"假如可以让音乐停下来"
一、unordered_map\unordered_set简介
在C++98中,STL底层提供了以红黑树封装的关联式容器map\set,其查询效率可以达到LogN(以2为底)。而在C++11中,STL又提供了unordered(无序)容器,其使用方式与map\set类似,但其底层不是红黑树的数据结构,而是一种哈希结构。
unordered_set\unordered_map:
①unordered_set的存储设计为<Key>模型,而unordered_map存储的设计为<Key,Value>模型。
②它们都是以Key值 标识一个位置的映射值。
③它们不同于map、set可以顺序遍历,而是一种无序的存储结构。
④unordered_map容器通过key访问单个元素要比map快。但是,如果让哈希结构的unordered_map去查询一段子类集的范围,效率就不如map了。
⑤unordered_map只提供了前向迭代器。
二、哈希结构
Hash,是把任意长度的输入(又叫做预映射pre-image)通过"散列算法"( 哈希函数)变换成固定长度的输出,该输出就是 散列值。这种转换是一种压缩映射,也就是,散列值的空间通常远小于输入的空间,不同的输入可能会散列成相同的输出,所以不可能从散列值来确定唯一的输入值。简单的说就是一种将任意长度的消息压缩到某一固定长度的消息摘要的函数。 取自这里
哈希其实就是一种映射性的数据结构。如何设计好哈希结构,跟我们怎样选择、设计哈希函数息息相关。
常见的哈希函数有以下几种:
1.直接定址法。取关键字或关键字的某个线性函数值为散列地址。即H(key)=key或H(key) = a·key + b,其中a和b为常数(这种散列函数叫做自身函数)
2.平方取中法。取关键字平方后的中间几位作为散列地址。
3.随机数法。选择一随机函数,取关键字作为随机函数的种子生成随机值作为散列地址,通常用于关键字长度不同的场合。
4.除留余数法。取关键字被某个不大于散列表(空间)表长m的数p除后所得的余数为散列地址。
