目录
- Kafka概述
- 定义
- 消息队列
- 目录结构分析
- 传统消息队列的应用场景
- 消息队列的两种模式
- 点对点模式
- 发布/订阅模式
- Kafka基础架构
- Kafka快速入门
- 安装部署
- 集群规划
- 集群部署
- 集群启停脚本
- Kafka命令行操作
- Kafka基础架构
- 主题命令行操作
- 生产者命令行操作
- 消费者命令行操作
- kafka可视化工具
- Kafka重要概念
- broker
- zookeeper
- producer(生产者)
- consumer(消费者)
- consumer group(消费者组)
- 分区(Partitions)
- 副本(Replicas)
- 主题(Topic)
- 偏移量(offset)
- 消费者组
- Kafka生产者
- 生产者消息发送流程
- 发送原理
- 生产者重要参数列表
- 异步发送API
- 普通异步发送
- 带回调函数的异步发送
- 同步发送API
- 生产者分区
- 分区和副本机制
- 分区好处
- 轮询策略
- 随机策略(不用)
- 按key分配策略
- 乱序问题
- 副本机制
- producer的ACKs参数
- acks配置为0
- acks配置为1
- acks配置为-1或者all
- Kafka生产者幂等性与事务
- 幂等性
- Kafka生产者幂等性
- 幂等性原理
- Kafka事务
- 事务操作API
- 数据有序和数据乱序
- Kafka Broker
- Zookeeper存储的Kafka信息
- Kafka Broker总体工作流程
- Broker重要参数
- Kafka副本
- 副本基本信息
- Leader 选举流程
- Leader 和 Follower 故障处理细节
- 活动调整分区副本存储
- Leader Partition 负载平衡
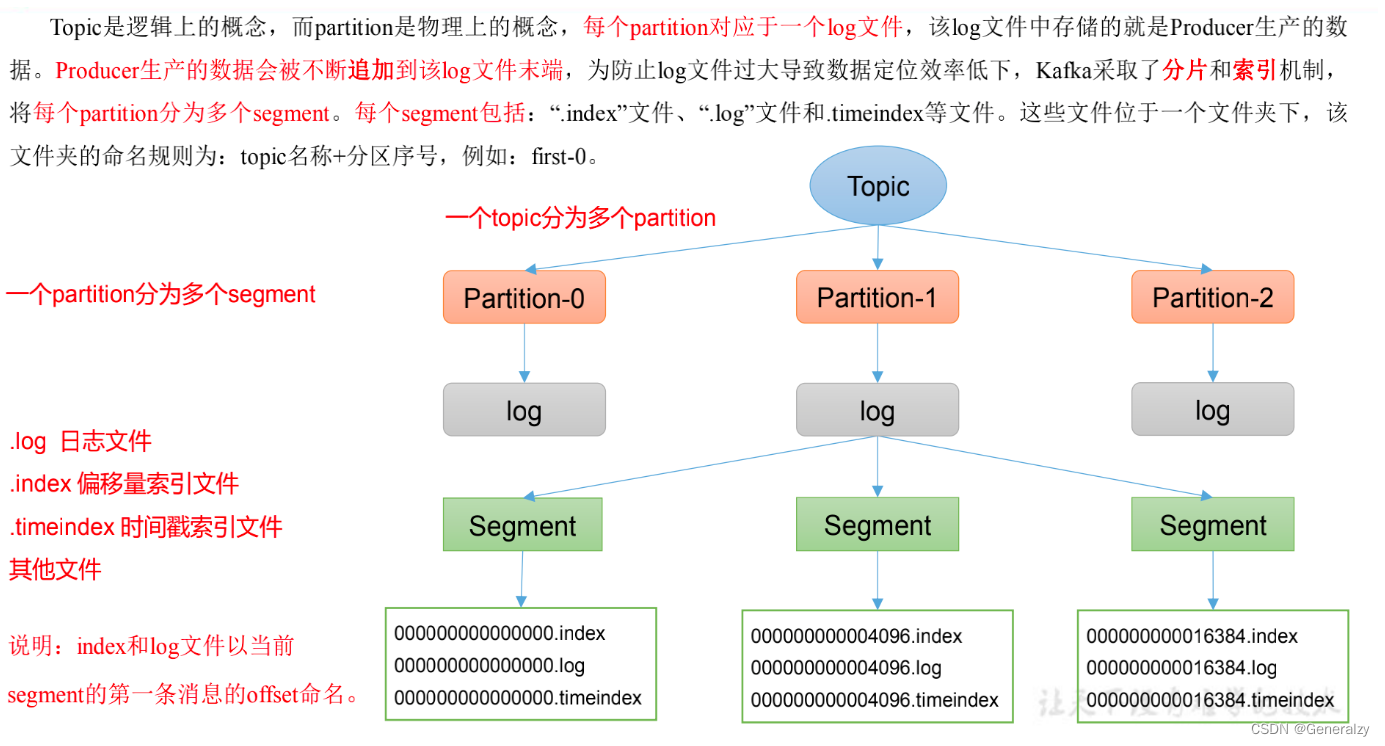
- 文件存储
- Topic 数据的存储机制
- 文件清理策略
- Kafka 消费者
- Kafka 消费方式
- Kafka 消费者工作流程
- 消费者组原理
- 消费者重要参数
- offset 位移
- offset 的默认维护位置
- 自动提交offset
- 手动提交offset
- 指定Offset消费
- Kafka-Kraft模式
- Kafka-Kraft架构
Kafka概述
定义
Kafka传统定义: Kafka是一个分布式的基于发布/订阅模式的消息队列(Message Queue),主要应用于大数据实时处理领域。
发布/订阅:消息的发布者不会将消息直接发布给特定的订阅者,而是将发布的消息分为不同的类别,订阅者只接收感兴趣的消息。
Kafka最新定义:Kafka是一个开源的分布式事件流平台(Event Streaming Platform),被数千家公司用于高性能的数据管道、流分析、数据集成和关键任务应用。
消息队列
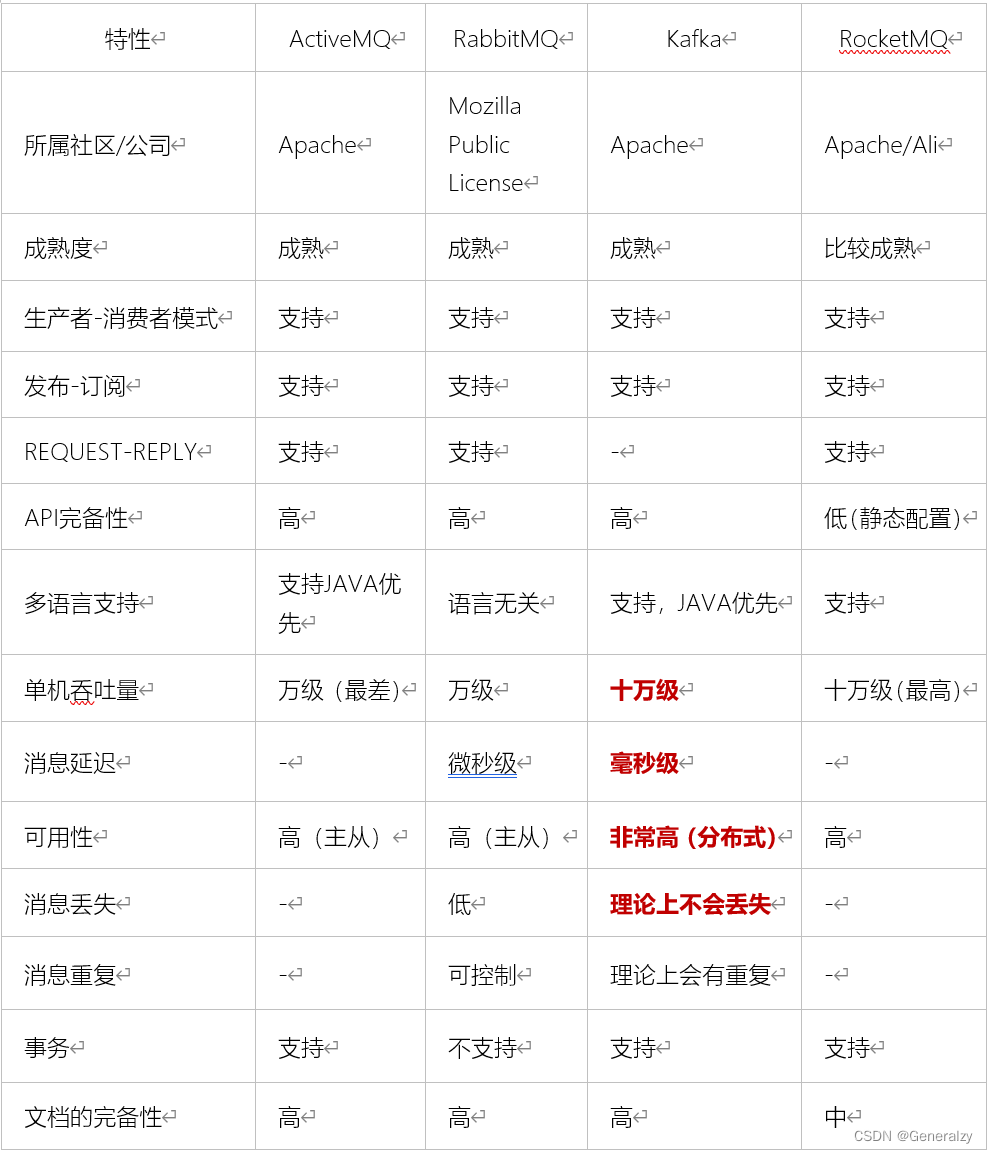
目前企业中比较常见的消息队列产品主要有Kafka、ActiveMQ、RabbitMQ、RocketMQ等。
在大数据场景主要采用Kafka作为消息队列。在JavaEE开发中主要采用ActiveMQ、RabbitMQ、RocketMQ。

目录结构分析
- bin:Kafka的所有执行脚本都在这里。例如:启动Kafka服务器、创建Topic、生产者、消费者程序等等
- config:Kafka的所有配置文件
- libs: 运行Kafka所需要的所有JAR包
- logs: Kafka的所有日志文件,如果Kafka出现一些问题,需要到该目录中去查看异常信息
- site-docs: Kafka的网站帮助文件
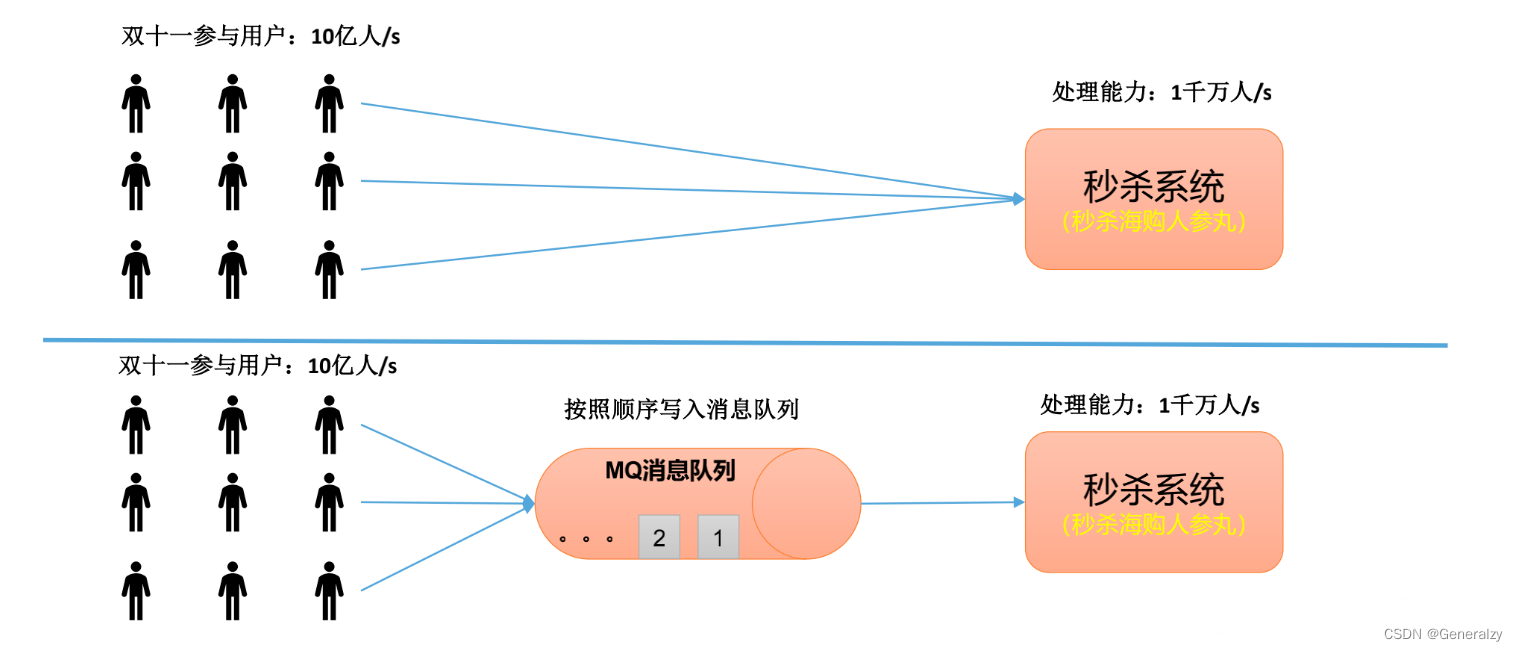
传统消息队列的应用场景
传统的消息队列的主要应用场景包括**:缓存/消峰、解耦和异步通信**。
缓冲/消峰: 有助于控制和优化数据流经过系统的速度,解决生产消息和消费消息的处理速度不一致的情况。
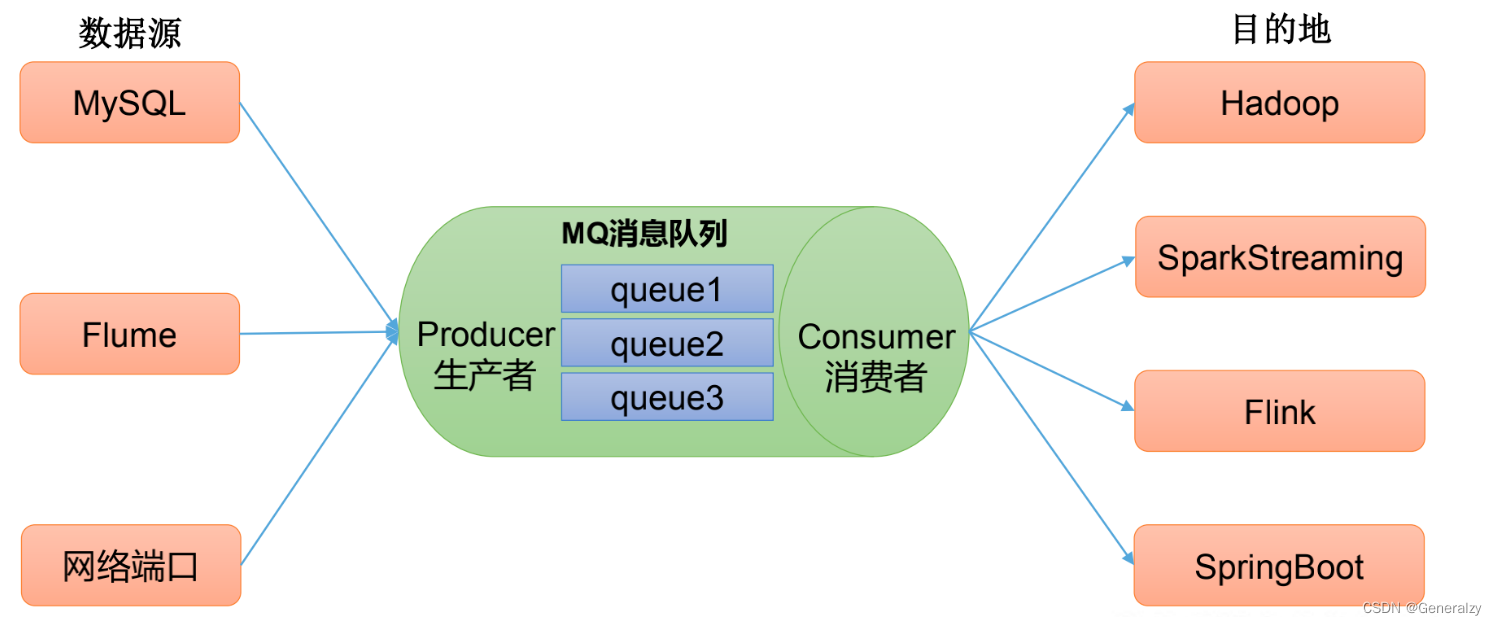
解耦:允许你独立的扩展或修改两边的处理过程,只要确保它们遵守同样的接口约束。
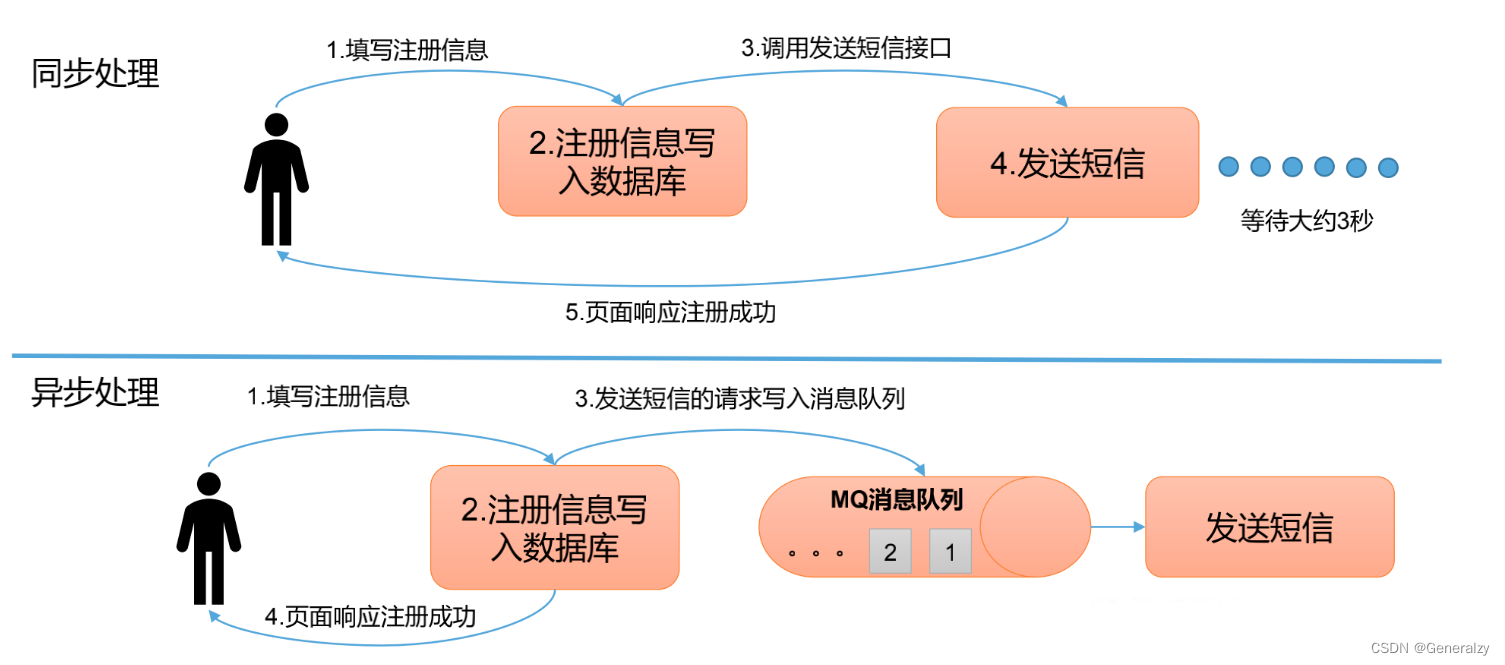
异步通信:允许用户把一个消息放入队列,但并不立即处理它,然后再需要的时候再去处理它们。
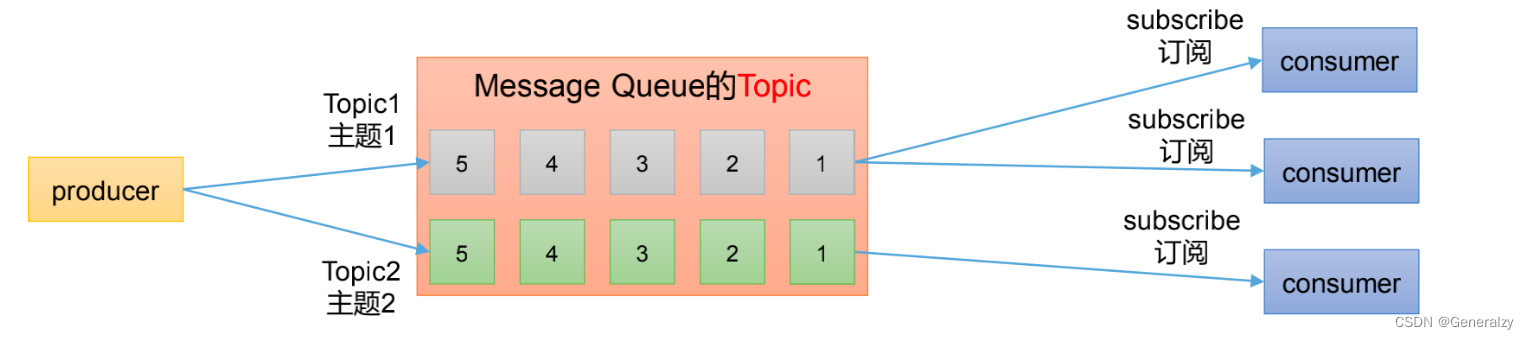
消息队列的两种模式
点对点模式
消费者主动拉去数据,消息收到后清除消息

发布/订阅模式
- 可以有多个topic主题(浏览,点赞,收藏,评论等)
- 消费者消费数据之后,不删除数据
- 每个消费者互相独立,都可以消费到数据
Kafka基础架构
1、为方便扩展,并提高吞吐量,一个topic分为多个partition
2、配合分区的设计,提出消费者组的概念,组内每个消费者并行消费
3、为提高可用性,为每个partition增加若干副本,类似NameNode HA
4、ZK中记录谁是leader,Kafka2.8.0 以后也可以配置不采用ZK.
