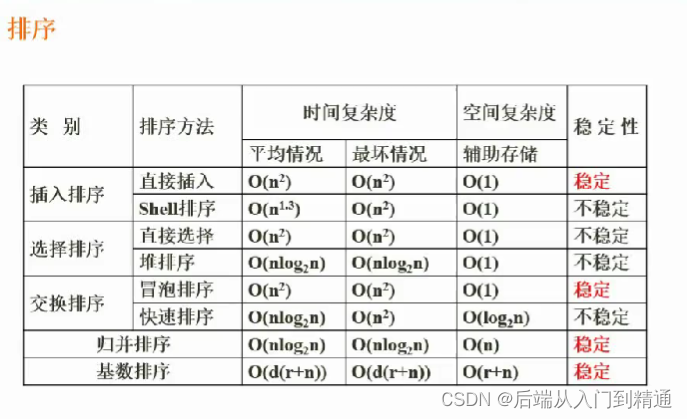
阶段十:总结专题(第五章:数据库篇 )
- Day-第五章:数据库篇
- ==1. 隔离级别==
- 1.1、**未提交读**(不使用)
- 1.2、**提交读(RC)**(经常使用)
- 1.3、**可重复读(RR)**(经常使用)
- 1.4、**串行读** (用得少,性能受损)
- ==2. 快照读与当前读==
- 3. MySQL 存储引擎
- ==4. 索引==
- ==索引基础==
- **==BTree vs B+Tree==**
- **B+Tree 新增 key**
- **B+Tree 查询 key**
- **B+Tree 删除叶子节点 key**
- **B+Tree 删除非叶子节点 key**
- ==命中索引==
- **索引用于排序**
- **索引用于 where 筛选**
- **索引条件下推**
- **二级索引覆盖**
- ==5. 查询语句执行流程==
- ==6. undo log 与 redo log==
- **undo log**
- **redo log**
- ==7. 锁==
- **全局锁**
- <font color = #FF0000>表级锁(InnoDB)
- 行级锁(InnoDB)
))
Day-第五章:数据库篇
1. 隔离级别
要求
- 掌握四种隔离级别与相关的错误现象
1.1、未提交读(不使用)
- 读到其它事务未提交的数据(最新的版本)
- 错误现象:有脏读、不可重复读、幻读现象
脏读现象
| tx1 | tx2 |
|---|---|
| set session transaction isolation level read uncommitted; (#将隔离级别设置成read uncommitted未提交读) | |
| start transaction; (#tx1开始事务) | |
| select * from account; /两个账户都为 1000/ | |
| start transaction; (#tx2开启事务) | |
| update account set balance = 2000 where accountNo=1;(#将账户1改为2000,但未提交) | |
| select * from account; /1号账户2000, 2号账户1000/ |
- tx2 未提交的情况下,tx1 仍然读取到了它的更改
1.2、提交读(RC)(经常使用)
- 读到其它事务已提交的数据(最新已提交的版本)
- 错误现象:有不可重复读、幻读现象
- 使用场景:希望看到最新的有效值
不可重复读现象
| tx1 | tx2 |
|---|---|
| set session transaction isolation level read committed; (#将隔离级别设置成read committed提交读) | |
| start transaction; | |
| select * from account; /两个账户都为 1000/ | |
| update account set balance = 2000 where accountNo=1;(更改值,提交) | |
| select * from account; /1号账户2000, 2号账户1000/ |
- tx1 在同一事务内,两次读取的结果不一致,当然,此时 tx2 的事务已提交
1.3、可重复读(RR)(经常使用)
-
在事务范围内,多次读能够保证一致性(快照建立时最新已提交版本)
-
错误现象:有幻读现象,可以用加锁避免
-
使用场景:事务内要求更强的一致性,但看到的未必是最新的有效值
幻读现象
| tx1 | tx2 |
|---|---|
| set session transaction isolation level repeatable read; | |
| start transaction; | |
| select * from account; /存在 1,2 两个账户/ | |
| insert into account values(3, 1000); | |
| select * from account; /发现还是只有 1,2 两个账户/ | |
| insert into account values(3, 5000); /* ERROR 1062 (23000): Duplicate entry ‘3’ for key ‘PRIMARY’ */ |