即 H(key) = key MOD p,p<=m。不仅可以对关键字直接取模,也可在折叠、平方取中等运算之后取模。对p的选择很重要,一般取素数或m,若p选的不好,容易产生碰撞。 取自这里
我们举一个小小的例子:
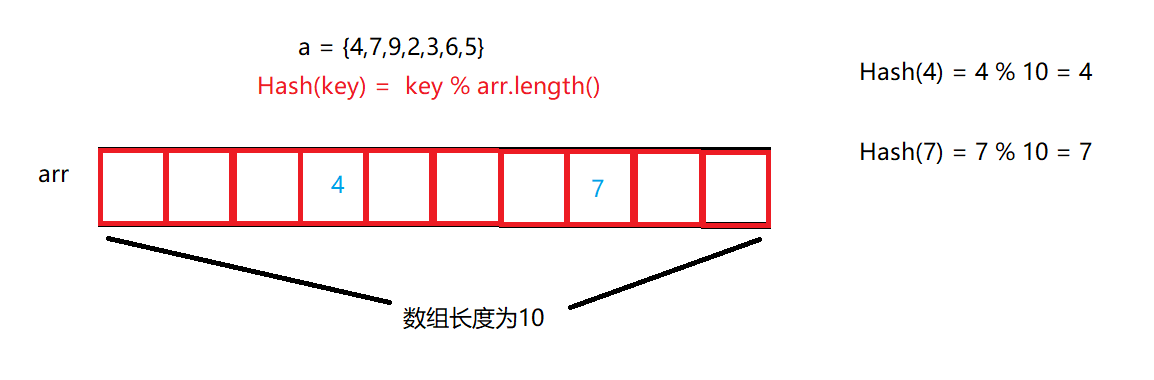
三、底层结构
多的不谈,我们现在来看看封装。不过在这之前,我们先来看看STL的源码库。
(1)HashData

HashData同上篇讲的红黑树结点Value一样,它们根本不关心你到底是传入的<Key,Value>模型,还是就是<Key>模型。
template<class Value>
struct HashTable_node
{
HashTable_node<Value>* _next;
Value _data;
};(2)HashTable1
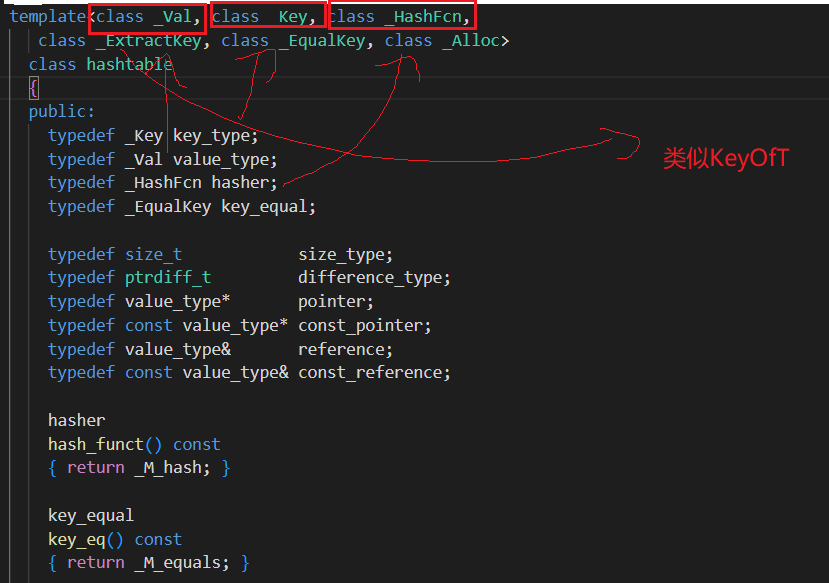
HashTable中的模板参数,与RBTree的模板参数类似,都是Key与Value。不过值得关注的是,哈希结构存储时,需要上层传入"哈希函数"。毕竟只有整数才能取模,如果上层的key是字符串类型呢??我们, 又该如何做?
哈希函数:
我们如何处理字符串类型的哈希函数结构?
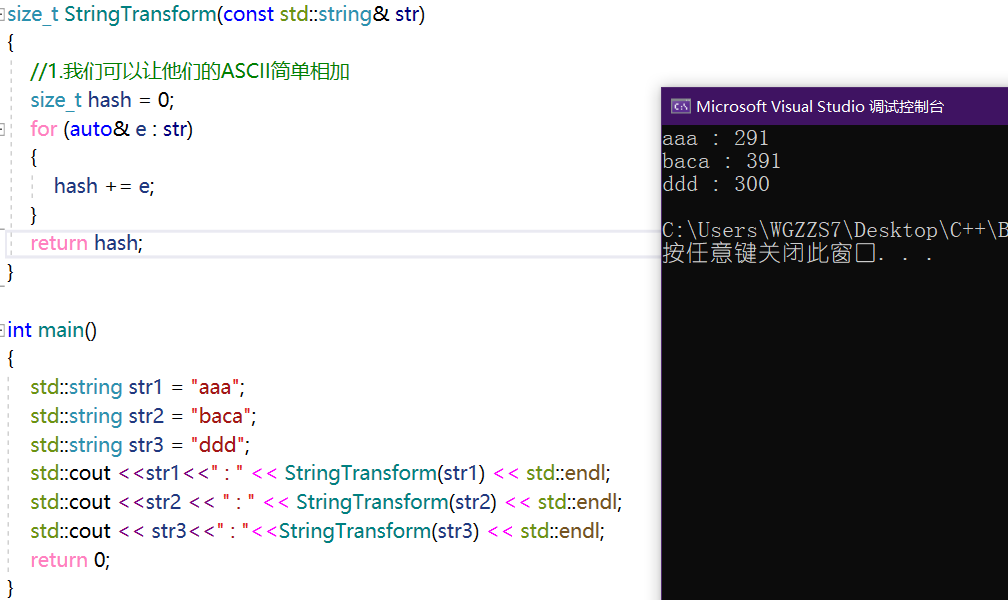
但是如果子串字母顺序不一样,则映射到同一个值(这个也叫做"哈希冲突")。

关于字符串的哈希函数,有很多前辈们都提供了一定的方法函数。
我们就随便借一个来试试(更多的字符串哈希函数)。
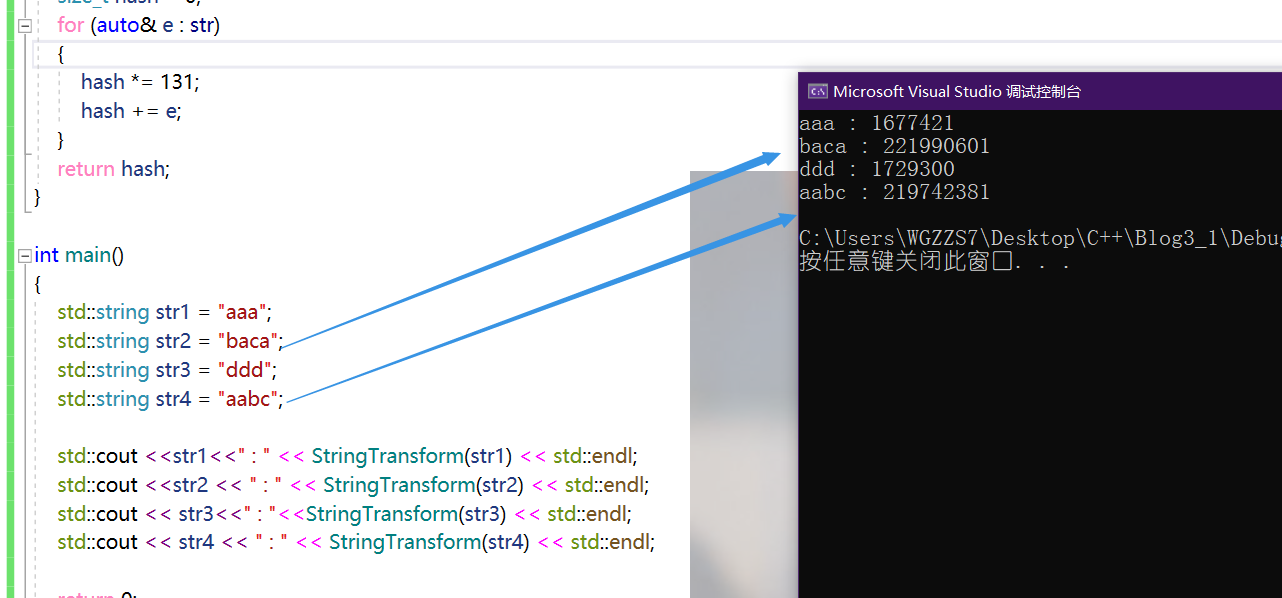
template<class K>
struct HashFunc
{
size_t operator()(const K& key)
{
return key;
}
};
//模板特化
template<>
struct HashFunc<std::string>
{
size_t operator()(const std::string& str)
{
size_t hash = 0;