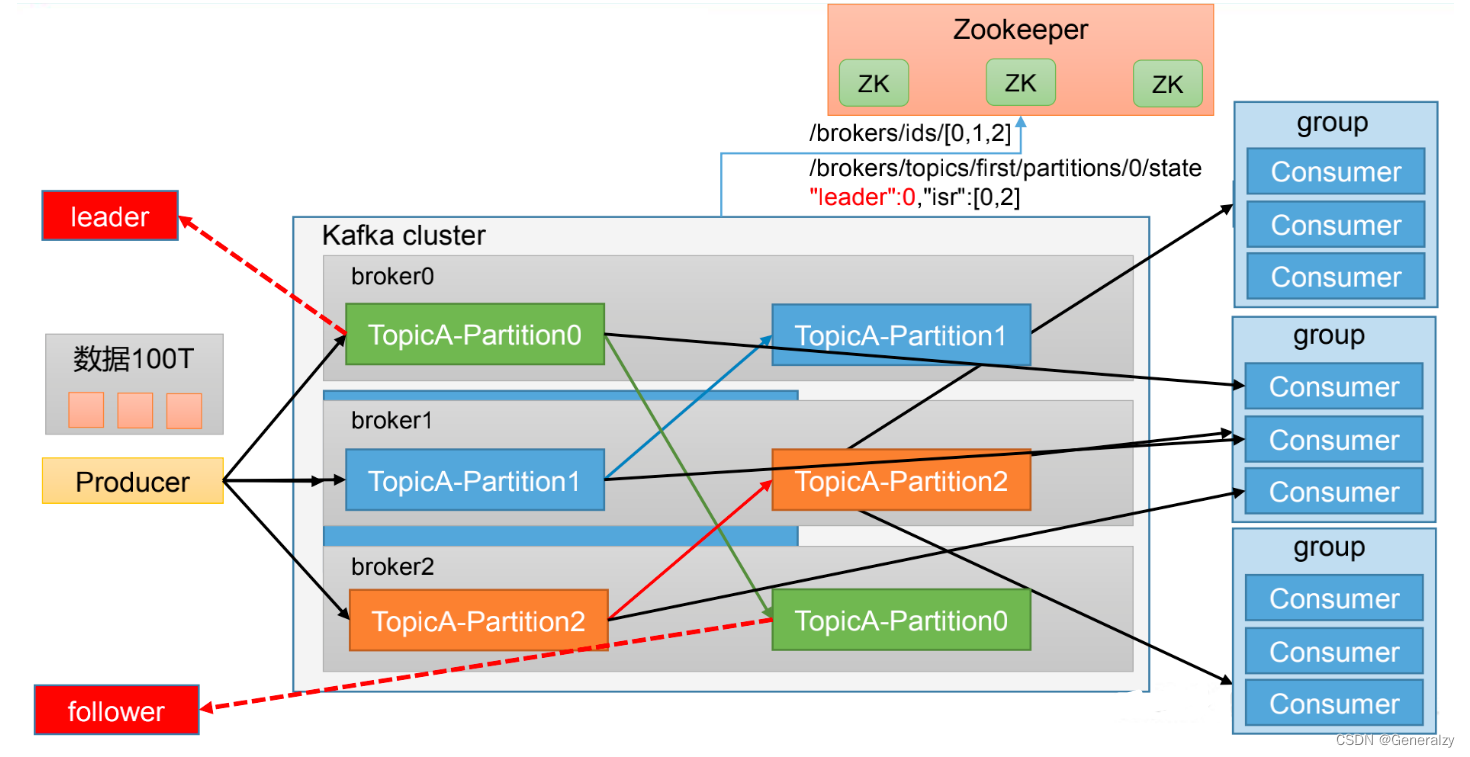
-
Producer:消息生产者,就是向Kafka broker 发消息的客户端。
-
Consumer:消息消费者,向Kafka broker 取消息的客户端。
-
Consumer Group(CG):消费者组,由多个consumer组成。消费者组内每个消费者负责消费不同分区的数据,一个分区只能由一个组内消费者消费;消费者组之间互不影响。所有的消费者都属于某个消费者组,即消费者组是逻辑上的一个订阅者。
-
Broker:一台Kafka服务器就是一个broker。一个集群由多个broker组成。一个broker可以容纳多个topic。
-
Topic: 可以理解为一个队列,生产者和消费者面向的都是一个topic。
-
Partition: 为了实现扩展性,一个非常大的topic可以分布到多个broker(即服务器)上,一个topic可以分为多个partition,每个partition是一个有序的队列。
-
Replica:副本。一个topic的每个分区都有若干个副本,一个Leader和若干个Follower。
-
Leader:每个分区多个副本的 “主”,生产者发送数据的对象,以及消费者消费数据的对象都是Leader。
-
Follower:每个分区多个副本中的 “从”,实时从 Leader 中同步数据,保持和 Leader 数据的同步。Leader 发生故障时,某个Follower会成为新的 Leader。
Kafka快速入门
安装部署
集群规划
| Hadoop102 | Hadoop103 | Hadoop104 |
|---|---|---|
| zk | zk | zk |
| kafka | kafka | kafka |
集群部署
-
docker部署zk集群:参考《zk全解》
-
进入到/usr/local/kafka目录,修改配置文件
vim server.properties #broker 的全局唯一编号,不能重复,只能是数字。 broker.id=0 #处理网络请求的线程数量 num.network.threads=3 #用来处理磁盘 IO 的线程数量 num.io.threads=8 #发送套接字的缓冲区大小 socket.send.buffer.bytes=102400 #接收套接字的缓冲区大小 socket.receive.buffer.bytes=102400 #请求套接字的缓冲区大小 socket.request.max.bytes=104857600 #kafka 运行日志(数据)存放的路径,路径不需要提前创建,kafka 自动帮你创建,可以 # 配置多个磁盘路径,路径与路径之间可以用","分隔 log.dirs=/opt/module/kafka/datas # 监听所有网卡地址,允许外部端口连接 listeners=PLAINTEXT://0.0.0.0:9092 #topic 在当前 broker 上的分区个数 num.partitions=1 #用来恢复和清理 data 下数据的线程数量 num.recovery.threads.per.data.dir=1 # 每个 topic 创建时的副本数,默认时 1 个副本 offsets.topic.replication.factor=1 #segment 文件保留的最长时间,超时将被删除 log.retention.hours=168 #每个 segment 文件的大小,默认最大 1G log.segment.bytes=1073741824 # 检查过期数据的时间,默认 5 分钟检查一次是否数据过期 log.retention.check.interval.ms=300000 #配置连接 Zookeeper 集群地址(在 zk 根目录下创建/kafka,方便管理) zookeeper.connect=hadoop102:2181,hadoop103:2181,hadoop104:2181/kafka可以提前在hosts文件中配置master,slave1,slave2的ip,之前在学习k8s的时候我已经配置过了,可以直接拿来用。
listeners=PLAINTEXT://0.0.0.0:9092,默认情况下,advertised.listeners不设置的话,则默认使用listeners的属性,然而advertised.listeners是不支持0.0.0.0的,所以需要指定暴露的监听器,如下listeners=PLAINTEXT://0.0.0.0:9092 advertised.listeners=PLAINTEXT://虚拟机ip:9092 -
将安装包拷贝到其他服务器
-
分别在hadoop103和hadoop104 上修改配置文件
/opt/module/kafka/config/server.properties中的broker.id=1、broker.id=2 -
配置环境变量
- 在/etc/profile.d/my_env.sh 文件中增加 kafka 环境变量配置
sudo vim /etc/profile.d/my_env.sh 增加如下内容: #KAFKA_HOME export KAFKA_HOME=/opt/module/kafka export PATH=$PATH:$KAFKA_HOME/bin这里我将kafka直接放在了根目录下的一个文件夹,更加方便:
- 刷新一下环境变量。
source /etc/profile- 分发环境变量文件到其他节点,并 source。
sudo /home/atguigu/bin/xsync /etc/profile.d/my_env.sh source /etc/profile source /etc/profile -
分别启动kafka:
bin/kafka-server-start.sh -daemon config/server.properties
- 如果遇到cluser_id不符合的问题,直接将日志文件删除重新启动即可。
集群启停脚本
- 脚本如下,
#! /bin/bash
case $1 in
"start"){
for i in hadoop102 hadoop103 hadoop104
do
echo " --------启动 $i Kafka-------"
ssh $i "/opt/module/kafka/bin/kafka-server-start.sh -
daemon /opt/module/kafka/config/server.properties"
done
};;
"stop"){
for i in hadoop102 hadoop103 hadoop104
do
echo " --------停止 $i Kafka-------"
ssh $i "/opt/module/kafka/bin/kafka-server-stop.sh "
done
};;
esac
- 添加执行权限
chmod +x kf.sh
- 启动集群命令
kf.sh start
- 停止集群命令
kf.sh stop
Kafka命令行操作
Kafka基础架构
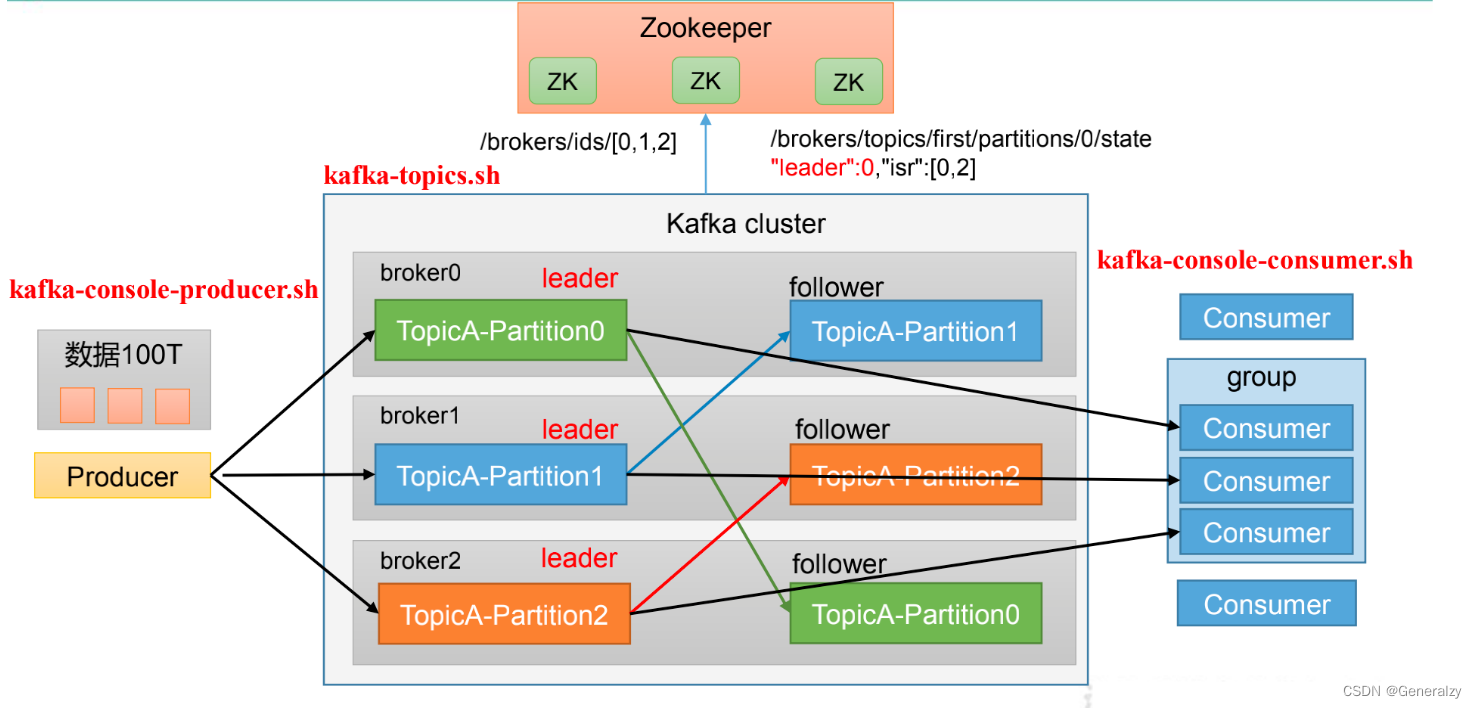
主题命令行操作
-
