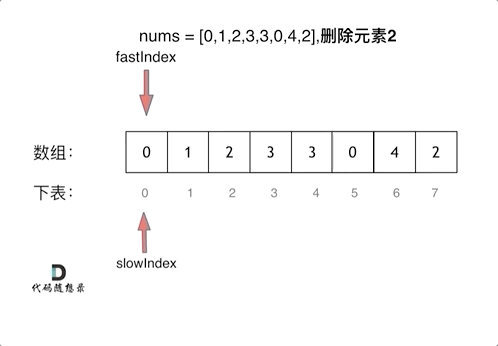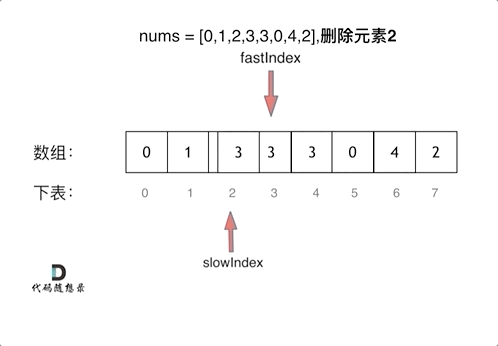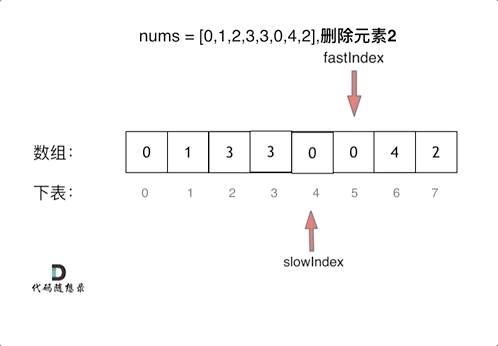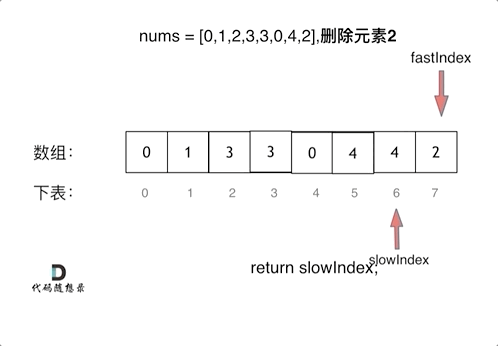
基频估计算法 F0 estimate methods
估计F0的方法可以分为三类:基于时域、基于频域、或混合方法。本文详细介绍了这些方法。
所有的算法都包含如下三个主要步骤:
1.预处理:滤波,加窗分帧等
2.搜寻:可能的基频值F0(候选值)
3.跟踪:选择最可能的F0轨迹(这很重要,因为每个时刻我们都有几个候选轨迹)
基于时域
首先,基本情况。在应用时域方法之前,对信号进行滤波以只留下低频。设置阈值:最小频率和最大频率,例如75 ~ 500hz。F0估计仅对谐波。那些有停顿或噪声斑点的部分不仅没有观察意义,还可能改变相邻帧,并在应用插值或平滑时导致错误。所选帧的长度使其至少包含三个基频周期。
自相关
主要的算法就是自相关,随后又出现了一系列在此基础上的改进算法。自相关方法非常简单:计算自相关函数,然后定义它的第一个最大值,该最大值将反映信号中最显著的频率成分。那么,在使用自相关的问题是什么,为什么第一个最大值不能总是对应所需的频率?即使在高质量录音的近乎完美的条件下,由于信号的复杂结构,算法也容易出现错误。在接近真实的情况下,错误的数量急剧增加。此外,在最初质量较差和有噪声的录音中,我们可能会面临缺乏所期望的峰值等问题。
YIN算法
尽管自相关算法存在错误,但由于其基本的简单性和逻辑性,该方法较受欢迎。它被广泛应用于包括YIN在内的许多算法中。YIN这个名字本身指的是自相关的便利和不准确之间的平衡:YIN这个名字来自东方哲学的阴和阳,暗指它所涉及的自相关和抵消之间的相互作用。
YIN的创造者试图解决这个问题。他们改变的第一件事是使用累积平均归一化差分函数,该函数被认为可以降低信号对幅度调制的灵敏度,并使峰值更加明显。
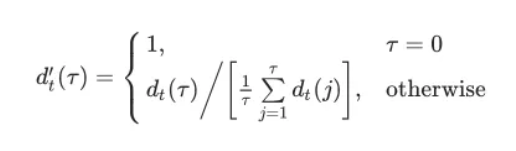
YIN试图避免当窗口函数的长度不能被波动周期整除时出现的错误。为此,应用抛物线插值来近似最小值。在音频信号处理的最后一步,使用最佳局部估计函数来避免值的快速波动。(很难说是好是坏。)
基于频域
