elasticSearch入门和安装
- 一,elasticSearch入门
- 1,什么是elasticSearch
- 2,elasticSearch的底层优点
- 2.1,全文检索
- 2.2,倒排索引
- 2.2.1,正排索引
- 2.2.2,倒排索引
- 2.2.3,倒排索引解决的问题
- 2.2.4,正排和倒排总结
- 二,下载安装
- 1,elasticsearch安装
- 2,安装elasticsearch-head
- 3,安装kibana
一,elasticSearch入门
官网地址如下:https://www.elastic.co/cn/
1,什么是elasticSearch
用官网的话说就是:Elasticsearch 是一个分布式、高扩展、高实时的搜索与数据分析引擎,它能很方便的使大量数据具有搜索、分析和探索的能力。

2,elasticSearch的底层优点
2.1,全文检索
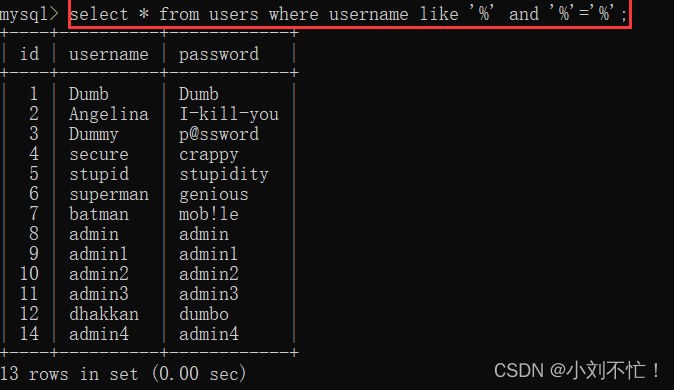
如在对一个输入框输入东西进行搜索的时候,在使用关系型数据库存储时,那么就需要使用到模糊查询,其sql语句如下。如果是直接使用SQL的模糊查询对数据进行检索,那么下面这条sql语句,在数据量大的时候,会非常的慢,并且最重要的是,根据B+树的底层数据结构,下面这条SQL不走索引,因此在海量数据检索时,一般不会考虑使用这个SQL
select * from product where name like '%衣服%'
针对上述的问题,就可以引入这个为什么使用elasticSearch了。其底层就是会通过一个程序扫描文本的每一个单词,针对单字或者单词建立索引,并保存该单词在文本中的位置、以及出现的次数。然后在用户查询时,就会通过之前建立好的索引来查询,将索引中单词对应的文本位置、出现的次数返回给用户,因为有了具体的文本位置,所以就可以将具体的内容读取出来了。这样速度就非常的高效,并且底层也使用到了索引,即倒排索引。
2.2,倒排索引
2.2.1,正排索引
首先先说一下什么是正排索引,就是底层不会提前建立好索引,而是在查找时,会去判断数据中是否存在这个关键字,如果存在,那么就会记录这个关键字的位置以及出现的次数,这样又有点类似于这个使用sql了。那就以mysql为例子作为这个正排索引,假设有海量数据中包含着以下的数据: java多线程和高并发,那么如果用户直接在搜索框输入java高并发 关键字进行一个模糊查询,那么mysql是肯定不能查询出这条数据的,并且使用like直接不能走索引,还有涉及到回表的问题等等,因此查询效率低,查询的数据不完整。
select * from data like '%java高并发%'
2.2.2,倒排索引
由于正排索引效率并不高,并且查询出来的数据并不完整,因此es底层就参考这个正排索引,设计出了这个倒排索引,主要由id,关键字和这个索引下表index组成。如下有一下数据,都是英文组成,因此关键字就是以一个空格为一个关键字,因此可以对这个倒排索引进行如下的总结:
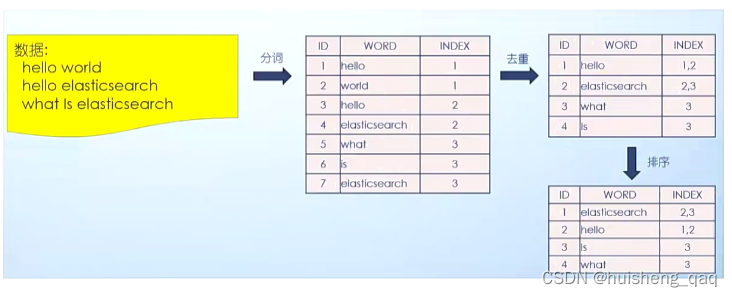
1,就是会将这些数据进行一个关键字的分词,然后将每一个词建立一个index的下标索引;
2,建立索引之后,就会进行一个去重的操作,根据关键字进行去重,然后再合并,并且将index存放在一起;
3,然后会根据关键字进行一个排序,由于这使用的是英文,所以直接根据首字母进行排序
2.2.3,倒排索引解决的问题
再来分析一下上面的那个用户java高并发关键字的问题,根据倒排索引的原则,首先会对数据进行一个分词,具体怎么分词由分词器决定,具体怎么分词要看使用什么样的分词器。那么就会对这条 java多线程和高并发 数据进行一个分词,如下,这个是数据的分词
| id | word | index |
|---|---|---|
| 1 | java | 1 |
| 2 | 多线程 | 1 |
| 3 | 和 | 1 |
| 4 | 高并发 | 1 |
那么在查询时,也会对要查询的数据再做一个分词,如将 java高并发 拆分成java和高并发两个关键字,然后再去和关键字进行一个匹配,然后再获取到下标,即数据对应的位置,由于这里只有一行数据,那么对应的数据就在index所示位置,第一行,这样即让关键字走了索引,也将全部需要的数据检索出来。
