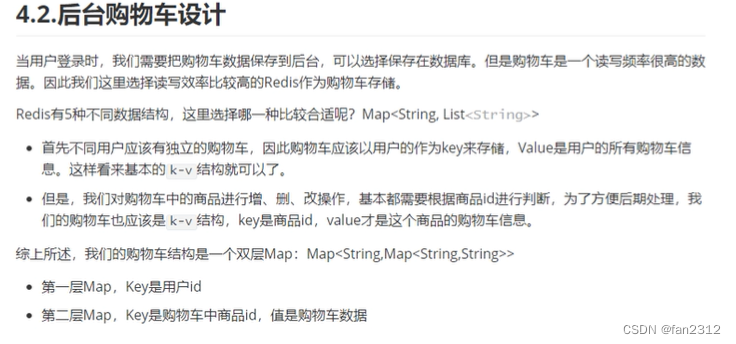
大数据技术生态全景一览
- 大数据平台ETL数据接入
- 大数据平台海量数据存储
- 大数据平台通用计算
- 大数据平台各场景的分析运算
- 分布式协调服务
- 任务流调度引擎
大数据平台ETL数据接入
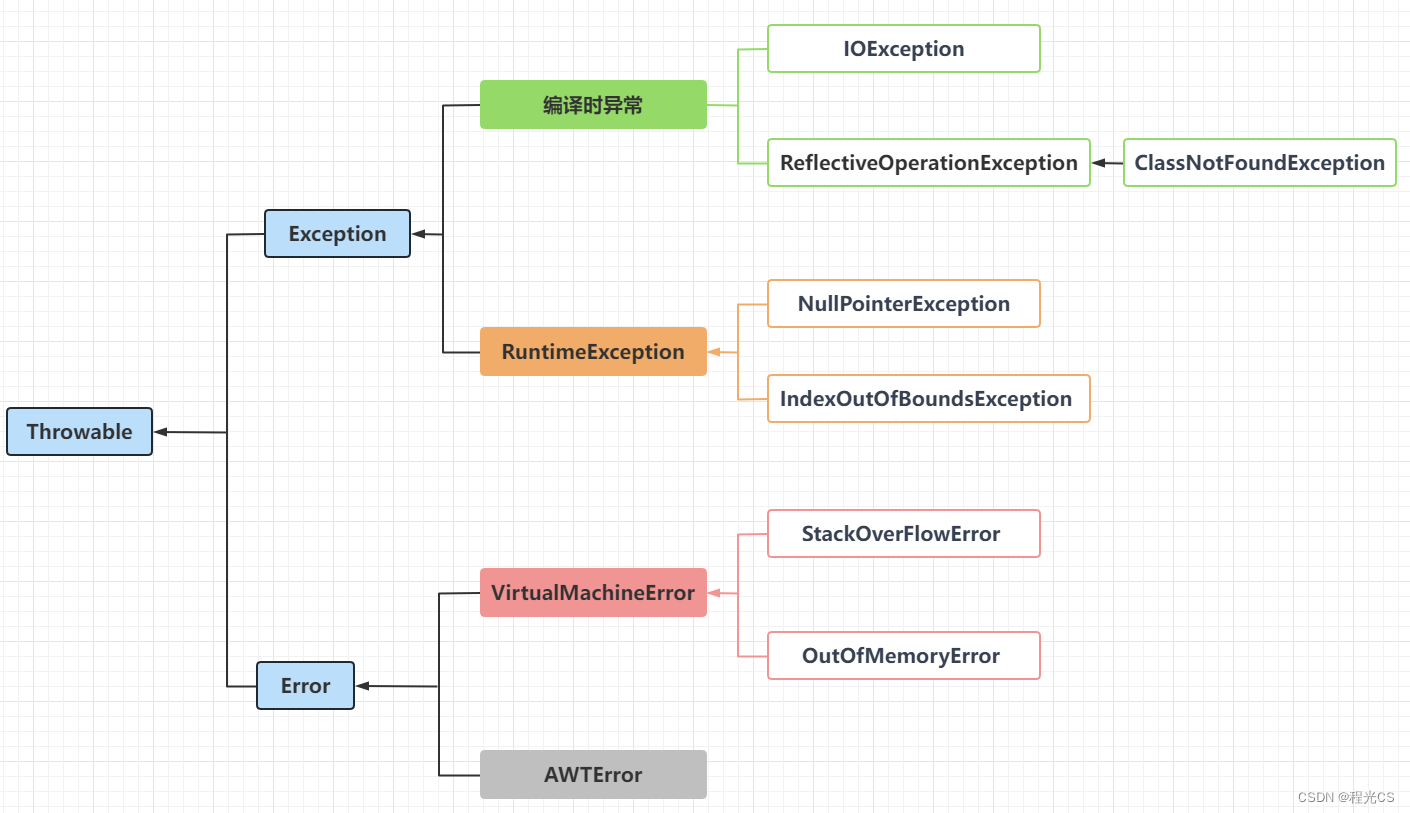
大数据有很多的产品,琳琅满目。从架构图上就能看出产品很多。这些产品它们各自的功能是什么,它们又是怎么样相互配合来完成一整套的数据存储,包括分析计算任务。这里要给大家进行一个讲解与分析。
我们按照数据处理的流程,从下往上给大家进行依次的讲解。
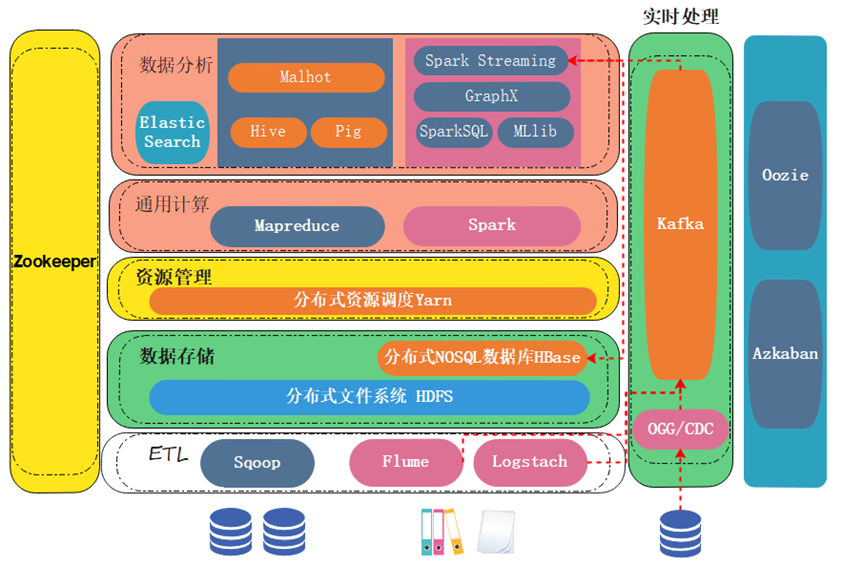
首先我们看数据源,数据有结构化数据,存在关系型数据库里的数据,它以二维表的形式进行存储;还有一些非结构化、半结构化数据,比如日志 json属于半结构化数据,图片视频音频属于非结构化数据。
对于结构化数据来说,一般通过sqoop组件进行抽取,把数据抽取到大数据存储平台。
大数据存储平台主流的选型是HDFS,因为它已经非常成熟了,并且经过很多年的一个打磨。
Sqoop会通过jdbc的方式,连接到数据库,对数据库进行直接抽取后做一个导出。将数据导出到HDFS中。
Sqoop在抽取的时,一般是T+1的。什么叫T+1?就是今天产生的数据,可能明天才能导入到大数据平台,它的时效性比较低一些。
像数据仓库,它其实是每天凌晨0点才会把昨天新生成的数据统一进行一个导入。
对于这种非结构化半结构化数据,它们其实就是文件,例如图片、视频、日志、json。这种文件一般来说,它们会实时产生。比如监控的摄像头,它会实时产生图片或者视频;日志会实时在服务器端生成。
实时产生的数据要进行实时抽取,这个时候肯定就不能用sqoop了,这些数据会通过flume或者logstash进行实时的监控。一旦这些非结构化半结构化数据产生,它们就会立即被抽取到大数据的存储平台。
但是按照我们前面讲过的一个知识点,实时产生的数据在架构设计上来说,我们要先给它推送到一个消息队列中进行缓冲,起到一个抗压的作用。
这个消息队列,常用的选型就是Kafka,它能扛住数据源的并发压力。扛住压力以后,实时产生的数据一定是要先经过大数据平台的处理,处理完以后再把结果存到大数据存储平台。这样才能发挥实时数据的一个价值。
所以这种实时数据,它不是直接往大数据平台存,而是先经过消息队列缓存抗压后,再由大数据平台处理,最终将计算结果保存起来。
有的同学这个时候想了,那结构化的数据,如果它也想进行实时的一个抽取,可不可以实现?当然可以,这个时候它要用到另外一种方式,目前有CDC和Ogg。Ogg是Oracle特有的,CDC是开源的。