- tx1 查询时并没有发现 3 号账户,执行插入时却发现主键冲突异常,就好像出现了幻觉一样
加锁避免幻读 (for update)
| tx1 | tx2 |
|---|---|
| set session transaction isolation level repeatable read; | |
| start transaction; | |
| select * from account; /存在 1,2 两个账户/ | |
| select * from account where accountNo=3 for update; | |
| insert into account values(3, 1000); /* 阻塞 */ | |
| insert into account values(3, 5000); |
- 在 for update 这行语句执行时,虽然此时 3 号账户尚不存在,但 MySQL 在 repeatable read 隔离级别下会用间隙锁,锁住 2 号记录与正无穷大之间的间隙
- 此时 tx2 想插入 3 号记录就不行了,被间隙锁挡住了
也可以提升隔离级别(串行读)避免幻读 (for update)
1.4、串行读 (用得少,性能受损)
-
在事务范围内,仅有读读可以并发,读写或写写会阻塞其它事务,用这种办法保证更强的一致性
-
错误现象:无
串行读避免幻读
| tx1 | tx2 |
|---|---|
| set session transaction isolation level serializable; | |
| start transaction; | |
| select * from account; /* 存在 1,2 两个账户,此时已经加了读锁 */ | |
| insert into account values(3, 1000); /* 阻塞 */ | |
| insert into account values(3, 5000); |
- 串行读隔离级别下,普通的 select 也会加共享读锁,其它事务的查询可以并发,但增删改就只能阻塞了
2. 快照读与当前读
要求
- 理解快照读与当前读
- 了解快照产生的时机
当前读
即读取最新提交的数据,查询时需要加锁
- select … for update
- select … lock in share mode
- insert、update、delete,都会按最新提交的数据进行操作
当前读本质上是基于锁的并发读操作
快照读
读取某一个快照建立时(可以理解为某一时间点)的数据,也称为一致性读,无需加锁,读取的是历史数据(原理是回滚段)。快照读主要体现在 select 时,而不同隔离级别下,select 的行为不同
-
在 Serializable(串行读) 隔离级别下 - 普通 select 也变成当前读,即加共享读锁
-
在 RC 隔离级别下(建立快照的时机) - 每次 select 都会建立新的快照
-
在 RR 隔离级别下(建立快照的时机)
- 事务启动后,首次 select 会建立快照
- 如果事务启动选择了 with consistent snapshot,事务启动时就建立快照
- 基于旧数据的修改操作,会重新建立快照
快照读本质上读取的是历史数据(原理是回滚段),属于无锁查询
RR 下,快照建立时机 - 第一次 select 时
| tx1 | tx2 |
|---|---|
| set session transaction isolation level repeatable read; | |
| start transaction; (开始事务) | |
| select * from account; /* 此时建立快照,两个账户为 1000 */ | |
| update account set balance = 2000 where accountNo=1; | |
| select * from account; /* 两个账户仍为 1000 */ |
- 快照一旦建立,以后的查询都基于此快照,因此 tx1 中第二次 select 仍然得到 1 号账户余额为 1000
如果 tx2 的 update 先执行
| tx1 | tx2 |
|---|---|
| set session transaction isolation level repeatable read; | |
| start transaction; (开始事务) | |
