一、作者
Xie Jun, Wang Yuzhu, Chen Bo, Zhang Zehua, and Liu Qin
College of Information and Computer, Taiyuan University of Technology, Jinzhong, Shanxi
二、背景
在应用于方面情感分析的深度神经网络中,序列型神经网络能捕获句子的上下文语义信息,但是对于词语之间的远距离依赖关系无法进行有效学习;而图神经网络虽然可以通过图结构聚合更多的属性依赖信息,但会忽略有序词语间的上下文语义联系。
三、创新点
作者将 BiLSTM 与 GCN 进行了集合,提出了一种基于双指导注意力网络的方面级情感分析模型,该模型通过交互指导注意力机制,同时关注到文本的上下文信息和远距离依赖信息,提高了模型对于方面级情感特征表示的学习能力。
四、具体实现
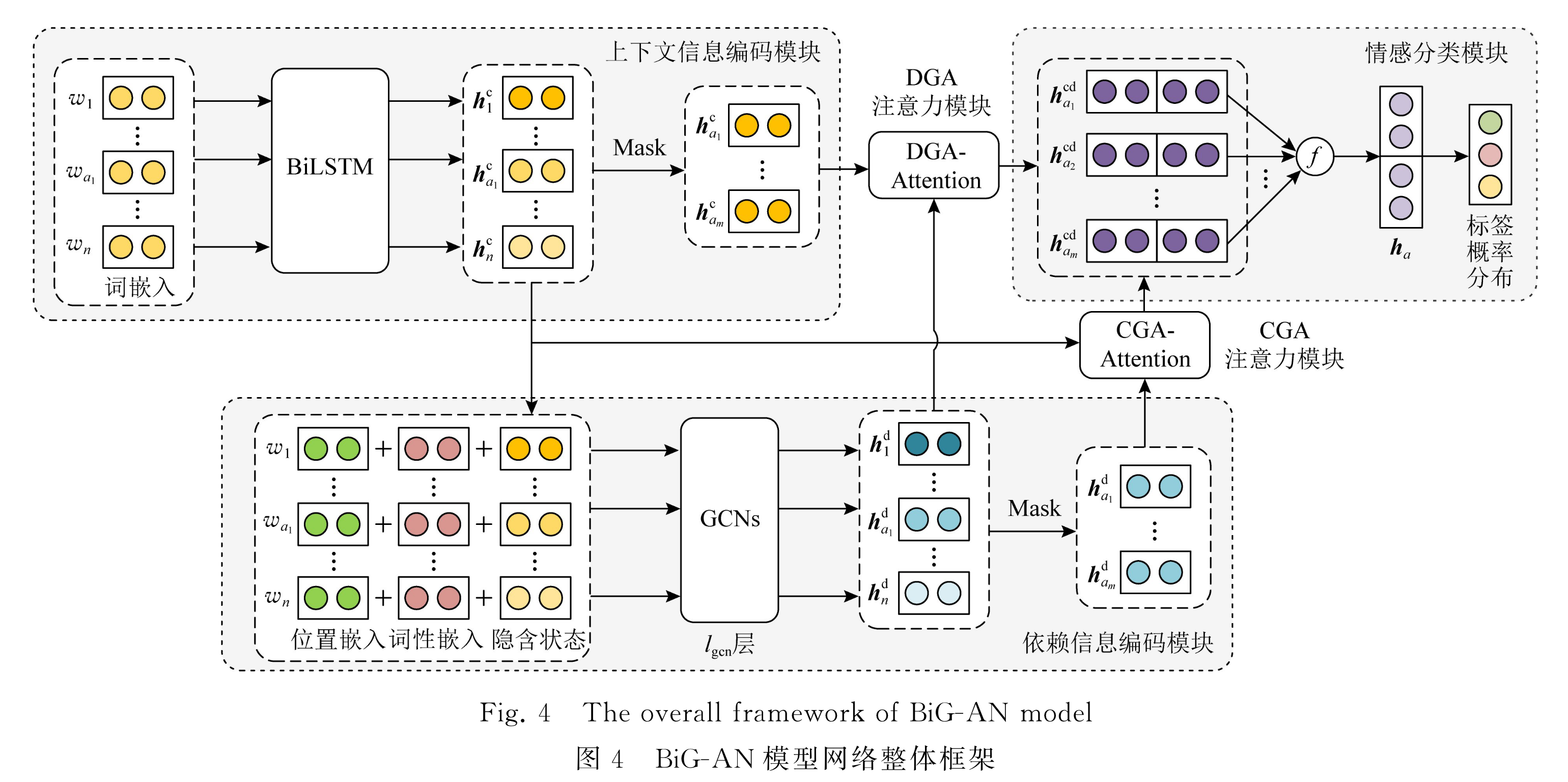
模型主要包括上下文信息编码、依赖信息编码、特征信息融合和情感分类四个模块。
1.上下文信息编码模块
给定单词序列 s = [ w 1 , w 2 , ⋯ , w a 1 , w a 2 , ⋯ , w n ] s = [w_1, w_2, \cdots, w_{a_1}, w_{a_2}, \cdots, w_n] s=[w1,w2,⋯,wa1,wa2,⋯,wn],其中 [ w a 1 , w a 2 , ⋯ , w a m ] [w_{a_1}, w_{a_2}, \cdots, w_{a_m}] [wa1,wa2,⋯,wam] 为句子中的方面序列,通过 Glove 即可将单词序列 s s s 转换为词向量表示 e = ( e 1 , e 2 , ⋯ , e a 1 , e a 2 , ⋯ , e n ) e = (e_1, e_2, \cdots, e_{a_1}, e_{a_2}, \cdots, e_{n}) e=(e1,e2,⋯,ea1,ea2,⋯,en)。然后将 e e e 输入到 BiLSTM中,得到引入了上下文信息的句子表示 h c h_c hc,其计算过程如下图所示,包含前向隐藏状态序列和后向隐藏状态序列两部分。

接下来,通过 Zero-Mask 操作可以得到序列 h c h_c hc 的 Zero-Mask 嵌入表示 h M a s k c h_{Mask}^c hMaskc,该操作的目的是减少与评价对象无关的上下文信息的影响,在去除非方面词的句子成分后即可得到融合了上下文信息的方面隐藏状态序列 h A c h_{A}^c hAc。
2.依赖信息编码模块
