CV - 计算机视觉 | ML - 机器学习 | RL - 强化学习 | NLP 自然语言处理
Subjects: cs.CV
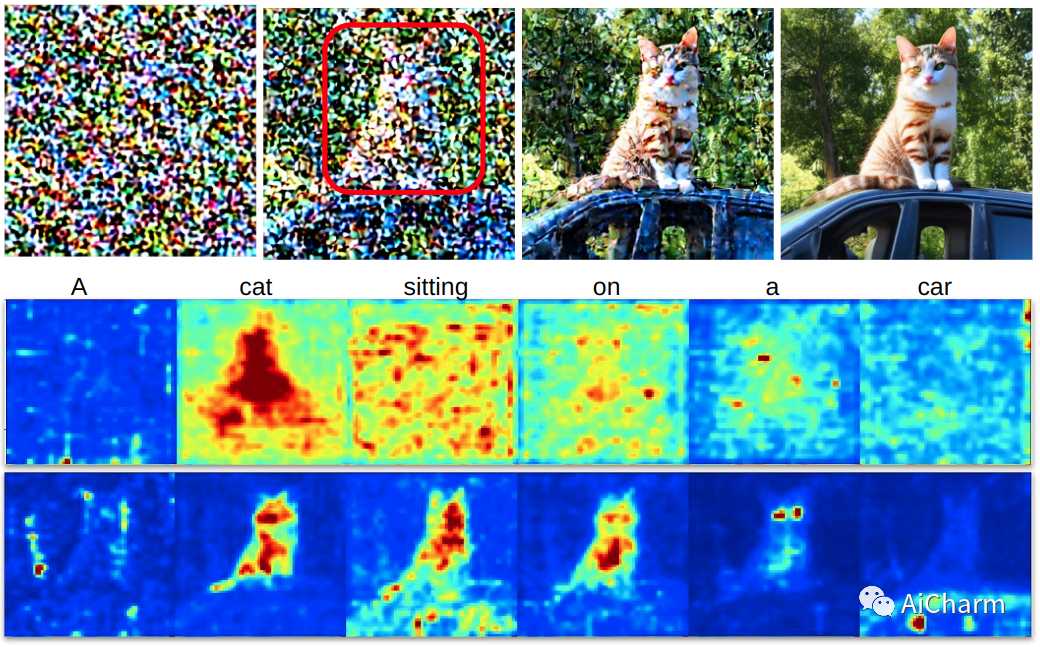
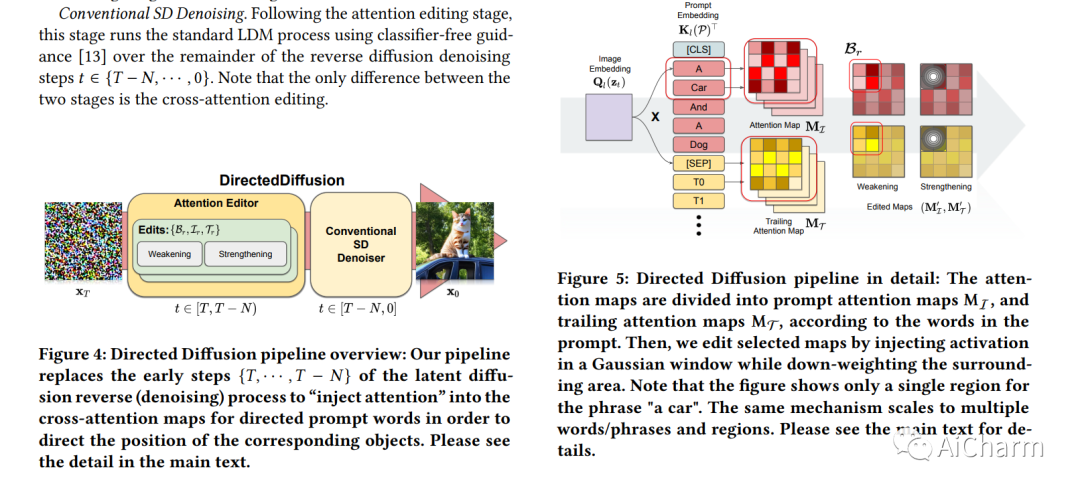
1.Directed Diffusion: Direct Control of Object Placement through Attention Guidance

标题:定向扩散:通过注意力引导直接控制物体放置
作者:Wan-Duo Kurt Ma, J.P. Lewis, W. Bastiaan Kleijn, Thomas Leung
文章链接:https://arxiv.org/abs/2302.02814
项目代码:https://hohonu-vicml.github.io/DirectedDiffusion.Page/

摘要:
文本引导的扩散模型,如 DALLE-2、IMAGEN 和 Stable Diffusion,只要给出描述所需图像内容的简短文本提示,就能够有效地生成无穷无尽的图像。在许多情况下,图像的质量也非常高。然而,这些模型通常难以组合包含多个关键对象的场景,例如具有指定位置关系的角色。不幸的是,正如电影和动画理论文献中所承认的那样,这种“指导”图像内和图像间人物和物体放置的能力在讲故事中至关重要。在这项工作中,我们采用一种特别直接的方法来提供所需的方向,通过在交叉注意力图中与受控对象对应的所需位置注入“激活”,同时衰减地图的其余部分。由此产生的方法是朝着将文本引导扩散模型的适用性从单个图像推广到相关图像集合的一步,就像在故事书中一样。据我们所知,我们的定向扩散方法是第一个提供对多个对象的位置控制的扩散技术,同时利用现有的预训练模型并保持定位对象和背景之间的连贯混合。而且,它只需要几行就可以实现。
2.Imaginary Voice: Face-styled Diffusion Model for Text-to-Speech