for (auto& e : str)
{
hash *= 131;
hash += e;
}
return hash;
}
};毕竟字符串等不是整数的类型是作为Key时的少数,大多数都是直接可以去key作为整数的取模。
我们就可以简单地搭一下HashTable的框架。
template<class Value,class Key,class KeyOfValue,class Hash>
class HashTable
{
public:
typedef HashTable_node<Value> Node;
private:
std::vector<Node*> _tables; //哈希桶
size_t n = 0; //有效个数
}; (3)迭代器
同样,我们来看看源码。
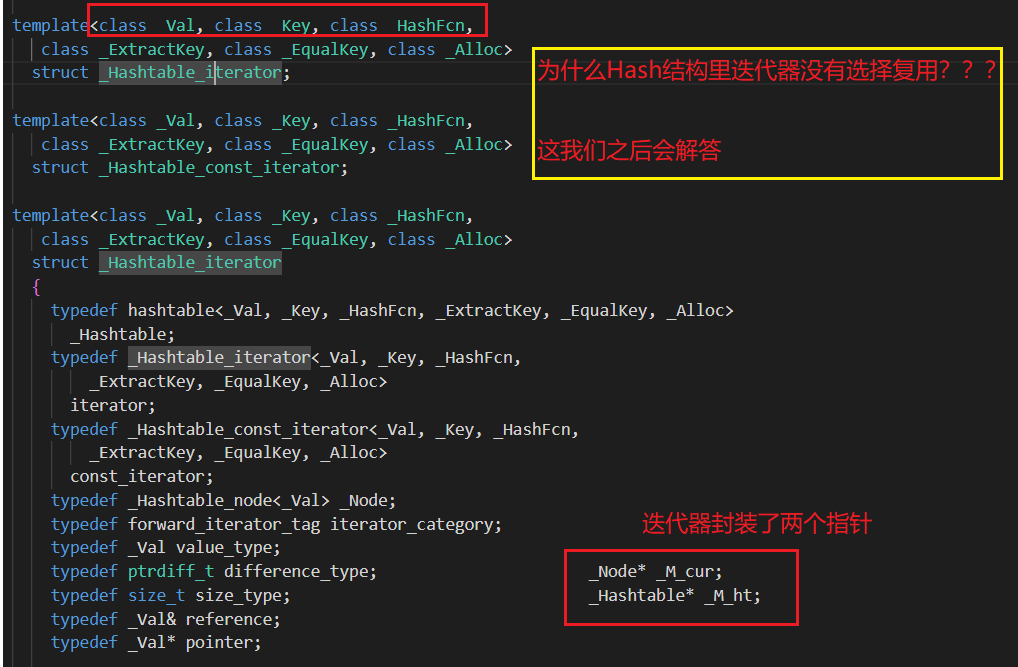

opeartor++;
这样,我们也就完成了一个简单的迭代器。
template<class Value, class Key, class KeyOfValue, class Hash>
class HashTable;
template<class Key,class Value,class KeyOfVal,class Hash>
struct __HashIterator__
{
typedef HashTable_node<Value> Node;
typedef HashTable<Key, Value, KeyOfVal, Hash> HT;
HT* _ht;
Node* _node;
KeyOfVal kot;
Hash hf;
typedef __HashIterator__<Key, Value, KeyOfVal, Hash> Self;
__HashIterator__(Node* node,HT* ht)
:_node(node),
_ht(ht)
{}
Value& operator*()
{
return _node->_data;
}
Value* operator->()
{
return &_node->_data;
