓冲器(JB)处理。 后者根据接收到的数据包构造编码帧,并估计视频抖动。 帧完成后,将其发送到解码器,由解码器输出原始数据(YUV格式)。 JB还负责构建作为重新传输请求基础的丢失数据包列表。
我们将抖动建模为包括两个分量,一个是随机分量,另一个是相对于视频帧大小的分量[9]。 然后,我们收集帧捕获时间和帧的接收时间的每帧统计信息,并将其建模为线性依赖于帧大小的差异。 这种估算抖动的方法可以适应帧大小和链接容量的变化,而这通常会影响视频抖动。 抖动估计适用于由于FEC解码而不是由于重传而延迟的帧。
发送方的媒体优化(MO)组件控制自适应混合NACK / FEC。 MO定期接收网络统计信息,并随每个传入的RTCP接收器报告(大约每秒)更新一次。 这些网络统计信息包括可用带宽,丢包率和往返时间(RTT)。 接收侧带宽估计器计算可用的网络带宽[9]。 MO还接收编码器统计信息,例如传入的帧速率和发送的实际比特率(视频比特率和FEC / NACK保护开销率)。 MO关于混合NACK / FEC的主要功能是设置FEC保护量,并以新的源速率(可用带宽减去估计的保护开销)更新编码器。
4.系统行为和结果
我们采用了离线模拟工具对系统进行了评估,该工具可以在受控环境中模拟各种网络条件。 仿真工具充当发送客户端和接收客户端之间的传输模块,并且由一个通告网络传输延迟的队列组成。 数据包丢弃器放置在队列之后,这可能造成使用GilbertElliot模型[10]从突发丢失模型得出的数据包丢失。 在以下结果中,仅将完整的VP8比特流提供给解码器,因此对视频进行解码时不会出现错误/数据包丢失的情况,并且将接收器配置为等待所有必要的数据包。 因此,视频质量主要受回放的平滑度和可用比特率影响。
测量以下定义的以下性能指标以表征系统的行为:
端到端延迟: 从文件读取帧到在接收器将其呈现回文件之前所花费的平均时间。
渲染标准偏差:渲染的两个连续帧之间的时间增量的标准偏差。 为了获得最佳的时间质量,渲染增量应接近捕获的帧速率,且方差很小。
保护开销:定义为由于重传和FEC而导致的平均开销百分比(相对于总比特率)。 这是所施加的视频保护使压缩视频信号降级的量度。
下面报告的模拟结果是在会话(?)场景上进行的,分辨率为640x360,分辨率为30 fps,动作范围为中低。 该序列长约30秒,实验结果是多次运行后取的平均值。
5.混合NACK/FEC
WebRTC使用自适应混合NACK / FEC方法在时间质量(渲染的平滑度),空间视频质量和端到端延迟之间获得更好的折衷。 我们方法的自适应方面是指发送方FEC量的动态设置,以及接收方的播放延迟。
NACK / FEC混合方法的成本是FEC的开销损失,如图2a所示。 除此之外,与仅NACK方法相比,它具有明显的优势。 图2b显示,将NACK和FEC结合使用时,平均端到端延迟会减少,因为平均等待重传的时间更少,尽管单个重传的等待时间没有改变。 如图2c和d所示,渲染时间增量的标准偏差也显着降低。
如第2节所述,在MO中根据接收到的网络统计信息确定FEC量(保护级别)。 特别地,FEC的量取决于RTT。 当RTT较低时,可以重发数据包而不会造成严重的冻结。 因此,FEC的数量可以减少,从而导致较小的延迟损失。 在大型RTT中,延迟对时间质量的影响更大,因此不应减少FEC的数量。 如图2a所示,对于RTT / 2 <〜50 ms,FEC开销减少了。
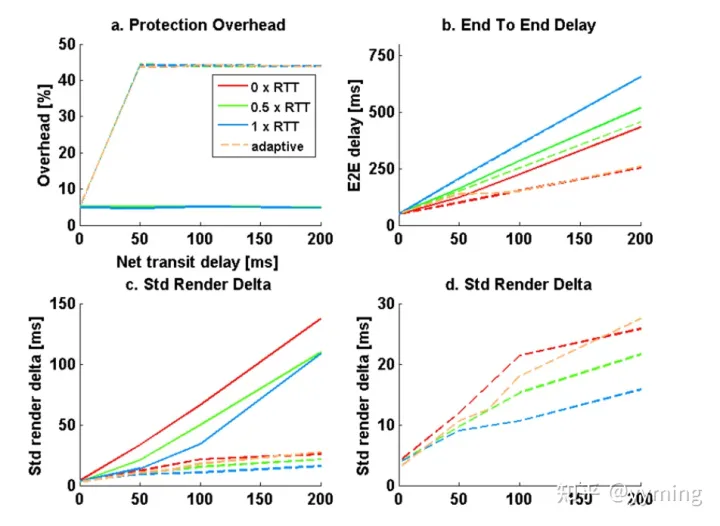
图2: nack和混合nack/fec
对于不同的d(add)值,取决于网络传输延迟。 实线表示NACK,虚线表示混合NACK / FEC。 对于5%的数据包丢失率,突发长度为1,为500kbps。 a)保护开销。 b)端到端延迟。 c)渲染标准偏差。 d)仅针对混合NACK / FEC渲染标准差
播放延迟是在jitterBuffer中控制的,用于权衡时间质量(渲染的平滑度)和端到端延迟。 目的是延迟回放,以减少在等待重发数据包时视频被冻结的持续时间。 但是,当RTT较大时,附加的播放延迟不太合适,因为单向延迟超过400 ms会严重损害通信[11]。 因此,应根据不可恢复的丢包率u和估计的RTT选择额外的播放延迟。 额外的播放延迟可以计算为