| update account set balance = 2000 where accountNo=1; | |
| select * from account; /* 此时建立快照,1号余额已经为2000 */ |
RR 下,快照建立时机 - 事务启动时
如果希望事务启动时就建立快照,可以添加 with consistent snapshot 选项
| tx1 | tx2 |
|---|---|
| set session transaction isolation level repeatable read; | |
start transaction with consistent snapshot; /* 此时建立快照,两个账户为 1000 */ | |
| update account set balance = 2000 where accountNo=1; | |
| select * from account; /* 两个账户仍为 1000 */ |
RR 下,快照建立时机 - 修改数据时
| tx1 | tx2 |
|---|---|
| set session transaction isolation level repeatable read; | |
| start transaction; | |
| select * from account; /* 此时建立快照,两个账户为 1000 */ | |
| update account set balance=balance+1000 where accountNo=1; | |
| update account set balance=balance+1000 where accountNo=1; (重新建立快照) | |
| select * from account; /* 1号余额为3000 */ |
- tx1 内的修改必须重新建立快照,否则,就会发生丢失更新的问题
3. MySQL 存储引擎
InnoDB(现在MySQL默认的存储引擎) vs MyISAM(早期的MySQL默认的存储引擎)
要求
- 掌握 InnoDB 与 MyISAM 的主要区别
- 尤其注意它们在索引结构上的区别
InnoDB
-
索引分为聚簇索引与二级索引
- 聚簇索引:主键值作为索引数据,叶子节点还包含了所有字段数据,索引和数据是存储在一起的
- 二级索引:除主键外的其它字段建立的索引称为二级索引。被索引的字段值作为索引数据,叶子节点还包含了主键值
-
支持事务(ACID)
- 通过 undo log 支持事务回滚、当前读(多版本查询)
- 通过 redo log 实现持久性
- 通过两阶段提交实现一致性
- 通过当前读、锁实现隔离性
-
支持行锁、间隙锁
-
支持外键
MyISAM
-
索引只有一种
- 被索引字段值作为索引数据,叶子节点还包含了该记录数据页地址,数据和索引是分开存储的
-
不支持事务,没有 undo log 和 redo log
-
仅支持表锁
-
不支持外键
-
会保存表的总行数
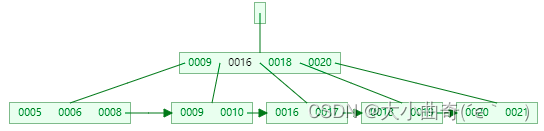
InnoDB 索引特点
聚簇索引:主键值作为索引数据,叶子节点还包含了所有字段数据,索引和数据是存储在一起的
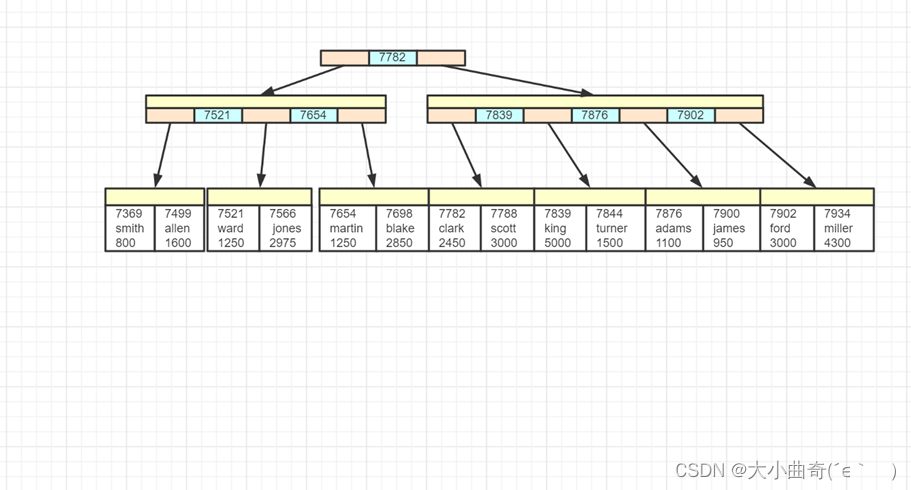
- 主键即 7369、7499、7521 等
二级索引:除主键外的其它字段建立的索引称为二级索引(比如以工资作为索引)。被索引的字段值作为索引数据,叶子节点(主键值+要查看的值)还包含了主键值
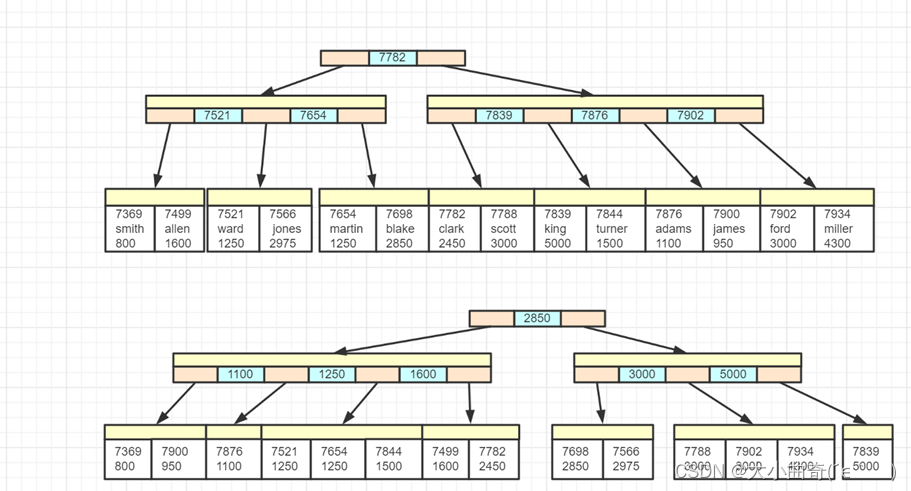
- 上图中 800、950、1100 这些是工资字段的值,根据它们建立了二级索引
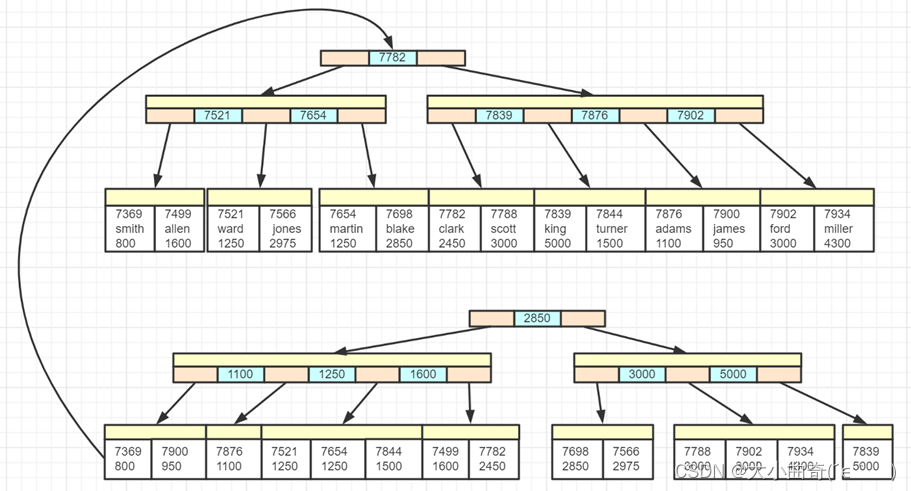
- 上图中,如果执行查询
select empno, ename, sal from emp where sal = 800,这时候可以利用二级索引定位到 800 这个工资,同时还能知道主键值 7369 - 但 select 字句中还出现了 ename 字段,在二级索引中不存在,因此需要根据主键值 7369 查询聚簇索引来获取 ename 的信息,这个过程俗称**回表**
MyISAM 索引特点
被索引字段值作为索引数据,叶子节点还包含了该记录数据页地址,数据和索引是分开存储的
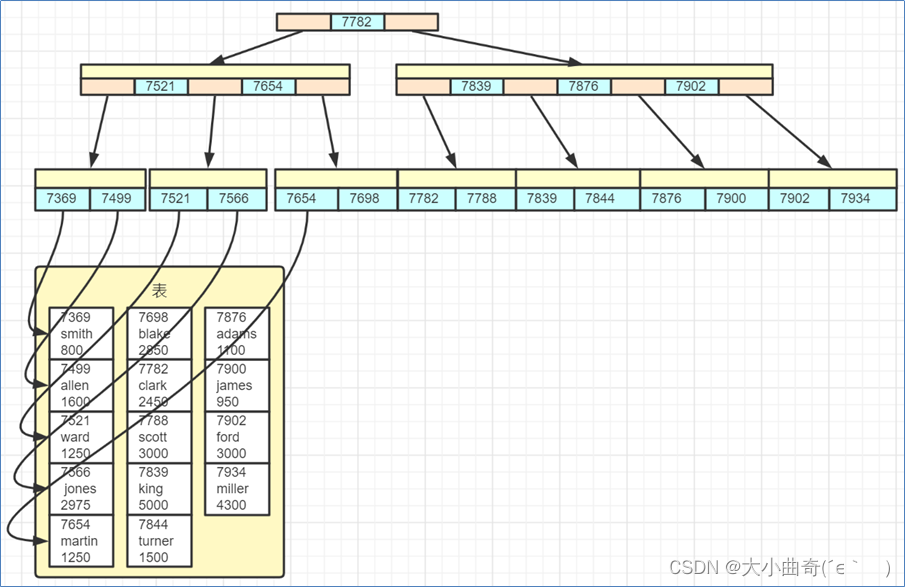
4. 索引
面试题:为什么 MySQL 主要采用 B+ 树作为索引实现?