当我们谈到频域时,最突出的方面似乎是信号的谐波结构。换句话说,谱峰的频率可以被F0整除。在倒谱分析的帮助下,您可以将这种周期性模式转换为一个明显的峰值。倒谱是估计功率谱对数的傅里叶变换(FFT)。倒谱峰对应于频谱中最具周期性的分量。
混合法
有一个相当有说服力的名字YAAPT Yet Another algorithm of Pitch Tracking。它被归类为混合,因为它同时使用时间和频率数据。
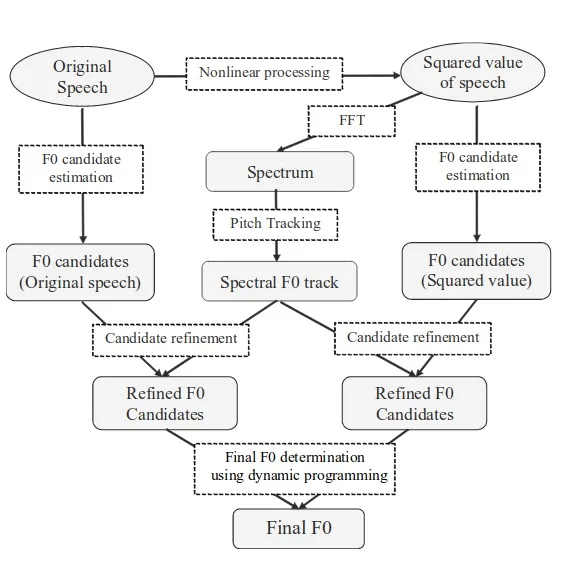
YAAPT包括几个阶段,首先预处理开始。在这一阶段,初始信号的值被平方。这一步与YIN中的累积平均归一化差函数的目标相同:放大和恢复自相关的阻塞峰值。两个版本的信号都经过滤波,通常在50-1500 Hz或50- 900 Hz的频谱范围内。
然后,根据变换后信号的频谱,计算出F0的基本轨迹。利用谱谐波相关函数(Spectral Harmonics Correlation,SHC)确定F0的候选值。
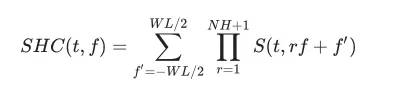
其中S(t,f)是第t帧和频率f的幅度频谱,WL是窗口的长度,单位为Hz, NH是谐波的数量(本文作者建议使用前三个谐波)。
基于功率谱对有音-无音帧进行了定义。然后,考虑音高加倍/音高减半的可能性,寻找最优轨迹。
然后,对于初始信号和转换信号,用归一化交叉相关(Normalized Cross Correlation,NCCF)来确定F0的候选信号,而不是自相关。
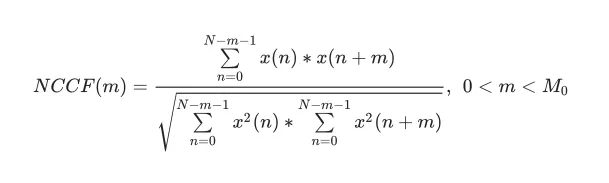
下一步是评估所有可能的候选值并计算他们的权重。候选的权重不仅取决于NCCF的振幅峰值,还取决于它们与F0轨迹的接近程度,这也是由频谱决定的。因此,频域被认为是相当稳定的。
对于所有剩余的候选值对,转移成本矩阵计算转移成本,以找到最佳的可能轨迹。
例子
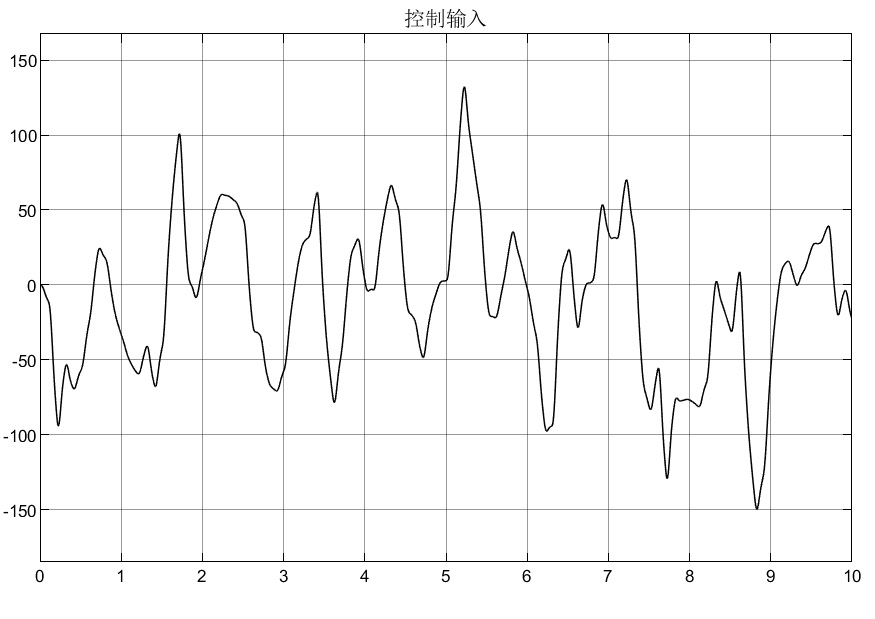
我们选取了几段男女声音的片段,既有中性的声音,也有带有情感色彩的声音,并将它们组合在一起。让我们看一下信号的频谱图,它的强度(橙色)和F0(蓝色)。你可以在Praat用Ctrl+O(打开从文件中读取)打开它,然后按查看&编辑。
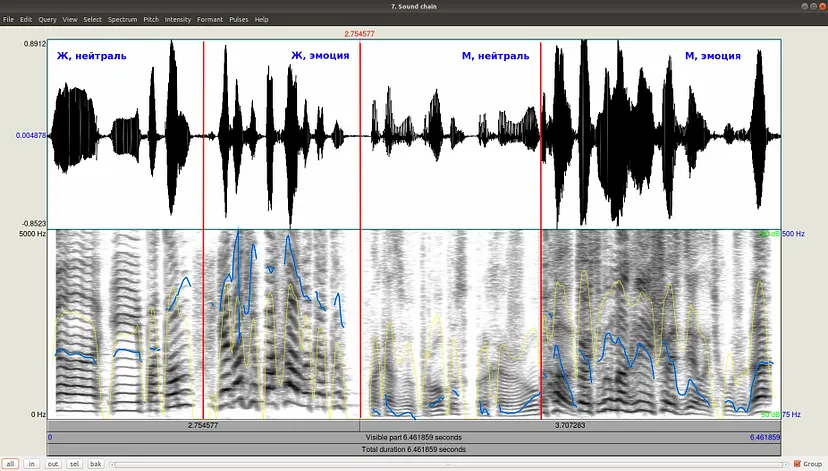
从录音中可以清楚地看出,男性和女性在带感情说话的音调都更高。此外,男性情感言语的F0与女性的F0相似。
跟踪Tracking
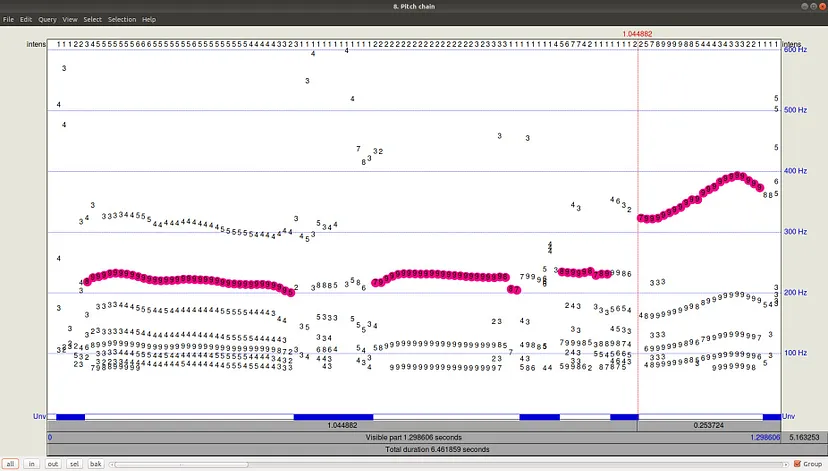