标题:想象的声音:用于文本到语音的面部风格扩散模型
作者:Jiyoung Lee, Joon Son Chung, Soo-Whan Chung
文章链接:https://arxiv.org/abs/2302.13700
项目代码:https://facetts.github.io/
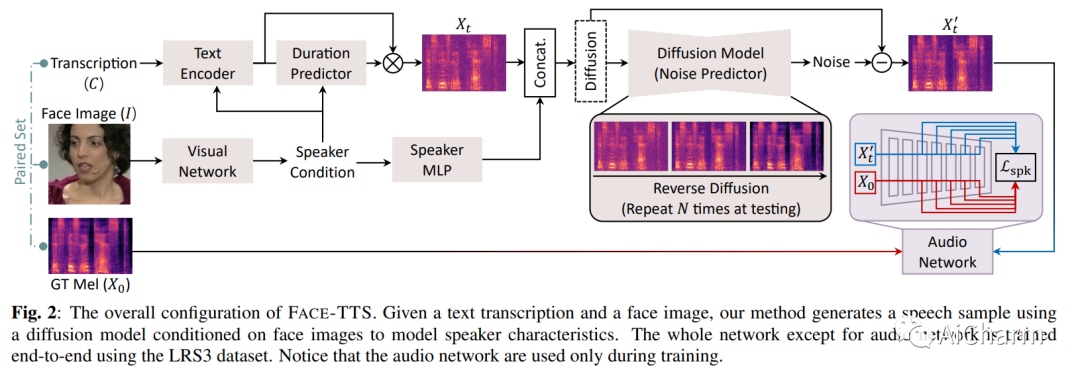

摘要:
我们联合训练跨模型生物识别和 TTS 模型,以保留面部图像和生成的语音片段之间的说话人身份。我们还提出了说话人特征绑定损失,以加强说话人嵌入空间中生成的语音片段和真实语音片段的相似性。由于生物识别信息是直接从面部图像中提取的,因此我们的方法不需要额外的微调步骤来从看不见和听不到的说话者中生成语音。我们在 LRS3 数据集上训练和评估模型,LRS3 数据集是一个包含背景噪音和不同说话风格的野外视听语料库。
3.Decoupling Human and Camera Motion from Videos in the Wild

标题:从野外视频中解耦人类和相机运动
作者:Vickie Ye, Georgios Pavlakos, Jitendra Malik, Angjoo Kanazawa
文章链接:https://arxiv.org/abs/2302.01660v2

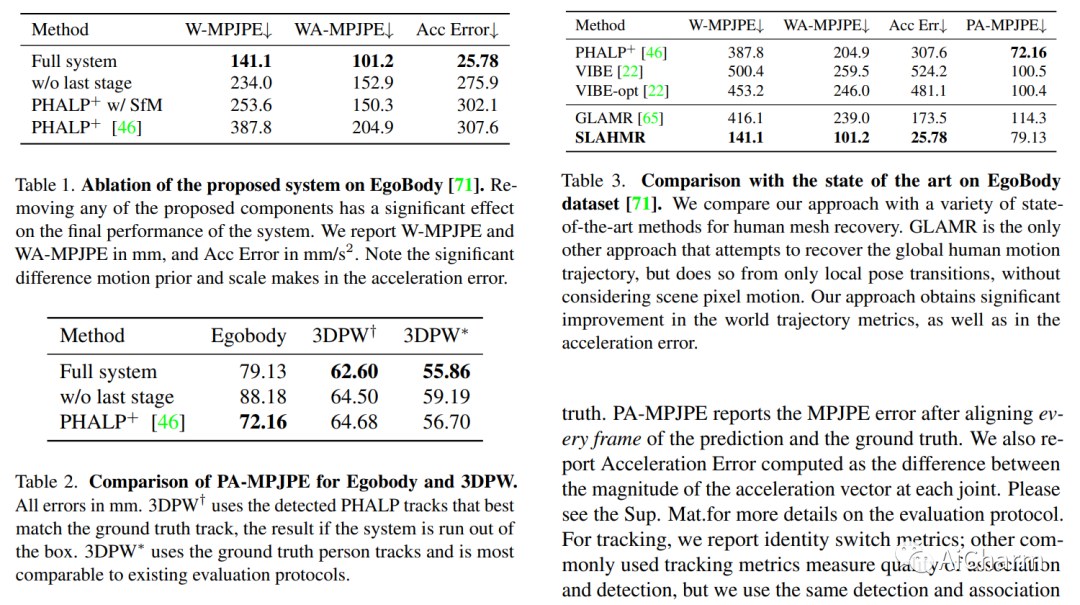
摘要:
我们提出了一种从野外视频重建全球人类轨迹的方法。我们的优化方法解耦了相机和人体运动,这使我们能够将人们置于同一个世界坐标系中。大多数现有方法不对相机运动进行建模;依赖背景像素来推断 3D 人体运动的方法通常需要全场景重建,这对于野外视频来说通常是不可能的。然而,即使现有的 SLAM 系统无法恢复准确的场景重建,背景像素运动仍然提供足够的信号来约束相机运动。我们表明,相对相机估计以及数据驱动的人体运动先验可以解决场景尺度歧义并恢复全球人体轨迹。我们的方法在具有挑战性的野外视频(例如 PoseTrack)中稳健地恢复了人们的全局 3D 轨迹。我们量化了我们对 3D 人体数据集 Egobody 现有方法的改进。我们进一步证明,我们恢复的相机比例允许我们推理共享坐标系中多人的运动,这提高了 PoseTrack 中下游跟踪的性能。可以在此 https URL 中找到代码和视频结果。
更多Ai资讯:公主号AiCharm