查看操作主题命令参数
./bin/kafka-topics.sh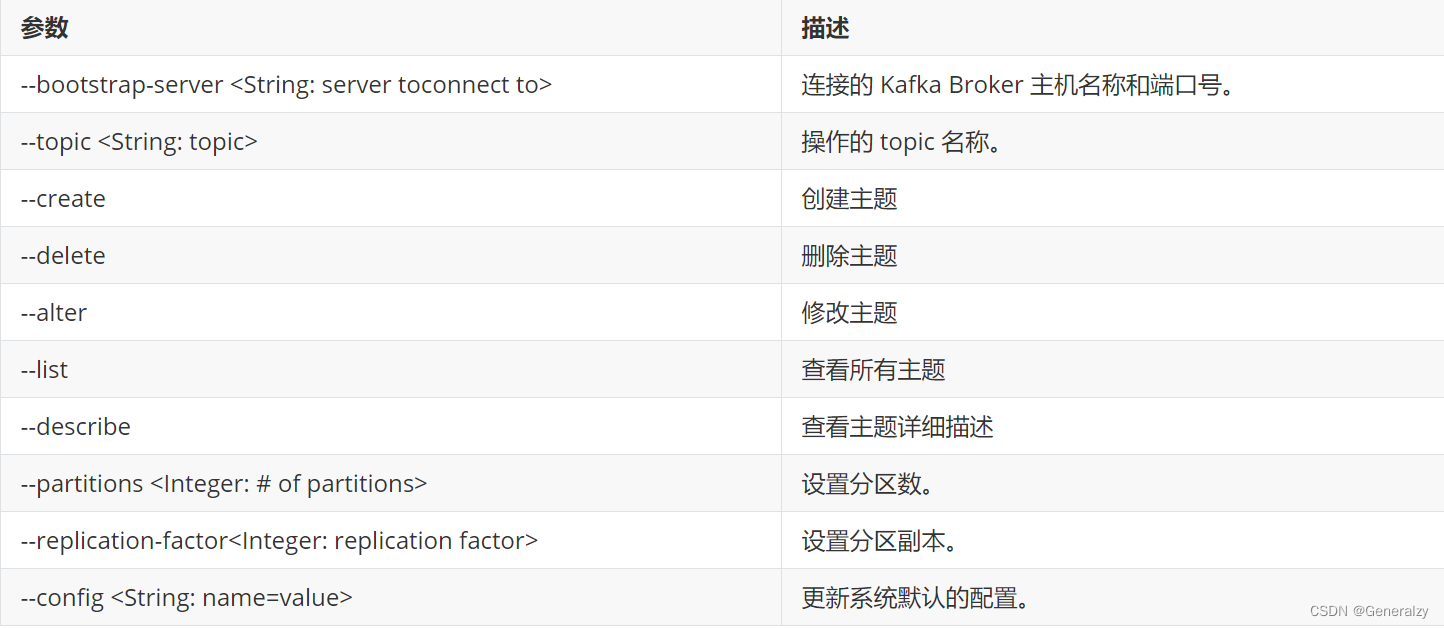
-
查看当前服务器中的所有topic
./bin/kafka-topics.sh --bootstrap-server localhost:9092 --list -
创建
first topic./bin/kafka-topics.sh --bootstrap-server localhost:9092 --create --partitions 1 --replication-factor 1 --topic first选项说明:
- –topic 定义 topic 名
- –replication-factor 定义副本数
- –partitions 定义分区数
-
查看
first主题的详情./bin/kafka-topics.sh --bootstrap-server localhost:9092 --topic first --describe -
修改分区数(注意:分区数只能增加,不能减少)
./bin/kafka-topics.sh --bootstrap-server localhost:9092 --alter --topic first --partitions 3 -
查看结果:
./bin/kafka-topics.sh --bootstrap-server localhost:9092 --topic first --describe Topic: first TopicId: _Pjhmn1NTr6ufGufcnsw5A PartitionCount: 3 ReplicationFactor: 1 Configs: segment.bytes=1073741824 Topic: first Partition: 0 Leader: 0 Replicas: 0 Isr: 0 Topic: first Partition: 1 Leader: 0 Replicas: 0 Isr: 0 Topic: first Partition: 2 Leader: 0 Replicas: 0 Isr: 0 -
删除
topic./bin/kafka-topics.sh --bootstrap-server localhost:9092 --delete --topic first
生产者命令行操作
-
查看操作者命令参数
./bin/kafka-console-producer.sh
-
发送消息
./bin/kafka-console-producer.sh --bootstrap-server localhost:9092 --topic first >hello world >yooome yooome
消费者命令行操作
-
查看操作消费者命令参数
./bin/kafka-console-consumer.sh
-
消费消息
- 消费
first主题中的数据:
./bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic first- 把主题中所有的数据都读取出来(包括历史数据)。
./bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --from-beginning --topic first
- 消费
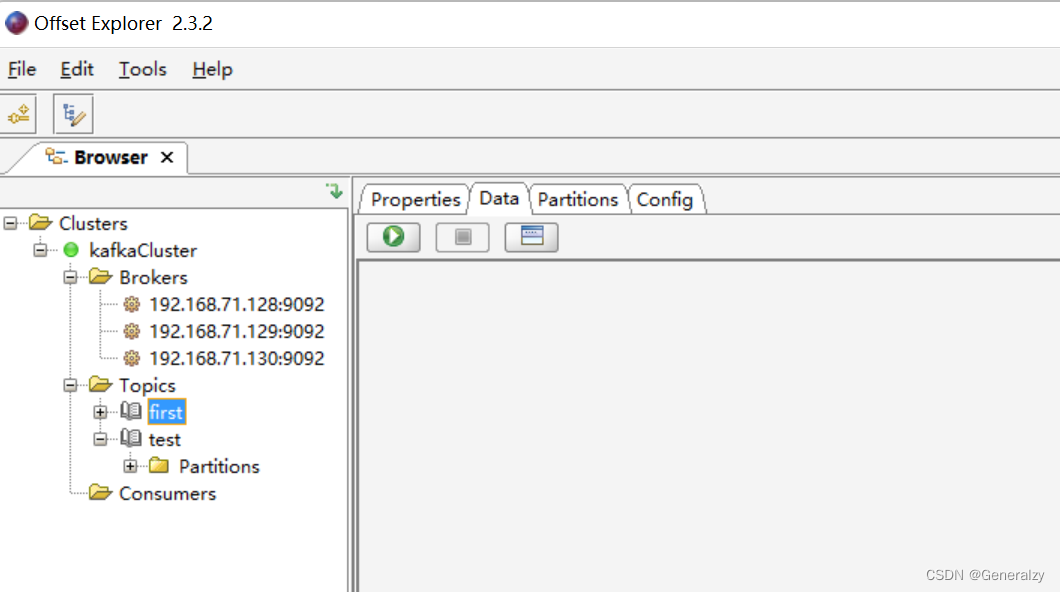
kafka可视化工具
官网:https://www.kafkatool.com/download.html
Kafka重要概念
broker
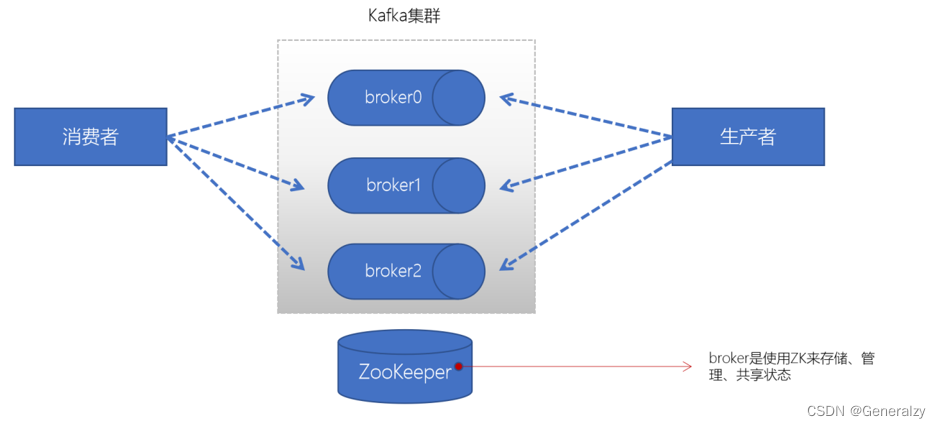
- 一个Kafka的集群通常由多个broker组成,这样才能实现负载均衡、以及容错
- broker是无状态(Sateless)的,它们是通过ZooKeeper来维护集群状态
- 一个Kafka的broker每秒可以处理数十万次读写,每个broker都可以处理TB消息而不影响性能
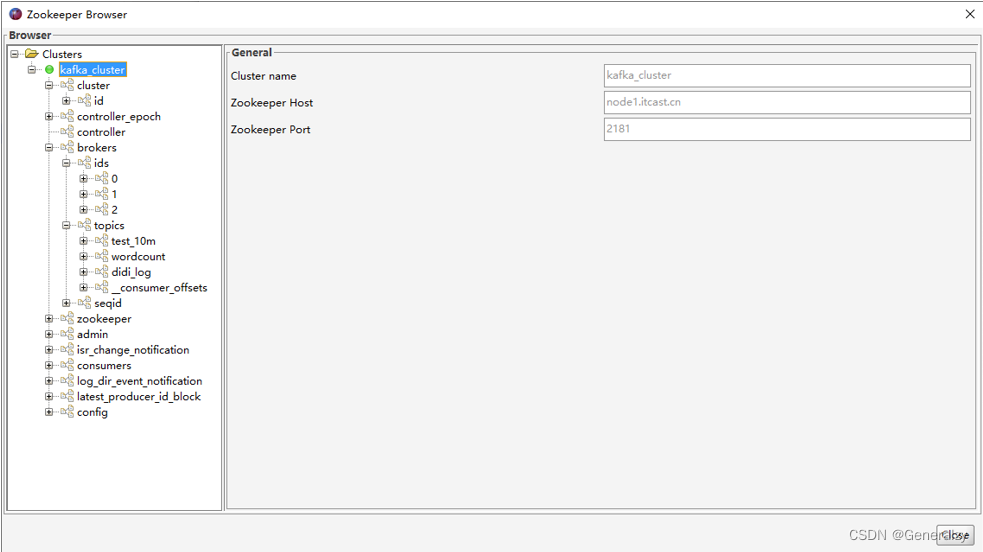
zookeeper
-
ZK用来管理和协调broker,并且存储了Kafka的元数据(例如:有多少topic、partition、consumer)
-
ZK服务主要用于通知生产者和消费者Kafka集群中有新的broker加入、或者Kafka集群中出现故障的broker。
-
Kafka正在逐步想办法将ZooKeeper剥离,维护两套集群成本较高,社区提出KIP-500就是要替换掉ZooKeeper的依赖。“Kafka on Kafka”——Kafka自己来管理自己的元数据
producer(生产者)
生产者负责将数据推送给broker的topic
consumer(消费者)
消费者负责从broker的topic中拉取数据,并自己进行处理
consumer group(消费者组)
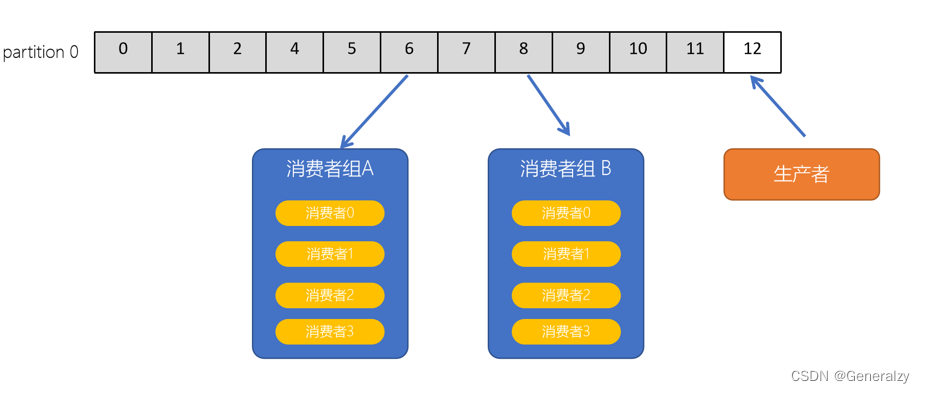
- consumer group是kafka提供的可扩展且具有容错性的消费者机制
- 一个消费者组可以包含多个消费者
- 一个消费者组有一个唯一的ID(group Id)
- 组内的消费者一起消费主题的所有分区数据
分区(Partitions)
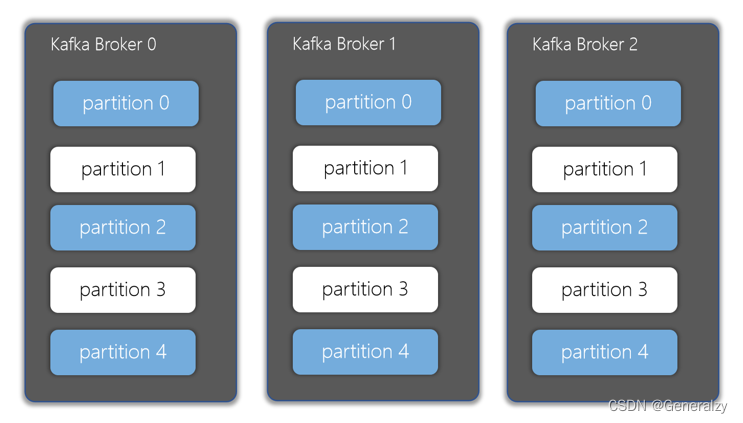
在Kafka集群中,主题被分为多个分区
副本(Replicas)
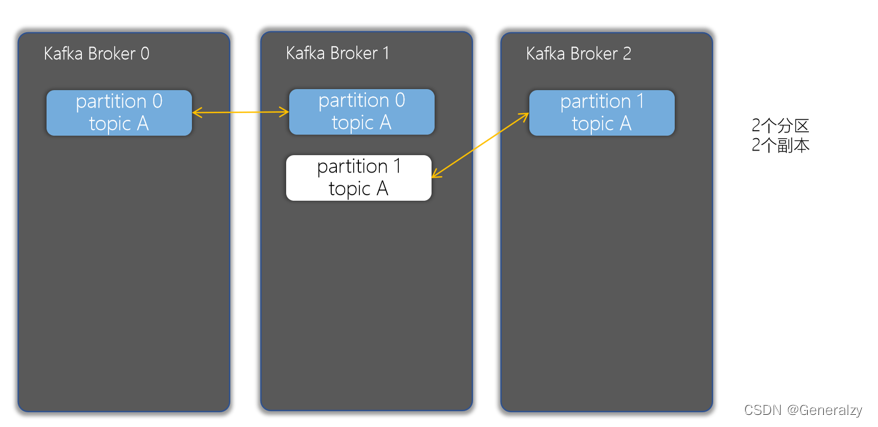
副本可以确保某个服务器出现故障时,确保数据依然可用,在Kafka中,一般都会设计副本的个数>1,
主题(Topic)
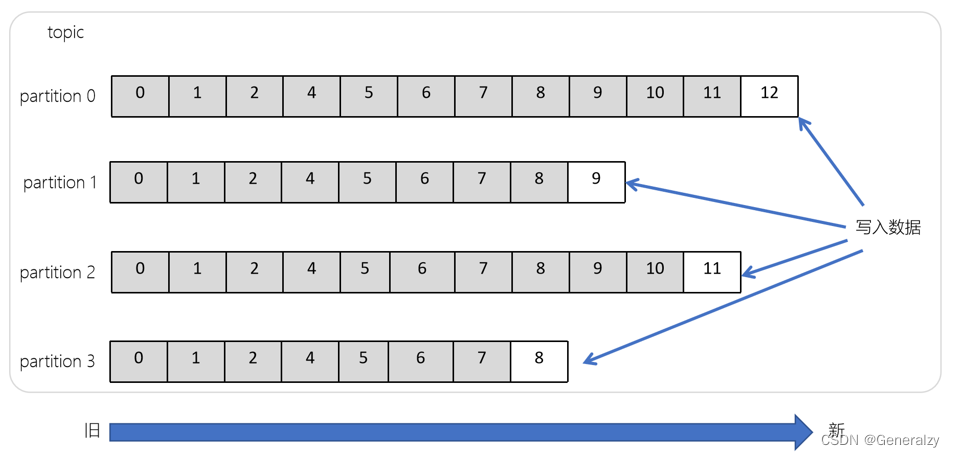
- 主题是一个逻辑概念,用于生产者发布数据,消费者拉取数据
- Kafka中的主题必须要有标识符,而且是唯一的,Kafka中可以有任意数量的主题,没有数量上的限制
- 在主题中的消息是有结构的,一般一个主题包含某一类消息
- 一旦生产者发送消息到主题中,这些消息就不能被更新(更改)
偏移量(offset)
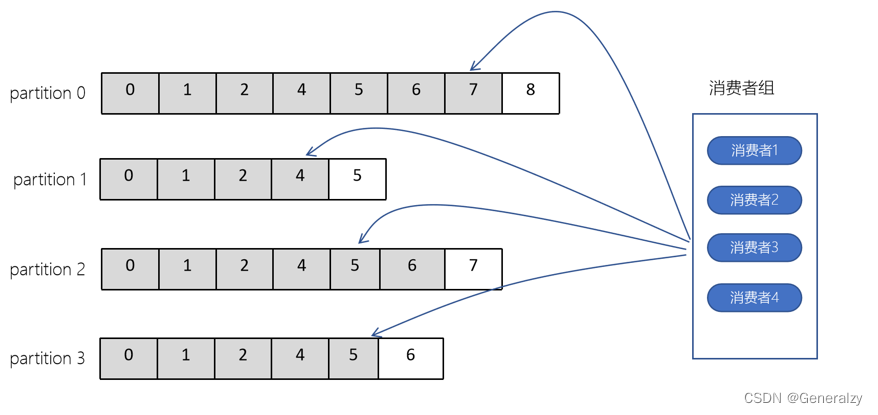
- offset记录着下一条将要发送给Consumer的消息的序号
- 默认Kafka将offset存储在ZooKeeper中
- 在一个分区中,消息是有顺序的方式存储着,每个在分区的消费都是有一个递增的id。这个就是偏移量offset
- 偏移量在分区中才是有意义的。在分区之间,offset是没有任何意义的
消费者组
-
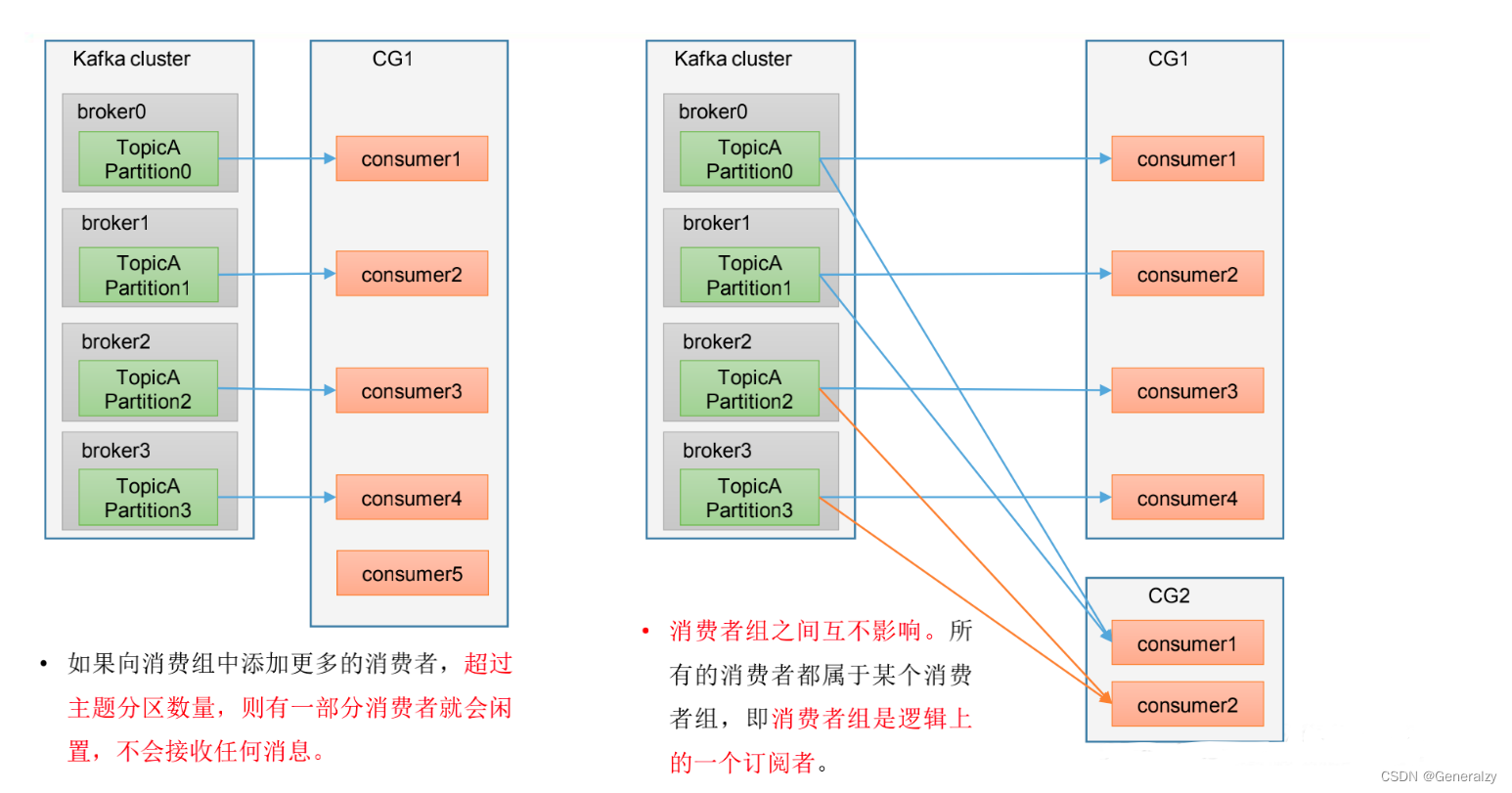
Kafka支持有多个消费者同时消费一个主题中的数据。
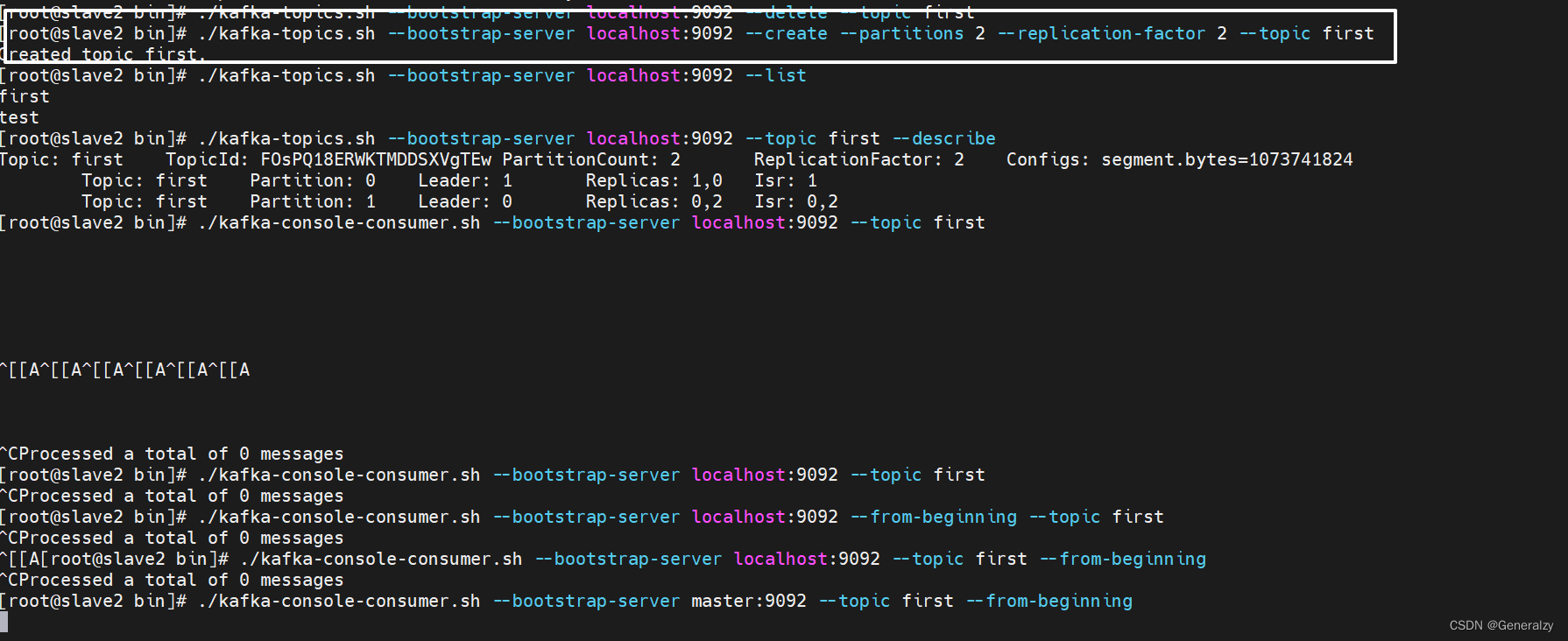
-
同时运行两个消费者,我们发现,只有一个消费者程序能够拉取到消息。想要让两个消费者同时消费消息,必须要给test主题,添加一个分区。
-
设置 test topic为2个分区