在菜单中选择Analyze periodicity to Pitch (ac),通过自相关估计F0。设置窗口允许为F0候选估计设置3个参数,以及为在所有候选中构建最可能的F0轨迹的寻径算法设置6个参数。
路径查找器结果可以通过单击OK和View &编辑Pitch文件。从图中可以看出,除了选定的轨道之外,还有其他频率较低的候选轨道。
让我们以两个提供音高跟踪的库为例。首先是aubio,其中默认算法是YIN。并利用YAAPT算法进行amfm_分解。将Praat中的F0值插入到一个单独的文件(PraatPitch.txt)中(您可以手动操作:选择音频文件,单击“查看和编辑”,选择整个文件,然后在上面的菜单中选择“Pitch-Pitch列表”)。
现在比较这三种算法(YIN, YAAPT, Praat)的结果。
import amfm_decompy.basic_tools as basic
import amfm_decompy.pYAAPT as pYAAPT
import matplotlib.pyplot as plt
import numpy as np
import sys from aubio
import source, pitch
# load audio
signal = basic.SignalObj('/home/eva/Documents/papers/habr/media/audio.wav')
filename = '/home/eva/Documents/papers/habr/media/audio.wav'
# YAAPT pitches
pitchY = pYAAPT.yaapt(signal, frame_length=40, tda_frame_length=40, f0_min=75, f0_max=600)
# YIN pitches
downsample = 1
samplerate = 0
win_s = 1764 // downsample # fft size
hop_s = 441 // downsample # hop size
s = source(filename, samplerate, hop_s)
samplerate = s.samplerate
tolerance = 0.8
pitch_o = pitch("yin", win_s, hop_s, samplerate) pitch_o.set_unit("midi")
