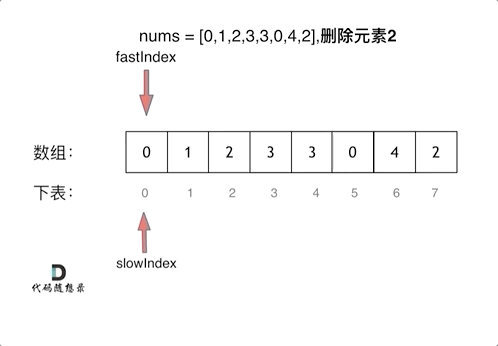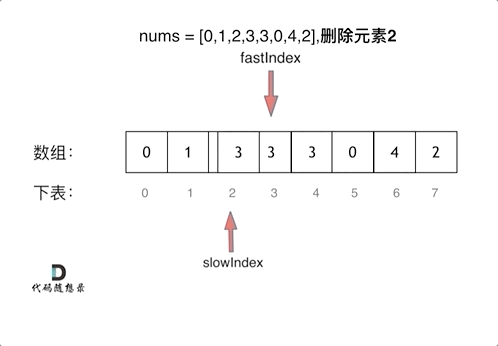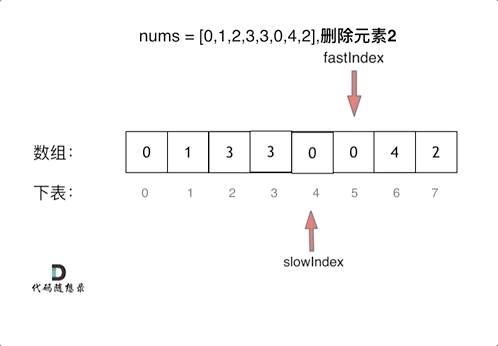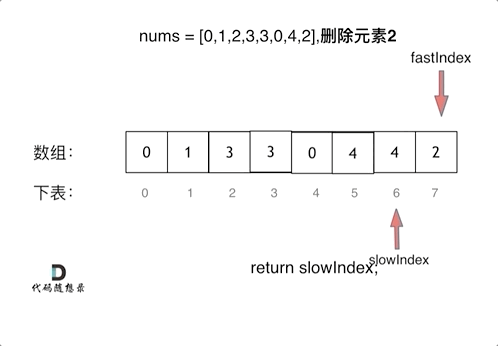
什么是Kafka
Kafka是一个消息系统。它可以集中收集生产者的消息,并由消费者按需获取。在Kafka中,也将消息称为日志(log)。
一个系统,若仅有一类或者少量的消息,可直接进行发送和接收。
随着业务量日益复杂,消息的种类和数量日益庞大,就需要一个专门的消息系统来进行消息的采集和获取,这就是kafka的初衷。
例如,张三决定提供消息服务。开始用户只有几个,于是张三有了消息就直接报告给这几个用户。但随着订阅人数以及消息种类的增多,张三无力将消息准确及时地送给这么多人,于是张三就专门搞了个店铺,一有消息就分门别类地放在店铺中。订阅者只需要按自己订阅的种类主动来取就是了。这个发布与订阅的设计,就是Kafka。
当然,Kafka除了负责消息中转功能,还提供了限流的能力:每次只能N个人到店铺里取消息,若店铺满了,那么店铺外面的人就等着,直到店铺里出来1个人,这样就可以进去1个人取消息。
基本概念
生产者、消费者和Broker
- 生产者:Producer,消息的提供者。当其有消息时,就为消息设置标签属性,然后发给Kafka。
- 消费者:Consumer,消息的消费者。消费者定期去向Kafka主动获取数据。
- Broker:一台或者多台Kafka服务器称之为Broker,即缓存代理。Kafka的一个Broker接收到生产者的消息后会将消息保存在磁盘上;同时Kafka会响应消费者的消息获取请求,将消息取出交给消费者。
多个Broker组成Kafka集群,可进行互备。同时有一个Broker负责充当控制器的角色。
Kafka存储的消息
一条消息的组成有4部分:主题+分区+键+键值。
- 主题:Topic,就是消息的类别。例如一个购物网站,Kafka接收到的消息,有的是商品查询消息,有的是咨询消息,有的是购物消息,等等。
- 分区:Partition,主题内部的队列。例如,有3台服务器负责商品查询消息主题,则可按地区对这3台服务器进行划分,每台维护一个地区的商品查询消息队列,即设置3个分区。当消费者拉取消息时,可由消费者指定从哪个分区来取。1个主题默认有1个分区。
- 键和键值:每一条消息都要设置键和该键的值。可理解为消息的
id字段和id值。
当生产者提供消息时,一定是带有Topic和Partition信息的。Topic一定是人为指定。但Partition的值需视情况而定:
- 人为指定Partition。
- 不指定Partition,但给定了数据key值,则分区器可对key值取Hashcode,自动计算Partition。
- 不指定Partition,且未给定数据key值,则直接轮循Partition。(默认方案)
- 自定义Partition策略。
消费者组Consumer Group
实际生产中,对于同一个购物消息Topic,不同的消费方都要使用这同一份数据,但其目的不同:A想要用这份数据进行购物人数的统计;B想要使用这份数据进行销售总额的计算;C想要使用这份数据进行畅销商品的排序,等等。A、B、C所应用的场景不同。
对于不同的应用场景,使用消费者组来进行业务的隔离。设有3个消费者组,则同一条消息最多被这3个消费者组各拉取一次。
一个Topic下有多个Partition,一个消费者组内有多个Consumer。真正建立关联的是具体的Partition和Consumer。1个Partition可被多个Consumer关联;1个Consumer可关联多个Partition。但是有具体的条件:
- 同一个消费者组下的Consumer,不能共享同一个Partition。这就意味着对于1个Topic而言,1个Partition只会与其下的1个Consumer建立关联。
- 对于不同的消费者组,可以共享同一个Partition。例如针对一个具体的Partition,有2个消费者组,则其下都可以有1个Consumer与该Partition建立关联。