更适合磁盘数据的索引,可以等值查询、范围查询(适合广泛的查询条件)等;
要求
- 了解常见索引与它们的适用场景,尤其是 B+Tree 索引的特点
- 掌握索引用于排序,以及失效情况
- 掌握索引用于筛选,以及失效情况
- 理解索引条件下推
- 理解二级索引覆盖
索引基础
常见索引
-
哈希索引
- 理想时间复杂度为 O ( 1 ) O(1) O(1)
- 适用场景:适用于等值查询的场景,内存数据的索引(不适合范围索引,磁盘索引)
- 典型实现:Redis,MySQL 的 memory 引擎
-
平衡二叉树索引
- 查询和更新的时间复杂度都是 O ( l o g 2 ( n ) ) O(log_2(n)) O(log2(n))
- 适用场景:适用于等值查询以及范围查询;适合内存数据的索引,但不适合磁盘数据的索引,可以认为 树的高度决定了磁盘 I/O 的次数,百万数据树高约为 20
-
BTree 索引
- BTree 其实就是 n 叉树,分叉多意味着节点中的孩子(key)多,树高自然就降低了(树越低,磁盘I/O越小)
- 分叉数由页大小和行(包括 key 与 value)大小决定
- 假设页大小为 16k,每行 40 个字节,那么分叉数就为 16k / 40 ≈ 410
- 而分叉为 410,则百万数据树高约为3,仅 3 次 I/O 就能找到所需数据
- 局部性原理:每次 I/O 按页为单位读取数据,把多个 key 相邻的行放在同一页中(每页就是树上一个节点),能进一步减少 I/O
-
B+ 树索引 (BTree 索引的改进)
- 在 BTree 的基础上做了改进,索引上只存储 key,这样能进一步增加分叉数,假设 key 占 13 个字节,那么一页数据分叉数可以到 1260,树高可以进一步下降为 2
- 更适合磁盘数据的索引,可以等值查询、范围查询(适合广泛的查询条件)等;
树高计算公式
- l o g 10 ( N ) / l o g 10 ( M ) log_{10}(N) / log_{10}(M) log10(N)/log10(M) 其中 N 为数据行数,M 为分叉数
BTree vs B+Tree
- 无论 BTree 还是 B+Tree,每个叶子节点到根节点距离都相同
- BTree key 及 value 在每个节点上,无论叶子还是非叶子节点

- B+Tree 普通节点只存 key,叶子节点才存储 key 和 value,因此分叉数可以更多
- 不过也请注意,普通节点上的 key 有的会与叶子节点的 key 重复
- B+Tree 必须到达叶子节点才能找到 value
- B+Tree 叶子节点用链表连接,可以方便范围查询及全表遍历

注:这两张图都是仅画了 key,未画 value
B+Tree 新增 key
假设阶数(m)为5(阶数代表每个节点中key的最大数)
- 若为空树,那么直接创建一个节点,插入 key 即可,此时这个叶子结点也是根结点。例如,插入 5
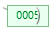
-
插入时,若当前结点 key 的个数小于阶数,则插入结束
-
依次插入 8、10、15,按 key 大小升序

- 插入 16,这时到达了阶数限制,所以要进行分裂

- 叶子节点分裂规则:将这个叶子结点分裂成左右两个叶子结点,左叶子结点包含前 m/2 个(2个)记录,右结点包含剩下的记录,将中间的 key 进位到父结点中。注意:中间的 key 仍会保留在叶子节点一份
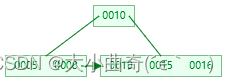
-
插入 17
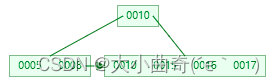
-
插入 18,这时当前结点的 key 个数到达 5,进行分裂
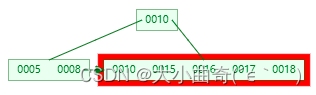
-
分裂成两个结点,左结点 2 个记录,右结点 3 个记录,key 16 进位到父结点中
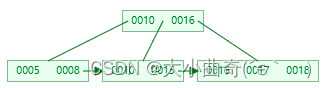
-
插入 19、20、21、22、6、9

-
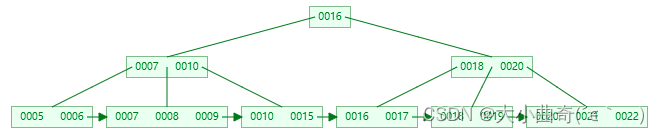
插入 7,当前结点的 key 个数到达 5,需要分裂

-
分裂后 key 7 进入到父结点中,这时父节点 key 个数也到达 5

- 非叶子节点分裂规则:左子结点包含前 (m-1)/2 个 key,将中间的 key 进位到父结点中(不保留),右子节点包含剩余的 key
B+Tree 查询 key
以查询 15 为例
- 第一次 I/O
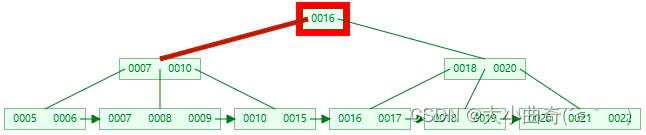
-
第二次 I/O
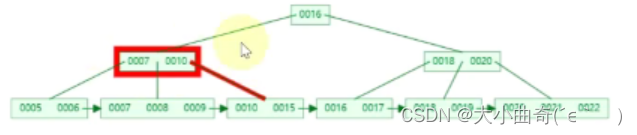
-
第三次 I/O
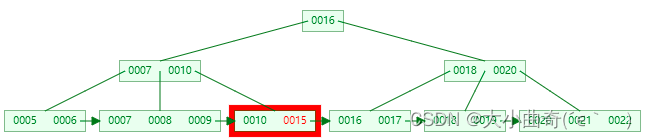
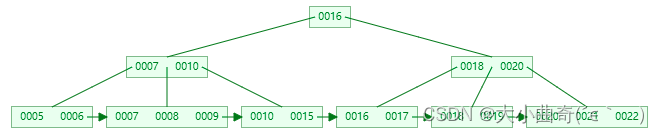
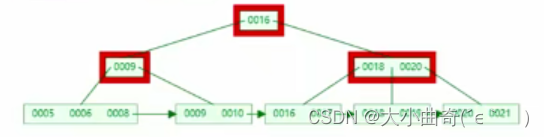
B+Tree 删除叶子节点 key
-
初始状态
-
删完有富余。即删除后结点的key的个数 > m/2 – 1,删除操作结束,例如删除 22
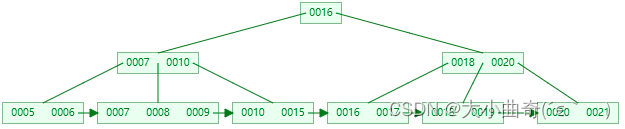
-
删完没富余,但兄弟节点有富余。即兄弟结点 key 有富余( > m/2 – 1 ),向兄弟结点借一个记录,同时替换父节点,例如删除 15
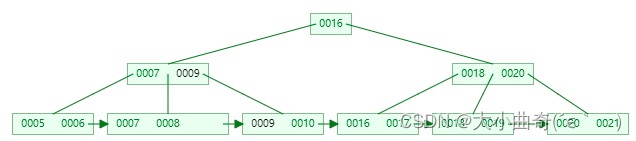
-
兄弟节点也不富余,合并兄弟叶子节点。即兄弟节点合并成一个新的叶子结点,并删除父结点中的key,将当前结点指向父结点,例如删除 7
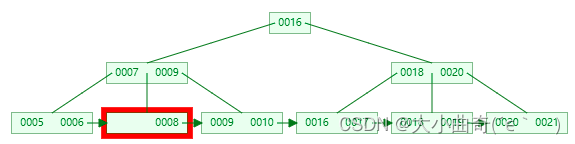
-
也需要删除非叶子节点中的 7,并替换父节点保证区间仍有效
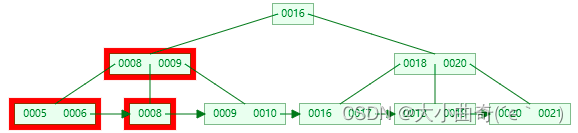
-
左右兄弟都不够借,合并
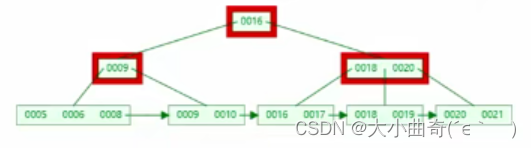
B+Tree 删除非叶子节点 key
接着上面的操作
-
非叶子节点 key 的个数 > m/2 – 1,则删除操作结束,否则执行 2
-
若兄弟结点有富余,父结点 key 下移,兄弟结点 key 上移,删除结束,否则执行 3
-
若兄弟节点没富余,当前结点和兄弟结点及父结点合并成一个新的结点。重复 1
命中索引
面试题:命中索引要注意什么?(索引什么时候失效)
准备数据
修改 MySQL 配置文件