pitch_o.set_tolerance(tolerance)
pitchesYIN = []
confidences = []
total_frames = 0
while True:
samples, read = s()
pitch = pitch_o(samples)[0]
pitch = int(round(pitch))
confidence = pitch_o.get_confidence()
pitchesYIN += [pitch]
confidences += [confidence]
total_frames += read
if read < hop_s:
break
# load PRAAT pitches
praat = np.genfromtxt('/home/eva/Documents/papers/habr/PraatPitch.txt', filling_values=0)
praat = praat[:,1]
# plot
fig, (ax1,ax2,ax3) = plt.subplots(3, 1, sharex=True, sharey=True, figsize=(12, 8))
ax1.plot(np.asarray(pitchesYIN), label='YIN', color='green')
ax1.legend(loc="upper right")
ax2.plot(pitchY.samp_values, label='YAAPT', color='blue')
ax2.legend(loc="upper right")
ax3.plot(praat, label='Praat', color='red')
ax3.legend(loc="upper right") plt.show()
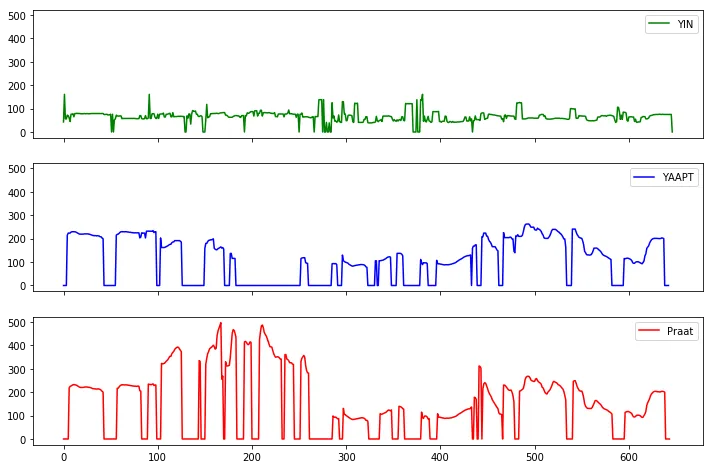
正如我们所看到的,在默认参数下,YIN不如Praat,显示出一个非常平坦的轨迹,相对于Praat的值更低。此外,它完全失去了男声和女声之间的过渡,以及情感和非情感话语之间的过渡。
YAAPT在女性情感言语的高音测试中失败,但总体上表现出较好的效果。我们不能肯定地说为什么它的效果更好,但我们可以假设它与从三个来源提取候选值以及比YIN更准确地计算他们的权重有关。
将Praat作为语音处理的标准算法(因为它在研究人员中被广泛使用),我们可以得出结论,YAAPT比YIN更可靠和准确,尽管我们的测试对它来说相当困难。