数据库设计遵循三大范式的理由:在面对复杂是数据库设计的时候,设计数据库要遵循一定的规则,有了一定的规范,这样就可以是自己看起来舒服。
1.第一范式(确保每列保持原子性)
第一范式主要是保证数据表中的每一个字段的值必须具有原子性,也就是数据表中的每个字段的值是不可再拆分的最小数据单元
2.第二范式(确保表中的每列都和主键相关)
数据表里的每一条数据记录,都是可唯一标识的,而且所有的非主键字段,都必须完全依赖主键,不能只依赖主键的一部分。
第二范式要求实体的属性完全依赖主关键字,如果存在不完全依赖,那么这个属性和主关键字的这一部分就应该分离处理形成一个新的实体,新实体和原来实体之间是一对多的关系
自己理解:主键可以是一个也可以是多个,但是必须要所有的主键才能确定一个非主键的属性,这样才满足第二范式
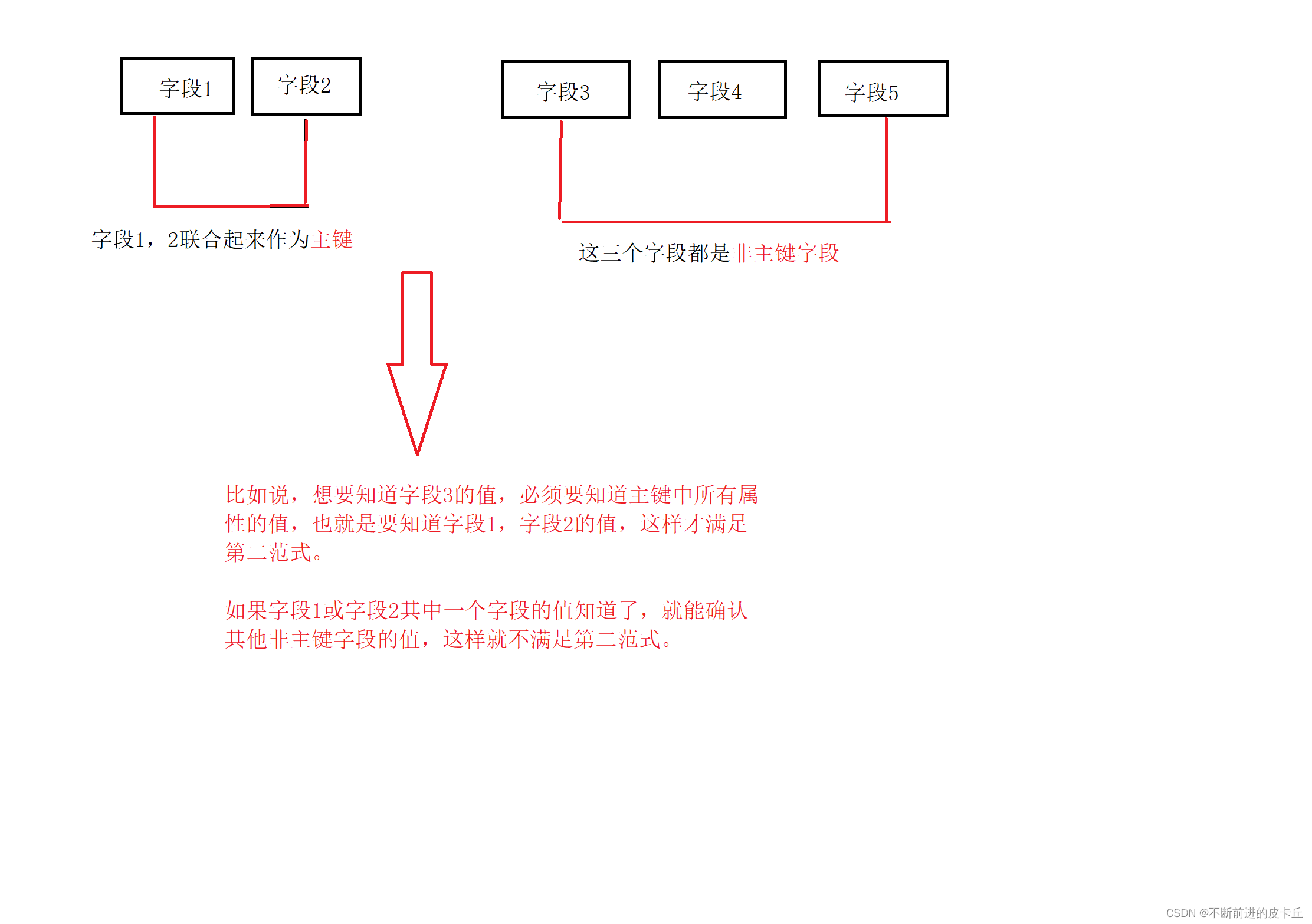
3.第三范式(确保每列都和主键列直接相关,而不是间接相关)
数据表中的每一个非主键字段都和主键字段直接相关
也就是说数据表中的所有非主键字段不能依赖于其他非主键字段
这个规则的意思是所有非主属性之间不能有依赖关系,它们是互相独立的
自己的理解:所有的非主键字段都可以由主键直接决定,并需要依赖传递。
范式的优缺点
优点:
数据的标准化有助于消除数据库中的数据冗余
第三范式通常被认为在性能,扩展性和数据完整性方面达到了最好的平衡
缺点:
降低了查询效率,因为范式等级越高,设计出来的表就越多,进行数据查询的时候就可能需要关联多张表,不仅代价昂贵,而且可能会使得一些索引失效
范式只是提出设计的标标准,实际设计的时候,我们可能为了性能和读取效率违反范式的原则,通过增加少量的冗余或重复的数据来提高数据库的读取性能,减少关联查询,实现空间换时间的目的
参考博客:数据库的三大范式_数据库三大范式_不断前进的皮卡丘的博客-CSDN博客









![【项目设计】高并发内存池(三)[CentralCache的实现]](https://img-blog.csdnimg.cn/96c9976b1cc3481586600144cb247250.png)