my.ini,在[mysqld]下添加secure_file_priv=重启 MySQL 服务器,让选项生效【目的是不用考虑权限的限制,可以从任意目录下导入数据文件】执行 db.sql 内的脚本,建表
执行
LOAD DATA INFILE 'D:\\big_person.txt' INTO TABLE big_person;【LOAD DATA INFILE ‘文本文件路径’ INTO TABLE big_person;】 注意实际路径根据情况修改
- 测试表 big_person(此表数据量较大,如果与其它表数据一起提供不好管理,故单独提供),数据行数 100 万条,列个数 15 列。为了更快速导入数据,这里采用了 load data infile 命令配合 *.txt 格式数据
索引用于排序
/* 测试单列索引并不能在多列排序时加速 */
create index first_idx on big_person(first_name);#为first_name创建索引first_idx
create index last_idx on big_person(last_name);#为last_name创建索引last_idx
explain select * from big_person order by last_name, first_name limit 10;
上面创建了索引,可是查询时仍然很慢,因为多列排序需要用组合索引;
上面的explain+SQL语句的作用是:不用执行实际查询,只展示如何优化SQL语句的;
/* 多列排序需要用组合索引 */
alter table big_person drop index first_idx; #删除索引first_idx
alter table big_person drop index last_idx; #删除索引last_idx
create index last_first_idx on big_person(last_name,first_name); #创建组合索引
/* 多列排序需要遵循最左前缀原则, 第1个查询可以利用索引,第2,3查询不能利用索引 */
explain select * from big_person order by last_name, first_name limit 10;
explain select * from big_person order by first_name, last_name limit 10;
explain select * from big_person order by first_name limit 10;
/* 多列排序升降序需要一致(都升序/都降序),查询1可以利用索引,查询2不能利用索引*/
explain select * from big_person order by last_name desc, first_name desc limit 10;
explain select * from big_person order by last_name desc, first_name asc limit 10;
最左前缀原则
若建立组合索引 (a,b,c),则可以利用到索引的排序条件是:
- order by a
- order by a, b
- order by a, b, c
索引用于 where 筛选
- 参考 https://dev.mysql.com/doc/refman/8.0/en/multiple-column-indexes.html
组合索引要满足最左侧原则,模糊查询也要满足字符串的最左前缀;
/* 模糊查询需要遵循字符串最左前缀原则,查询2可以利用索引,查询1,3不能利用索引 */
explain SELECT * FROM big_person WHERE first_name LIKE 'dav%' LIMIT 5;
explain SELECT * FROM big_person WHERE last_name LIKE 'dav%' LIMIT 5;
explain SELECT * FROM big_person WHERE last_name LIKE '%dav' LIMIT 5;
/* 组合索引需要遵循最左前缀原则,查询1,2可以利用索引,查询3,4不能利用索引 */
create index province_city_county_idx on big_person(province,city,county);
explain SELECT * FROM big_person WHERE province = '上海' AND city='宜兰县' AND county='中西区';
explain SELECT * FROM big_person WHERE county='中西区' AND city='宜兰县' AND province = '上海';
explain SELECT * FROM big_person WHERE city='宜兰县' AND county='中西区';
explain SELECT * FROM big_person WHERE county='中西区';
/* 函数及计算问题,一旦在字段上应用了计算或函数,都会造成索引失效。查询2可以利用索引,查询1不能利用索引 */
create index birthday_idx on big_person(birthday);
explain SELECT * FROM big_person WHERE ADDDATE(birthday,1)='2005-02-10'; #函数用在列上(字段上)
explain SELECT * FROM big_person WHERE birthday=ADDDATE('2005-02-10',-1);#函数用在值上
/* 隐式类型转换问题(desc 表名;#查看数据表各字段类型,得知phone是字符串)
* 查询1会发生隐式类型转换等价于在phone上应用了函数,造成索引失效
* 查询2字段与值类型相同不会类型转换,可以利用索引
*/
create index phone_idx on big_person(phone);
explain SELECT * FROM big_person WHERE phone = 13000013934;
explain SELECT * FROM big_person WHERE phone = '13000013934';
最左前缀原则(leftmost prefix)
若建立组合索引 (a,b,c),则可以利用到索引的查询条件是:
- where a = ?
