背景介绍
图(Graphs)是一种对物体(objects)和他们之间的关系(relationships)建模的数据结构,物体以结点(nodes)表示,关系以边(edges)表示。图是复杂系统中常用的信息载体,可以表示现实中许多复杂关系,如社交网络、犯罪网络、交通网络等。
环境配置
实践环境建议以Python3.7+,且需要安装如下库:
numpy
pandas
networkx
igraph
gensim
Task1: 图属性与图构造
Task1.1 导入network
import pandas as pd
import numpy as np
import networkx as nx
import matplotlib.pyplot as plt
Task1.2 加载数据集
# 两列,分别为节点id,节点类别
group = pd.read_csv('DATA/group.txt.zip', sep='\t', header=None)
#查看节点个数
print('节点个数:{}, 节点类别:{}'.format(group[0].nunique(), group[1].nunique()))
# 两列,分别为出发节点id,目的节点id
graph = pd.read_csv('DATA/graph.txt.zip', sep='\t', header=None)
#查看边的个数
print("边的个数:{},起始节点个数:{}, 终止节点个数:{}".format(graph.shape[0], graph[0].nunique(), graph[1].nunique()))

Task1.3 使用network构造有向图
# 创建 图
G1 = nx.Graph() # 创建:无向图
G2 = nx.DiGraph() #创建:有向图
G3 = nx.MultiGraph() #创建:多图
G4 = nx.MultiDiGraph() #创建:有向多图

#创建有向图,nx在2.5.0以上才会有指向自身的箭头
g = nx.DiGraph()
# 只添加前100条边
g.add_edges_from(graph.values[:100])
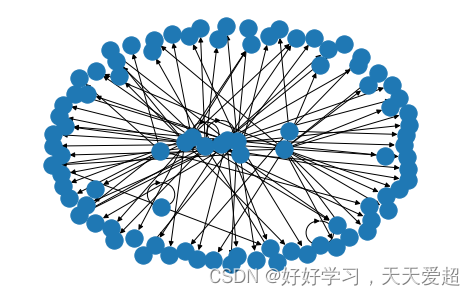
nx.draw_spring(g)
# 添加所有数据
g = nx.DiGraph()
g.add_edges_from(graph.values[:])
Task2: 图查询与遍历
步骤1:使用networkx对Wiki数据集进行如下统计
节点个数、边个数
dir(g) 查看graph的属性

print('节点个数{}, 边的个数{}'.format(g.number_of_nodes(), g.number_of_edges()))

节点度平均
1.查看节点的度,是个dict类型,key是node,value是入度+出度
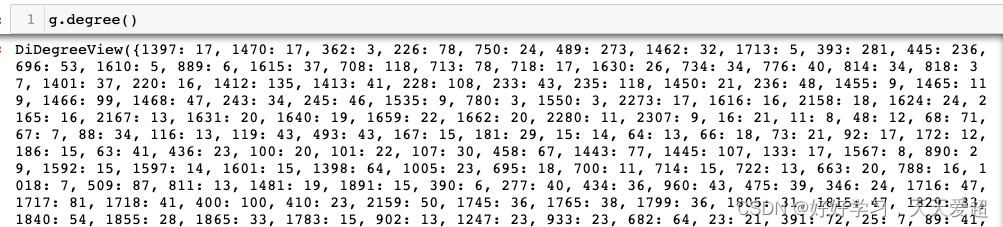
2.求度的均值
#节点度平均
np.mean([x[1] for x in list(g.degree)])

存在指向自身节点的个数
指向自身节点,就是边的起始点一样,edge[0]==edge[1]

