文章目录
- 一、if 语句
- 二、去重问题
- 三、concat,upper,lower
- 四、group_concat
- 五、like 模糊匹配
- 六、union和union all
- 七、流程控制语句case
- 八、limit
一、if 语句
if(expr1, expr2, expr3)
当expr1的值为真时函数的返回值为expr2,当expr1的值为假时,函数的返回值为expr3
举例:
- 计算特殊奖金
Employees表,employee_id 是这个表的主键。此表的每一行给出了雇员id ,名字和薪水。

写出一个SQL 查询语句,计算每个雇员的奖金。如果一个雇员的id是奇数并且他的名字不是以’M’开头,那么他的奖金是他工资的100%,否则奖金为0。返回的结果集请按照employee_id排序。
/*
select employee_id, salary * (mod(employee_id, 2) = 1 and substr(name, 1, 1) != 'M') as bonus
from Employees
order by employee_id;
*/
select employee_id,if(employee_id % 2 != 0 and name not like 'M%', salary, 0) as bonus
from Employees
order by employee_id;
- 变更性别
Salary 表,id 是这个表的主键。sex 这一列的值是 ENUM 类型,只能从 (‘m’, ‘f’) 中取。本表包含公司雇员的信息。

请你编写一个 SQL 查询来交换所有的 ‘f’ 和 ‘m’ (即,将所有 ‘f’ 变为 ‘m’ ,反之亦然),仅使用 单个 update 语句 ,且不产生中间临时表。
注意,你必须仅使用一条 update 语句,且 不能 使用 select 语句。
update Salary
set sex = if(sex = 'm', 'f', 'm');
二、去重问题
删除重复的电子邮件
Person表,id是该表的主键列。该表的每一行包含一封电子邮件。电子邮件将不包含大写字母。
编写一个 SQL 删除语句来删除所有重复的电子邮件,只保留一个id最小的唯一电子邮件。以任意顺序返回结果表。仅需要写删除语句
/*
delete from Person
where id not in(
select t.id
from(
select min(id) as id
from Person
group by email
) as t
);
*/
delete p1 from Person p1, Person p2
where p1.email = p2.email and p1.id > p2.id;
三、concat,upper,lower
concat(str1,str2,…):用于连接两个字符串,形成一个字符串
upper(str):将输入字符串转换为大写
lower(str):将输入字符串转换为小写
举例:修复表中的名字
Users表,user_id 是该表的主键。该表包含用户的 ID 和名字。名字仅由小写和大写字符组成。

编写一个 SQL 查询来修复名字,使得只有第一个字符是大写的,其余都是小写的。返回按 user_id 排序的结果表。
/*
select user_id,concat(upper(substr(name,1,1)), lower(substr(name,2,length(name)-1))) as name
from Users
order by user_id;
*/
select user_id,concat(upper(left(name,1)), lower(right(name,length(name)-1))) as name
from Users
order by user_id;
四、group_concat
group_concat()中的值为你要合并的数据的字段名,可以在内部用 distinct 来去重,distinct要去重,默认就要先排序;
separator函数是用来分隔这些要合并的数据的;
' '中是你要用哪个符号来分隔;

编写一个 SQL 查询来查找每个日期、销售的不同产品的数量及其名称。每个日期的销售产品名称应按词典序排列。返回按 sell_date 排序的结果表
select sell_date,count(distinct product) as num_sold, GROUP_CONCAT(distinct product order by product SEPARATOR ',') as products
from Activities
group by sell_date;
五、like 模糊匹配
like:用于在 where子句中搜索列中的指定模式
%:用于在模式的前后定义通配符(默认字母)
举例:患某种疾病的患者
Patients表,patient_id (患者 ID)是该表的主键。‘conditions’ (疾病)包含 0 个或以上的疾病代码,以空格分隔。这个表包含医院中患者的信息。