bin/kafka-topics.sh --zookeeper 192.168.88.100:2181 -alter --partitions 2 --topic test
Kafka生产者
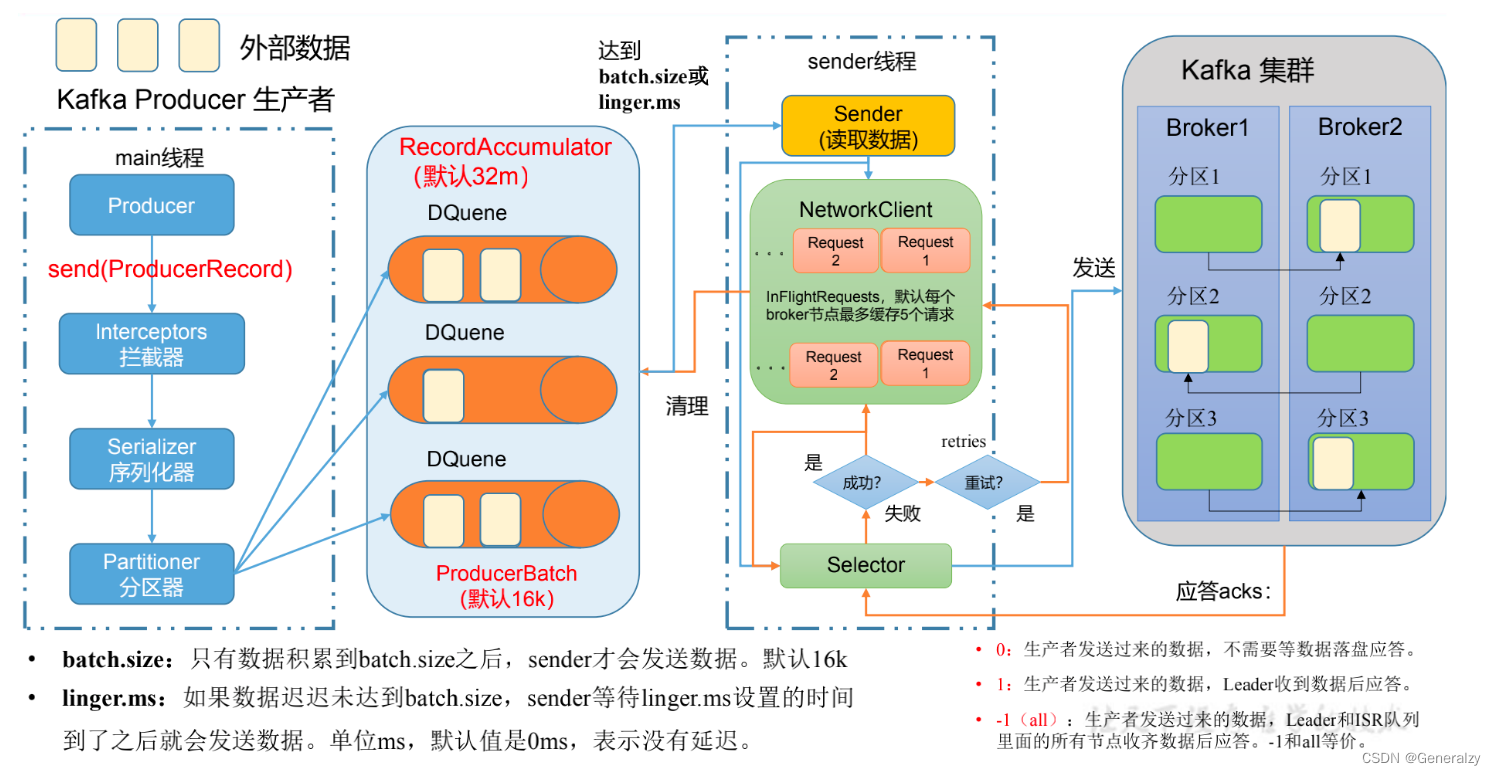
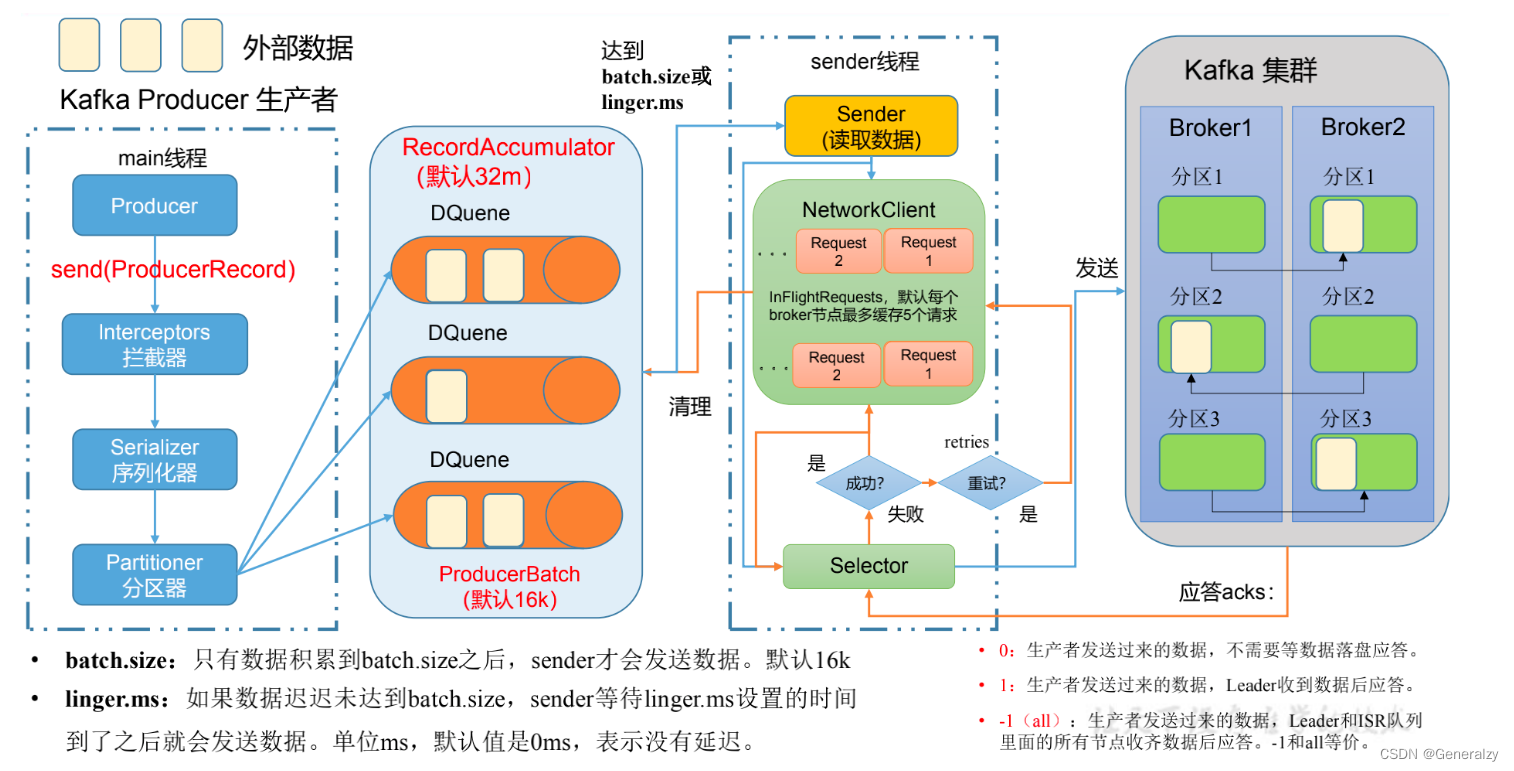
生产者消息发送流程
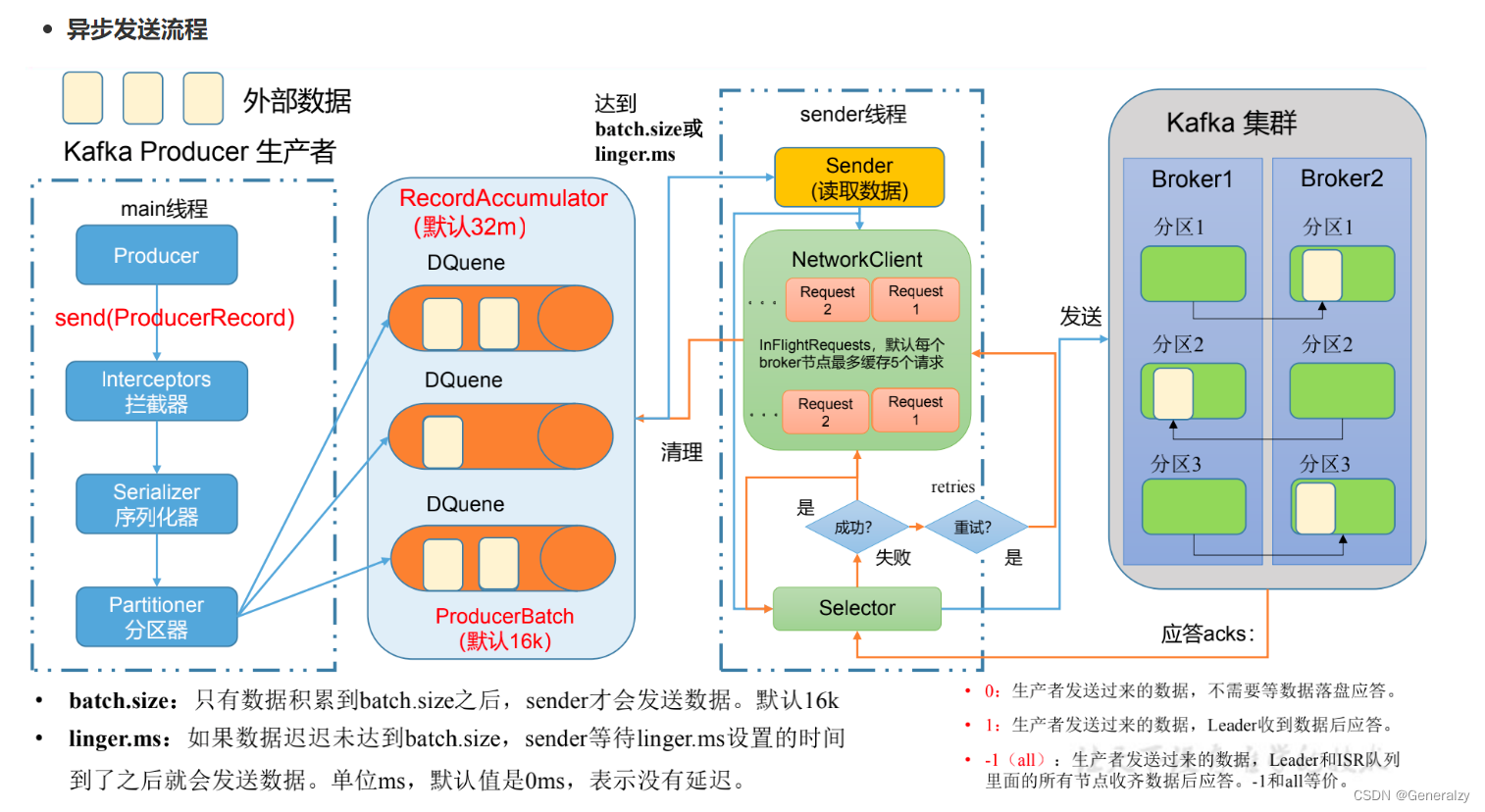
发送原理
在消息发送的过程中,涉及到了两个线程 — main 线程和Sender线程。在main线程中创建了一个双端队列 RecordAccumulator。main线程将消息发送给ResordAccumlator,Sender线程不断从 RecordAccumulator 中拉去消息发送到 Kafka Broker。
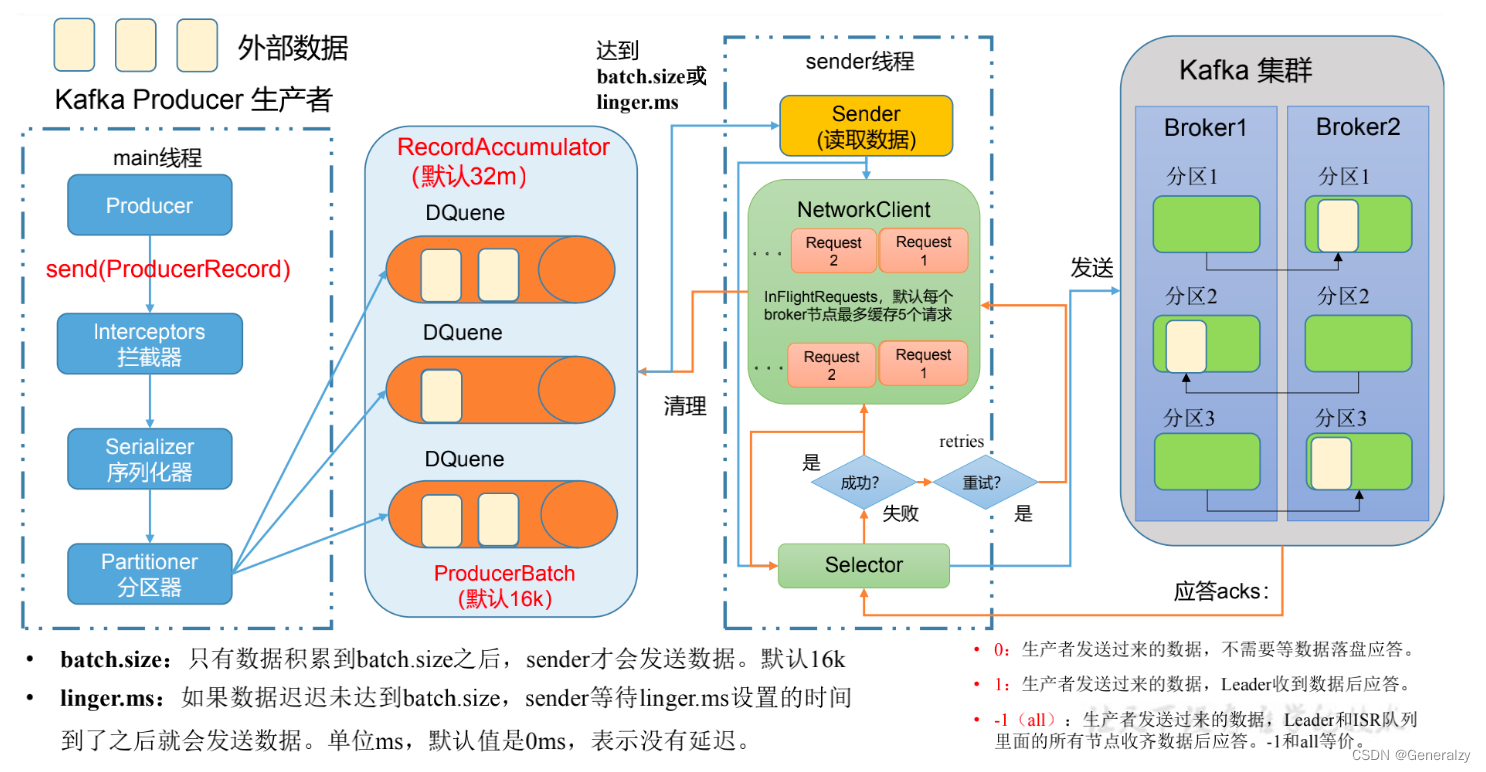
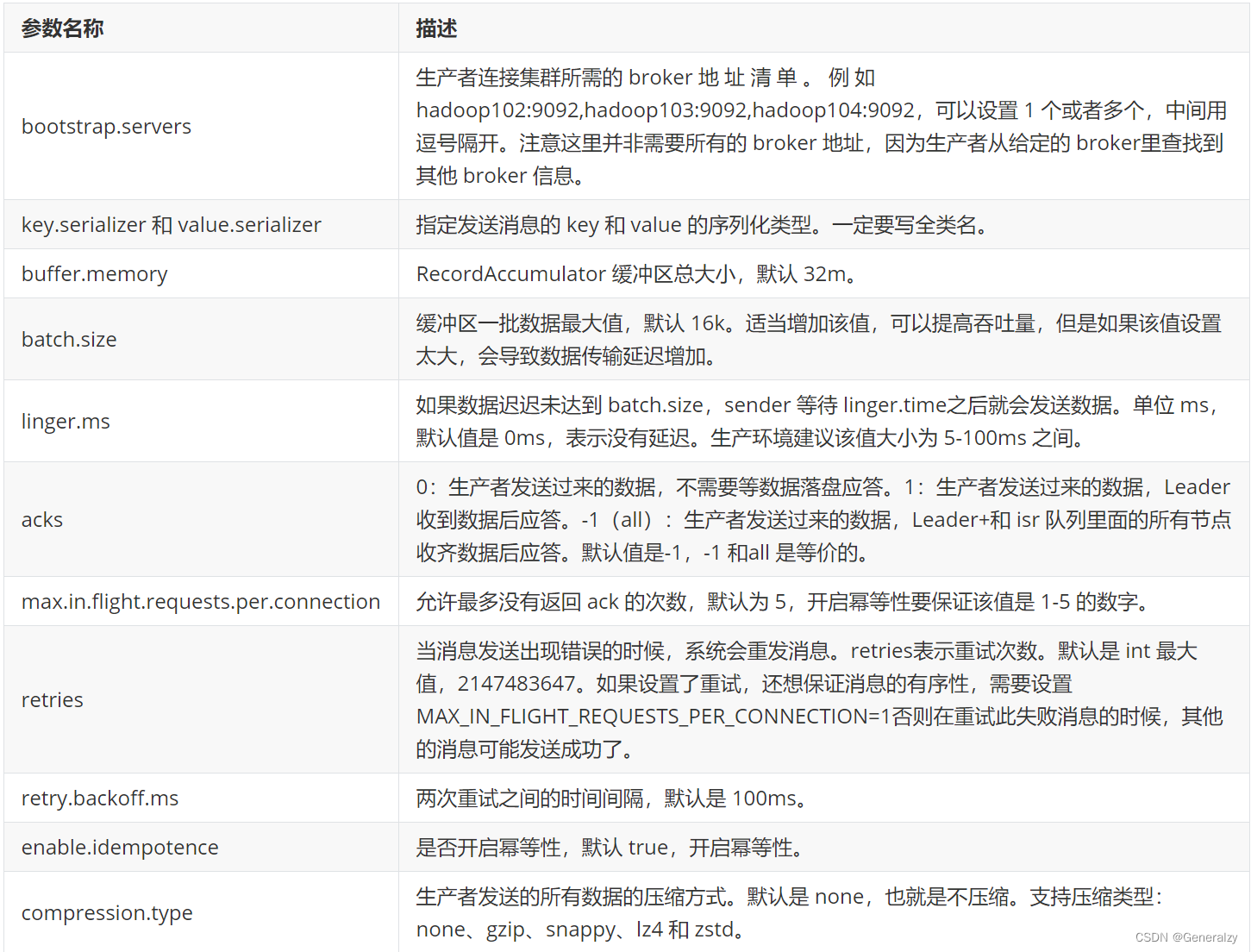
生产者重要参数列表
异步发送API
普通异步发送
- 需求:创建Kafka生产者,采用异步的方式发送到Kafka Broker。
2、代码编程go get github.com/Shopify/sarama
func main() {
config := sarama.NewConfig()
config.Producer.RequiredAcks = sarama.WaitForAll // 发送完数据需要leader和follow都确认
config.Producer.Partitioner = sarama.NewRandomPartitioner // 新选出一个partition
config.Producer.Return.Successes = true // 成功交付的消息将在success channel返回
// 构造一个消息
msg := &sarama.ProducerMessage{}
msg.Topic = "first"
msg.Value = sarama.StringEncoder("this is a test log")
// 连接kafka
client, err := sarama.NewSyncProducer([]string{
"192.168.71.128:9092", "192.168.71.129:9092", "192.168.71.130:9092",
}, config)
if err != nil {
fmt.Println("producer closed, err:", err)
return
} else {
fmt.Println(client)
}
defer client.Close()
// 发送消息
pid, offset, err := client.SendMessage(msg)
if err != nil {
fmt.Println("send msg failed, err:", err)
return
}
fmt.Printf("pid:%v offset:%v\n", pid, offset)
}
带回调函数的异步发送
【注意:】消息发送失败会自动重试,不需要我们在回调函数中手动重试。
同步发送API
生产者分区
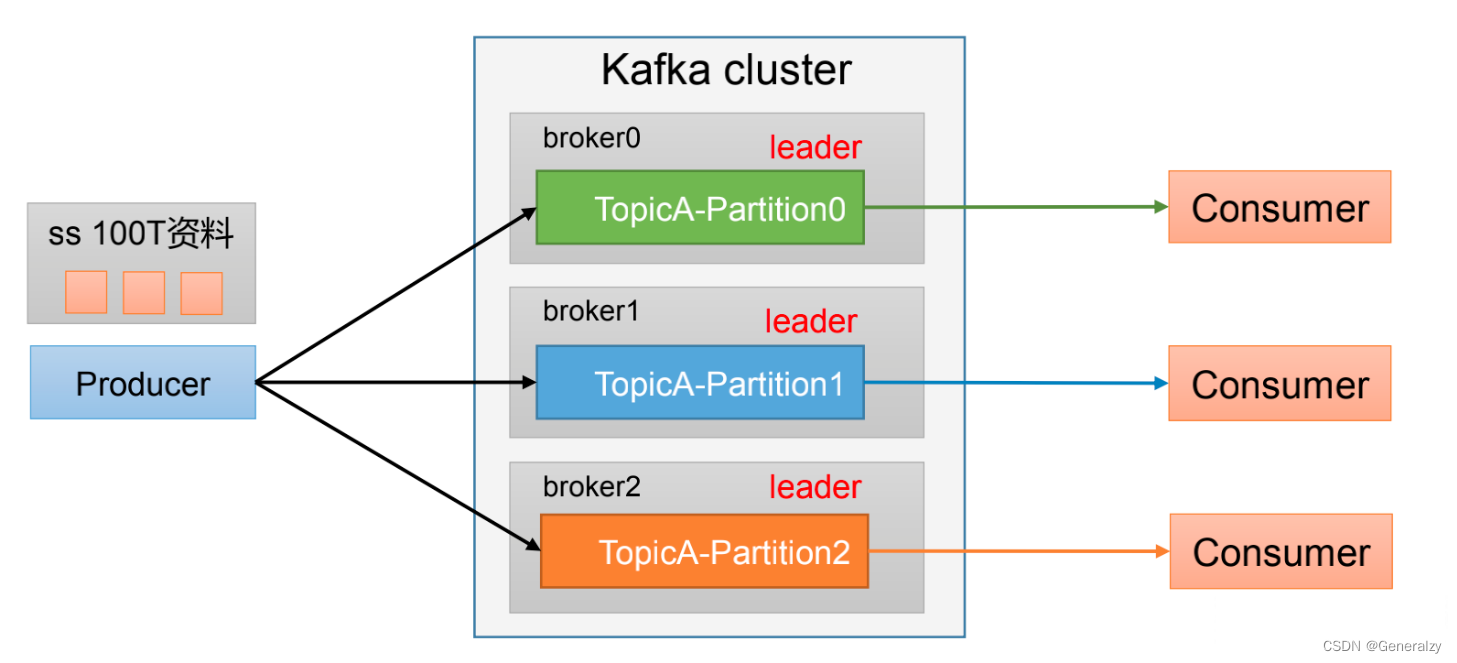
分区和副本机制
生产者写入消息到topic,Kafka将依据不同的策略将数据分配到不同的分区中
- 轮询分区策略
- 随机分区策略
- 按key分区分配策略
- 自定义分区策略
分区好处
-
便于合理使用存储资源,每个Partition在一个Broker上存储,可以把海量的数据按照分区切割成一块一块数据存储在多台Broker上。合理控制分区的任务,可以实现负载均衡的效果。
-
提高并行度,生产者可以以分区为单位发送数据;消费者可以以分区为单位进行 消费数据。
轮询策略
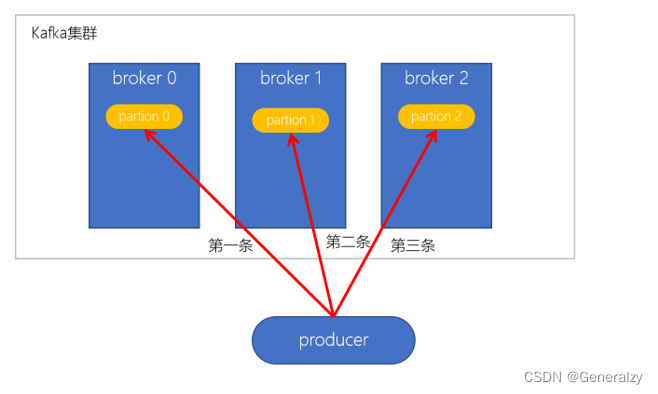
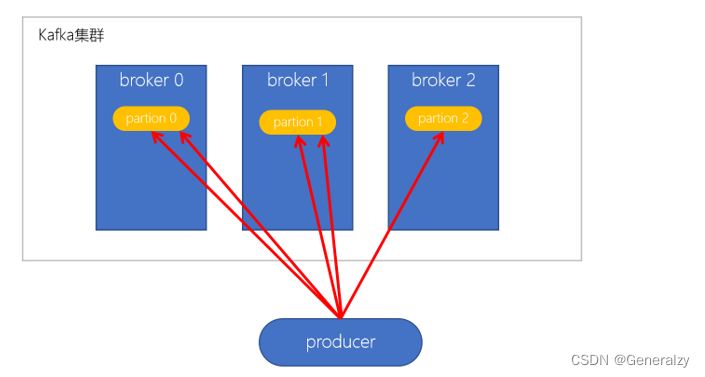
- 默认的策略,也是使用最多的策略,可以最大限度保证所有消息平均分配到一个分区
- 如果在生产消息时,key为null,则使用轮询算法均衡地分配分区
随机策略(不用)
随机策略,每次都随机地将消息分配到每个分区。在较早的版本,默认的分区策略就是随机策略,也是为了将消息均衡地写入到每个分区。但后续轮询策略表现更佳,所以基本上很少会使用随机策略。
按key分配策略
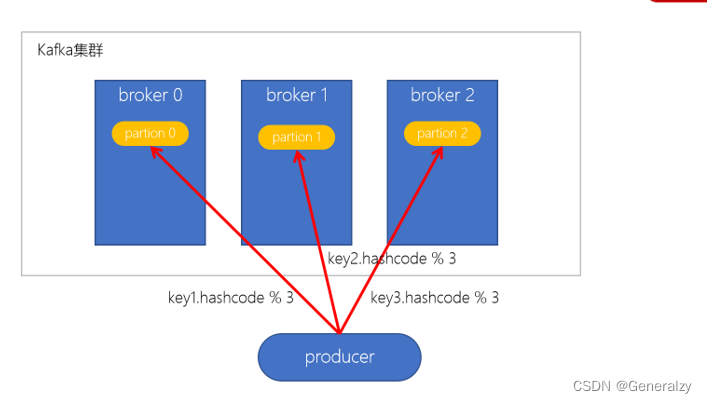
按key分配策略,有可能会出现「数据倾斜」,例如:某个key包含了大量的数据,因为key值一样,所有所有的数据将都分配到一个分区中,造成该分区的消息数量远大于其他的分区。
乱序问题
轮询策略、随机策略都会导致一个问题,生产到Kafka中的数据是乱序存储的。而按key分区可以一定程度上实现数据有序存储——也就是局部有序,但这又可能会导致数据倾斜,所以在实际生产环境中要结合实际情况来做取舍。
副本机制
副本的目的就是冗余备份,当某个Broker上的分区数据丢失时,依然可以保障数据可用。因为在其他的Broker上的副本是可用的。
producer的ACKs参数
对副本关系较大的就是,producer配置的acks参数了,acks参数表示当生产者生产消息的时候,写入到副本的要求严格程度。它决定了生产者如何在性能和可靠性之间做取舍。
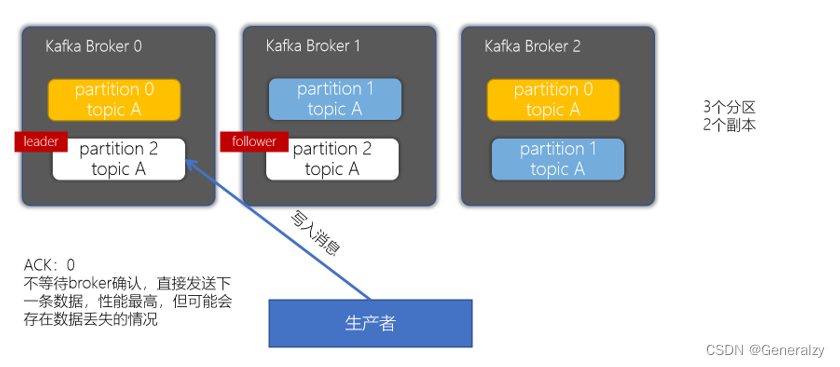
acks配置为0
acks配置为1
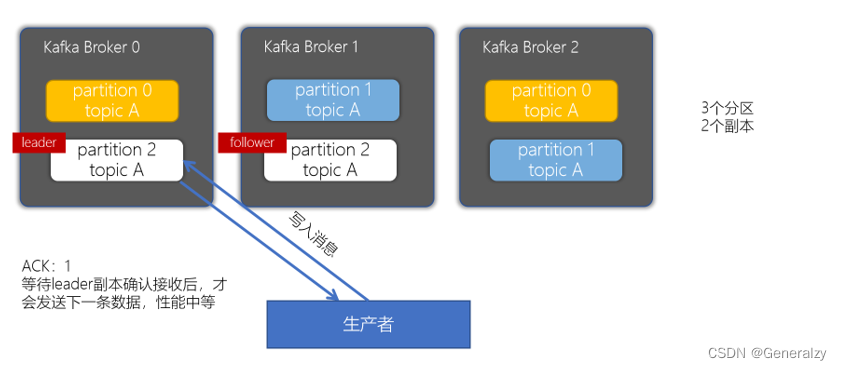
当生产者的ACK配置为1时,生产者会等待leader副本确认接收后,才会发送下一条数据,性能中等。
acks配置为-1或者all
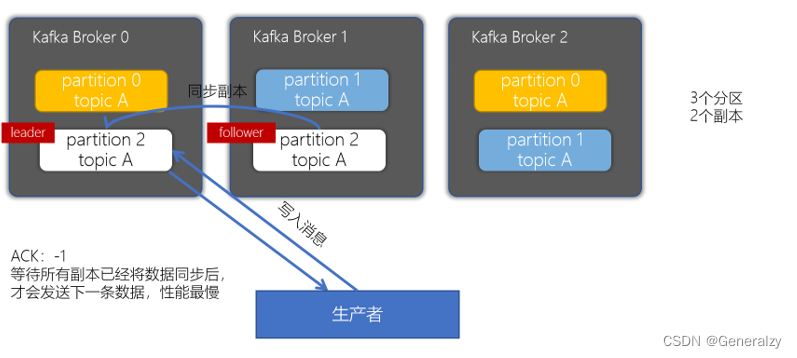
Kafka生产者幂等性与事务
幂等性
拿http举例来说,一次或多次请求,得到地响应是一致的(网络超时等问题除外),换句话说,就是执行多次操作与执行一次操作的影响是一样的。
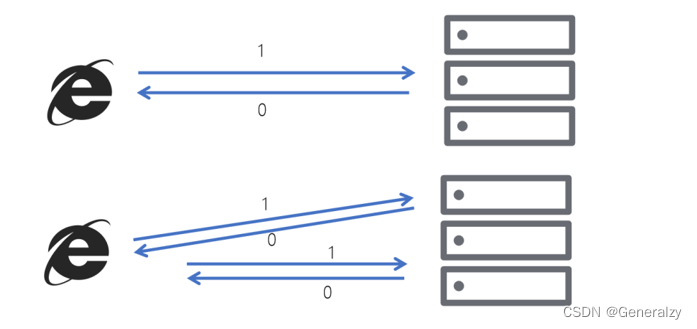
如果,某个系统是不具备幂等性的,如果用户重复提交了某个表格,就可能会造成不良影响。例如:用户在浏览器上点击了多次提交订单按钮,会在后台生成多个一模一样的订单。
Kafka生产者幂等性
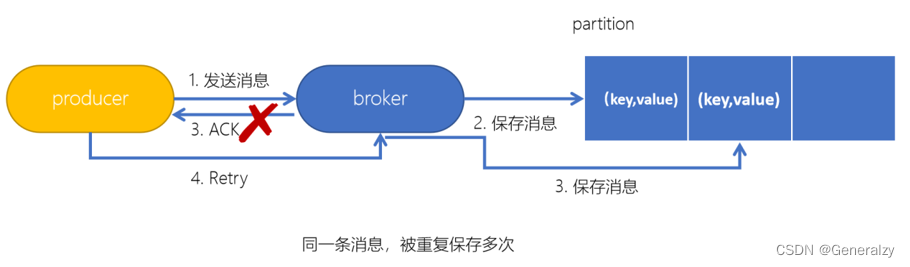
在生产者生产消息时,如果出现retry时,有可能会一条消息被发送了多次,如果Kafka不具备幂等性的,就有可能会在partition中保存多条一模一样的消息。
幂等性原理
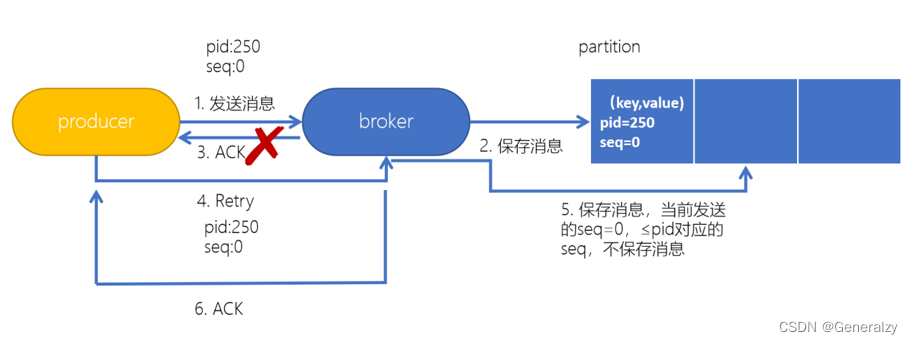
为了实现生产者的幂等性,Kafka引入了 Producer ID(PID)和 Sequence Number的概念。
- PID:每个Producer在初始化时,都会分配一个唯一的PID,这个PID对用户来说,是透明的。
- Sequence Number:针对每个生产者(对应PID)发送到指定主题分区的消息都对应一个从0开始递增的Sequence Number。