它们可以监控,数据库里的结构化数据,当数据一旦发生变化,它们就会监控到变动的数据,并将数据抽到Kafka或其它消息队列中。再交给大数据平台进行一个处理。
它们为什么能够进行实时的一个监控?其实它们监控的是数据库的日志,比如说Mysql会有binlog,其他的数据库也有它们特有的日志文件,当我们在对数据库做一些数据新增、修改删除的操作的时候,数据库会先把这样的一个操作记录在日志中,以保证容灾。之后再往数据库里面进行一个持久化写入。
我们直接监控数据库的日志,数据的实时的变更就可以立马获取到,而且不影响数据库的性能,因为日志本身就是一个文件。这是CDC和Ogg,它做的一个事情。
所以在数据源这里,结构化数据可以使用T+1的方式,隔一段时间抽一次,导入到大数据平台。非结构化半结构化数据,当然也可以通过flume和logstach定时(T+1)把它们抽到大数据平台。
但非结构化与半结构化数据的应用场景,更多的是实时去抽取,并传送到消息队列kafka中。结构化数据通过cdc、ogg,也实时抽取到kafka。
这样的话我们不管是结构化数据,还是非结构化半结构化数据,都可以满足t+1与实时抽取方式的需要。
大数据平台海量数据存储
那数据最终会存储到我们的hdfs中,但hdfs它本质上是一个文件系统,生产上使用起来并不能适合所有场景。生产中没有见过,我们直接把数据存到文件系统里面。
我们一般会选择把数据存到数据库里,hbase就是一个分布式的nosql数据库。它是基于hdfs建立的,虽然数据最终它也是存在hdfs中,但是它上层搭建了一个数据库,这个数据库用起来易用性会更好。
这样的话你抽取过来的数据,可以直接存到hdfs里,也可以存到hbase中,就看具体的应用场景来具体对待。
大数据平台通用计算
那数据存储起来以后,我们要基于这个数据做一些运算。运算的时候,可以用mapreduce也可以用spark。
Mapreduce它计算起来要慢一些,Spark相对快一些。不管使用哪种计算框架,它们的计算任务要移动到数据节点进行一个运算。
怎么能够把计算任务分发到数据节点,要通过中间资源管理层的一些框架来完成。这里最常用的是分布式资源调度框架YARN。
YARN这个框架,它在部署的时候是和数据存储的框架部署在一起的。比如说我们底层的hdfs,它是用来做存储的有三个节点,于是YARN它也装在这三个节点上,并且管理的这三个节点的计算资源。计算资源一般包含CPU、内存,还有一些环境变量。
MapReduce和Spark计算任务,要移动到数据节点进行运算,这个时候Yarn就可以直接在数据节点上分配给这些计算任务一些计算资源;它们就可以顺利的紧贴数据运算。
运算完成之后,Yarn又可以把资源进行一个回收。所以大数据的移动计算这一块的实现,就是通过资源管理层它来完成的。
大数据平台各场景的分析运算