步骤2:对节点1397进行深度和广度遍历,设置搜索最大深度为5
dir(nx)查看nx属性
# 对节点1397的深度5内进行深度和广度遍历
nx.dfs_tree(g, 1397, 5).nodes()
nx.bfs_tree(g, 1397, 5).nodes()
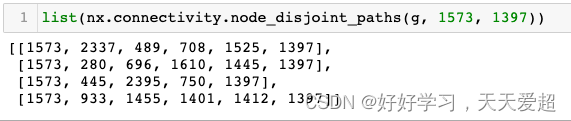
步骤3:判断节点1573与节点1397之间是否存在联通性
list(nx.connectivity.node_disjoint_paths(g, 1573, 1397))
Task3: 节点中心性与应用
步骤1:筛选度最大的Top10个节点,并对节点深度1以内的节点进行可视化;
步骤2:使用PageRank筛选Top10个节点,并对节点深度1以内的节点进行可视化;
步骤3:文本关键词提取算法RAKE
使用jieba对文本进行分词
单词作为节点,距离2以内的单词之间存在边
计算单词打分 wordDegree (w)/ wordFrequency (w)
按照打分统计每个文章Top10关键词
步骤4:文本关键词提取算法TextRank
使用jieba对文本进行分词
单词作为节点,距离2以内的单词之间存在边
使用PageRank对单词进行打分
按照打分统计每个文章Top10关键词
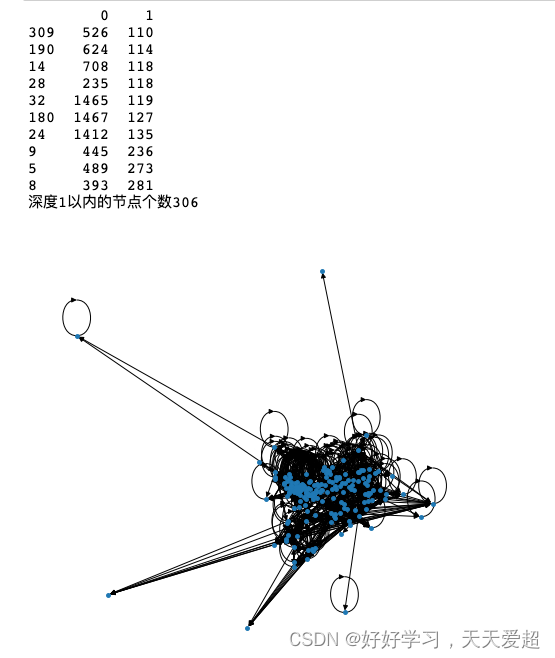
#步骤1:筛选度最大的Top10个节点,并对节点深度1以内的节点进行可视化;
g_degree = pd.DataFrame(g.degree()).sort_values(by=1)
g_degree = g_degree.iloc[-10:]
#对深度1以内的节点进行可视化
selected_nodes = []
for node in g_degree[0].values:
selected_nodes += list(nx.dfs_tree(g, node, 1).nodes())
print('深度1以内的节点个数{}'.format(len(selected_nodes)))
#设置图片大小
plt.rcParams['figure.figsize']= (10, 10)
nx.draw_spring(g.subgraph(selected_nodes), node_size=15)
# 步骤2:使用PageRank筛选Top10个节点,并对节点深度1以内的节点进行可视化;
g_pagerank = pd.DataFrame.from_dict(nx.pagerank(g), orient='index')
g_pagerank = g_pagerank.sort_values(by=0)
g_pagerank = g_pagerank.iloc[-10:]
print(g_pagerank)
selected_nodes = []
for node in g_pagerank[0].index:
selected_nodes += list(nx.dfs_tree(g, node, 1).nodes())
print('深度1以内的节点个数{}'.format(len(selected_nodes)))
nx.draw_spring(g.subgraph(selected_nodes), node_size=15)