K是最大可接受的端到端延迟,RTT / 2是对网络传输时间的估计,抖动是估计的抖动,Umin是数据包丢失的阈值。 与在合理的时间内(例如十秒)计算的合理时间内接收到的数据包数量相比,不可恢复的丢失的比例可以估计为NACK和不合理地延迟接收的数据包数量。 可以将不合理的延迟定义为至少比我们预期相关帧完成的时间晚RTT / 2。 在图2b中可以看到增加的端到端延迟的成本,而在图2c和2d中可以看到增加的回放延迟的收益。 图2中的“自适应”行对dadd使用上面的公式,其中K = 100 ms,Umin =0。其他行具有dadd = kRTT,其中k在{0,0.5,1}中。
6.多帧FEC
WebRTC中使用的FEC是XOR数据包级别的代码[8]。 我们将代码表示为(k,m),其中k是保护组中视频数据包的数量,m是该保护组中FEC数据包的数量。 FEC的保护开销定义为PL = m /(k + m)。 保护组中使用的最大帧数λ也是代码的特征。 此数字是在MO中根据接收到的网络延迟和视频帧速率来动态确定的:λ〜max(1,min(fRTT,λo)),其中f是帧速率,λo是固定上限。
多帧FEC可以降低低比特率的FEC开销,在这种情况下,一帧FEC的粒度非常小(即每帧少量的数据包)。 多帧FEC的另一个特点是,它在恢复损失方面通常比1帧FEC更有效,尤其是对于突发损失。 也就是说,给定两个具有相似保护等级的代码,较长的代码通常比较短的代码具有较低的平均残留损耗。 这是由于可以使用更长的FEC代码的生成器矩阵来恢复更多的损耗配置(参见图3)。 然而,这种改善的恢复是以增加的FEC解码延迟为代价的。
额外的开销阈值控制用于FEC的实际帧数。 多余的开销定义为实际开销(基于保护组中数据包的实际数量)减去目标开销(由PL确定)。 因此,如果FEC生成器从MO接收到λ> 1,则FEC保护组中使用的实际帧数会增加(可能达到最大λ),直到多余的开销低于阈值。
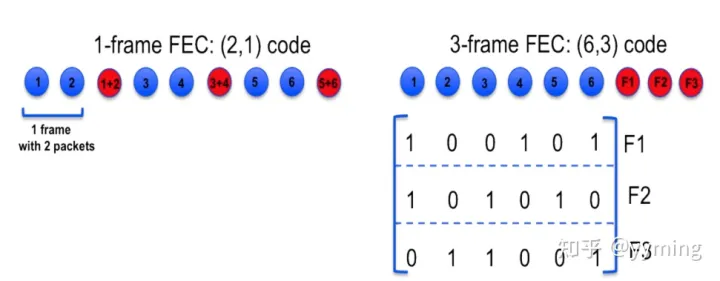
图4: 多帧FEC 会引入额外的恢复和等待延时
图4比较了1帧FEC和多帧FEC。 对于该比较,λ分别固定为1和6。 从图4a和4b中可以看出,使用多帧FEC可以降低端到端延迟和渲染增量方差。 对于此损耗模拟,MO中设置的FEC保护级别应使平均保护开销为〜20/25%。 图4c显示了多帧FEC如何达到目标保护开销,而1帧FEC过冲并因此产生了额外开销,特别是对于较低的比特率范围(过多的开销在较高的比特率下减少,即,更多的数据包/帧) 。 在多帧情况下,较低的保护开销导致较高的PSNR /质量。
每帧2个数据包,保护开销为33%的示例(FEC数据包跟随其保护的源数据包)。 1帧FEC是每个帧中两个源数据包的XOR,而3帧FEC具有上面所示的6x3生成器矩阵。 后者可以恢复更多的丢失配置,特别是使用(6,3)代码可以完全恢复大小小于等于3的任何连续丢失。
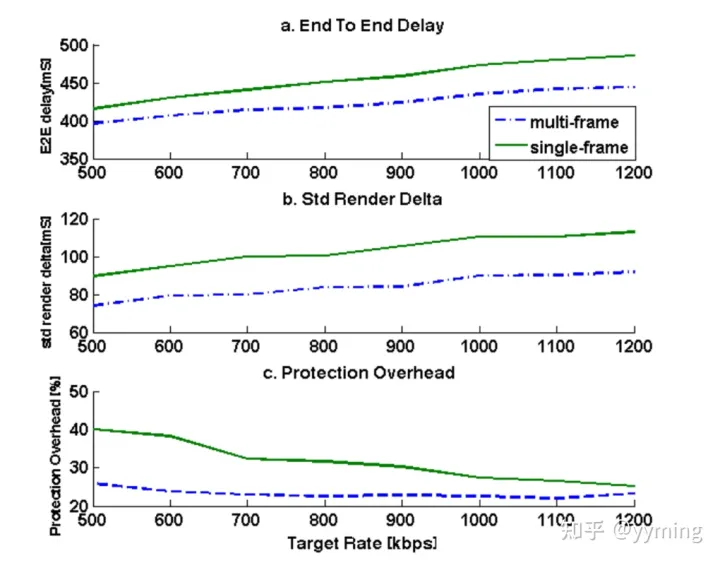
图5: 混合nack/fec
图5显示了混合组合NACK/FEC 多帧FEC与1帧FEC。 对于5%的丢包率,突发长度为2,RTT = 300ms; dadd =0。a)端到端延迟。 b)渲染标准偏差。 c)保护开销。
7结合Temporal Layers的混合NACK/FEC
上面讨论的多帧FEC具有降低保护开销和改善对丢包率的恢复的潜力,但是当RTT不明显大于逆帧速率时,较长的FEC解码延迟会变得太昂贵。 混合NACK / FEC与分层编码相结合,允许使用另一种机制来减少开销(例如,通过仅保护基本层帧),并提供了较低的端到端延迟与视频质量的附加折衷(较低的时空 解析度)。 在本文中,我们讨论了如何结合混合NACK / FEC使用时间层(TL)。