}
bool operator!=(const Self& s)const
{
return _node != s._node;
}
bool operator==(const Self& s)const
{
return _node == s._node;
}
//前向迭代器
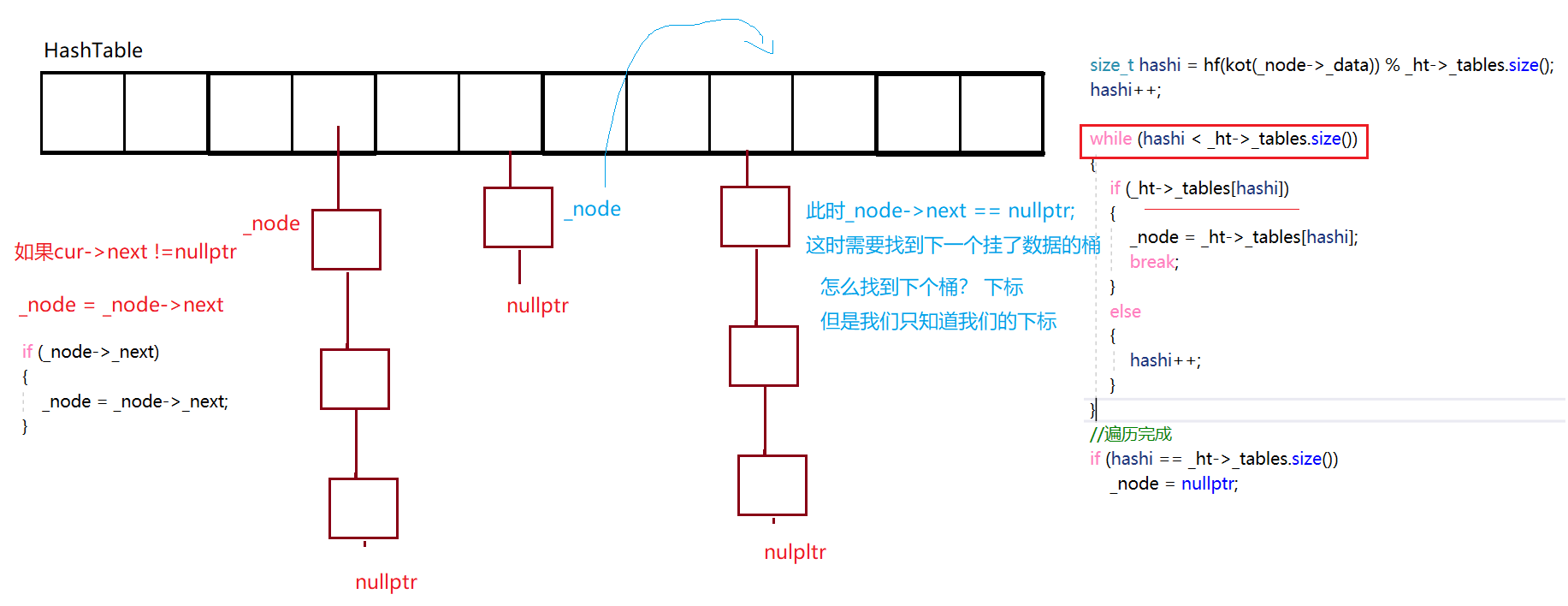
Self& operator++()
{
if (_node->_next)
{
_node = _node->_next;
}
else
{
size_t hashi = hf(kot(_node->_data)) % _ht->_tables.size();
hashi++;
while (hashi < _ht->_tables.size())
{
if (_ht->_tables[hashi])
{
_node = _ht->_tables[hashi];
break;
}
else
{
hashi++;
}
}
//遍历完成
if (hashi == _ht->_tables.size())
_node = nullptr;
}
return *this;
}
};
取自《STL源码剖析》
(4)HashTable2
迭代器:
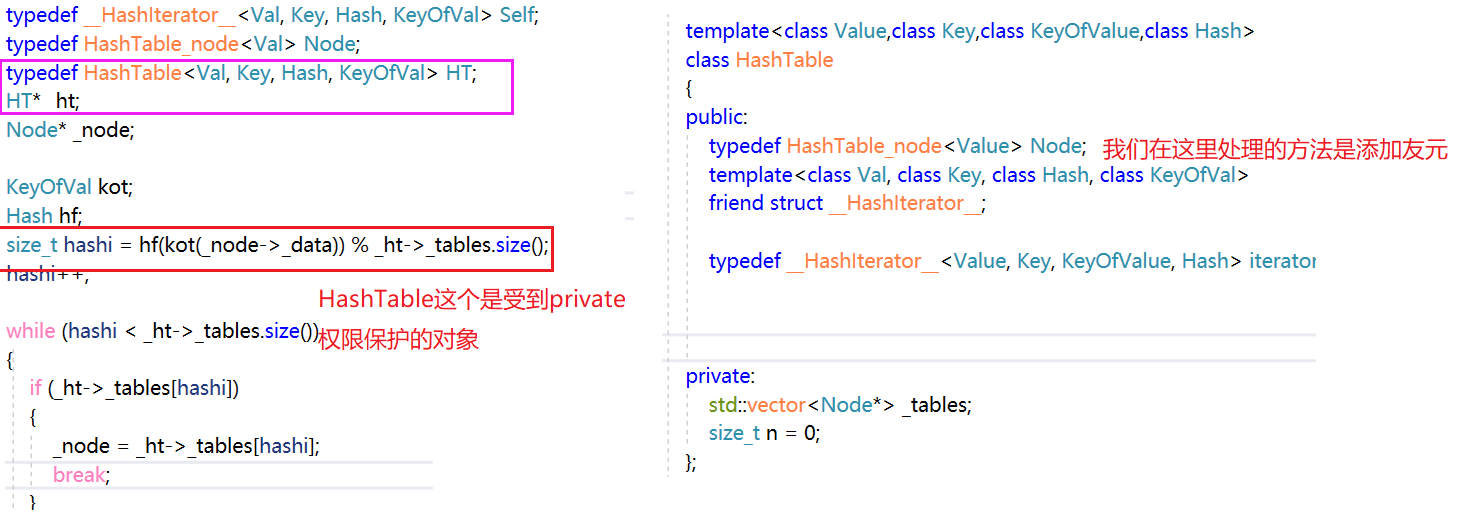
我们给原HashTable添入迭代器。
typedef __HashIterator__<Value, Key, KeyOfValue, Hash> iterator;
iterator begin()
{
//返回第一个非空的HashData
for (size_t i = 0;i < _tables.size();++i)
{
if (_tables[i])
{
return iterator(_tables[i], this);
}
}
return iterator(nullptr, this);
}
iterator end()
{
return iterator(nullptr, this);