虽然我们在做计算的时候,有了MapReduce有了Spark,但是用起来还是不够好用,易用性还是不够好。
因为我们在开发的时候,针对于这种结构化数据,一般我们习惯用什么?用SQL。一些非结构化半结构化数据,我们习惯用一些API。
但是现在你把数据抽取到大数据平台以后,这些SQL API都不能用了。你只能用它提供的MapReduce和spark去进行一个数据处理,对于我们来说就很难用。
而且之前我们的业务系统用的SQL,用的一些API,你是不是都要进行一个迁移。迁移的时候这个工作量就很大了。
为了让我们的数据开发,或者数据分析这样的一个过程更加易用。大数据这里其实提供了很多的一些易用框架,比方说Hive,它其实完成的就是帮你把SQL转换成底层的mapreduce。
当然Hive也可以转换成Spark,计算的效率会更高。
这样的话你原来的结构化数据,存到大数据平台后,之前是用SQL进行开发的,现在依然可以用SQL。由Hive帮你把SQL转换成通用计算,转化完成之后通用计算的mapreduce或者spark再通过资源管理调度到我们的数据节点,紧贴数据完成整个计算任务。
Pig也是相同的情况,Pig有它的一些API,你使用它的API进行开发。它会把这些API转换成MapReduce任务,当然Pig比较早就停止维护了。
还有malhot,它是做机器学习的,用它提供的机器学习的API,然后它帮你转换成MapReduce。
所以数据分析这一层,它们完全是用于提高我们易用性而诞生的一些框架。
而根据它们转换的计算任务的不同,如果默认是转换mapreduce的,它们就属于hadoop生态圈。
因为hadoop包含三个组件,除了hdfs、mapreduce之外,在hadoop 2.x的时候增加了一个YARN。
默认兼容hadoop的,就属于hadoop生态圈。当然有一些框架其实刚开始诞生的时候是兼容hadoop的,后面因为spark它的性能更高,用的公司更多一些;所以hadoop生态圈有一些框架,比如说hive它也可以运行在spark上面。
当然spark也有它的一些生态,spark sql帮你把sql转换成spark任务;Mllib是做机器学习的;GraphX是作图计算的。
spark streaming是做流计算的,就是实时处理,我们一般称为实时流处理或者实时流计算,它计算得到的结果我们会给它存到hdfs里或者hbase里,当然我们一般会存储在hbase里。
因为实时的结果,如果存到hdfs里的话它会产生一些小文件问题。hdfs对于小文件来说是很敏感的,它很容易把管理节点的内存给占满,而且也会导致后续计算的一个效率下降。所以实时计算完得到的结果会存到hbase中。
hbase虽然说数据最终也存到hdfs,但是它是一个数据库,它解决了小文件问题。它并没有小文件问题带来的这些隐患。
