下面聊聊Kafka中的Offset位移
1、Offset位移概述
在引入Kafka服务后,当consumer消费完数据后需要进行位移提交,那么提交的位移数据究竟存储到那里,有以何种方式进行存储?
Kafka旧版本(<0.8)是重度依赖Zookeeper来实现各种各样的协调管理,在旧版本的consumer group是把位移保存在Zookeeper中,减少broker端状态存储开销,鉴于Zookeeper的存储架构设计来说,它不适合频繁写更新,而consumer group的位移提交又是频繁写操作,这样会拖慢Zookeeper集群的性能,于是在Kafka新版本中,社区重新设计了consumer group的位移管理方式,采用了将位移保存在Kafka内部,就出现了大名鼎鼎的_consumer_offsets。
1.1、_consumer_offsets
_consumer_offsets是用来保存Kafka consumer提交的位移信息,且它是由Kafka自动创建的,和普通的Topic相同,它的消息格式也是Kafka自己定义的,无法进行修改。
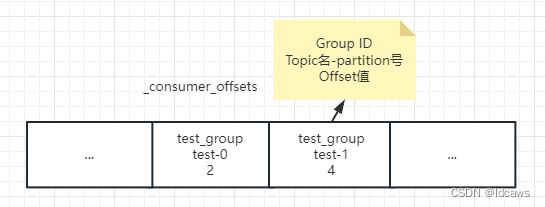
_consumer_offsets消息格式可以简单理解为一个K-V对,Key和Value分别表示消息的键值和消息体。_consumer_offsets存储consumer的位移信息,在Kafka中consumer数量很多,这时通过公共且唯一的Group ID来标识属于那个consumer,consumer提交位移是在分区的维度进行,这时通过分区号来标识要提交的位移分区。
总结,_consumer_offsets主题的Key应该包含3部分内容:<Group ID,主题名,分区号>,_consumer_offsets主题的Value可以简单认为存储的是offset值,当然还有其他一些元数据。
_consumer_offsets消息格式:
1.2、_consumer_offsets创建过程
当Kafka集群中的第一个consumer启动时,Kafka会自动创建_consumer_offsets。前面说过,它和普通Topic相同,它也有对应的分区数,若是由Kafka自动创建,这个依赖broker端参数offsets.topic.num.partitions(默认值为50),因此Kafka会自动创建一个有50个分区的_consumer_offsets。这就是在Kafka日志路径下看到很多_consumer_offsets-xxx这样目录的原因,既然有分区数,比如就会有对应的副本数,这个依赖broker端参数offsets.topic.replication.factor(默认值为3)。
总结,_consumer_offsets由Kafka自动创建,该Topic的分区数是50,副本数是3,而具体Group的消费情况要存储到那个Partition,根据abs(GroupId.hashCode())%NumPartitions来计算,这样就可以保证consumer offset信息与consumer group对应的coordinator处于同一个broker节点上。
2、数据测试
2.1、创建Topic
./bin/kafka-topics.sh --create --bootstrap-server localhost:9092 --replication-factor 3 --partitions 3 --topic test_1
2.2、生产数据
public class KafkaProducerTest {
public static final String bootStrap = "localhost:9092";
public static final String topic = "test_1";
public static final String key = "test";
public static void main(String[] args) {
// 1、配置客户端参数
Properties properties = new Properties();
// 指定生产者客户端连接Kafka集群所需的broker地址列表,具体的内容格式为host1:port1,host2:port2
properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, bootStrap);
// key序列化,转换成字节数组以满足broker端接收的消息形式
properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
// value序列化,转换成字节数组以满足broker端接收的消息形式
properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
// 配置重试次数,10次之后抛异常,可以在回调中处理
properties.put(ProducerConfig.RETRIES_CONFIG, 10);
// 配置客户端id
properties.put(ProducerConfig.CLIENT_ID_CONFIG, "producer.client.id.1");
// 2、构造KafkaProducer客户端实例
KafkaProducer kafkaProducer = new KafkaProducer(properties);
// 3、同一个key的消息放到同一个分区,不指定key则均衡分布,消息分区的选择是在客户端进行的
for (int i = 0; i < 100; i++) {
try {
String message = "hello world " + i;
ProducerRecord producerRecord = new ProducerRecord(topic, key, message);
Future<RecordMetadata> future = kafkaProducer.send(producerRecord);
List<PartitionInfo> partitionsFor = kafkaProducer.partitionsFor(topic);
for (PartitionInfo partitionInfo : partitionsFor) {
System.out.println(partitionInfo);
}
RecordMetadata recordMetadata = future.get();
System.out.println(recordMetadata.toString());
} catch (Exception e) {
e.printStackTrace();
}
}
}
}
2.3、消费者
public class KafkaConsumerTest {
public static final String bootStrap = "localhost:9092";
public static final String topic = "test_1";
public static final String groupId = "group_1";
public static void main(String[] args) {
// 1、配置客户端参数
Properties properties = new Properties();
// 设置offset初始位置
properties.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, "earliest");
// 指定消费者客户端连接Kafka集群所需的broker地址列表,具体的内容格式为host1:port1,host2:port2
properties.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, bootStrap);
// key序列化,转换成字节数组以满足broker端接收的消息形式
properties.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
// value序列化,转换成字节数组以满足broker端接收的消息形式
properties.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
// 关闭自动提交位移
properties.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, "false");
// 自动提交时间间隔
properties.put(ConsumerConfig.AUTO_COMMIT_INTERVAL_MS_CONFIG, "1000");
// session会话响应时间,超过这个时间kafka可以选择放弃消费或消费下一条消息
properties.put(ConsumerConfig.SESSION_TIMEOUT_MS_CONFIG, "30000");
// 配置消费组id
properties.put(ConsumerConfig.GROUP_ID_CONFIG, groupId);
// 配置客户端id
properties.put(ConsumerConfig.CLIENT_ID_CONFIG, "consumer.client.id.1");
// 2、构造KafkaConsumer客户端实例
KafkaConsumer kafkaConsumer = new KafkaConsumer(properties);
// 3、订阅主题
kafkaConsumer.subscribe(Collections.singletonList(topic));
// 4、消费消息
try {
while (true) {
ConsumerRecords<String, String> records = kafkaConsumer.poll(10000);
for (ConsumerRecord<String, String> item : records) {
System.out.printf("offset = %d, key = %s, value = %s%n", item.offset(), item.key(), item.value());
}
// 手动提交
kafkaConsumer.commitSync();
}
} catch (Exception e) {
e.printStackTrace();
} finally {
kafkaConsumer.close();
}
}
}
2.4、查看Offset数据

从上面可以看出指定的key为"test"的消息被分配到test_1的3分区下,并且当前的消费的offset是100。
3、重新消费
在Kafka新版本中位移偏移量会保存在Kafka内部的Topic(_consumer_offsets)中,该topic默认有50个partition,每个partition有3个副本,通过abs(GroupId.hashCode())%NumPartitions来确定某个消费者组已消费的offset保存到那个分区中。
重新消费数据时的方式如下:
- 修改偏移量offset
- 通过consumer.subscribe()指定偏移量offset
- 通过auto.offset.reset指定偏移量offset
- 通过指定时间来消费