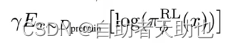论文链接:https://arxiv.org/pdf/2203.02155.pdf
1 摘要
做的事:
1、标注了数据,问题和答案写出来,然后训练模型
2、收集数据集,排序模型的输出,使用强化学习训练这个排序的过程
效果层面来说:
- 1.3Billions的参数 InstructGPT Model比175Billions参数的GPT3效果更好
- 降低了模型输出无效、有害信息
2 导论
2.1 问题
训练语言模型的时候,即使给定了例子来遵循人类的指令,但是也会出现不好的例子,那是因为目标函数的问题
目标:
- helpful
- honest
- harmles
2.2 方法
使用RLHF
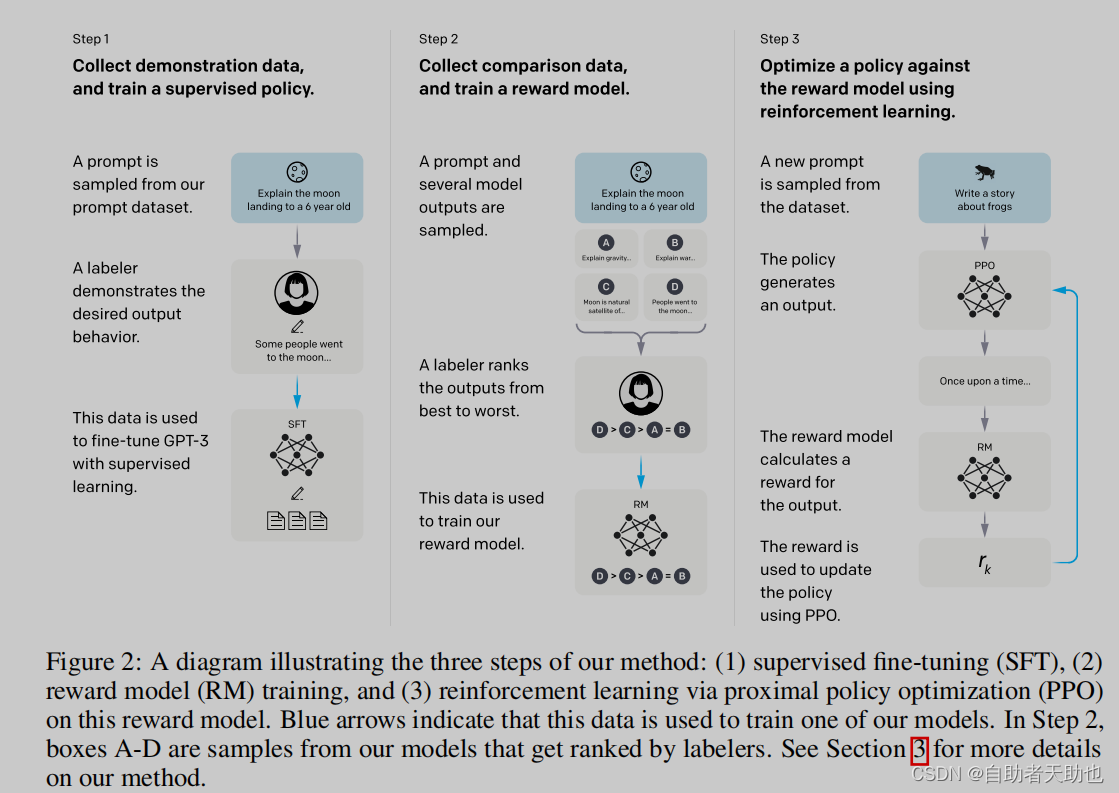
step1 在gpt3进行标注数据的微调,使用上下文,预测下一个词语,SFT
step2 给生成(beam search)的答案进行标注喜好, 排序,使用RM训练(prompt+答案=》分数),分数的排序满足,人类的排序
step3 重新训练SFT,满足生成出来的结果满足人类排序的结果
第一步的难点在于:生成式的标注难度和成本高于,判别式的标注
2.3 结果

更强

更可靠

无毒、无偏见

最小化减少对共有NLP任务的影响

生成的内容更满足人类的喜好,找人来判断的

公共的NLP数据集并不能反映出我们的语言模型的使用方式

模型有一定的泛化性,即使没见过的任务,也是能根据先验知识,进行很好的生成
3 方法和实验细节
3.1 顶层设计
Step 1: Collect demonstration data, and train a supervised policy.
Step 2: Collect comparison data, and train a reward model.
Step 3: Optimize a policy against the reward model using PPO
2/3步会反复迭代
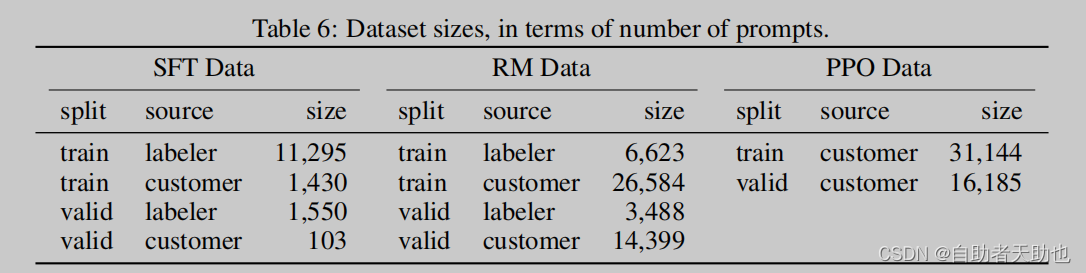
3.2 数据集

保证任务的多样性、一个指令,多样的回答下命令也要多、已经希望构成的任务,以上数据训练了一个模型,然后放在Playground中,试运行,收集问题,根据用户ID进行划分train\dev\test,同时过滤掉了PII.
上线后产生了三个不同的数据集:
- SFT,直接写答案 13k样本
- RM数据集,ranking output 33K
- PPO, 没有标注,直接作为RLHF进行FT 31K
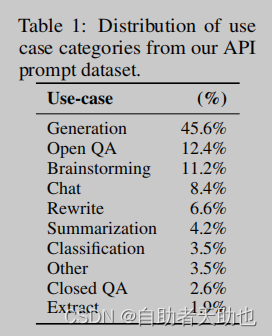
3.3 任务
3.4 人类数据收集
招人 40个人的团队
筛选人的标准
标注的准则:helpfulness
评估的准则:truthfulness and harmlessness
标注的一致性:72.6±1.5%、77±3%
3.5 模型
3.5.1 SFT
模型用的是:GPT3
16epochs, 发现1个epochs就overfitting了,这个模型只是在初始化用
3.5.2 RM
原本的SFTmodel, 最后应该接一个softmax, 得到一个概率最大的词语,现在是,不用这个softmax,改为linear,到一个标量上,输入是:prompt+response
model是6B的model,大的模型不稳定
loss用的是pair wise ranking loss

拿出一对respond,如果yw的分数大于yl,那么最大化这个损失函数,用的是logistics regression,
每个prompt生成9个答案,C(9,2)=36对这样的数据集来进行构造损失. r是6B的GPT3
改了损失函授之后,过拟合的现象稍微缓和点了
3.5.3 RL
PPO算法

模型叫:
-
pai(RL,SIGMA) RL policy,强化学习的时候采样的y会变化,就是强化选择的过程,y生成多个,并进行排序
-

-
用上了KL散度,评估函数的相似度
-

-
GPT3训练的语言模型的损失函数,保证原本数据集的性能不要下降
-