- 幂等性只能保证的是在单分区单会话内不重复
Kafka事务
-
Kafka事务是2017年Kafka 0.11.0.0引入的新特性。类似于数据库的事务。Kafka事务指的是生产者生产消息以及消费者提交offset的操作可以在一个原子操作中,要么都成功,要么都失败。尤其是在生产者、消费者并存时,事务的保障尤其重要。(consumer-transform-producer模式)
-
开启事务,必须开启幂等性
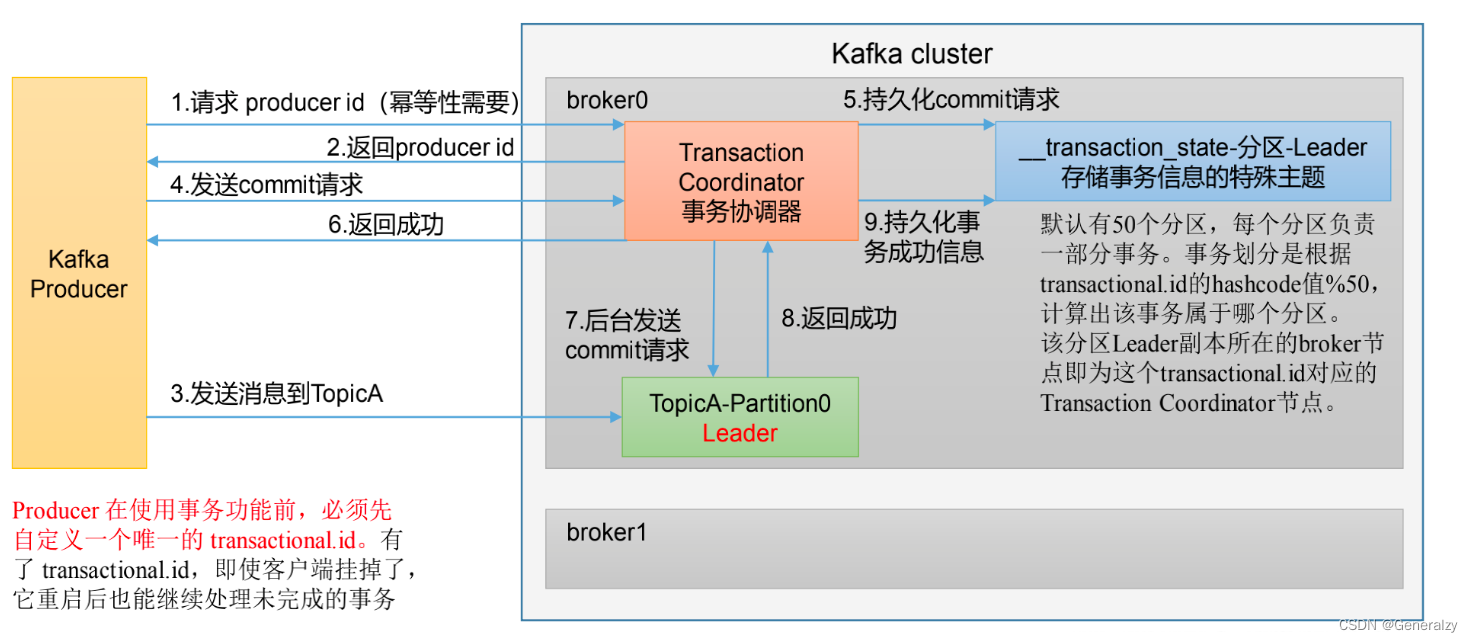
事务操作API
Producer接口中定义了以下5个事务相关方法:
- initTransactions(初始化事务):要使用Kafka事务,必须先进行初始化操作
- beginTransaction(开始事务):启动一个Kafka事务
- sendOffsetsToTransaction(提交偏移量):批量地将分区对应的offset发送到事务中,方便后续一块提交
- commitTransaction(提交事务):提交事务
- abortTransaction(放弃事务):取消事务
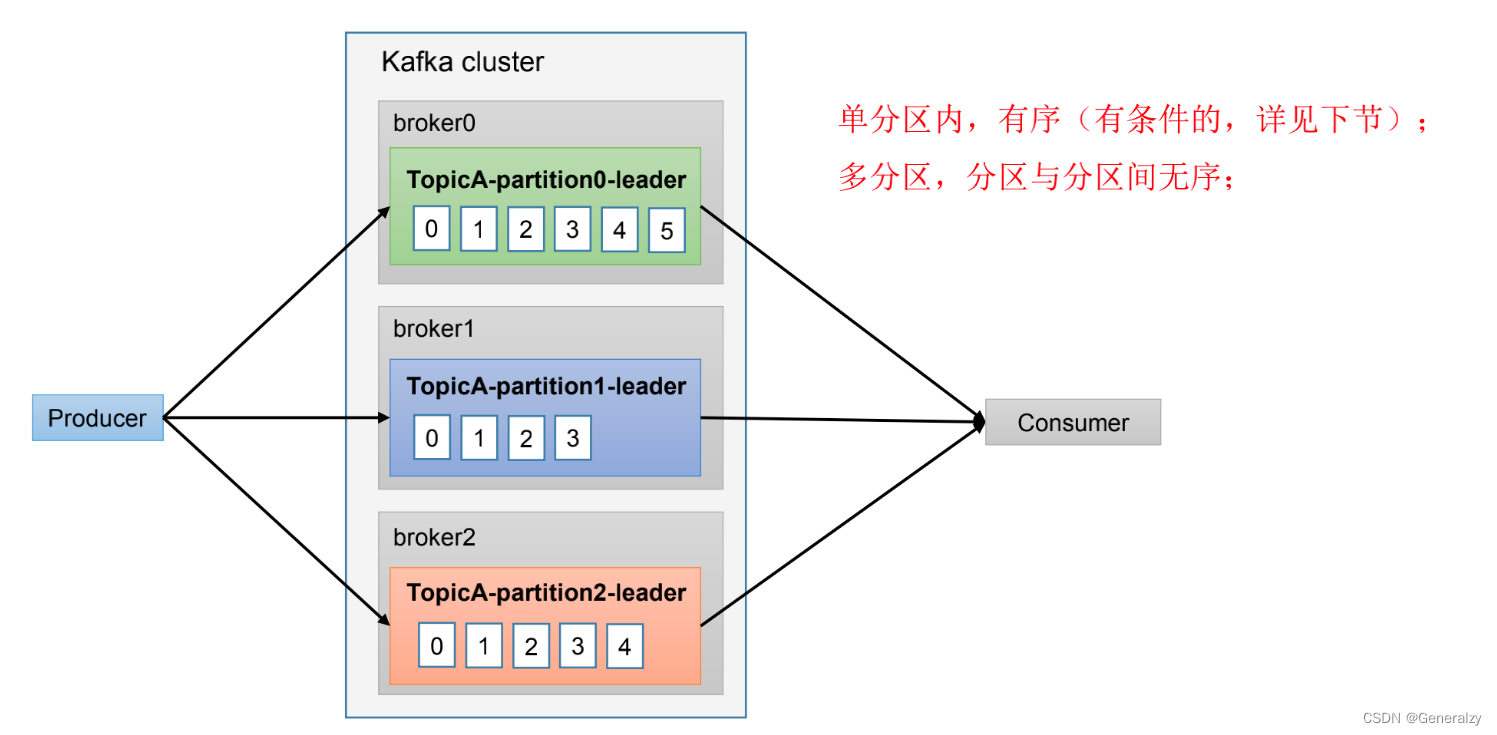
数据有序和数据乱序
Kafka Broker
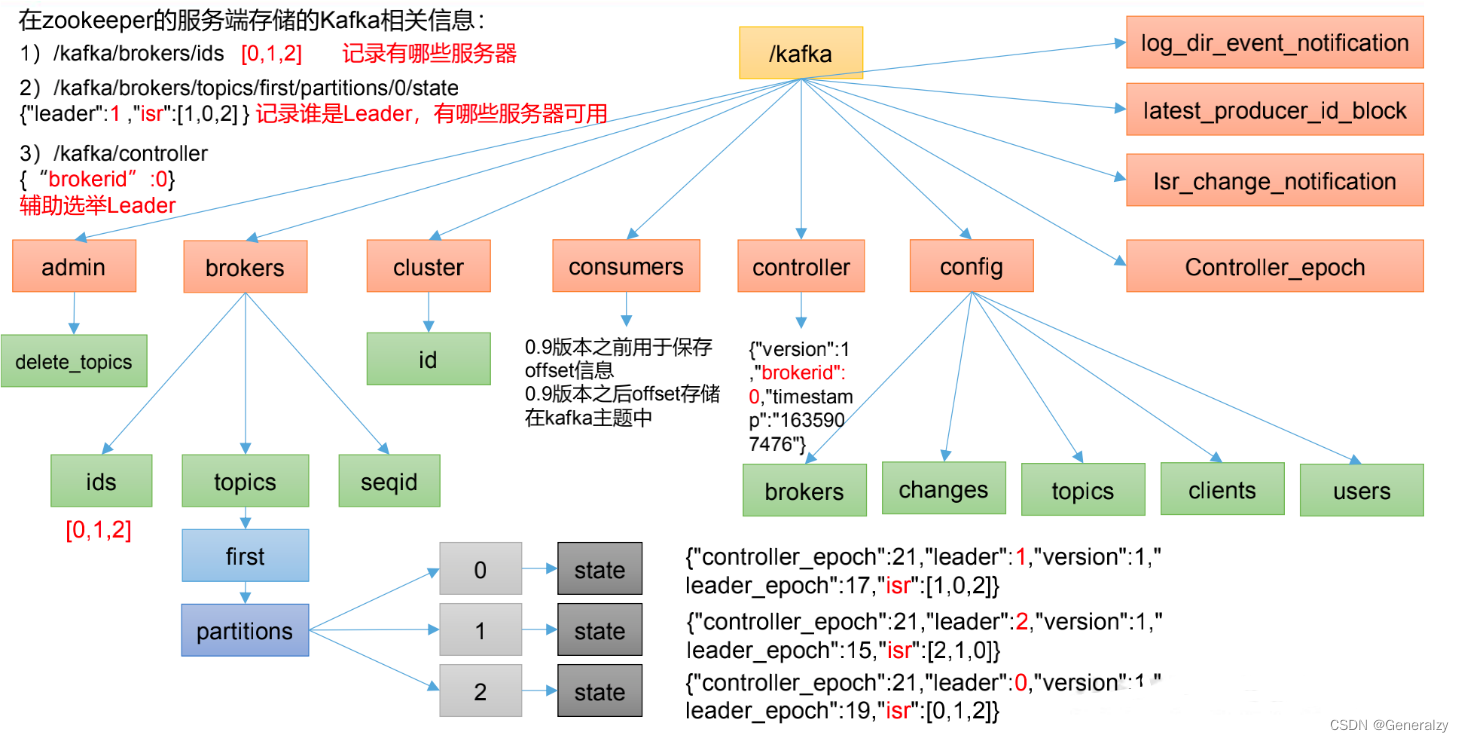
Zookeeper存储的Kafka信息
[zk: localhost:2181(CONNECTING) 0] ls /
[admin, brokers, cluster, config, consumers, controller, controller_epoch, feature, isr_change_notification, latest_producer_id_block, log_dir_event_notification, zookeeper]
Kafka Broker总体工作流程
Broker重要参数


Kafka副本
副本基本信息
- Kafka副本作用:提高数据可靠性。
- Kafka默认副本1个,生产环境一般配置为2个,保证数据可靠性;太多副本会增加磁盘存储空间,增加网络上数据传输,降低效率。
- Kafka中副本为:Leader和Follower。Kafka生产者只会把数据发往 Leader,然后Follower 找 Leader 进行同步数据。
- Kafka 分区中的所有副本统称为 AR(Assigned Repllicas)。
AR = ISR + OSR
ISR:表示 Leader 保持同步的 Follower 集合。如果 Follower 长时间未 向 Leader 发送通信请求或同步数据,则该 Follower 将被踢出 ISR。该时间阈值由 replica.lag.time.max.ms 参数设定,默认 30s 。Leader 发生故障之后,就会从 ISR 中选举新的 Leader。
OSR:表示 Follower 与 Leader 副本同步时,延迟过多的副本。
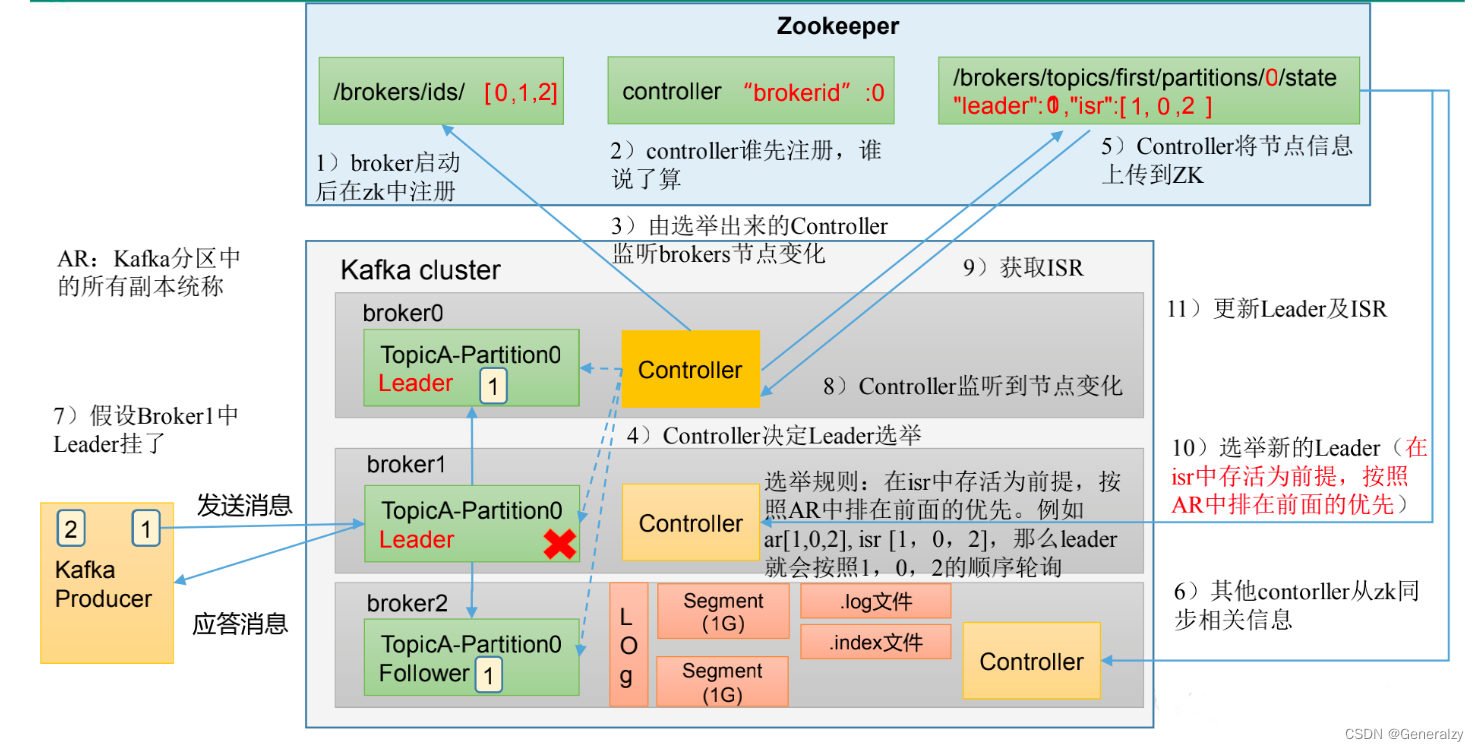
Leader 选举流程
Kafka 集群中有一个 broker 的 Controller 会被选举为 Controller Leader ,负责管理集群 broker 的上下线,所有 topic 的分区副本分配 和 Leader 选举等工作。
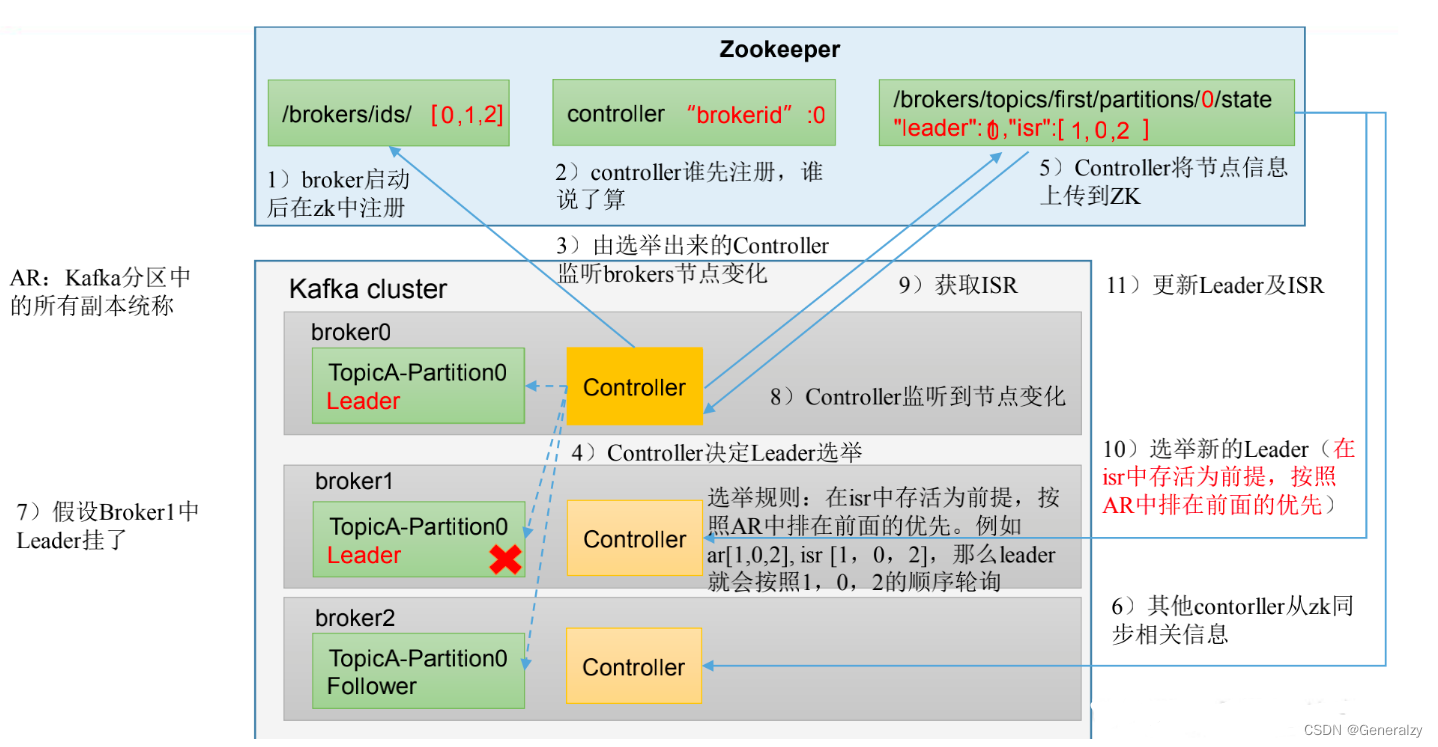
- 创建一个新的 topic,4 个分区,4 个副本
[atguigu@hadoop102 kafka]$ bin/kafka-topics.sh --bootstrap-server hadoop102:9092 --create --topic atguigu1 --partitions 4 --replication-factor 4
Created topic atguigu1.
- 查看 Leader 分布情况
[atguigu@hadoop102 kafka]$ bin/kafka-topics.sh --bootstrap-server hadoop102:9092 --describe
--topic atguigu1
Topic: atguigu1 TopicId: awpgX_7WR-OX3Vl6HE8sVg PartitionCount: 4 ReplicationFactor: 4
Configs: segment.bytes=1073741824
Topic: atguigu1 Partition: 0 Leader: 3 Replicas: 3,0,2,1 Isr: 3,0,2,1
Topic: atguigu1 Partition: 1 Leader: 1 Replicas: 1,2,3,0 Isr: 1,2,3,0
Topic: atguigu1 Partition: 2 Leader: 0 Replicas: 0,3,1,2 Isr: 0,3,1,2
Topic: atguigu1 Partition: 3 Leader: 2 Replicas: 2,1,0,3 Isr: 2,1,0,3
- 停止掉 hadoop105 的 kafka 进程,并查看 Leader 分区情况
[atguigu@hadoop105 kafka]$ bin/kafka-server-stop.sh
[atguigu@hadoop102 kafka]$ bin/kafka-topics.sh --bootstrap-server hadoop102:9092 --describe
--topic atguigu1
Topic: atguigu1 TopicId: awpgX_7WR-OX3Vl6HE8sVg PartitionCount: 4 ReplicationFactor: 4
Configs: segment.bytes=1073741824
Topic: atguigu1 Partition: 0 Leader: 0 Replicas: 3,0,2,1 Isr: 0,2,1
Topic: atguigu1 Partition: 1 Leader: 1 Replicas: 1,2,3,0 Isr: 1,2,0
Topic: atguigu1 Partition: 2 Leader: 0 Replicas: 0,3,1,2 Isr: 0,1,2
Topic: atguigu1 Partition: 3 Leader: 2 Replicas: 2,1,0,3 Isr: 2,1,0
- 停止掉 hadoop104 的 kafka 进程,并查看 Leader 分区情况
[atguigu@hadoop104 kafka]$ bin/kafka-server-stop.sh
[atguigu@hadoop102 kafka]$ bin/kafka-topics.sh --bootstrap-server hadoop102:9092 --describe
--topic atguigu1
Topic: atguigu1 TopicId: awpgX_7WR-OX3Vl6HE8sVg PartitionCount: 4 ReplicationFactor: 4