2.2.4,正排和倒排总结
正排索引就是根据这个关键字去进行一个全文检索的定位,最后再获取到那一条数据的id,然后根据id获取到那一条数据。倒排就是先将关键词进行一个拆分,然后根据拆分的关键词进行一个数据的定位,定位之后再获取到数据的index索引值,这个值对应的就是数据的id,然后根据id去定位那一条数据。
最大的区别就是:正排是后获取id,然后根据id获取整条数据;倒排是先获取id,就是通过关键字单位获取到的index索引值,然后根据这个id获取到文档中的全部数据 ,简单理解就是正向索引是key找value,反向索引就是通过value找key,这个vaue就是对应的id,数据库中被称为id,es中被称为index。
二,下载安装
如果用原生的方式通过linux安装这些玩意,那么肯定是比较复杂的,因此我这边选择使用docker进行一个安装,本人使用的是腾讯云服务器,内存大小为2核4g的,基本是够用了。
1,elasticsearch安装
1,先设置max_map_count的值
sysctl -w vm.max_map_count=262144
2,这里选择7.x的版本,并且这里安装7.7.0的版本
docker pull elasticsearch:7.7.0
3,接下来运行这个容器,各个参数就先不说了,可以直接去查看官网或者百度。然后输入docker ps命令,也可以发现这个容器已经在运行了
docker run --name elasticsearch -d -e ES_JAVA_OPTS="-Xms512m -Xmx512m" -e "discovery.type=single-node" -p 9200:9200 -p 9300:9300 elasticsearch:7.7.0
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Y7SHUl3W-1677565105149)(img/1675244046781.png)]](https://img-blog.csdnimg.cn/42dc8dfb2a4f4b42a513c079d9c4b5c3.png)
4,然后以交互式进入容器
docker exec -it elasticsearch /bin/bash
5,切换到这个config的目录下面
cd config
6,然后编辑里面的这个elasticsearch.yml文件。
vim elasticsearch.yml
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-J5ukB9tp-1677565105150)(img/1673326215198.png)]](https://img-blog.csdnimg.cn/4c5726db767344d19066a2a43e6d3ea2.png)
要是出现这个没有vim的情况,直接安装这个vim即可,或者也可以使用vi
yum install vim
//或者上面的直接使用
vi elasticsearch.yml
7,编辑这个elasticsearch.yml的内容如下。编辑完成之后,exit退出
cluster.name: "docker-cluster"
network.host: 0.0.0.0
#设置跨域问题
http.cors.enabled: true
http.cors.allow-origin: "*"
#设置端口号
http.port: 9200
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-UCZBnP1I-1677565105151)(img/1673326486352.png)]](https://img-blog.csdnimg.cn/3b592bfb5ac94134a3406dc1e473068f.png)
8,这样es就安装成功了,接下来服务器里面测试一下这个容器是否安装成功
curl 0.0.0.0:9200
9,浏览器输入这个ip + 9200,就可以查看是否安装成功了。如果curl有显示东西而这个浏览器里面访问不了,那么查看一下是不是这个防火墙的问题,或者是服务器端口号没开。有了一下界面,说明es安装成功了。
服务器ip + 9200