contents=[
# 文章1
'''
一纸四季报,令芯片巨头英特尔一夜间股价重挫近6.5%,市值蒸发80亿美元,再度被AMD反超。
这份严重缩水的财报显示,英特尔在去年四季度营收大降32%至140亿美元,是2016年以来最低单季收入;净利润由三季度的10.2亿美元转为近7亿美元净亏损;毛利率更从2021年四季度的53.6%大幅下降至39.2%。
此番业绩“跳水”并非英特尔一家的一时失利,在全球PC出货量整体下滑的背景下,包括英特尔、AMD、英伟达、高通在内的芯片企业,均在过去一年里出现不同程度的收入与利润下滑,但英特尔的确是其中的重灾区。
'''
,
# 文章2
'''
2021年,成都地区生产总值已经超过1.99万亿元,距离2万亿门槛仅咫尺之间。在去年遭受多轮疫情冲击及高温限电冲击的不利影响下,2022年,成都市实现地区生产总值20817.5亿元,按可比价格计算,比上年增长2.8%。
成都因此成为第7个跨过GDP2万亿门槛的城市。目前,GDP万亿城市俱乐部中形成了4万亿、3万亿、2万亿和万亿这四个梯队。上海和北京在2021年跨过了4万亿,深圳2021年跨过了3万亿,重庆、广州、苏州和成都则是2万亿梯队。
在排名前十的城市中,预计武汉将超过杭州。武汉市政府工作报告称,预计2022年武汉地区生产总值达到1.9万亿元左右。而杭州市统计局公布的数据显示,杭州2022年地区生产总值为18753亿元。受疫情影响,武汉在2020年GDP排名退居杭州之后。
'''
,
# 文章3
'''
据报道,美国证券交易委员会(SEC)与特斯拉首席执行官埃隆·马斯克之间又起波澜。SEC正对马斯克展开调查,主要审查内容是,马斯克是否参与了关于特斯拉自动驾驶软件的不恰当宣传。
据知情人士透露,该机构正在调查马斯克是否就驾驶辅助技术发表了不恰当的前瞻声明。
特斯拉在2014年首次发布了其自动驾驶辅助功能,公司声称该功能可以让汽车在车道内自动转向、加速和刹车。目前所有特斯拉车辆都内置了该软件。
'''
]
步骤3:文本关键词提取算法RAKE
import jieba
from collections import Counter
for content in contents:
g2 = nx.Graph()
words = jieba.lcut(content)
words = [x for x in words if len(x) > 1]
for i in range(len(words)-2):
for j in range(i-2, i+2):
if i == j:
continue
g2.add_edge(words[i], words[j])
g2_node_gree = dict(g2.degree())
word_counter = dict(Counter(words))
g2_node_gree = pd.DataFrame.from_dict(g2_node_gree, orient='index')
g2_node_gree.columns = ['degree']
g2_node_gree['freq'] = g2_node_gree.index.map(word_counter)
g2_node_gree['score'] = g2_node_gree['degree'] / g2_node_gree['freq']
print(list(g2_node_gree.sort_values(by='score').index[-10:]))
g2.clear()

文本关键词提取算法TextRank
for content in contents:
g2 = nx.Graph()
words = jieba.lcut(content)
words = [x for x in words if len(x) > 1]
for i in range(len(words)-2):
for j in range(i-2, i+2):
if i == j:
continue
g2.add_edge(words[i], words[j])
g2_node_gree = pd.DataFrame.from_dict(nx.pagerank(g2), orient='index')
g2_node_gree.columns = ['degree']
g2_node_gree = g2_node_gree.sort_values(by='degree')
print(list(g2_node_gree.sort_values(by='degree').index[-10:]))
g2.clear()

Task4: 图节点嵌入算法:DeepWalk/node2vec
步骤1:使用DeepWalk对Wiki数据集节点嵌入,维度为50维
步骤2:每个group中20%的节点作为验证集,剩余的作为训练集
步骤3:使用节点嵌入向量 + 逻辑回归进行训练,并记录验证集准确率
步骤4:使用node2vec重复上述操作
步骤5:使用t-SNE将节点的DeepWalk/node2vec特征降维,绘制散点图,节点颜色使用group进行区分
2014 DeepWalk: Online Learning of Social Representations, PDF
DeepWalk的思想类似word2vec,使用图中节点与节点的共现关系来学习节点的向量表示。那么关键的问题就是如何来描述节点与节点的共现关系,DeepWalk给出的方法是使用随机游走(RandomWalk)的方式在图中进行节点采样。
RandomWalk是一种可重复访问已访问节点的深度优先遍历算法。给定当前访问起始节点,从其邻居中随机采样节点作为下一个访问节点,重复此过程,直到访问序列长度满足预设条件。