作者将依存关系树当作有向图来处理,并通过邻接矩阵进行存储,当两个单词之间存在边,即存在依存关系时对应位置置 1。构建好的邻接关系图将会由 GCNs 来进行捕获,GCNs 可以有效利用依存关系路径来进行信息传递,并通过对传递的信息进行聚合来更新节点的表示状态。其中节点 i 的状态更新公式如下,其中 h j l g c n − 1 h_j^{l_{gcn}-1} hjlgcn−1 表示节点 j 在 GCNs 中第 l g c n − 1 l_{gcn}-1 lgcn−1 层的输入隐含状态, W d W_d Wd 是线性变换权重矩阵, b d b_d bd 是偏置项, d i + 1 d_i + 1 di+1 是归一化常数,用来防止度大的节点具有过大的特征值,节点 i 的度计算公式是 d i = ∑ j = 1 n A i j d_i = \displaystyle \sum_{j = 1}^nA_{ij} di=j=1∑nAij, σ \sigma σ 是非线性激活函数(作者采用的是ReLU)。
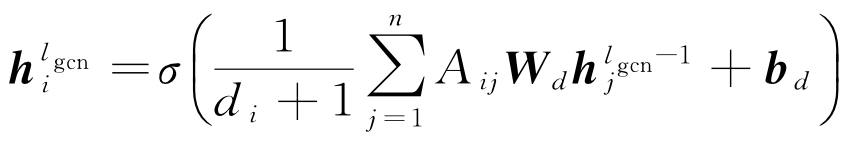
通过 GCNs 得到的依赖信息还需要进行 Zero-Mask 操作,最终得到的依赖信息为 h A d = ( h a 1 d , h a 2 d , ⋯ , h a m d ) h_A^d = (h_{a_1}^d, h_{a_2}^d, \cdots , h_{a_m}^d) hAd=(ha1d,ha2d,⋯,hamd)。
3.特征信息融合模块
此模块包括两个基于信息主导的注意力机制,分别为 DGA-Attention 和 CGA-Attention。其中 DGA-Attention 为以依赖信息指导的注意力,其思想是通过上下文信息状态 h a i c , i ∈ [ 1 , m ] h_{a_i}^c, i \in [1, m] haic,i∈[1,m] 从 GCNs 的输出 h j d , j ∈ [ 1 , n ] h_j^d, j \in [1, n] hjd,j∈[1,n] 中检索与方面相关的语义特征,并相应计算其注意力权重,最终得到基于依赖信息指导注意力的方面特征表示 h A d g a h_A^{dga} hAdga。与此类似,基于上下文信息指导的注意力 CGA-Attention 使用 h A d h_A^d hAd 作为查询序列对 BiLSTM 输出的隐藏状态序列 h c h^c hc 进行查询,可以得到基于上下文信息指导注意力的方面特征表示 h A c g a h_A^{cga} hAcga。
4.情感分类模块
情感分类模块首先将 h A d g a h_A^{dga} hAdga 和 h A c g a h_A^{cga} hAcga 进行拼接,得到了同时融合了上下文信息和依赖信息的属性特征 h A c d h_A^{cd} hAcd,然后通过多头注意力机制 MHA 和最大池化操作即可得到最终的聚合表示 h a h_a ha。最后,通过全连接层和 softmax 归一化处理即可得到最终的情感标签概率分布 p p p。