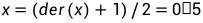fuse:纠结的page下刷流程细节之fuse_writepage_in_flight
- fuse_writepage_in_flight
- 硬爬代码
- 自己理解消化
- 作者本人如是说
fuse_writepage_in_flight
先说下这个函数,位于fs/fuse/file.c,这里以4.19内核来分析。因为这个函数里面藏了很多小细节,不看作者的pr comment真的很难完全理解到底是怎么想的。果然,如果再对比下5.10的版本这个函数的模样又变了不少。
static bool fuse_writepage_in_flight(struct fuse_req *new_req,
struct page *page);
参数new_req是一个刚刚填充好内容的,op是FUSE_WRITE类型的fuse request实例的指针,这个request里面也已经填充好了待下刷的若干页page,嗯提前剧透它肯定只包含一个page;
而第二个参数page是request里这“若干页page”中的最后一个page(其实也就是唯一的一个page)的copy。那看函数名称就是说需要来判断一下第二个参数这个page的内容,或者说fuse request对象里包含的最后一个page内容,是不是已经在发送流程中了(处于pending或sent状态);
从函数名来看只要求得到“是”或“否”的回答就可以了,但是C代码嘛,或者说内核代码嘛,函数名和其实际行为总是有那么一点点偏差。
硬爬代码
struct fuse_conn *fc = get_fuse_conn(new_req->inode);
struct fuse_inode *fi = get_fuse_inode(new_req->inode);
struct fuse_req *tmp;
struct fuse_req *old_req;
bool found = false;
pgoff_t curr_index;
BUG_ON(new_req->num_pages != 0);
开始上来定义了一堆局部变量,都是和后续操作有关的,当然fuse内核模块几乎百分九十的函数都是从获取fuse的connect句柄和fuse inode对象开始。
这里两个fuse_req指针和curr_index是后续算法需要的,这里c代码必须在代码域开头一次性定义好局部变量的ugly就非常的扎眼了。
那句BUG_ON就非常有灵性,说明预期传入的fuse request实例必须是真的包含有至少一个单位的待刷page的。
spin_lock(&fc->lock);
list_del(&new_req->writepages_entry);
list_for_each_entry(old_req, &fi->writepages, writepages_entry) {
BUG_ON(old_req->inode != new_req->inode);
curr_index = old_req->misc.write.in.offset >> PAGE_SHIFT;
if (curr_index <= page->index &&
page->index < curr_index + old_req->num_pages) {
found = true;
break;
}
}
if (!found) {
list_add(&new_req->writepages_entry, &fi->writepages);
goto out_unlock;
}
到这里整个人还是正常的,判断第二个参数指代的page内容是不是已经处于下刷过程中了。我们看到非常的笨啊,就是去遍历fuse inode的下刷请求链表writepages,一个个判断链表里面的fuse request,如果某个fuse request包含的一组连续pages中已经完全覆盖掉了本次期望下刷的page的内容,那就是yes in flight,否则就是not found。
简单的情况就是没找到,not found,found == false,那么把当前这个request对象也加到fuse inode的writepages链表中就完事了。
我们说这一段是非常清楚的,除了line2那句list_del(),先把当前fuse request对象从任何链表里摘出来,这就是典型的强耦合补丁式的行为,单看这个函数上下文,这里唯一的理解就是在插入list head前都一律要list_del一把,大家有兴趣自己爬代码吧。
接下来就有点烧脑了,
new_req->num_pages = 1;
for (tmp = old_req; tmp != NULL; tmp = tmp->misc.write.next) {
BUG_ON(tmp->inode != new_req->inode);
curr_index = tmp->misc.write.in.offset >> PAGE_SHIFT;
if (tmp->num_pages == 1 &&
curr_index == page->index) {
old_req = tmp;
}
}
离大谱的是你凭什么确定new_req里面只包含一个page的?整个函数哪里说了new_req里一定只有一个函数的?好吧其实是全靠caller函数fuse_writepages_fill在调用本文主角的方式保证了传入的new request一定只携带了一个page,真的TM硬核耦合啊。