Configs: segment.bytes=1073741824
Topic: atguigu1 Partition: 0 Leader: 0 Replicas: 3,0,2,1 Isr: 0,1
Topic: atguigu1 Partition: 1 Leader: 1 Replicas: 1,2,3,0 Isr: 1,0
Topic: atguigu1 Partition: 2 Leader: 0 Replicas: 0,3,1,2 Isr: 0,1
Topic: atguigu1 Partition: 3 Leader: 1 Replicas: 2,1,0,3 Isr: 1,0
- 启动 hadoop105 的 kafka 进程,并查看 Leader 分区情况
[atguigu@hadoop105 kafka]$ bin/kafka-server-start.sh -daemon config/server.properties
[atguigu@hadoop102 kafka]$ bin/kafka-topics.sh --bootstrap-server hadoop102:9092 --describe
--topic atguigu1
Topic: atguigu1 TopicId: awpgX_7WR-OX3Vl6HE8sVg PartitionCount: 4 ReplicationFactor: 4
Configs: segment.bytes=1073741824
Topic: atguigu1 Partition: 0 Leader: 0 Replicas: 3,0,2,1 Isr: 0,1,3
Topic: atguigu1 Partition: 1 Leader: 1 Replicas: 1,2,3,0 Isr: 1,0,3
Topic: atguigu1 Partition: 2 Leader: 0 Replicas: 0,3,1,2 Isr: 0,1,3
Topic: atguigu1 Partition: 3 Leader: 1 Replicas: 2,1,0,3 Isr: 1,0,3
- 启动 hadoop104 的 kafka 进程,并查看 Leader 分区情况
[atguigu@hadoop104 kafka]$ bin/kafka-server-start.sh -daemon config/server.properties
[atguigu@hadoop102 kafka]$ bin/kafka-topics.sh --bootstrap-server hadoop102:9092 --describe
--topic atguigu1
Topic: atguigu1 TopicId: awpgX_7WR-OX3Vl6HE8sVg PartitionCount: 4 ReplicationFactor: 4
Configs: segment.bytes=1073741824
Topic: atguigu1 Partition: 0 Leader: 0 Replicas: 3,0,2,1 Isr: 0,1,3,2
Topic: atguigu1 Partition: 1 Leader: 1 Replicas: 1,2,3,0 Isr: 1,0,3,2
Topic: atguigu1 Partition: 2 Leader: 0 Replicas: 0,3,1,2 Isr: 0,1,3,2
Topic: atguigu1 Partition: 3 Leader: 1 Replicas: 2,1,0,3 Isr: 1,0,3,2
- 停止掉 hadoop103 的 kafka 进程,并查看 Leader 分区情况
[atguigu@hadoop103 kafka]$ bin/kafka-server-stop.sh
[atguigu@hadoop102 kafka]$ bin/kafka-topics.sh --bootstrap-server hadoop102:9092 --describe
--topic atguigu1
Topic: atguigu1 TopicId: awpgX_7WR-OX3Vl6HE8sVg PartitionCount: 4 ReplicationFactor: 4
Configs: segment.bytes=1073741824
Topic: atguigu1 Partition: 0 Leader: 0 Replicas: 3,0,2,1 Isr: 0,3,2
Topic: atguigu1 Partition: 1 Leader: 2 Replicas: 1,2,3,0 Isr: 0,3,2
Topic: atguigu1 Partition: 2 Leader: 0 Replicas: 0,3,1,2 Isr: 0,3,2
Topic: atguigu1 Partition: 3 Leader: 2 Replicas: 2,1,0,3 Isr: 0,3,2
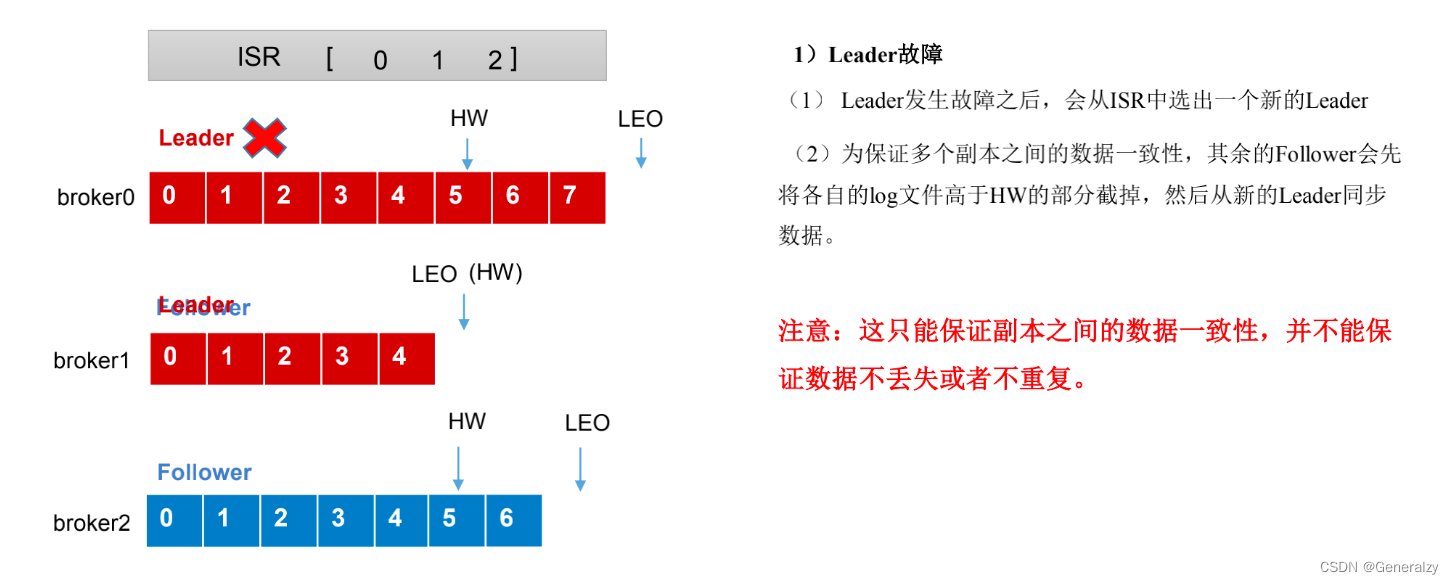
Leader 和 Follower 故障处理细节
LEO(Log End Offset): 每个副本的最后一个offset,LEO其实就是最新的 offset + 1。
HW(High Watermark):所有副本中最小的LEO。
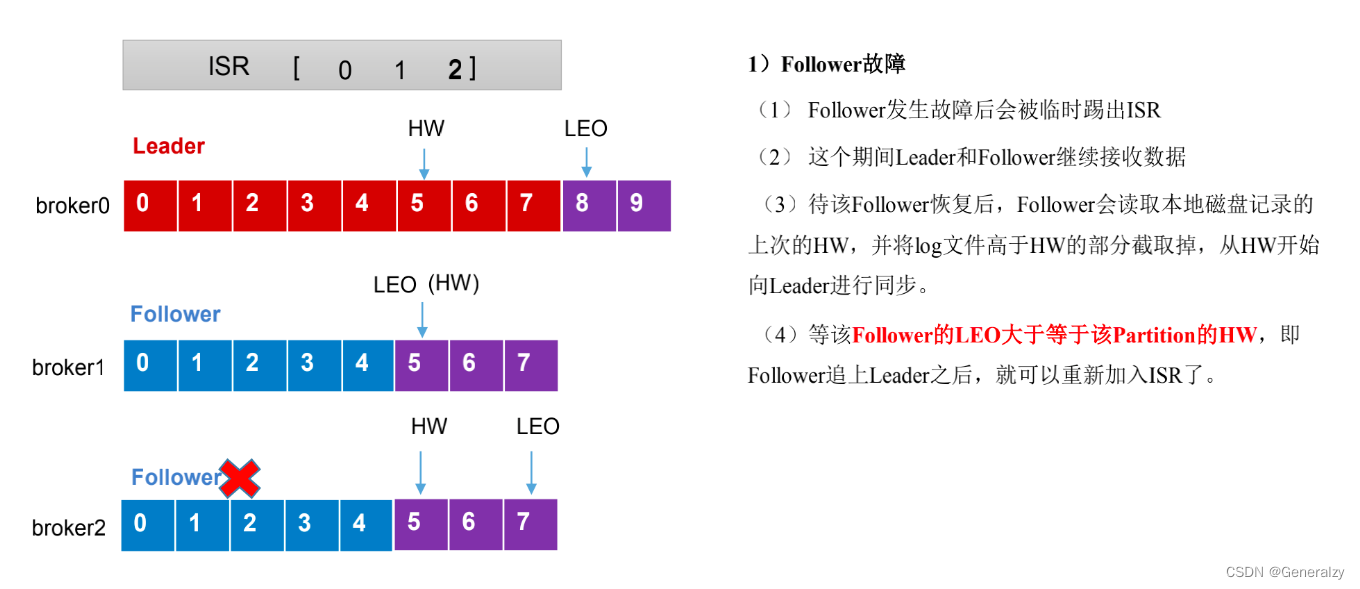
LEO(Log End Offset):每个副本的最后一个offset,LEO其实就是最新的offset + 1
HW(High Watermark):所有副本中最小的LEO
活动调整分区副本存储
在生产环境中,每台服务器的配置和性能不一致,但是kafka只会根据自己的代码规则创建对应的分区副本,就会导致个别服务器存储压力较大。所有需要手动调整分区副本的存储。
需求:创建一个新的 topic ,4个分区,两个副本,名称为three 。将该 topic 的所有副本都存储到 broker0 和 broker1 两台服务器上。
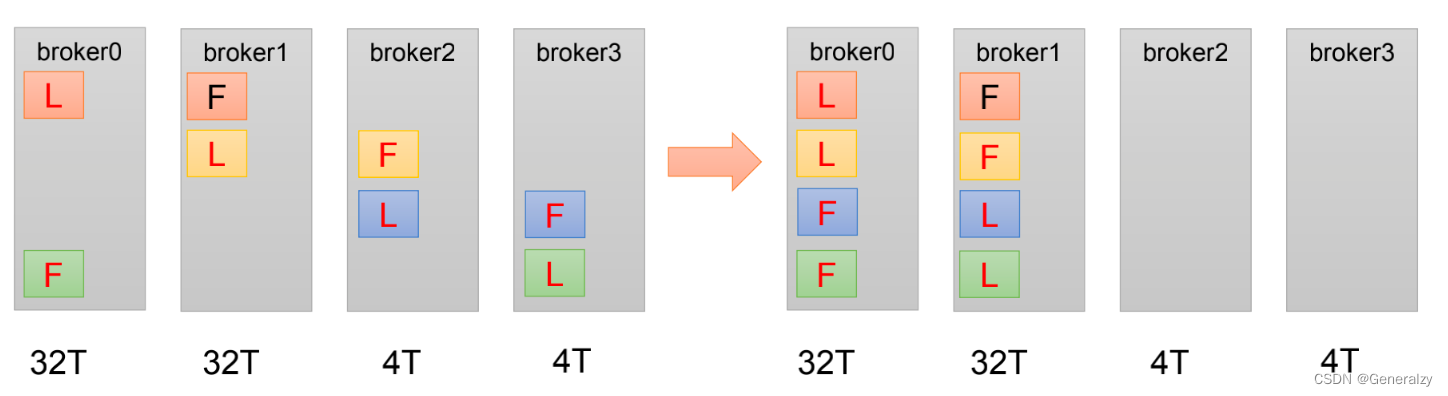
手动调整分区副本存储的步骤如下:
- 创建一个新的 topic,名称为 three。
[atguigu@hadoop102 kafka]$ bin/kafka-topics.sh --bootstrap-server
hadoop102:9092 --create --partitions 4 --replication-factor 2 --
topic three
- 查看分区副本存储情况
[atguigu@hadoop102 kafka]$ bin/kafka-topics.sh --bootstrap-server
hadoop102:9092 --describe --topic three
- 创建副本存储计划(所有副本都指定存储在 broker0、broker1 中)。
[atguigu@hadoop102 kafka]$ vim increase-replication-factor.json
输入如下内容:
{
"version":1,
