DQN和TD更新算法。
目录
Review
1. Deep Q-Network(DQN)
1.1 Approximate the Q*(s,a) Function
1.2 Apply DQN to Play Game
1.3 Temporal Difference(TD) Learning
1.4 TD Learning for DQN
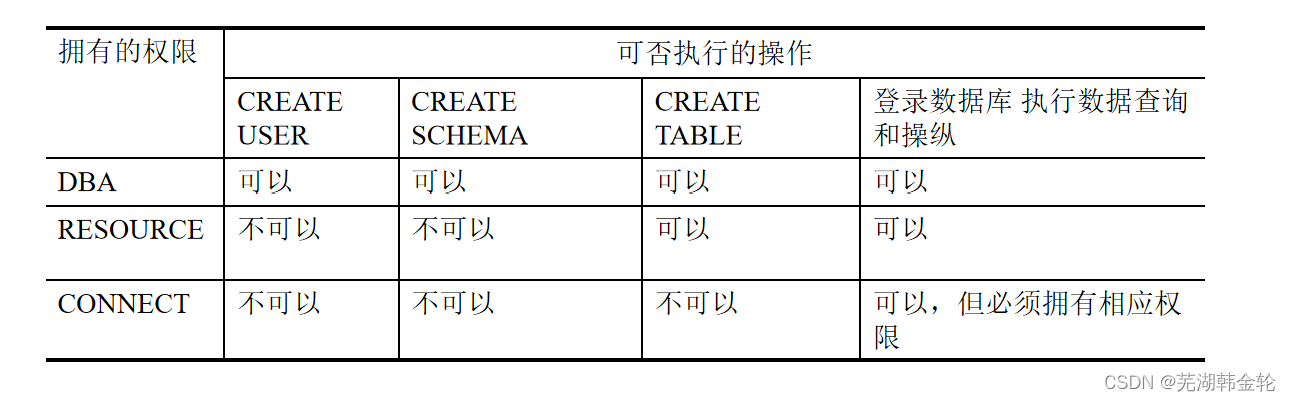
1.4.1 TD使用条件 condition
1.4.2 Train DQN using TD learning
1.5 summary: DQN and TD learning
参考
Review

- Ut是未来奖励reward的加权和
- Qπ(st, at)可以反应当前状态st下动作at的好坏程度。
- 对Qπ关于π求最大化,Q*函数可以给所有动作打分。
1. Deep Q-Network(DQN)
本质:用神经网络近似Q*函数
1.1 Approximate the Q*(s,a) Function
Goal: Win the game(≈ maximize the total world.)
Question: If we know Q*(s, a), what is the best action? 假设我们知道Q*函数
![]()
Q* is an indication for how good it is for an agent to pick action a while being in state s.
Challenge: we do not know Q*(s, a)函数
value-based model,就是学习一个函数来近似Q*函数。--> DQN
- Solution: Deep Q Network (DQN)
- Use neural network Q(s, a; w) to approximate Q*(s, a)
用一个神经网络去近似Q*(s,a)函数,神经网络参数是w、输入是s、输出是很多数值(这些数值是对所有可能动作的打分),通过奖励reward来学习这个网络,这个网络对动作的打分就会逐渐改进,打分会越来越准。
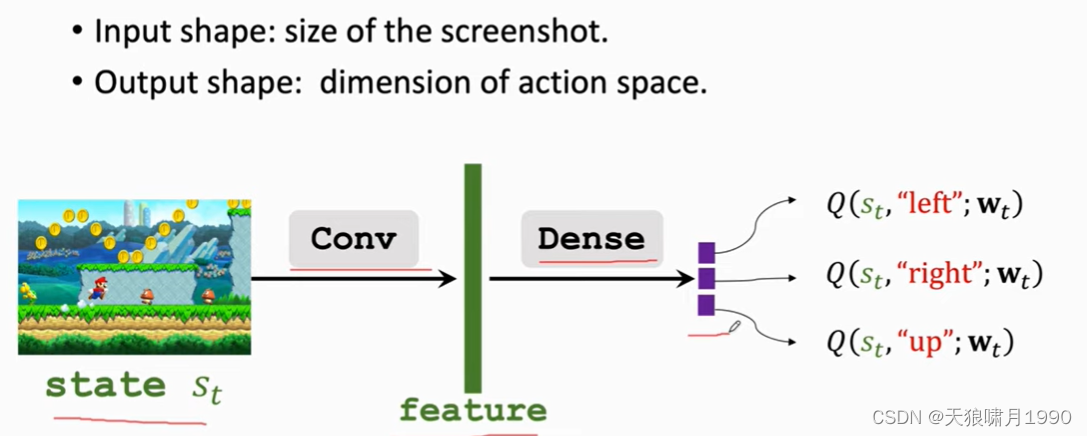
1.2 Apply DQN to Play Game

- 当前观测到状态st,用DQN把st作为输入给所有的动作actions打分,选出分数最高的动作作为at,agent执行动作at后,
- environment会改变状态S,用状态转移函数p来随机抽一个新的状态st+1,还会告诉我们这一步的奖励rt(rt可以是正的、负的、0)。
- 奖励reward就是强化学习中的监督信号,DQN要靠这些奖励来训练。
- 有了新的状态st+1,DQN对所有动作进行打分,agent选择分数最高的动作作为at+1。at+1后,环境会再更新状态st+2、再给一个奖励r+1。
- 然后重复这个过程,直到游戏结束。
how to train a DQN?
1.3 Temporal Difference(TD) Learning
TD算法,时间差分算法。

challenge: Can I update the model before finishing the trip?
TD 算法。
- TD target。
- TD error。
- 用梯度下降来减小TD error

1.4 TD Learning for DQN
1.4.1 TD使用条件 condition

证明:


左边称为Prediction;右边称为TD target。
1.4.2 Train DQN using TD learning
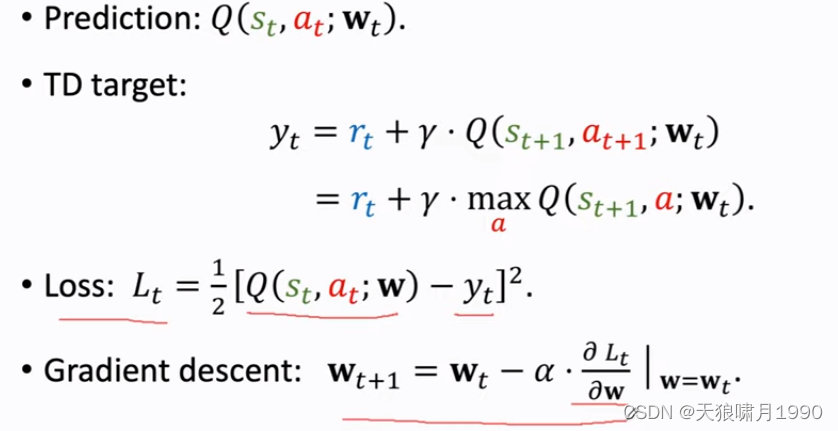
agent在t+1时刻的动作at+1,DQN对所有动作a进行打分,分数最高的动作作为at+1。
注意,这里的a不等于at。
1.5 summary: DQN and TD learning


参考
1. 王树森~强化学习 Reinforcement Learning
2. https://www.cnblogs.com/pinard/category/1254674.html