这一部分是spark生态圈,我们之后在做开发的时候,大部分同学可能直接用spark或者mapreduce进行编程相对会比较少一些。我们可能更多的是用上层的,易用性比较高的组件来进行一些相关的开发。
还有一些是独立开发的组件(非Hadoop、Spark生态圈),比如说elasticsearch它是做搜索与检索的,数据存到elasticsearch里面以后可以进行一些模糊查询、精确匹配、语义匹配等一些操作。
为什么说它是独立的?因为elasticsearch有它自己的通用计算,也有它自己的资源管理,包括数据存储层。所以它并不依赖hadoop,它也不依赖spark。这个产品里面,它本身就包含这几层。所以它属于一个独立的产品。
分布式协调服务
最左边有一个zookeeper,zookeeper对大数据的各个产品其实是非常重要的。很多产品比如说hdfs、hbase都要依赖zookeeper。
它是干嘛的?它是一个分布式的协调服务。
因为大数据的产品它都是分布式,也就是运行在多个节点上的。比方说我们某一个大数据组件,它突然新增的一个节点上来,zookeeper就会识别到,然后通知我们之前的3个节点说,你现在的集群规模变成了4。
突然这个节点挂掉了,zookeeper也会通知另外三个节点说,好,你现在有一个节点挂掉了,节点数现在变成了3。
包括说我们的集群里面,有多个管理节点,但是这些管理节点它只有一个能够管理当前集群,其他的都是备用节点。这样的话究竟由谁来进行管理?谁来做备份?zookeeper可以进行一个选举。
比如说选第一个,作为当前的管理节点,另外两个做备份。管理节点挂掉以后,zookeeper又可以从剩下的两个备用节点里面再选出一个来,让它来进行集群的一个接管。
所以zookeeper的作用其实是很大的,我们用到的这些大数据产品,只要想要在分布式环境下进行协调,都可以依赖zookeeper来完成这样的一个诉求。
而且像一些组件是必须依赖zookeeper的,比如说kafka它在搭建之前,zookeeper必须要进行安装。
任务流调度引擎
最右边有两个任务的调度组件,一个叫oozie一个叫azkaban。azkaban相对比较新一些,它俩是用来调度我们的计算任务的,比如说我们在大数据集群里面的任务,它如果有一个先后顺序,比如说任务1完成以后,我们任务2才可以执行,任务2执行完成以后再任务3。
如果有一个严格的先后顺序,可以由oozie和azkaban来进行一个限定。再比如计算任务,如果我们要进行定时,比如说让它每天凌晨0点的时候定时执行,就可以由oozie或azkaban来完成。
所以它们主要是来完成这种任务流的管理和调度的。
OK,那大数据的整个产品就先介绍到这里,当然大数据的产品不止这些,大家要慢慢归纳,整体的架构是一致的,可以定位到它所属的分层后基本就明白它的职责。那我们下期再会!B站配套视频传送:大数据技术生态全景一览