"partitions":[{"topic":"three","partition":0,"replicas":[0,1]},
{"topic":"three","partition":1,"replicas":[0,1]},
{"topic":"three","partition":2,"replicas":[1,0]},
{"topic":"three","partition":3,"replicas":[1,0]}]
}
- 执行副本存储计划。
[atguigu@hadoop102 kafka]$ bin/kafka-reassign-partitions.sh --
bootstrap-server hadoop102:9092 --reassignment-json-file
increase-replication-factor.json --execute
- 验证副本存储计划。
[atguigu@hadoop102 kafka]$ bin/kafka-reassign-partitions.sh --
bootstrap-server hadoop102:9092 --reassignment-json-file
increase-replication-factor.json --verify
- 查看分区副本存储情况。
[atguigu@hadoop102 kafka]$ bin/kafka-topics.sh --bootstrap-server
hadoop102:9092 --describe --topic three
Leader Partition 负载平衡
正常情况下,Kafka本身会自动把Leader Partition均匀分散在各个机器上,来保证每台机器的读写吞吐量都是均匀的。但是如果某 些broker宕机,会导致Leader Partition过于集中在其他少部分几台broker上,这会导致少数几台broker的读写请求压力过高,其他宕机的broker重启之后都是follower partition,读写请求很低,造成集群负载不均衡。

| 参数名称 | 描述 |
|---|---|
| auto.leader.rebalance.enable | 默认是 true。 自动 Leader Partition 平衡。生产环 境中,leader 重选举的代价比较大,可能会带来 性能影响,建议设置为 false 关闭。 |
| leader.imbalance.per.broker.percentage | 默认是 10%。每个 broker 允许的不平衡的 leader 的比率。如果每个 broker 超过了这个值,控制器 会触发 leader 的平衡。 |
| leader.imbalance.check.interval.seconds | 默认值 300 秒。检查 leader 负载是否平衡的间隔 时间。 |
文件存储
Topic 数据的存储机制
查看 hadoop102(或者 hadoop103、hadoop104)的/opt/module/kafka/datas/first-1 (first-0、first-2)路径上的文件
[atguigu@hadoop104 first-1]$ ls
00000000000000000092.index
00000000000000000092.log
00000000000000000092.snapshot
00000000000000000092.timeindex
leader-epoch-checkpoint
partition.metadata
直接查看 log 日志,发现是乱码。
通过工具查看 index 和 log 信息。
[atguigu@hadoop104 first-1]$ kafka-run-class.sh kafka.tools.DumpLogSegments
--files ./00000000000000000000.index
Dumping ./00000000000000000000.index
offset: 3 position: 152
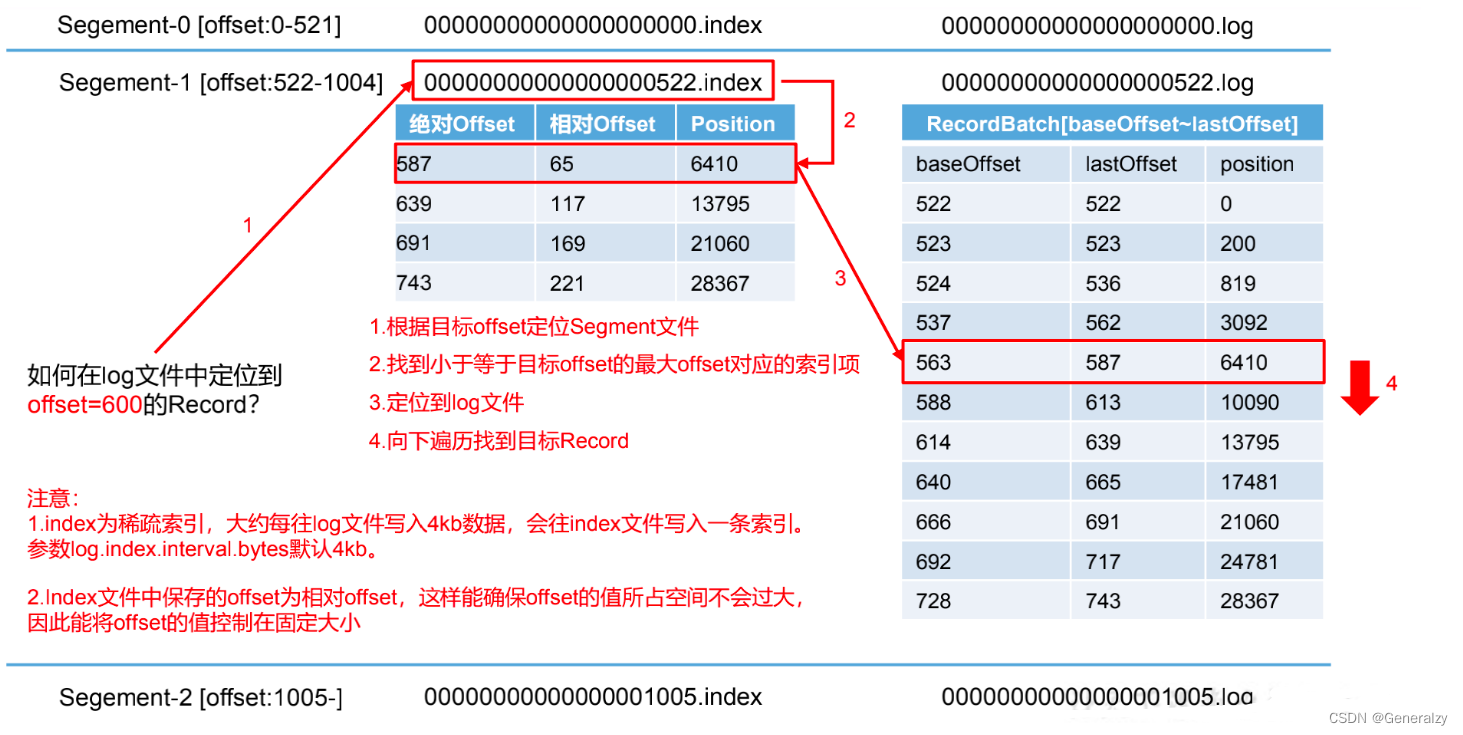
日志存储参数配置
| 参数 | 描述 |
|---|---|
| log.segment.bytes | Kafka 中 log 日志是分成一块块存储的,此配置是指 log 日志划分 成块的大小,默认值 1G。 |
| log.index.interval.bytes | 默认 4kb,kafka 里面每当写入了 4kb 大小的日志(.log), 然后就往 index 文件里面记录一个索引。 稀疏索引。 |
文件清理策略
Kafka 中默认的日志保存时间为 7 天,可以通过调整如下参数修改保存时间。
- Log.retention.hours,最低优先级小时,默认7天。
- log.retention.minutes,分钟。
- log.retention.ms,最高优先级毫秒。
- log.retention.check.interval.ms,负责设置检查周期,默认 5 分钟。
那么日志一旦超过了设置的时间,怎么处理呢?
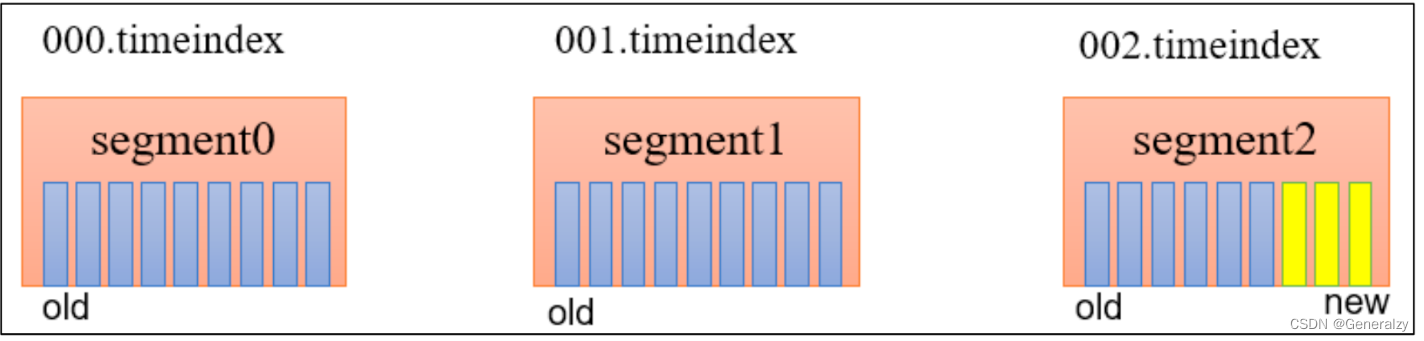
Kafka 中提供的日志清理策略有 delete 和 compact 两种。
- delete 日志阐述:将过期数据删除
- log.cleanup.policy = delete 所有数据启用阐述策略
(1) 基于时间:默认打开。以 segment 中所有记录中的最大时间戳作为该文件时间戳。
(2) 基于大小:默认关闭。超过设置的所有日志总大小,阐述最早的 segment 。
log.retention.bytes,默认等于-1,表示无穷大。
- compact 日志压缩
compact日志压缩:对于相同 key 的不同 value 值,值保留最后一个版本。
- log.cleanup.policy = compact所有数据启动压缩策略
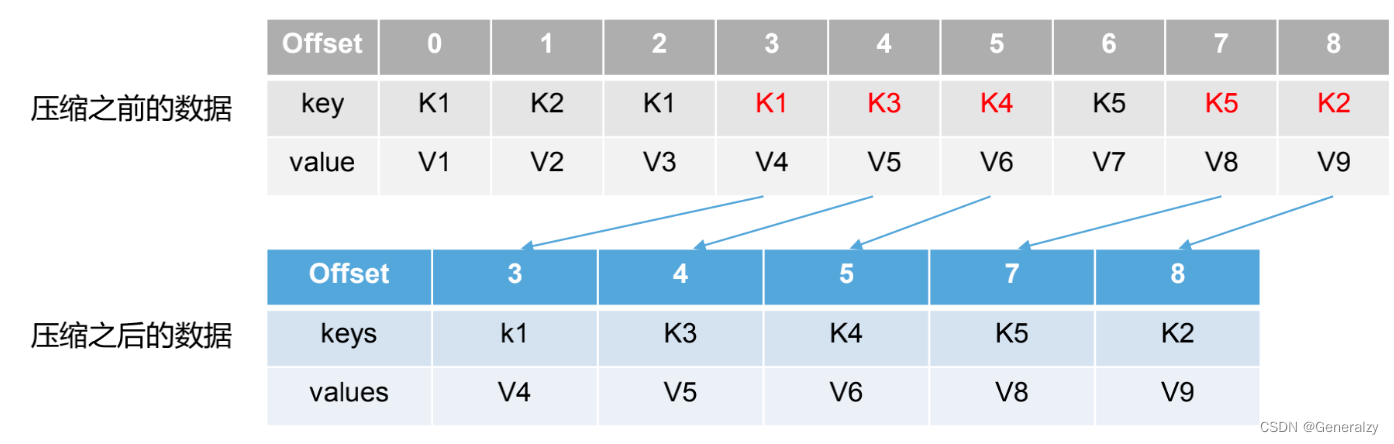
压缩后的offset可能是不连续的,比如上图中没有6,当从这些offset消费消息时,将会拿到比这个 offset 大的 offset 对应的消息,实际上会拿到 offset 为 7 的消息,并从这个位置开始消费。
这种策略只适合特殊场景,比如消息的 key 是用户 ID,value 是用户的资料,通过这种压缩策略,整个消息集里就保存了所有用户最新的资料。
Kafka 消费者
Kafka 消费方式
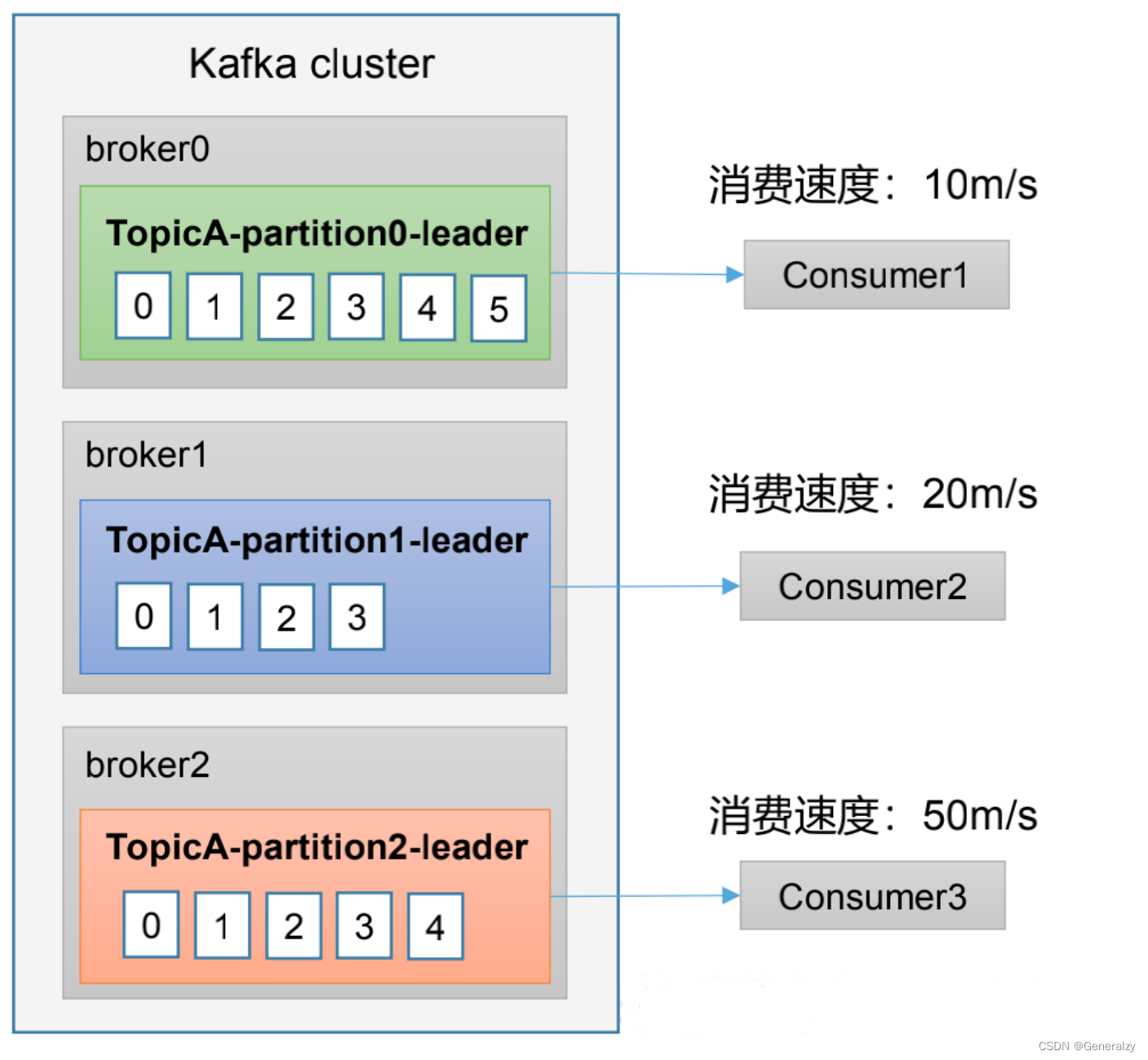
- pull(拉)模式:consumer 采用从 broker 中主动拉去数据。Kafka 采用这种方式。
- push(推)模式:Kafka没有采用这种方式,因为由 broker 决定消息发送速率,很难适应所有消费者的消费速率。例如推送的速度是 50m/s,Consumer1,Consumer2就来不及处理消息。
pull 模式不足之处是,如果Kafka 没有数据,消费者可能会陷入循环中,一直返回空数据。
Kafka 消费者工作流程
消费者组原理
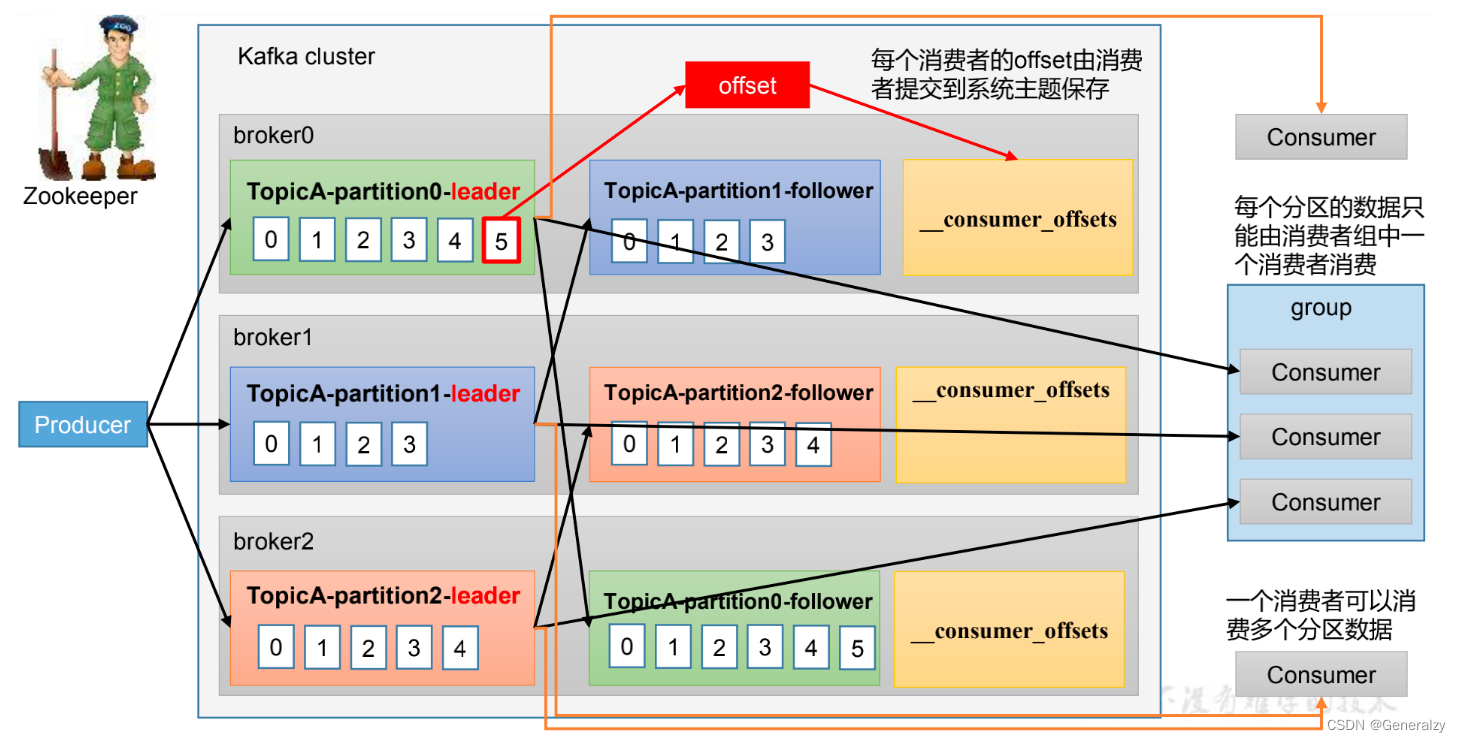