}Erase\find:
iterator Find(const Key& key)
{
if (_n == 0) return end();
//Key下标
size_t hashi = Hash()(key) % _tables.size();
Node* cur = _tables[hashi];
while (cur)
{
if (KeyOfValue()(cur->_data) == key)
{
return iterator(cur, this);
}
else
{
cur = cur->_next;
}
}
return end();
}
bool Erase(const Key& key)
{
size_t hashi = Hash()(KeyOfValue()(key)) % _tables.size();
Node* cur = _tables[hashi];
Node* prev = nullptr;
while (cur)
{
if (KeyOfValue()(cur->_data) == key)
{
//1.头删
if (cur == _tables[hashi])
{
_tables[hashi] = cur->_next;
}
else
{
//2.中间删
prev->_next = cur->_next;
}
delete cur;
--_n;
return true;
}
else
{
//迭代
prev = cur;
cur = cur->_next;
}
}
return false;
}这些功能逻辑简单,实现起来不是很复杂。不解释。
Insert:
面对扩容问题:
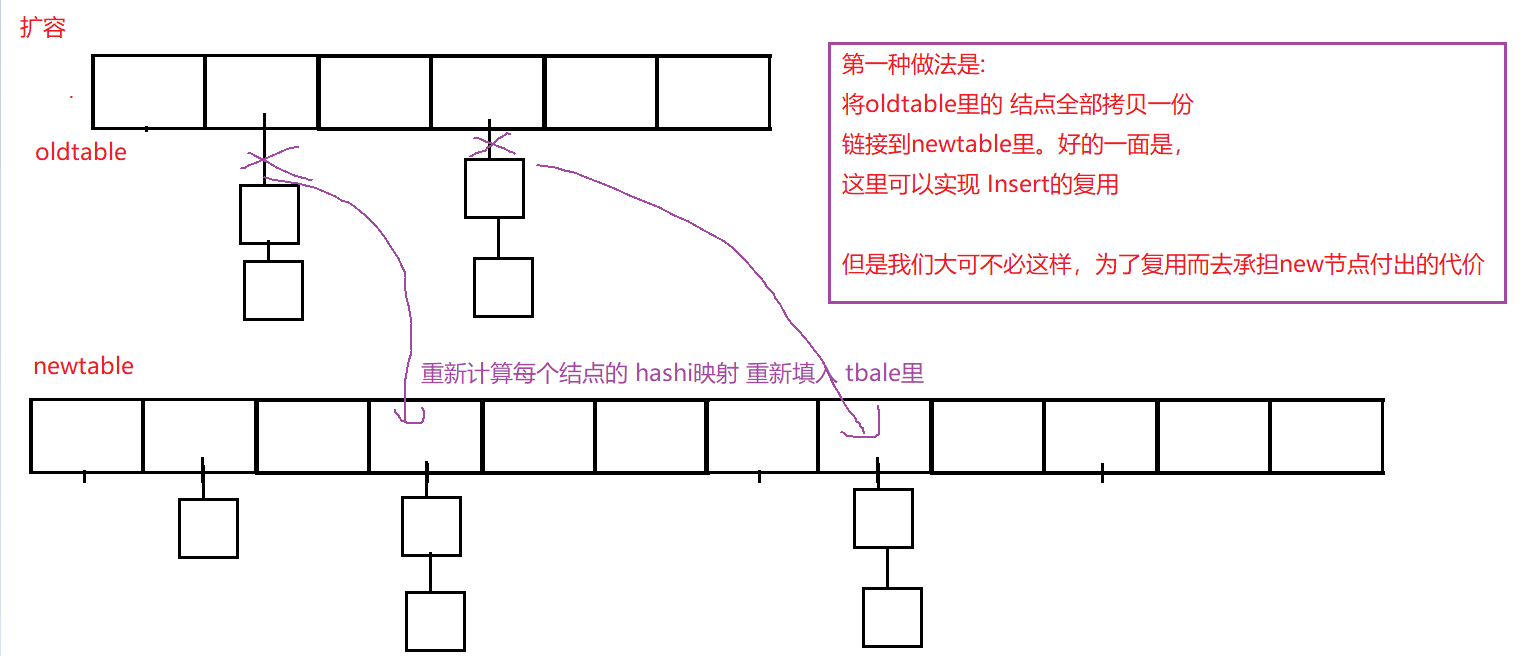
STL提供了一份素数表,用来开辟table的空间大小。

源码库:
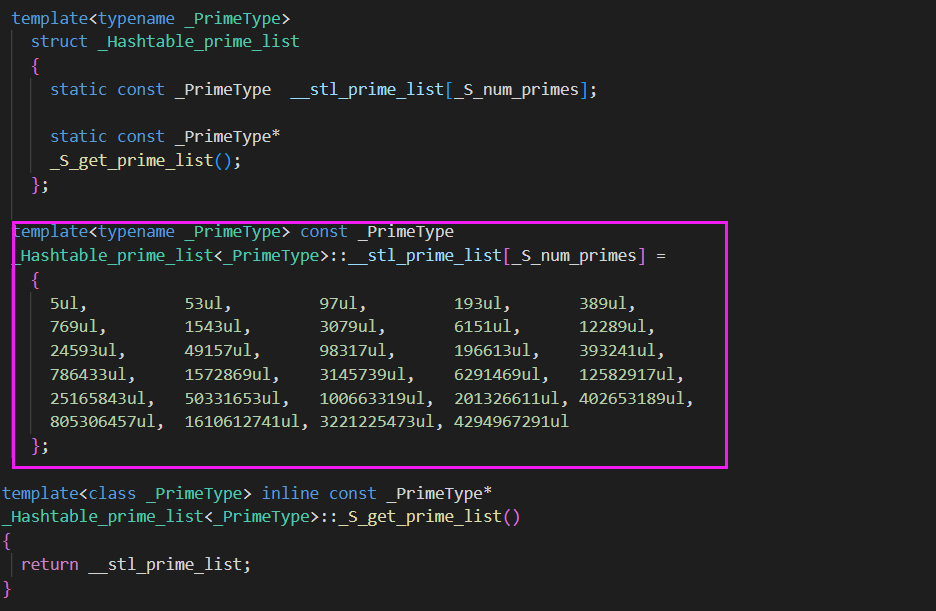
inline unsigned long __stl_next_prime(unsigned long n)
{