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Z6NW3oKB-1677565105152)(img/1675244254503.png)]](https://img-blog.csdnimg.cn/02900691030e4037be29815e0b6ee249.png)
2,安装elasticsearch-head
1,安装head头部
docker pull mobz/elasticsearch-head:5
2,查看全部的镜像,查看一下这个mobz/elasticsearch-head:5是否拉取成功
docker images

3,运行这个head,后面可以直接使用这个imageId运行,可以在docker images里面查看这个head的image Id,这个imageID就是上图种的哪个IMAGE ID
docker run -d --name="es-head" -p 9100:9100 imageId
4,服务器里面测试一下这个容器是否安装成功。正常来讲就是安装成功的
curl 0.0.0.0:9100
5,浏览器输入这个ip + 9100,就可以查看是否安装成功了。如果curl有显示东西而这个浏览器里面访问不了,那么查看一下是不是这个防火墙的问题,或者是服务器端口号没开
服务器ip + 9100
6,访问一下,测试一下这个head能否连接成功这个ElasticSearch,如果用的是服务器记得改成服务器的ip + 9200。不然里面默认是localhost:9200,是一直等不到结果的,这样这个head就安装成功了
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-EaXXDnJN-1677565105153)(img/1674025641971.png)]](https://img-blog.csdnimg.cn/957391afac7346abb88f7ffbd0a95886.png)
3,安装kibana
1,拉取kibana镜像,这个版本要和ElasticSearch的版本一致
docker pull kibana:7.7.0
2,创建一个文件夹
mkdir -p /data/elk7/kibana/config/
vi /data/elk7/kibana/config/kibana.yml
这个配置文件文件的内容如下
server.name: kibana
server.host: "0"
elasticsearch.hosts: [ "http://服务器ip:9200" ]
xpack.monitoring.ui.container.elasticsearch.enabled: true
3,运行这个容器
docker run -d --name=kibana --restart=always -p 5601:5601 -v /data/elk7/kibana/config/kibana.yml:/usr/share/kibana/config/kibana.yml kibana:7.7.0
4,最后查看一下kibana的日志,如果有日志出现,那么这个kibana就安装成功了
docker logs -f kibana
最后通过这个 ip + 5601在浏览器访问一下,就可以得到一下的界面,那么这个kibana就算安装好了。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-PINgATHq-1677565105154)(img/1675245053085.png)]](https://img-blog.csdnimg.cn/8e80cbe583be4100bcecceeeb292c5c0.png)
这样安装这一块,基本就没啥问题了。最后查看一下这个全部的镜像,可以发现这些全部都安装好了,看大小占用了2.6个G,还没有配分词器那些,所以如果服务器安装的话,最低选择2核4g的服务器。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-lfc1rSyv-1677565105155)(img/1675245301353.png)]](https://img-blog.csdnimg.cn/87c15c361ec84cbea2d3f21e36bbc56e.png)