- where a = ? and b = ? (注意与条件的先后次序无关,也可以是 where b = ? and a = ?,只要出现即可)
- where a = ? and b = ? and c = ? (注意事项同上)
不能利用的例子:
- where b = ?
- where b = ? and c = ?
- where c = ?
特殊情况:
- where a = ? and c = ?(a = ? 会利用索引,但 c = ? 不能利用索引加速,会触发索引条件下推)
索引条件下推
- 参考 https://dev.mysql.com/doc/refman/8.0/en/index-condition-pushdown-optimization.html
并非组合索引会用到所有的索引,可能用到0个、1个、2个、3个;
/* 查询 1,2,3,4 都能利用索引,但 4 相当于部分利用了索引,会触发索引条件下推 */
explain SELECT * FROM big_person WHERE province = '上海';
explain SELECT * FROM big_person WHERE province = '上海' AND city='嘉兴市';
explain SELECT * FROM big_person WHERE province = '上海' AND city='嘉兴市' AND county='中西区';
explain SELECT * FROM big_person WHERE province = '上海' AND county='中西区';
比如省、市、县都有索引,查询时“省、市、县”用到了三个索引;“省、市”用到了两个索引;“省、县、市”用了一个索引;“市、省、县”一个索引也用不到
索引条件下推
- MySQL 执行条件判断的时机有两处:
- 服务层(上层,不包括索引实现)
- 引擎层(下层,包括了索引实现,可以利用)
- 上面查询 4 中有 province 条件能够利用索引,在引擎层执行,但 county 条件仍然要交给服务层处理
- 在 5.6 之前,服务层需要判断所有记录的 county 条件,性能非常低
- 5.6 以后,引擎层会先根据 province 条件过滤,满足条件的记录才在服务层处理 county 条件
我们现在用的是 5.6 以上版本,所以没有体会,可以用下面的语句关闭索引下推优化,再测试一下性能
SET optimizer_switch = 'index_condition_pushdown=off';
SELECT * FROM big_person WHERE province = '上海' AND county='中西区';
二级索引覆盖
explain SELECT * FROM big_person WHERE province = '上海' AND city='宜兰县' AND county= '中西区';
explain SELECT id,province,city,county FROM big_person WHERE province = '上海' AND city='宜兰县' AND county='中西区';
根据查询条件查询 1,2 都会先走二级索引,但是二级索引仅包含了 (province, city, county) 和 id 信息
- 查询 1 是 select *,因此还有一些字段二级索引中没有,需要回表(查询聚簇索引)来获取其它字段信息
- 查询 2 的 select 中明确指出了需要哪些字段,这些字段在二级索引都有,就避免了回表查询【二级索引覆盖】
其它注意事项
- 表连接需要在连接字段上建立索引
- 不要迷信网上说法,具体情况具体分析
例如:
create index first_idx on big_person(first_name); #创建索引
/* 不会利用索引,因为优化器发现查询记录数太多,还不如直接全表扫描 */
explain SELECT * FROM big_person WHERE first_name > 'Jenni';
/* 会利用索引,因为优化器发现查询记录数不太多 */
explain SELECT * FROM big_person WHERE first_name > 'Willia';
/* 同一字段的不同值利用 or 连接,会利用索引 */
explain select * from big_person where id = 1 or id = 190839;
/* 不同字段利用 or 连接,会利用索引(底层分别用了两个索引) */
explain select * from big_person where first_name = 'David' or last_name = 'Thomas';
/* in 会利用索引 */
explain select * from big_person where first_name in ('Mark', 'Kevin','David');
/* not in 不会利用索引的情况 */ //没有发生索引覆盖
explain select * from big_person where first_name not in ('Mark', 'Kevin','David');
