本文目录
- 一、为什么我们需要推荐系统?
- 二、推荐系统的发展阶段
- 三、推荐系统模型
- 四、通用推荐系统框架
- 4.1 数据生产
- 4.2 数据存储
- 4.3 算法召回
- 4.4 结果排序
- 4.5 结果应用
- 4.6 新浪微博的框架开源结构图
- 五、推荐常用特征
- 5.1 用户特征
- 5.2 物品特征
- 六、推荐常用算法
- 七、结果评估指标
- 7.1 准确率
- 7.2 AUC指标
- 7.3 其他指标
一、为什么我们需要推荐系统?
几十年来,从时间维度上看,信息呈指数爆炸式的增长,数据和信息已经成为一种重要的生产资料了。
如果从表现维度上看,图片、视频等越来越多,信息的载体越来越多。
除此之外,任何一家企业公司都需要留存与转化,推荐系统越完善,用户信息采集的越多,从而可以达到更好的优化推荐效果,这会有明显的正反馈效应。
二、推荐系统的发展阶段
早期:
1990年由哥伦比亚大学教授首次提出。
1992年协同过滤被踢出。
2001年Item-based CF出现。
发展高潮期:
2006-2009年,Netflix发起的电影推荐系统竞赛。
2009年BPR算法成为隐式反馈数据推荐的经典算法。