static const int __stl_num_primes = 28;
static const unsigned long __stl_prime_list[__stl_num_primes] =
{
53, 97, 193, 389, 769,
1543, 3079, 6151, 12289, 24593,
49157, 98317, 196613, 393241, 786433,
1572869, 3145739, 6291469, 12582917, 25165843,
50331653, 100663319, 201326611, 402653189, 805306457,
1610612741, 3221225473, 4294967291
};
for (int i = 0; i < __stl_num_primes; ++i)
{
if (__stl_prime_list[i] > n)
{
//返回 > n 的那next数组大小
return __stl_prime_list[i];
}
}
return __stl_prime_list[__stl_num_primes - 1];
}扩容:
//扩容
if (_n == _tables.size())
{
std::vector<Node*> newtable;
newtable.resize(__stl_next_prime(_tables.size(),nullptr);
//计算节点并拷贝
for (int i = 0;i < _tables.size();++i)
{
Node* cur = _tables[i];
//处理一个桶里的 链表
while (cur)
{
Node* next = cur->_next;
//重新计算hashi
size_t hashi = Hash()(KeyOfValue()(cur->_data)) % newtable.size();
//头插
cur->_next = newtable[hashi];
newtable[hashi] = cur;
cur = next;
}
_tables[i] = nullptr;
}
//交换
_tables.swap(newtable);
}插入:
std::pair<iterator, bool> Insert(const Value& data)
{
iterator it = Find(KeyOfValue()(data));
if (it != end())
{
return std::make_pair(it, false);
}
///..扩容
size_t hashi = Hash()(KeyOfValue()(data)) % _tables.size();
Node* newnode = new Node(data);
//头插
newnode->_next = _tables[hashi];
_tables[hashi] = newnode;
++_n;
return std::make_pair(iterator(newnode,this), true);
} 四、unordered_map\unordered_set封装
当把unordered_map\unordered_set底层的架子搭好后,我们现在可以来对它们进行封装了。
unordered_map;
template<class K,class V,class Hash = HashFunc<K>>
class unordered_map
{
struct MapOfKey
{
const K& operator()(const std::pair<K, V>& kv)
{
return kv.first;
}
};
public:
typedef typename dy_OpenHash::HashTable<K, std::pair<const K, V>, MapOfKey, Hash>::iterator iterator;
iterator begin()
{
return _ht.begin();
}
iterator end()
{
return _ht.end();
}
std::pair<iterator, bool> insert(const std::pair<K, V>& data)