/* not in 会利用索引的情况 */ //发生了索引覆盖
explain select id from big_person where first_name not in ('Mark', 'Kevin','David');
- 以上实验基于 5.7.27,其它如 !=、is null、is not null 是否使用索引都会跟版本、实际数据相关,以优化器结果为准
- 查看mysql版本:
select @@version;
5. 查询语句执行流程
面试题:执行 SQL 语句 select * from user where id = 1 时发生了什么
要求
- 了解查询语句执行流程
执行 SQL 语句 select * from user where id = 1 时发生了什么
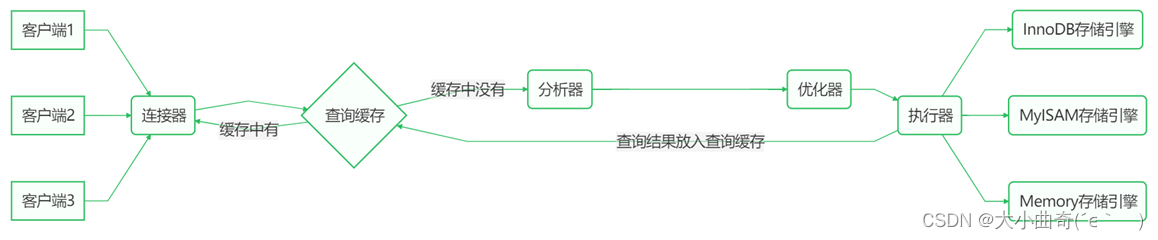
-
连接器:负责建立连接、检查权限、连接超时时间由 wait_timeout 控制,默认 8 小时
-
查询缓存:会将 SQL 和查询结果以键值对方式进行缓存,修改操作会以表单位导致缓存失效
-
分析器:词法、语法分析
-
优化器:决定用哪个索引,决定表的连接顺序等
-
执行器:根据存储引擎类型,调用存储引擎接口
-
存储引擎:数据的读写接口,索引、表都在此层实现
6. undo log 与 redo log
要求
- 理解 undo log 的作用
- 理解 redo log 的作用
undo log
- 回滚数据,以行为单位,记录数据每次的变更,一行记录有多个版本并存
- 多版本并发控制,即快照读(也称为一致性读,查询操作不受锁的影响),让查询操作可以去访问历史版本
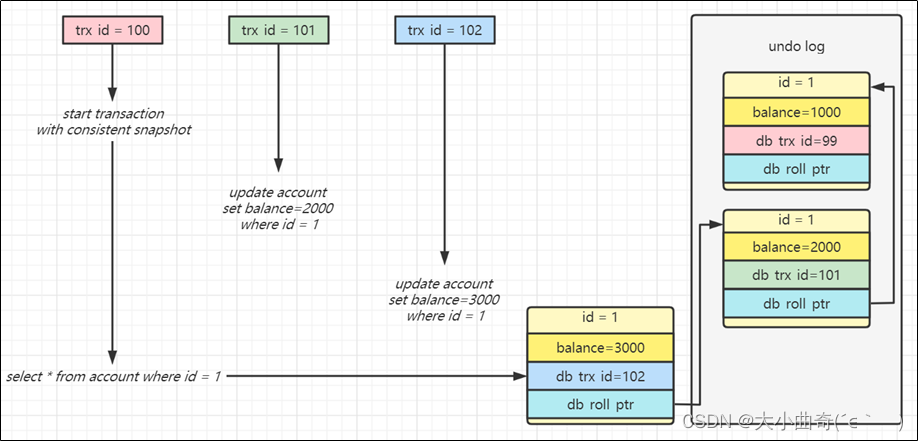
最终
trx id = 100查询到的是trx id = 101、trx id = 102之前的状态
- 每个事务会按照开始时间,分配一个单调递增的事务编号 trx id
- 每次事务的改动都会以行为单位记入回滚日志,包括当时的事务编号,改动的值等
- 查询操作,事务编号大于自己的数据是不可见的,事务编号小于等于自己的数据才是可见的
- 例如图中红色事务看不到 trx id=102 以及 trx id=101 的数据,只有 trx id=99 的数据对它可见
redo log
redo log 的作用主要是实现 ACID 中的持久性,保证提交的数据不丢失
- 它记录了事务提交的变更操作,服务器意外宕机重启时,利用 redo log 进行回放,重新执行已提交的变更操作
- 事务提交时,首先将变更写入 redo log,事务就视为成功。至于数据页(表、索引)上的变更,可以放在后面慢慢做
- 数据页上的变更宕机丢失也没事,因为 redo log 里已经记录了
- 数据页在磁盘上位置随机,写入速度慢,redo log 的写入是顺序的速度快
它由两部分组成,内存中的 redo log buffer,磁盘上的 redo log file
- redo log file 由一组文件组成,当写满了会循环覆盖较旧的日志,这意味着不能无限依赖 redo log,更早的数据恢复需要 binlog
buffer和file两部分组成意味着,写入了文件才真正安全,同步策略由参数innodb_flush_log_at_trx_commit控制- 0 - 每隔 1s 将日志 write and flush 到磁盘
- 1 - 每次事务提交将日志
write and flush(==默认值=) - 2 - 每次事务提交将日志 write,每隔 1s flush 到磁盘,意味着 write 意味着写入操作系统缓存,如果 MySQL 挂了,而操作系统没挂,那么数据不会丢失
write:将数据写入到操作系统的缓存;flush:将操作系统的缓存存到磁盘文件;
7. 锁
面试题:你对 MySQL 的锁了解吗
要求
- 了解全局锁
- 了解表级锁
- 掌握行级锁
全局锁
用作数据的全量备份时,保证表与表之间的数据一致性
如果不加任何包含,数据备份时就可能产生不一致的情况,如下图所示
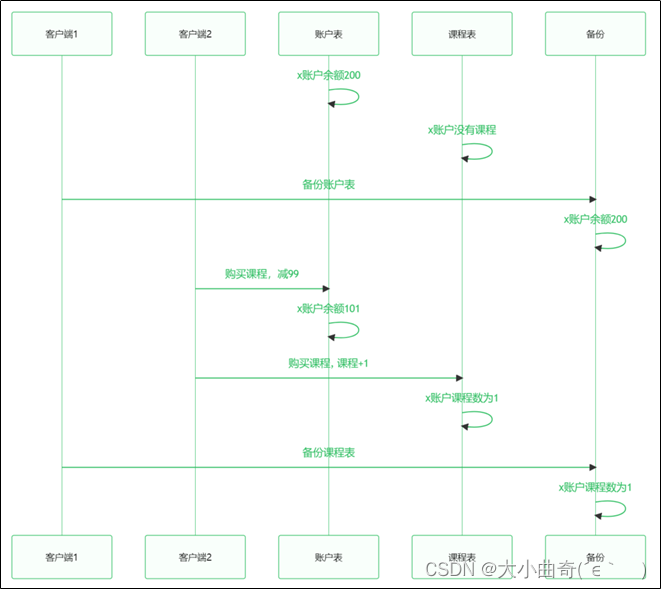
全局锁的语法:
阻塞增删改
flush tables with read lock;
- 使用全局读锁锁定所有数据库的所有表。这时会阻塞其它所有 DML 以及 DDL 操作,这样可以避免备份过程中的数据不一致。接下来可以执行备份,最后用 unlock tables 来解锁
注意
但 flush tables 属于比较重的操作,可以使用 --single-transaction 参数来完成不加锁的一致性备份(仅针对 InnoDB 引擎的表)
备份mysqldump --single-transaction -uroot -p test > 1.sql
表级锁(InnoDB)
**表级锁 - 表锁**(需要显示的执行加锁、解锁操作) * 语法:**加锁** `lock tables 表名 read/write` (==`read`是共享锁,其他客户端能做读操作,`write`是排它锁,其他客户端什么都做不了==),**解锁** `unlock tables` * 缺点:==粒度较粗(并发低),在 InnoDB 引擎很少使用==表级锁 - 元数据锁(隐示的执行加锁、解锁操作)
-