深度学习期:
2016年谷歌发布YoutubeDNN,分为召回排序两个阶段。
2018年阿里引入注意力机制。
近年来字节、百度等公司均大规模使用深度学习。
三、推荐系统模型
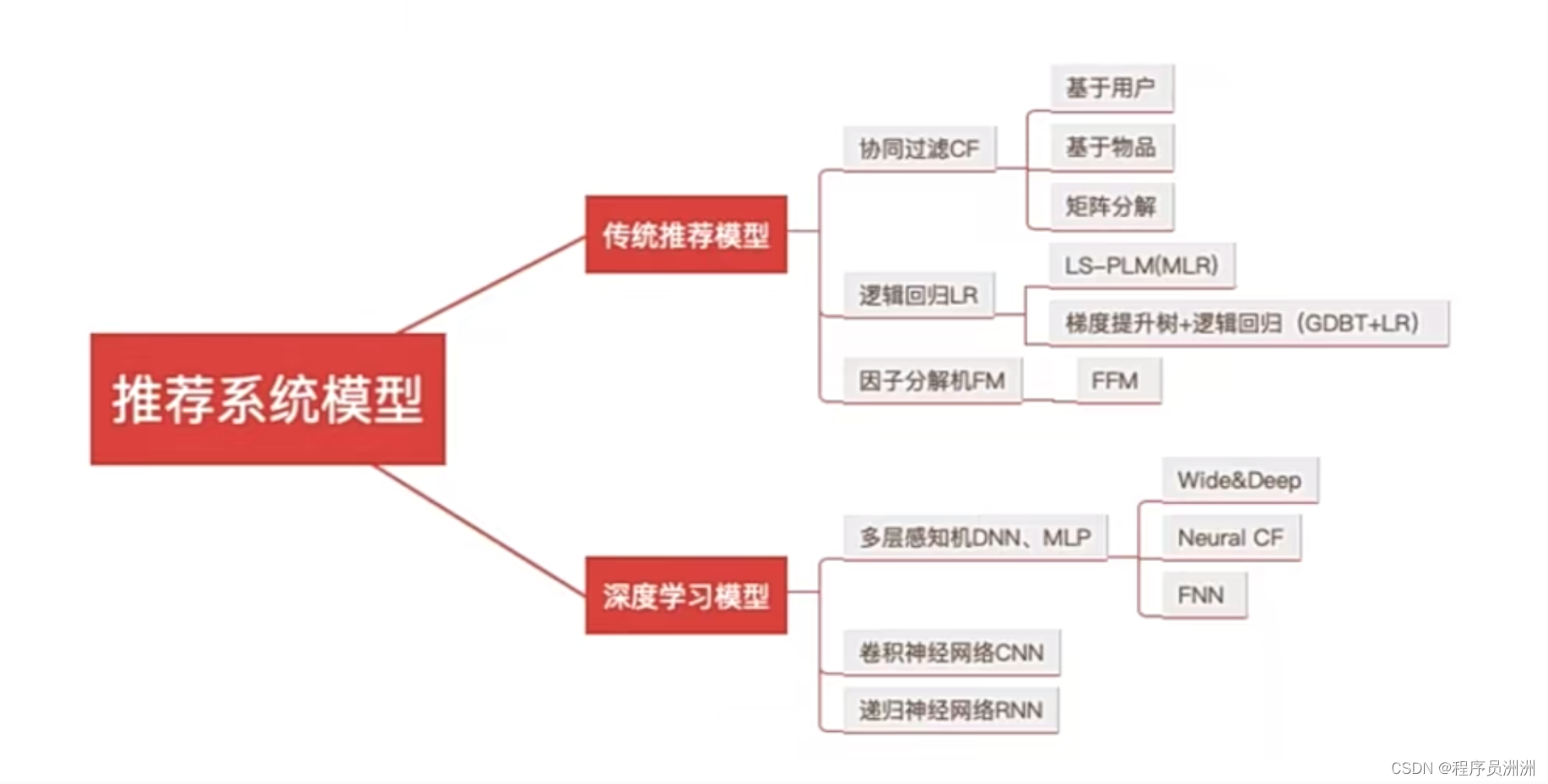
推荐系统的抽象结构:
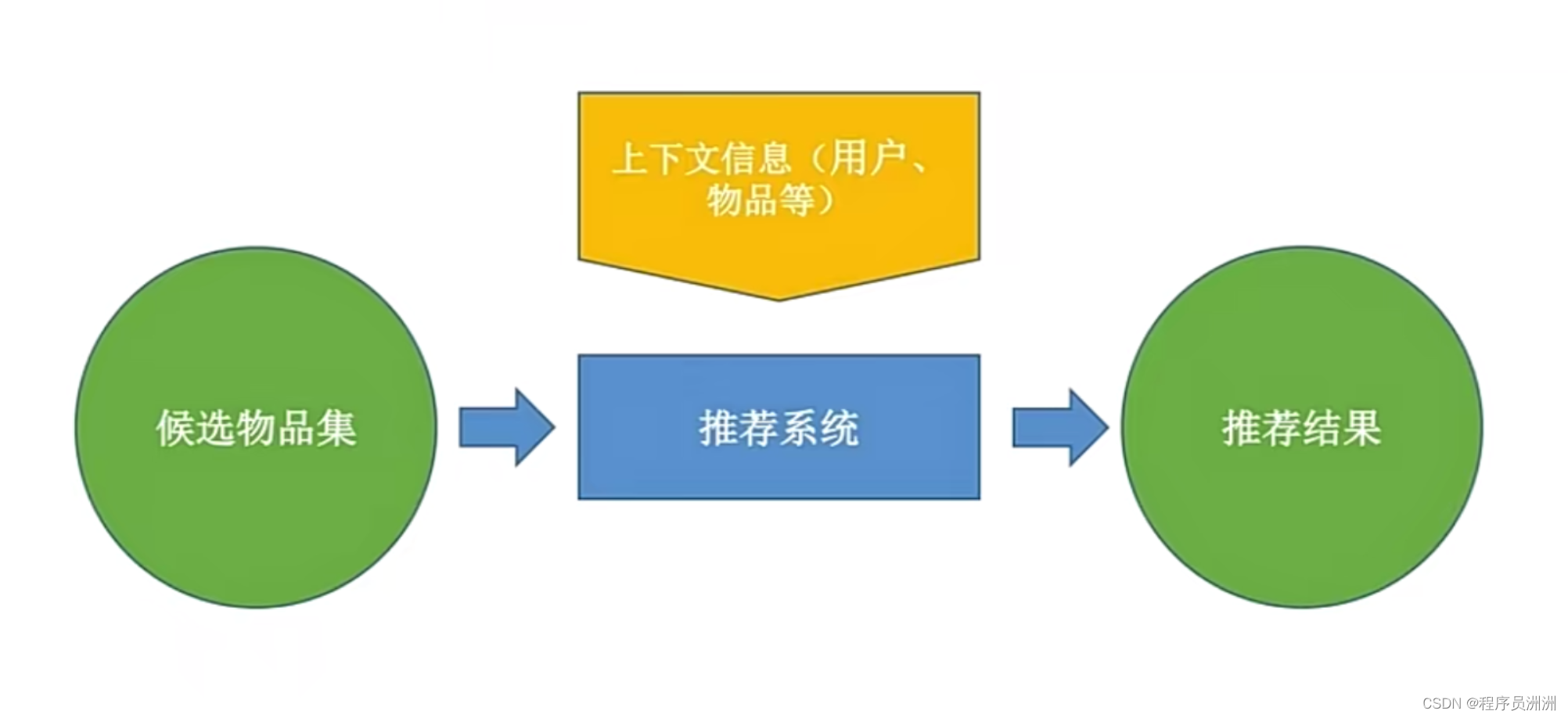
四、通用推荐系统框架

4.1 数据生产
将有用的信息进行汇总、清洗、及预处理,为后续的分析和推荐做准备。
4.2 数据存储
进行持久化存储收集到的数据。方便后续不同阶段和不同模块灵活的取用。通常会按照数据的冷热、结构化和非结构化等等特征进行分布存储。
4.3 算法召回
将海量的数据集,通过特定的算法进行初步筛选。通常会把候选集的数据规模从数十万降低至数百或者数千个。
在实际的算法过程中,会考虑多种策略,做到面面俱到。
4.4 结果排序
对召回的结果进行进一步的筛选,并且进行精确的排序。通常会将数据集规模从数百降低至几十,排序时会针对多个目标进行优化。
4.5 结果应用
根据不同的场景给用户展示最终的推荐结果,场景的不同往往会影响推荐的策略和算法。