写一条 SQL 语句,查询患有 I 类糖尿病的患者 ID (patient_id)、患者姓名(patient_name)以及其患有的所有疾病代码(conditions)。I 类糖尿病的代码总是包含前缀 DIAB1 。
# instr 函数是一个字符串处理函数,返回子字符串在源字符串中的位置,如果在源串中没有找到子串,则返回0
/*
select *
from Patients
where instr(conditions, " DIAB1") or substr(conditions,1,5) = "DIAB1";
*/
select *
from patients
where conditions like 'DIAB1%' or conditions like '% DIAB1%';
六、union和union all
union:去重且排序,取唯一值,记录没有重复
union all:不去重不排序,直接连接,取到得是所有值,记录可能有重复
举例:
- 丢失信息的雇员
Employees表,employee_id 是这个表的主键。每一行表示雇员的id 和他的姓名。
Salaries表,employee_id is 这个表的主键。每一行表示雇员的id 和他的薪水。
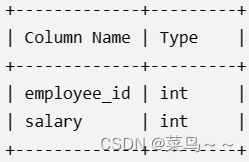
写出一个查询语句,找到所有 丢失信息 的雇员id。当满足下面一个条件时,就被认为是雇员的信息丢失:雇员的姓名丢失了,或者雇员的薪水信息丢失了。返回这些雇员的id employee_id , 从小到大排序 。
/*order by默认从小到大
select employee_id
from Employees
where employee_id not in(
select employee_id
from Salaries
)
union
select employee_id
from Salaries
where employee_id not in(
select employee_id
from Employees
)
order by employee_id;
*/
/*union having
select employee_id
from(
select employee_id from Employees
union all
select employee_id from Salaries
) as t
group by employee_id
having count(*) = 1
order by employee_id;
*/
# 左右连接
select a.employee_id
from Employees a left join Salaries b
on a.employee_id = b.employee_id
where b.salary is null
union
select a.employee_id
from Salaries a left join Employees b
on a.employee_id = b.employee_id
where b.name is null
order by employee_id;
- 每个产品在不同商店的价格
Products表,这张表的主键是product_id(产品Id)。每行存储了这一产品在不同商店store1, store2, store3的价格。如果这一产品在商店里没有出售,则值将为null。

请你重构 Products 表,查询每个产品在不同商店的价格,使得输出的格式变为(product_id, store, price) 。如果这一产品在商店里没有出售,则不输出这一行。输出结果表中的顺序不作要求 。
# 列转行用union all,行转列用group by + sum if
select product_id, 'store1' store, store1 price
from Products
where store1 is not null
union all
select product_id, 'store2', store2 price
from Products
where store2 is not null
union all
select product_id, 'store3', store3 price
from Products
where store3 is not null
order by product_id, price;
七、流程控制语句case
case流控制语句对基于不同输入产生不同输出非常有效。CASE语句遍历条件并在满足第一个条件时返回一个值(如IF-THEN-ELSE语句)。因此,一旦条件为真,它将停止读取并返回结果。如果没有条件为 true,则返回 ELSE 子句中的值。
如果没有其他部分,并且没有条件为 true,则返回 NULL。
case语法:
CASE
WHEN condition1 THEN result1
WHEN condition2 THEN result2
WHEN conditionN THEN resultN
ELSE result
END;
举例:树节点
给定一个表 tree,id 是树节点的编号, p_id 是它父节点的 id 。

树中每个节点属于以下三种类型之一:
- 叶子:如果这个节点没有任何孩子节点。
- 根:如果这个节点是整棵树的根,即没有父节点。
- 内部节点:如果这个节点既不是叶子节点也不是根节点。
写一个查询语句,输出所有节点的编号和节点的类型,并将结果按照节点编号排序
/* if 语句
select id,
if(isnull(p_id),
'Root',
if(id in (select t.p_id from tree t), 'Inner', 'Leaf')) as Type
from tree;
*/
#case
select id,
case
when p_id is null then 'Root'
when id in (select p_id from tree) then 'Inner'
else 'Leaf'
end as Type
from tree;
八、limit
第二高的薪水
Employees表,id 是这个表的主键。表的每一行包含员工的工资信息。
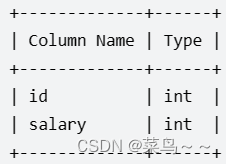
编写一个 SQL 查询,获取并返回 Employee 表中第二高的薪水 。如果不存在第二高的薪水,查询应该返回 null 。
#IFNULL(expression_1,expression_2);
#如果expression_1不为NULL,则IFNULL函数返回expression_1; 否则返回expression_2的结果。
select ifnull(
(select distinct salary
from Employee
order by salary desc limit 1,1),
null) as SecondHighestSalary;



![[牛客网] HJ35 蛇形矩阵(写了好久才写出来)](https://img-blog.csdnimg.cn/img_convert/80d01f56b0444a6a8dc055e3702c3241.png)


![[SQL]增删查改语法概览](https://img-blog.csdnimg.cn/img_convert/d10a154046e85e775e87731972b922ef.png)