回头过来看这段,这里是已经找到了覆盖待刷page的一个old_req,但是这个old_req可能是所谓的“请求簇”,也就是多个fuse request通过misc.write的next字段组成一簇,第一个fuse request为主请求,后面的都是搭车的。现在我们要从这一簇中尝试找到满足如下两个条件的一个solo fuse request:
- 只携带单个page的数据;
- index正好也等于当前new request;
显然就是找到是否当前已经存在一个同样page的request,无外乎两种结果:
1). 是的当前page已经存在一个旧的fuse request;
2). 未能找到,此时old_req必然是一个携带了多个page的,且包含当前待刷page的fuse request;
下面来看下对于这两种结果分别如何处理
if (old_req->num_pages == 1 && test_bit(FR_PENDING, &old_req->flags)) {
struct backing_dev_info *bdi = inode_to_bdi(page->mapping->host);
copy_highpage(old_req->pages[0], page);
spin_unlock(&fc->lock);
dec_wb_stat(&bdi->wb, WB_WRITEBACK);
dec_node_page_state(new_req->pages[0], NR_WRITEBACK_TEMP);
wb_writeout_inc(&bdi->wb);
fuse_writepage_free(fc, new_req);
fuse_request_free(new_req);
goto out;
} else {
new_req->misc.write.next = old_req->misc.write.next;
old_req->misc.write.next = new_req;
}
如果找到了下刷同一page的request且request还未发送到userspace,那么直接把当前最新的request的page负载覆盖掉旧request的负载即可;
如果没找到,或者找到了但是已经发送到userspace了,那么把当前新request直接链接到这个old reqeust后面;
自己理解消化
综上,就是三种结果:
- 新的request插入到fuse inode对象的writepages链表中;
- 新的request插入到某旧的request的簇组中;
- 存在同一page的下刷request,直接覆盖其内容;

好,到这里可以开喷了,如开头所述,4.19版本的fuse_writepage_in_flight几乎违反了clean code所有的原则,特别是函数命名上,表面上是个仅回答yes or no的const方法,实际上它可能: - 把fuse request插入到fuse inode的writepages链表;
- 把fuse request插入到某old request的簇组链表中;
- 覆盖某old request的内容,本体被free;
当然内核代码追求的是准确性、效率和稳定性,其他诸如可读性可扩展性都不在其主要考虑范围呢,高效准确的完成功能就好。
作者本人如是说
当时反复爬了这段代码好几次,始终觉得不是很透彻。俗话说解铃还须系铃人,特别是kernel代码,直接看作者的commit就清晰多了:
https://github.com/torvalds/linux/commit/8b284dc47291daf72fe300e1138a2e7ed56f38ab
所以这个函数所在的commit是为了解决这样一个问题:
有的时候,当我们准备下刷一个脏页时,这个脏页的一份copy可能正在被回写中。
讲真我想不出到底是什么场景,不过never mind先不要在意这些细节。这会带来的问题就是,导致对相同偏移的两个并发的写请求,如果最终写请求混在一起的话数据就会被破坏。
接下来Miklos Szeredi解释了这一段代码的逻辑如何来解决这个问题,思路就是delay掉其中一个req:
- 针对某page,如果发现其copy正在under writeout,那么为其创建一个所谓secondary request,显然这个secondary request一定只会包含这一个page;
- 尝试把这个secondary request加入到旧有的request的misc->write->next链表中;如果链表中已经存在针对同一页的一个secondary request,那么用当前的新request的page内容去覆盖旧的request的内容,然后丢弃掉新的secondary request。这样就能保证针对每个page,同一时间肯定只会有两个request在under writeout;
- 当旧有的request被处理完毕后,依次发送后续的secondary requests即可;
这里面内藏玄机,比如: - fuse inode->writepages里面的所有request对象,numpages总是为1,就是说都肯定只包含一个page;虽然代码上看似乎它处理了单个request包含多个page的情况;
- 一簇request对象(也就是通过misc->write->next链起来的)的总数最大就是2,不会大于2;这两个request对象包含的是同一页;