VP8中的时间可伸缩性[7]能够生成以速率为目标的时间可分离流。 对于此处报告的结果,对于TL = 2,基础层的速率分配为60%,对于TL = 3,基层的速率分配为40%(分别为2和3个时间层)。 时间模式结构具有同步帧(每8帧放置一次),这些同步帧用于在接收器处启用(不完整/丢失的)增强帧。
混合NACK / FEC + TL系统的操作如下:
\1. UEP-FEC(不等错误保护)用于仅对基础层帧进行保护的情况。 发送方仅重新传输属于基础层帧的数据包。
\2. 时间层ID和同步帧标志嵌入每个数据包的编解码器特定的RTP头[12]中,并在接收器/抖动缓冲器中提取.
\3. 完成了一种选择性的nacking,仅对与基础层帧相对应的丢失数据包进行了NACK。 如果在增强层帧中检测到丢失的数据包,则丢弃所有增强帧,直到接收到完整的同步帧。
图6: 混合nack/fec + TL系统
图5显示了TL = 1、2、3的混合NACK / FEC的性能指标。在这些比较中,FEC仅用在了最低层simulcast中。图5a和5b显示了较低的端到端延迟和渲染差异,以及图5c中的较低保护开销方面的显着收益。开销的减少是由于仅将FEC应用于基本层帧。开销减少大致对应于基础层比特率:对于TL = 2,约为60%,对于TL = 3,约为40%。
使用TL的权衡有两个组成部分:(1)在没有丢包的情况下的压缩效率损失(编解码器损失),以及(2)在渲染的视频中较低的时间分辨率(来自接收器丢失的增强帧)。掉落的增强帧造成的视觉质量损失很难量化。关于TL> 1的编解码器损失,至少在开销相对较高的情况下,我们可以预期,减少的FEC开销所带来的收益将弥补压缩效率的损失。这在图6中提出,图6显示了时间层下的编解码器损失。
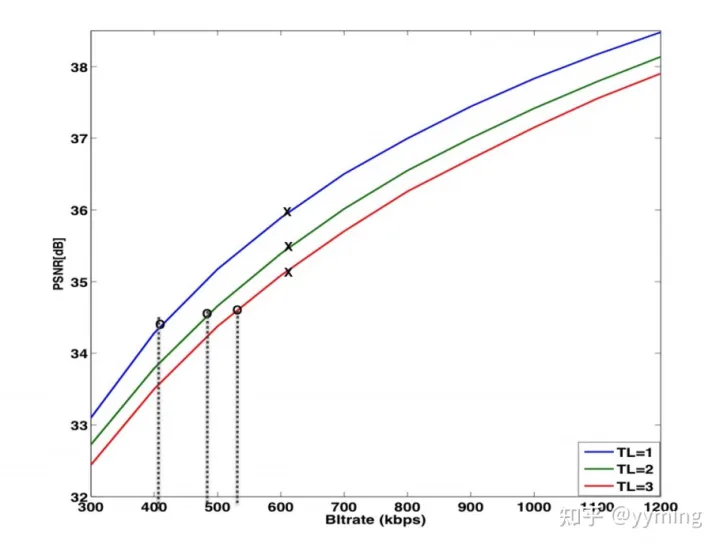
图6: 零丢包场景下的图像PSNR值
图中指示了两组点:一组为〜600kbps,另一组为降低的比特率,对应于TL = 1时的保护开销为〜33%,〜(33 * 0.6)%,〜(33 * 0.4)% ,2、3。 33%是图5c中TL = 1的示例开销(〜600 / 700kbps)。
8.总结和展望未来
在本文中,我们介绍了用于处理WebRTC中数据包丢失的视频处理工具的某些方面。性能指标用于量化丢包和延迟对网络的影响。提出了一种与TL相结合的自适应混合NACK / FEC方法,以控制整体视频质量,播放抖动和端到端延迟。尤其讨论了自适应播放延迟作为权衡渲染抖动和延迟的一种机制,并提出了两种方法(多帧FEC和TL)来降低保护开销成本。当考虑突发损失情况和相对较长的RTT时,结果表明这两种方法都有可能改善所有三个系统指标:更低的渲染抖动,更低的端到端延迟以及更高或类似的(空间)视频质量/ PSNR。可以从各种扩展中获得改进的性能,例如跨时间层更好地使用选择性NACKing,多帧FEC和UEP-FEC。这项工作的扩展还包括改进指标,以包括例如更好的抖动适应程度[13]。
9.参考文档
[1] http://www.webrtc.org/; http://code.google.com/p/webrtc/
[2] Y. Wang, S. Wenger, J.T. Wen, A.K. Katsaggelos, “Review of Error Resilient Coding Techniques for RealTime Video Communications,” IEEE Signal Proc. Magazine, vol. 17, no. 4, pp. 61-82, Jul. 2000.
[3] J, Korhonen, P. Frossard, “Flexible forward error correction codes with application to partial media data recovery”, Signal Processing: Image Communication 24, (2009), 229-242.