即 metadata-lock(MDL),主要是为 了避免
DML(增删改查) 与DDL(表定义语言:创建表,修改表,删除表) 冲突 ,DML 的元数据锁之间不互斥 -
加元数据锁的几种情况
lock tables read/write,类型为 SHARED_READ_ONLY 和 SHARED_NO_READ_WRITEalter table,类型为 EXCLUSIVE,与其它 MDL 都互斥select,select … lock in share mode,类型为 SHARED_READinsert,update,delete,select for update,类型为 SHARED_WRITE
-
查看元数据锁(适用于 MySQL 8.0 以上版本)
select object_type,object_schema,object_name,lock_type,lock_duration from performance_schema.metadata_locks;
表级锁 - IS(意向共享) 与 IX(意向排他)
【意向锁】
客户端1加了IS(意向共享)锁,则其他客户端表锁中还可以加上read共享锁;客户端1加了IX(意向排他)锁,则其他客户端表锁中什么锁都不能加啦;
- 主要是 避免 DML 与表锁冲突,DML 主要目的是加行锁,为了让表锁不用检查每行数据是否加锁,加意向锁(表级)来减少表锁的判断,意向锁之间不会互斥
- 加意向表锁的几种情况
select … lock in share mode会加 IS 锁insert,update,delete, select … for update会加 IX 锁
- 查看意向表锁(适用于 MySQL 8.0 以上版本)
select object_schema,object_name,index_name,lock_type,lock_mode,lock_data from performance_schema.data_locks;
行级锁(InnoDB)
-
种类
- 行锁 – 在 RC 下,锁住的是行,防止其他事务对此行 update 或 delete
- 间隙锁 – 在 RR 下,锁住的是间隙,防止其他事务在这个间隙 insert 产生幻读
- 临键锁 – 在 RR 下,锁住的是前面间隙+行 ,特定条件下可优化为行锁
-
查看行级锁
select object_schema,object_name,index_name,lock_type,lock_mode,lock_data from performance_schema.data_locks where object_name='表名';
注意
- 它们锁定的其实都是 索引上的行与间隙,根据索引的有序性来确定间隙
测试数据
create table t (id int primary key, name varchar(10),age int, key (name));
insert into t values(1, 'zhangsan',18);
insert into t values(2, 'lisi',20);
insert into t values(3, 'wangwu',21);
insert into t values(4, 'zhangsan', 17);
insert into t values(8,'zhang',18);
insert into t values(12,'zhang',20);
说明
- 1,2,3,4 之间其实并不可能有间隙
- 4 与 8 之间有间隙
- 8 与 12 之间有间隙
- 12 与正无穷大之间有间隙
- 其实我们的例子中还有负无穷大与 1 之间的间隙,想避免负数可以通过建表时选择数据类型为 unsigned int
间隙锁例子
事务1:
begin;
select * from t where id = 9 for update; /* 锁住的是 8 与 12 之间的间隙 */
事务2:
update t set age=100 where id = 8; /* 不会阻塞 */
update t set age=100 where id = 12; /* 不会阻塞 */
insert into t values(10,'aaa',18); /* 会阻塞 */
临键锁和记录锁例子
事务1:
begin;
select * from t where id >= 8 for update;
- 临键锁锁定的是左开右闭的区间,与上条查询条件相关的区间有 (4,8],(8,12],(12,+∞)
- 临键锁在某些条件下可以被优化为记录锁,例如 (4,8] 被优化为只针对 8 的记录锁,前面的区间不会锁住
事务2:
insert into t values(7,'aaa',18); /* 不会阻塞 */
update t set age=100 where id = 8; /* 会阻塞 */
insert into t values(10,'aaa',18); /* 会阻塞 */
update t set age=100 where id = 12; /* 会阻塞 */
insert into t values(13,'aaa',18); /* 会阻塞 */