- 对于一个具体的Consumer,可以与任意个Partition建立关联,无论这些Partition是否属于同一个Topic。只要不与同组下的Consumer冲突即可。
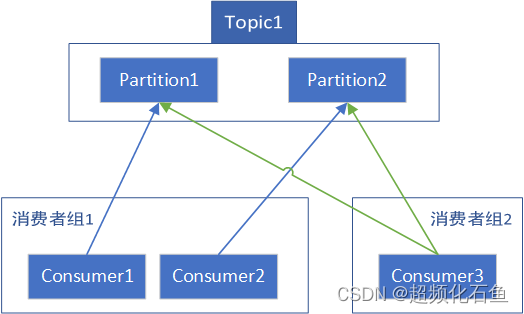
如上,图中每个Partition的每个关联都是与不同分组下的Consumer建立的,合法。
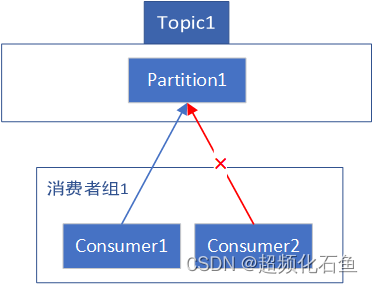
如上,图中Partition1的2个关联是与同属于分组1的Consumer1和Consumer2建立的,非法。
还要注意一点:一个消费者组下的所有Consumer合起来,一定可以消费一个或多个Topic下的所有Partition。
均衡分配
Kafka在自动分配资源时会遵循上述的原则,即:Kafka在一个Partition上不允许并发,1个Partition只能对应1个Consumer。
例如,有分组1下包含2个Consumer,对于订阅的Topic1,在自动分配下:
- 设Topic1有2个Partition。则每个Consumer会负责1个Partition。
- 设Topic1有3个Partition。则Consumer1会负责Partition1和Partition2,Consumer2会负责Partition3。
- 设Topic1有1个Partition。则Consumer1会负责Partition1,Consumer2会闲置。
综上可知,自动分配总是会尽量维持合理的均衡分配。
- 1个partition只能被1个Consumer负责。Consumer数量比partition多会造成Consumer浪费。
- 1个Consumer可以同时负责多个Partition。但为了确保同一个Topic下的多个Partition被均匀地拉取消息,Partition数量应为Consumer数量的整数倍。
- 1个Partition被1个Consumer负责,会确保按索引从小到大顺序读取,不会乱序。
- 如果发生Broker、Consumer、Partition数量的增减,会导致rebalance(再平衡),即重新为所有Consumer分配partition。
然而,均衡分配是Kafka自动分配所遵循的原则。在人为分配下,该原则是可以被打破的。但打破均衡分配原则可能会导致问题,具体可参考下文。
offset
消息放入Partition中是有顺序的,类似一维数组的索引。因此每条消息都是有偏移量(offset)的。每条消息的偏移量唯一。偏移量不断递增,不会因前面的消息删除而重置。故而对一个Partition指定offset,一定可定位唯一的消息。
消息是否被拉取与消息的删除并无直接关联,消息的拉取和删除是分开的两套逻辑。因此对于一个Consumer,需要记录拉取消息的进度,即offset。offset指向下一条要拉取的消息。
Consumer根据offset来拉取一个Partition中的消息时,一定是顺序的。即先拉取Partition[0]消息,再拉取Partition[1]消息。若Partition[0]消息未拉取,不能拉取后面的消息。同时,一个消费者只能拉取同一条消息1次,不能被重复拉取。
同一个Partition可被多个不同消费者组的Consumer关联。因此消费进度offset不能由Partition负责。但实际上消费进度也不是由Consumer负责,而是由消费者组负责。1个消费者组会为1个Partition维护1个offset。
offset并非存储在消费者组中,而是存储在Kafka中。Kafka为这些进度信息专门设置了一个名为__Consumer_offsets的Topic。当Consumer要拉取消息时,先从该处获取offset信息。
之所以这样做是因为可能发生再平衡。一旦发生再平衡,那么原Partition与Consumer的关联就可能被打乱。采用该方案后消息的消费就能按原进度继续执行。
举个例子:
- A组的Consumer1和B组的Consumer3同时关联了同一个Partition1。
- A组关于Partition1的