- 总的来说,从上百万的候选集中召回一定的数据,然后进行排序,最终成为推荐结果。
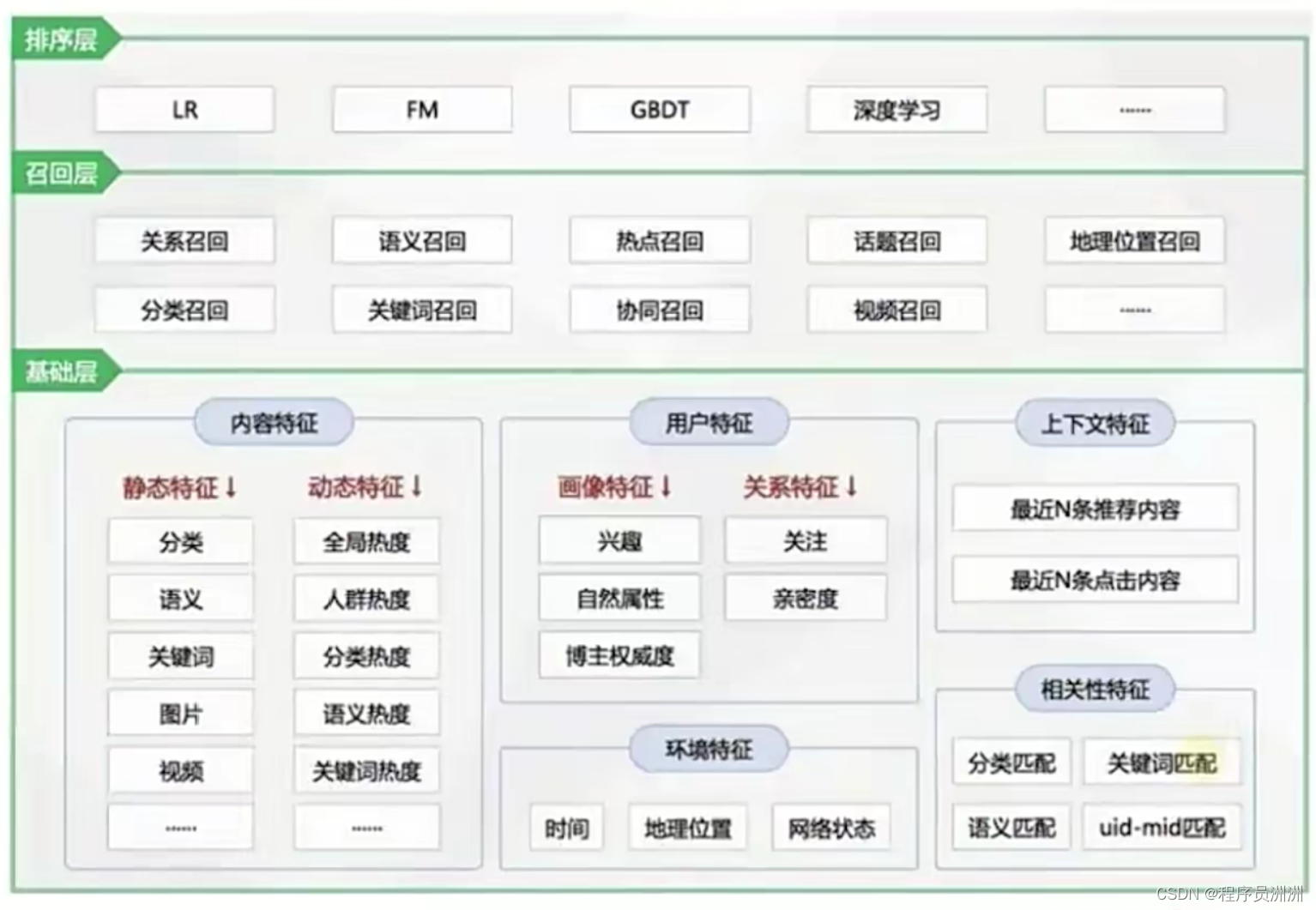
4.6 新浪微博的框架开源结构图
五、推荐常用特征
5.1 用户特征
自然属性:姓名、性别、年龄、地域。
画像特征:兴趣、行为。
关系特征:人群属性、关注关系、亲密度等等。
协同特征:点击相似用户、兴趣分类相似用户、兴趣主题相似用户。
5.2 物品特征
静态特征:分类、标签、主题、价格。
动态特征:热度、分类热度、标签热度。
相关性特征:主题相似、分类匹配、主题匹配、关键词匹配等等。
上下文特征:最近N条浏览记录。
环境特征:时间、地理位置等等。
六、推荐常用算法
基于流行度:最热门的、最新、最多人点赞等等。
基于内容:相同标签、关键词、主题等等。
基于关联规则:看了A的人也看了B。
近邻推荐:协同过滤(又可以进一步分为基于用户、基于物品、基于模型的过滤)
七、结果评估指标
7.1 准确率
1、准确率:正确的预测样本数/总采样数。(但容易被正负样本比例影响)
7.2 AUC指标
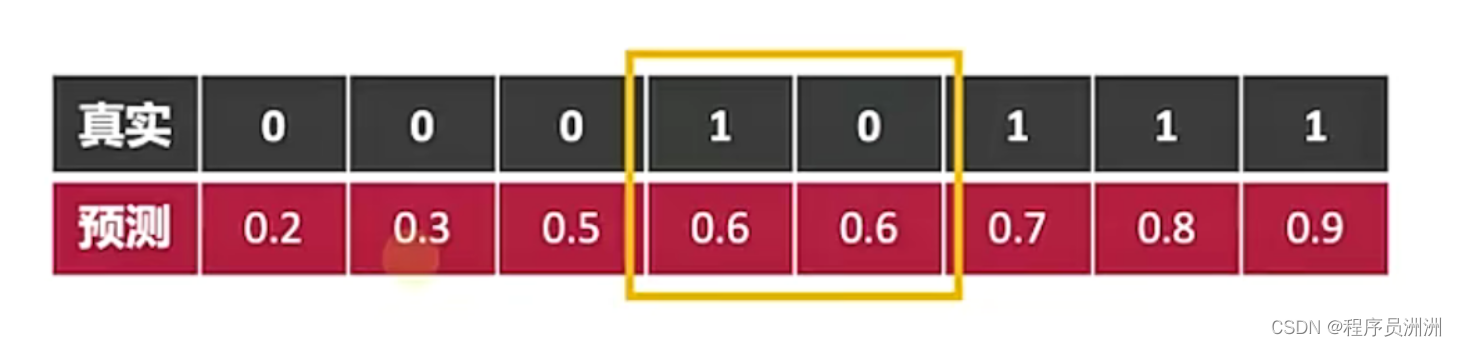