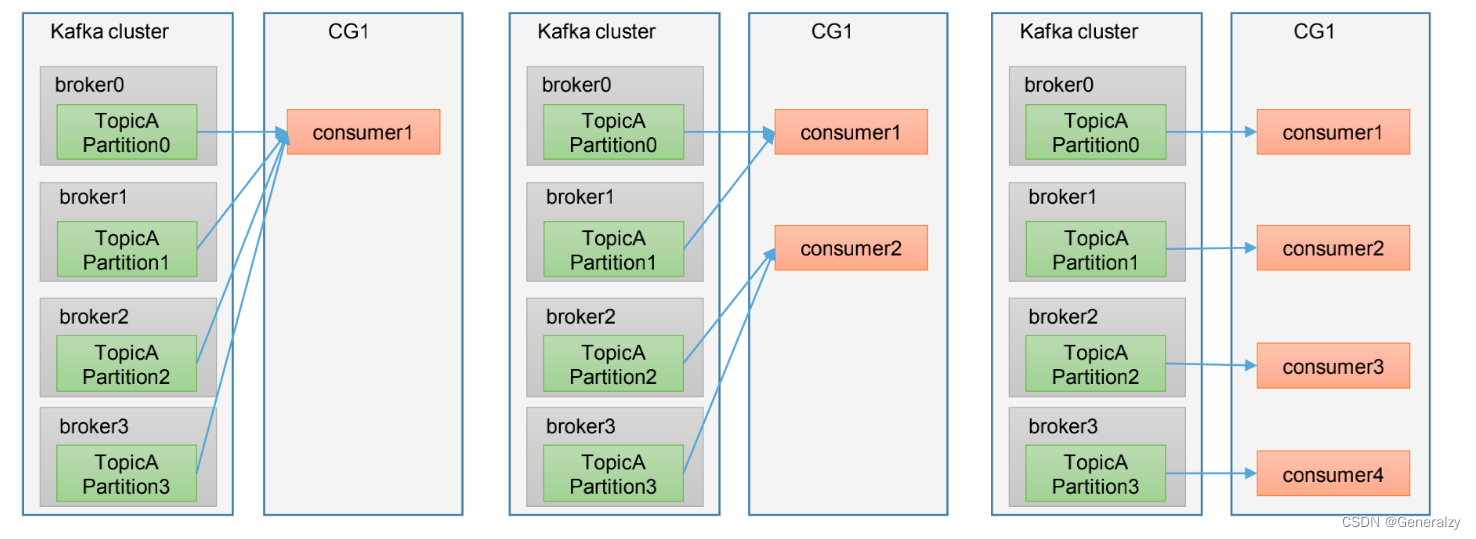
Consumer Group (CG):消费者组,由多个consumer组成。形成一个消费者组的条件是所有消费者的 groupid 相同。
- 消费者组内每个消费者负责消费不同分区的数据,一个分区只能由一个组内消费者消费。
- 消费者组之间互不影响。所有的消费者都属于某个消费者组,即消费者组是逻辑上的一个订阅者。
消费者重要参数
| 参数名称 | 描述 |
|---|---|
| bootstrap.servers | 向 Kafka 集群建立初始连接用到的 host/port 列表。 |
| key.deserializer 和value.deserializer | 指定接收消息的 key 和 value 的反序列化类型。一定要写全类名。 |
| group.id | 标记消费者所属的消费者组。 |
| enable.auto.commit | 默认值为 true,消费者会自动周期性地向服务器提交偏移量。 |
| auto.commit.interval.ms | 如果设置了 enable.auto.commit 的值为 true, 则该值定义了 消费者偏移量向 Kafka 提交的频率,默认 5s。 |
| auto.offset.reset | 当 Kafka 中没有初始偏移量或当前偏移量在服务器中不存在 (如,数据被删除了),该如何处理? earliest:自动重置偏 移量到最早的偏移量。 latest:默认,自动重置偏移量为最 新的偏移量。 none:如果消费组原来的(previous)偏移量 不存在,则向消费者抛异常。 anything:向消费者抛异常。 |
| offsets.topic.num.partitions | __consumer_offsets 的分区数,默认是 50 个分区。 |
| heartbeat.interval.ms | Kafka 消费者和 coordinator 之间的心跳时间,默认 3s。 该条目的值必须小于 session.timeout.ms ,也不应该高于 session.timeout.ms 的 1/3。 |
| session.timeout.ms | Kafka 消费者和 coordinator 之间连接超时时间,默认 45s。 超过该值,该消费者被移除,消费者组执行再平衡。 |
| max.poll.interval.ms | 消费者处理消息的最大时长,默认是 5 分钟。超过该值,该 消费者被移除,消费者组执行再平衡。 |
| fetch.min.bytes | 默认 1 个字节。消费者获取服务器端一批消息最小的字节数。 |
| fetch.max.wait.ms | 默认 500ms。如果没有从服务器端获取到一批数据的最小字 节数。该时间到,仍然会返回数据。 |
| fetch.max.bytes | 默认 Default: 52428800(50 m)。消费者获取服务器端一批 消息最大的字节数。如果服务器端一批次的数据大于该值 (50m)仍然可以拉取回来这批数据,因此,这不是一个绝 对最大值。一批次的大小受 message.max.bytes (broker config)or max.message.bytes (topic config)影响。 |
| max.poll.records | 一次 poll 拉取数据返回消息的最大条数,默认是 500 条。 |
offset 位移
offset 的默认维护位置
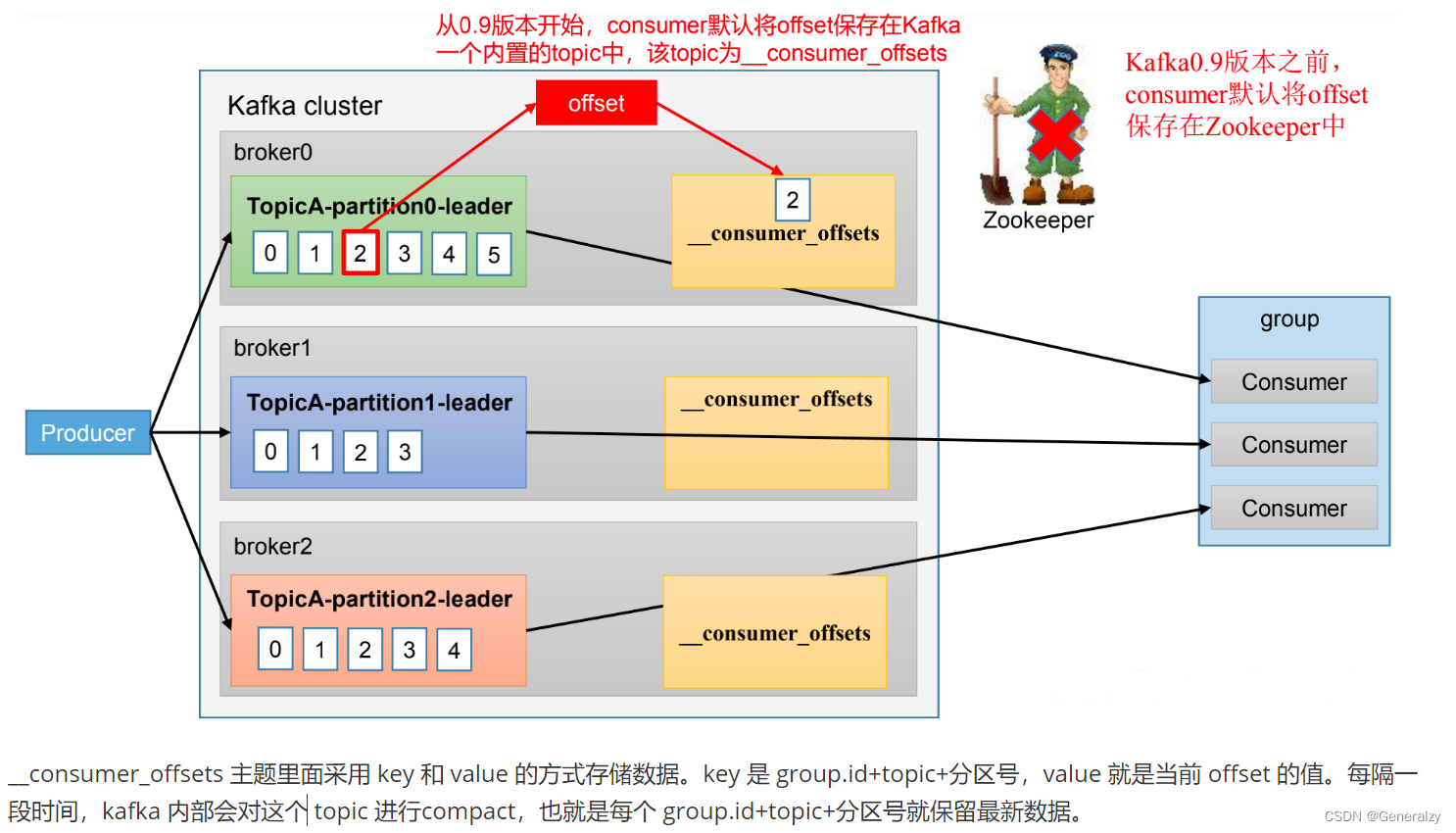
自动提交offset
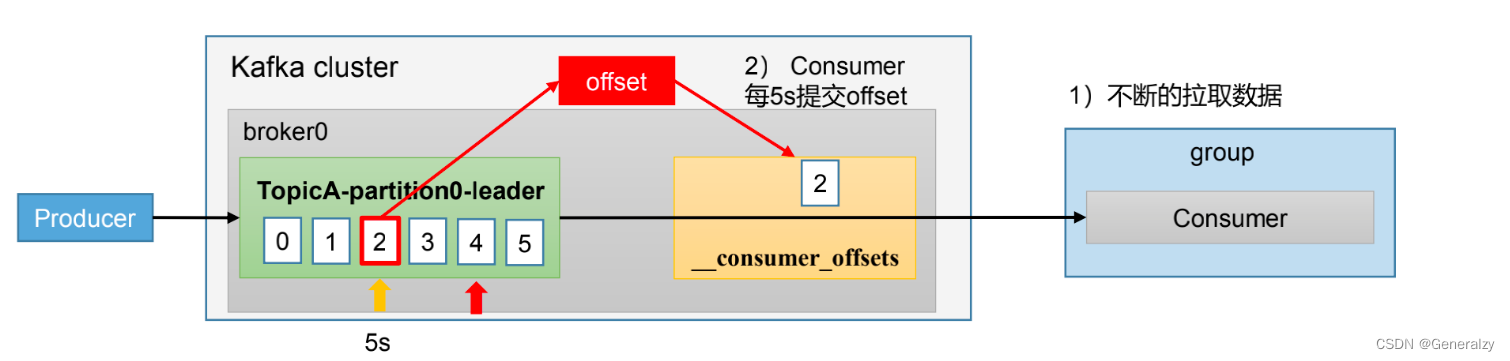
为了使我们能够专注于自己的业务逻辑,Kafka提供了自动提交offset的功能。
自动提交offset的相关参数:
-
enable.auto.commit:是否开启自动提交offset功能,默认是true
-
auto.commit.interval.ms:自动提交offset的时间间隔,默认是5s
| 参数名称 | 描述 |
|---|---|
| enable.auto.commit | 默认值为 true,消费者会自动周期性地向服务器提交偏移量。 |
| auto.commit.interval.ms | 如果设置了 enable.auto.commit 的值为 true, 则该值定义了消费者偏移量向 Kafka 提交的频率,默认 5s。 |
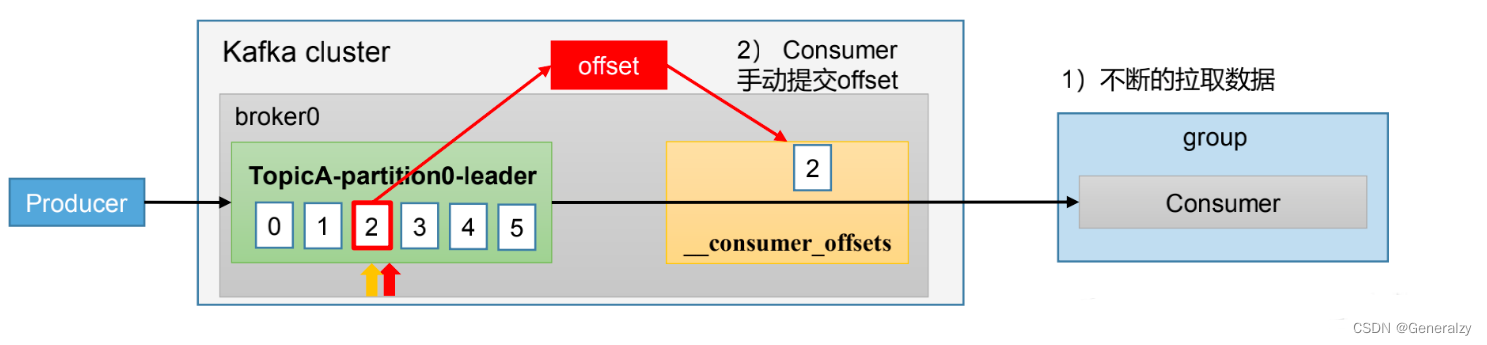
手动提交offset
虽然自动提交offset十分简单比那里,但由于其是基于时间提交的,开发人员难以把握 offset 提交的时机。一次 Kafka 还提供了手动提交 offset 的API。
手动提交 offset 的方法有两种:分别是 commitSync(同步提交)和commitAsync(异步提交)。两者的相同点是,都会将本次提交的一批数据最高的偏移量提交;不同点是,同步提交阻塞当前线程,一直到提交成功,并且会自动失败重试(由不可控因素导致,也会出现提交失败);而异步提交则没有失败重试机制,故有可能提交失败。
- commitSync(同步提交):必须等待offset提交完毕,再去消费下一批数据。
- commitAsync(异步提交) :发送完提交offset请求后,就开始消费下一批数据了。
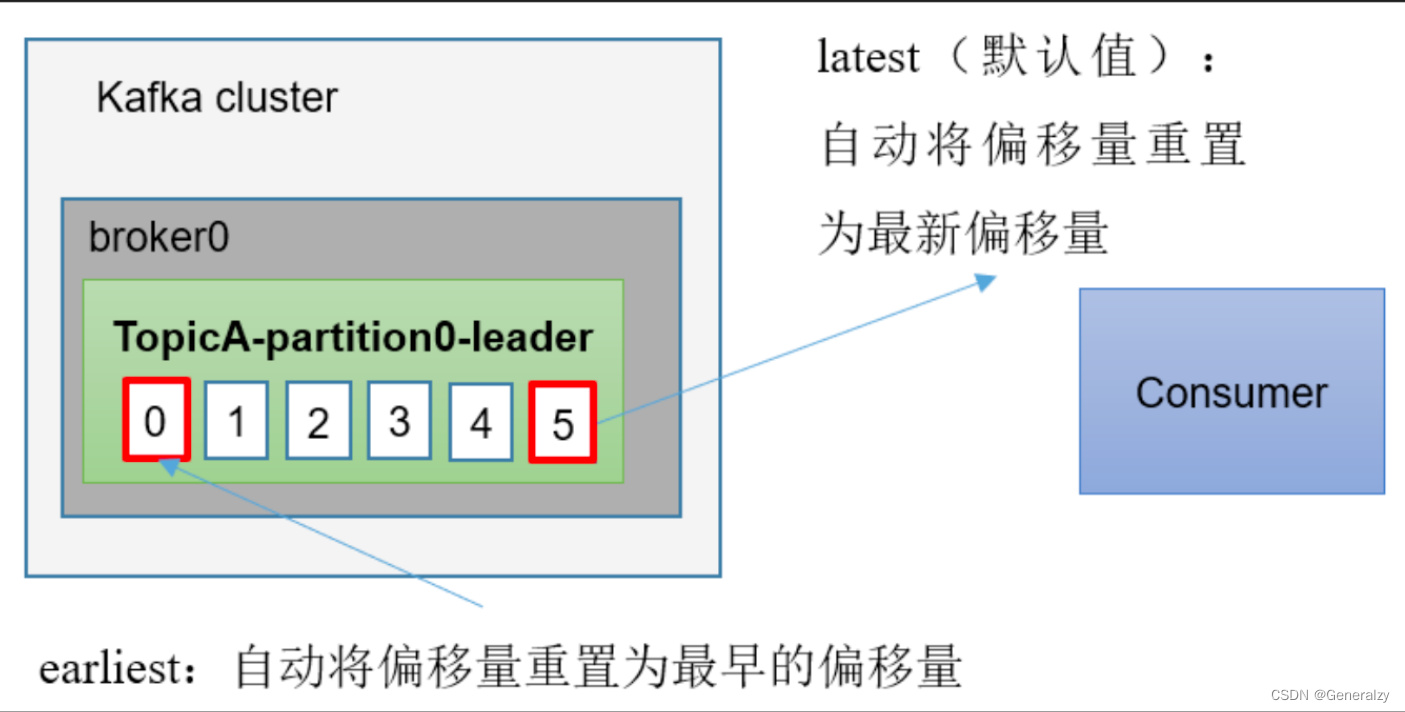
指定Offset消费
auto.offset.reset = earliest | latest | none 默认是 latest。
当 Kafka 中没有初始偏移量(消费者组第一次消费)或服务器上不再存在当前偏移量
时(例如该数据已被删除),该怎么办?
(1)earliest:自动将偏移量重置为最早的偏移量,–from-beginning。
(2)latest(默认值):自动将偏移量重置为最新偏移量。
(3)none:如果未找到消费者组的先前偏移量,则向消费者抛出异常。
Kafka-Kraft模式
Kafka-Kraft架构
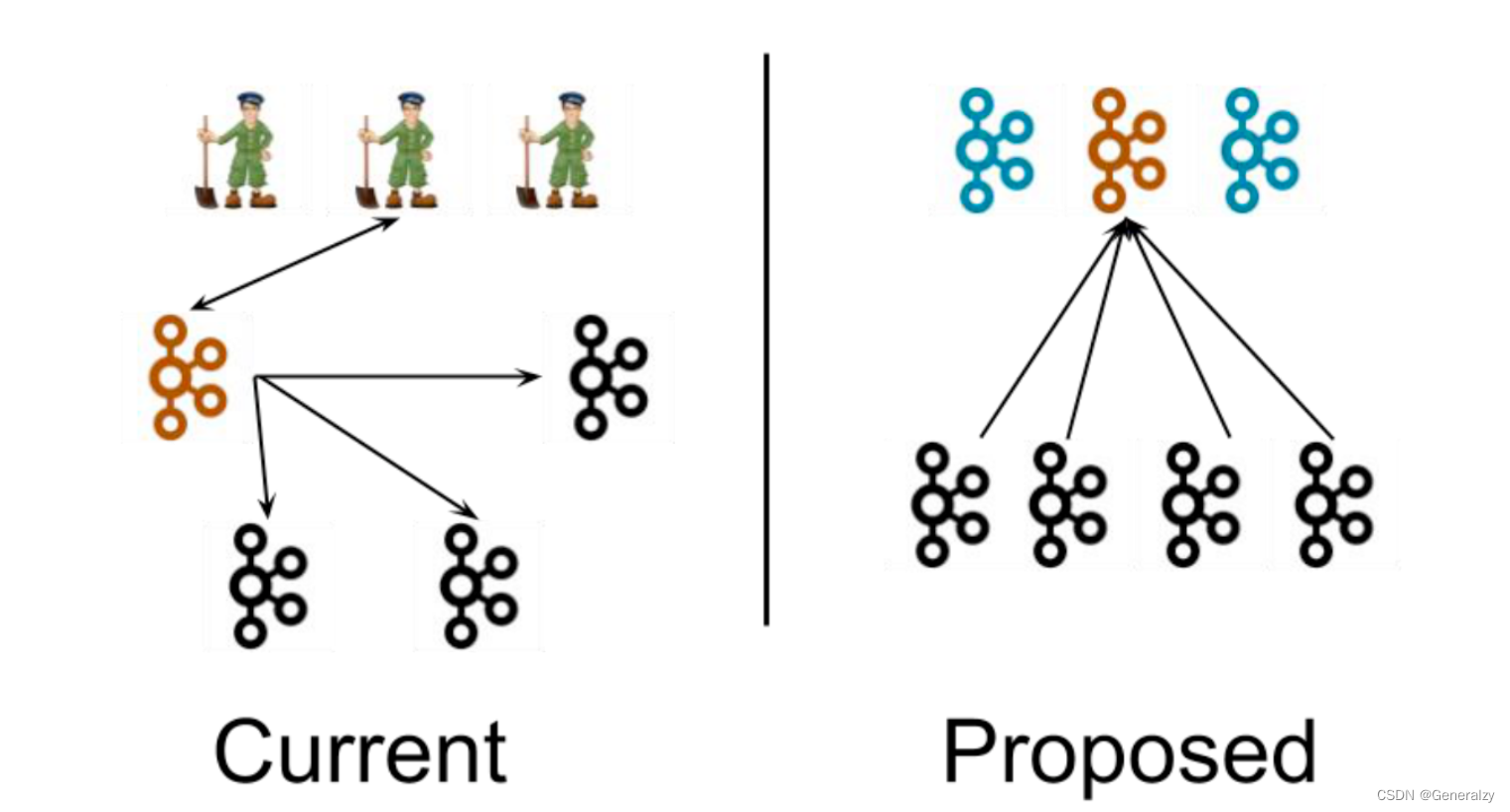
左图为 Kafka 现有架构,元数据在 zookeeper 中,运行时动态选举 controller,由controller 进行 Kafka 集群管理。右图为 kraft 模式架构(实验性),不再依赖 zookeeper 集群,而是用三台 controller 节点代替 zookeeper,元数据保存在 controller 中,由 controller 直接进行 Kafka 集群管理。
这样做的好处有以下几个:
-
Kafka 不再依赖外部框架,而是能够独立运行;
-
controller 管理集群时,不再需要从 zookeeper 中先读取数据,集群性能上升;
-
由于不依赖 zookeeper,集群扩展时不再受到 zookeeper 读写能力限制;
-
controller 不再动态选举,而是由配置文件规定。这样我们可以有针对性的加强controller 节点的配置,而不是像以前一样对随机 controller 节点的高负载束手无策。