offset为1。此时Consumer1需要拉取Partition1的消息,则先取出A组关于Partition1的offset,得到1,然后拉取Partition1[1]的消息。消费后提交offset=2,于是A组关于Partition1的offset变更为2。 - 同一时间,B组关于Partition1的
offset为5。此时Consumer3需要拉取Partition1的消息,则先取出B组关于Partition1的offset,得到5,然后拉取Partition1[5]的消息。消费后提交offset=6,于是B组关于Partition1的offset变更为2。
人为指定
按照设计:
- 一个Partition不能被同一消费者组下的多个Consumer共享。
- Consumer拉取Partition中的消息时一定是顺序的。
然而,实际开发中Consumer的各项属性均可人为指定,包括从哪个Partition来取,以及设置offset。此时Kafka也依然会正常运作,但会造成业务问题。
例如,设消费者组1的offset为6,其下有Consumer1和Consumer2,都手动指定了相同的Topic及Partition:
- Consumer1和Consumer2同时使用消费者组的offset拉取消息,都拉取到了索引为6的同一个消息。
- Consumer1和Consumer2会在两个线程中独立处理,因此是同步的。故而到底是哪个Consumer的处理会早完成是随机的。这里假设Consumer1的处理比Consumer2的处理要提前完成。
- 当Consumer1提交offset时,由于其拉取的消息offset为6,因此Consumer1提交的消费者组offset值会在其基础上+1,为7。此时消费者组的offset会由6更新为7。
- 当Consumer2提交offset时,由于其拉取的消息offset为6,因此Consumer2提交的消费者组offset值会在其基础上+1,为7。此时消费者组的offset会由7更新为7。Consumer2与Consumer1消费的消息相同,造成重复消费。
再例如,设消费者组1的offset为6,Consumer提交offset时,本应令其+1变为7:
- 忘记提交offset,这样下次拉取消息依然是offset为6的消息。
- 提交的offset为6,这样下次拉取消息依然是offset为6的消息。
- 提交的offset为8,这样下次拉取消息是offset为8的消息。
这样会导致消息重复消费、消息丢失(调过了正确的消息,导致后续无法再拉取)等问题。
因此,若非必要,不要人为指定。
消息消费与offset提交时机
人为指定条件下,Consumer拉取到消息后,有2种情况:
- 先消费消息,再提交offset。
- 先提交offset,再消费消息。
若先消费消息,再提交offset,可能出现的一个问题是:如果消费者消费完成,但尚未提交offset时出现了异常,则消费者组的offset没有被变更,下次消费还是会拉取到本次的消息,从而造成重复消费。
如果能将消息消费与offset提交绑定在一个原子操作中则无问题。
若先提交offset,再消费消息,可能出现的一个问题是:如果offset正常提交后,在消费消息的过程中出现了异常,则下次拉取到的是下一条消息,这就造成了消息丢失。
消息的清除
Kafka的消息按策略进行清理,与消息是否已拉取无关。
通常清除策略有2个:
- 按消息的保留时间。若一条消息在Kafka中的保存超过了指定时间就会被清理。
- 按Topic存储文件的大小。若Topic存储文件超出了一定的阈值,则按消息的时间从前往后清理。
- 按分段起始偏移量。消息存储在Partition中,分为多个段。每个段的开始索引称为
baseOffset。同时Kafka会维护一个最小可访问索引logStartOffset。当一个段的baseOffset小于logStartOffset时,该段就会放入删除列表中。
Kafka会启动一个线程定期来进行检测与清除工作。
清除工作是Kafka服务执行的,与生产者和消费者无关。若要调整相关的设置,需要修改Kafka根目录下 /config/server.properties 的配置。