2、曲线下面积AUC:不同阈值下,预测结果中真阳和假阳之比。
ROC指标:
对于输出值连续的分类器(如概率预测),在某一阈值下真阳性TP的概率/假阳性FP的概率。
阈值的概念:就是超过多少概率下,才会认为是垃圾邮件。(例如阈值0.6,只有概率大于0.6时,才认为是真阳性。)
AUC可以看成:随机从正负样本中选取一对正负样本,其中正样本的得分大于负样本的概率。(就是任意选取一对正负样本,能够正样本的得分概率大于负样本的概率。)这对于正负样本的数值比例不会受影响!就优化了准确率这个评估指标。
AUC=1时,就是完美分类器。
AUC>0.5时候,绝大多数真实分类器的区间。
AUC=0.5,就是基线分类器,就是抛硬币。
AUC<0.5,对于负样本更加准确,是可以转化为正分类器的。
7.3 其他指标
满意度:准确率、停留时长、转化率。
覆盖率:长尾物品是否能被推荐。
多样性:推荐的物品是否两两不相似,尽可能覆盖多个兴趣点。
新颖性:是否能推一些新兴的产品。
惊喜性:推荐的东西和用户历史行为记录都不相似,但是用户非常喜欢。
实时性:根据用户最新喜好实时更新推荐结果。
商业目标:是否能达成商业目标如GMV。