[4] F. Battisti, M. Carli, E. Mammi, and A. Neri, "A study on the impact of AL-FEC techniques on TV over IP Quality of Experience", EURASIP Journal on Advances in Signal Processing, 2011.
[5] S. Fukunaga, T. Nakai, and H. Inoue, “Error Resilient Video Coding by Dynamic Replacing of Reference Pictures”, Proceedings of IEEE Global Telecommunications Conf. (GLOBECOM), London, vol. 3, Nov. 1996, pp.1503– 1508.
[6] F. Zhai, Y. Eisenberg, T. N. Pappas, R. Berry and A. K. Katsaggelos, “Rate distortion optimized hybrid error control for real-time packetized video transmission,” IEEE Transactions on Image Processing, pp. 40-53, 2006.
[7] [Welcome to the WebM Project](https://link.zhihu.com/?target=http%3A//www.webmproject.org/); J. Bankoski, P. Wilkins and Y. Xu, “VP8 Data Format and Decoding Guide,” RFC6386 (Informational), Nov. 2011.
[8] Li, A., “RTP Payload Format for Generic Forward Error Correction,” RFC 5109 (Proposed Standard), Dec. 2007.
[9] H. Lundin, S. Holmer and H. Alvestrand, “A Google Congestion Control Algorithm for RealTime Communication on the World Wide Web,” IETF Informational Draft, April 2012.
[10] P. Ferre, D. Agrafiotis, T-K Chiew, A. Doufexi, A.R. Nix, D.R Bull, “Packet Loss Modelling for H.264 Video Transmission over IEEE 802.11g Wireless LANs”, in WIAMIS 2005.
[11] ITU-T G.114, February 1996.
[12] P. Westin, H. Lundin, M. Glover, J. Uberti and F. Galligan “RTP Payload Format for VP8 Video,” IETF Internet Draft, Jan 2013.
[13] S. Borer, “A model of jerkiness for temporal impairments in video transmission,” in Proc. Int. Workshop Quality Multimedia Exper. (QoMEX), Jun. 2010, pp. 218– 223.
原文: HANDLING PACKET LOSS IN WEBRTC
★文末名片可以免费领取音视频开发学习资料,内容包括(FFmpeg ,webRTC ,rtmp ,hls ,rtsp ,ffplay ,srs)以及音视频学习路线图等等。
见下方!↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