{
return _ht.Insert(data);
}
V& operator[](const K& key)
{
//pair<iterator,bool> ret
auto ret = _ht.Insert(std::make_pair(key,V()));
return ret.first->second;
}
private:
dy_OpenHash::HashTable<K, std::pair<const K,V>, MapOfKey, Hash> _ht;
};unordered_set;
template<class K,class Hash = HashFunc<K>>
class unordered_set
{
struct SetOfKey
{
const K& operator()(const K& key)
{
return key;
}
};
public:
typedef typename dy_OpenHash::HashTable<K, K, SetOfKey, Hash>::iterator iterator;
iterator begin()
{
return _ht.begin();
}
iterator end()
{
return _ht.end();
}
std::pair<iterator, bool> insert(const K& key)
{
return _ht.Insert(key);
}
private:
dy_OpenHash::HashTable<K, K, SetOfKey, Hash> _ht;
};这里也不多解释,和Mapset差不多。
测试:
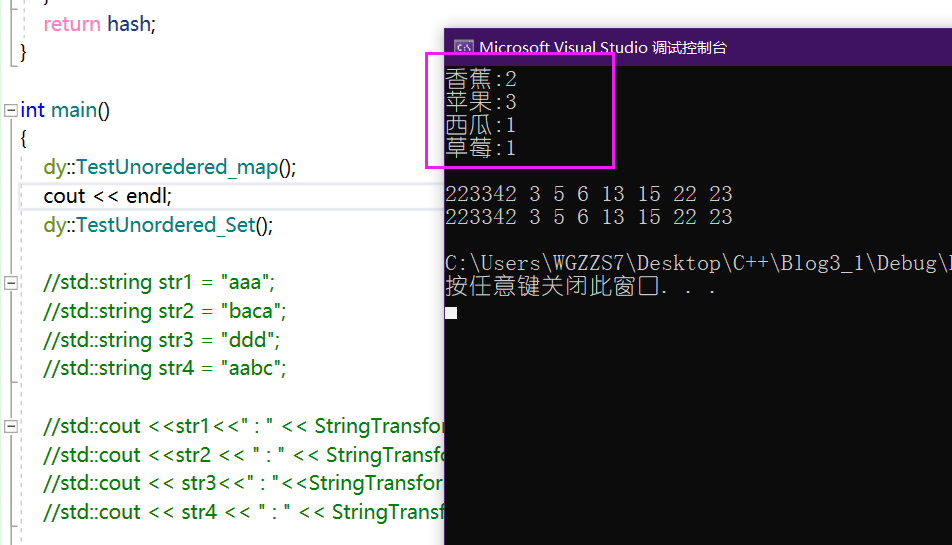
那么它们封装后的测试也能行得通。差不多最后的"工程"也就结束了。
最后留了一个小问题:
为什么unordered_map\unordered_set const迭代器没有复用普通迭代器?

本篇到此结束,感谢你的阅读。
祝你好运,向阳而生~