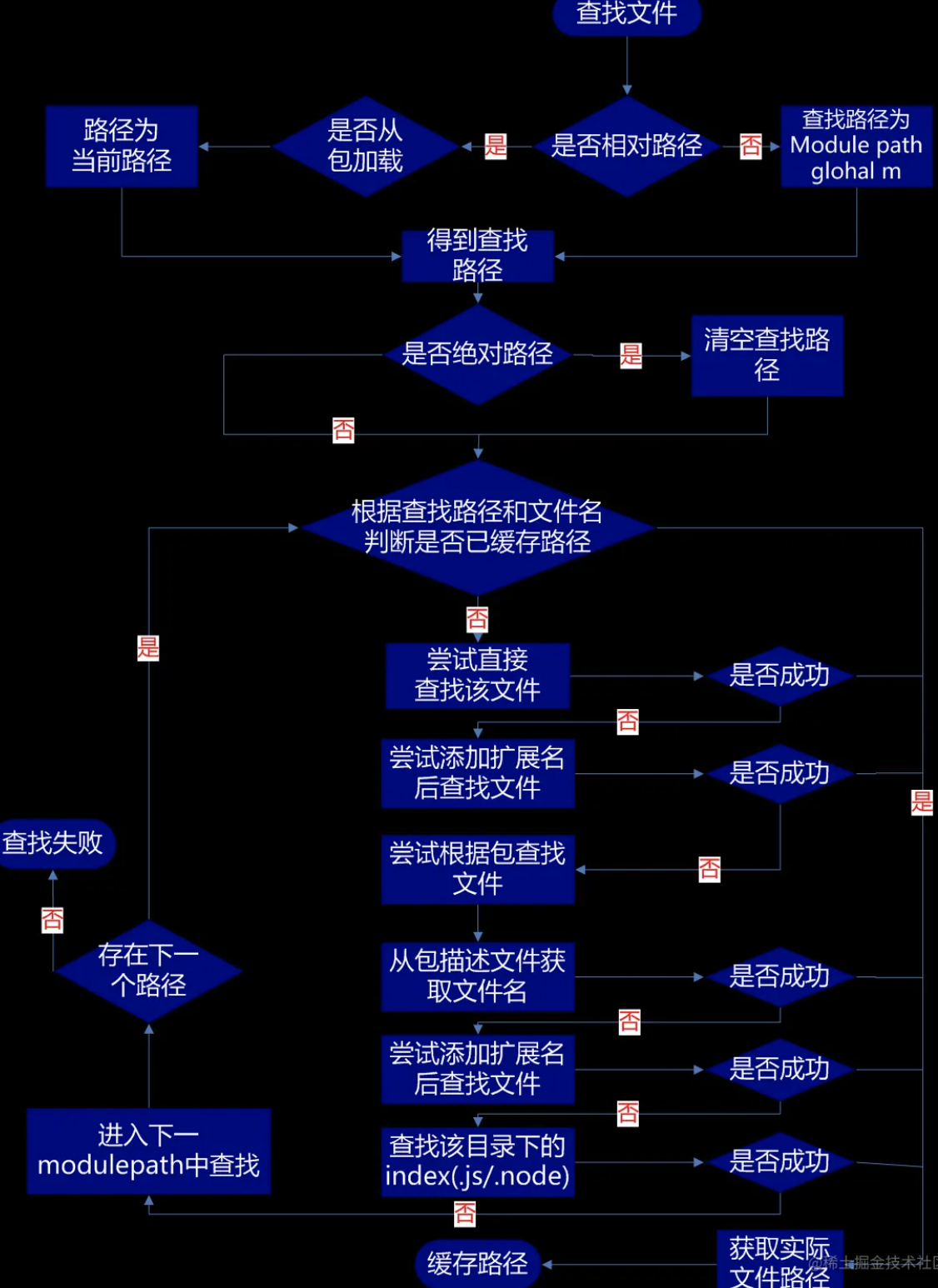
21 理解 Persistence Context 的核心概念
21.1 Persistence Context 相关核心概念
21.1.1 EntityManagerFactory 和 Persistence Unit
按照 JPA 协议⾥⾯的定义:persistence unit 是⼀些持久化配置的集合,⾥⾯包含了数据源的配置、EntityManagerFactory 的配置,spring 3.1 之前主要是通过 persistence.xml 的⽅式来配置⼀个 persistence unit。
⽽ spring 3.1 之后已经不再推荐这种⽅式了,但是还保留了 persistence unit 的概念,我们只需要在配置 LocalContainerEntityManagerFactory 的时候,指定 persistence unit 的名字即可。
请看下⾯代码,我们直接指定 persistenceUnit 的 name 即可。
@Bean(name = "slaveEntityManagerFactory")
public LocalContainerEntityManagerFactoryBean entityManagerFactory(EntityManagerFactoryBuilder builder,
@Qualifier("slaveDataSource") DataSource slaveDataSource) {
return builder.dataSource(slaveDataSource)
// slave 数据的实体所在的路径
.packages("com.zzn.slave")
// persistenceUnit 的名字采⽤ slave
.persistenceUnit("slave")
.build();
}
EntityManagerFactory 的⽤途就⽐较明显了,即根据不同的数据源,来管理 Entity 和创建 EntityManger,在整个 application 的⽣命周期中是单例状态。所以在 spring 的 application ⾥⾯获得 EntityManagerFactory 有两种⽅式。
第⼀种:通过 Spring 的 Bean 的⽅式注⼊。
@Autowired
@Qualifier(value="slaveEntityManagerFactory")
private EntityManagerFactory entityManagerFactory;
这种⽅式是我⽐较推荐的,它利⽤了 Spring ⾃身的 Bean 的管理机制。
第⼆种:利⽤ java.persistence.PersistenceUnit 注解的⽅式获取。
@PersistenceUnit("slave")
private EntityManagerFactory entityManagerFactory;
21.1.2 EntityManager 和 PersistenceContext
按照 JPA 协议的规范,我们先理解⼀下 PersistenceContext,它是⽤来管理会话⾥⾯的 Entity 状态的⼀个上下⽂环境,使 Entity 的实例有了不同的状态,也就是我们所说的实体实例的⽣命周期。
⽽这些实体在 PersistenceContext 中的不同状态都是通过 EntityManager 提供的⼀些⽅法进⾏管理的,也就是说:
- PersistenceContext 是持久化上下⽂,是 JPA 协议定义的,⽽ Hibernate 的实现是通过 Session 创建和销毁的,也就是说⼀个 Session 有且仅有⼀个 PersistenceContext;
- PersistenceContext 既然是持久化上下⽂,⾥⾯管理的是 Entity 的状态;
- EntityManager 是通过 PersistenceContext 创建的,⽤来管理 PersistenceContext 中 Entity 状态的⽅法,离开 PersistenceContext 持久化上下⽂,EntityManager 没有意义;
- EntityManger 是操作对象的唯⼀⼊⼝,⼀个请求⾥⾯可能会有多个 EntityManger 对象。
下⾯我们看⼀下 PersistenceContext 是怎么创建的。直接打开 SessionImpl 的构造⽅法,就可以知道 PersistenceContext 是和 Session 的⽣命周期绑定的,关键代码如下:
public SessionImpl(SessionFactoryImpl factory, SessionCreationOptions options) {
super( factory, options );
// Session ⾥⾯创建了 persistenceContext,每次 session 都是新对象
this.persistenceContext = createPersistenceContext();
this.actionQueue = createActionQueue();
// ... 其他我们暂不关⼼的代码我们可以先省略
}
// ... 其他我们暂不关⼼的代码我们可以先省略
protected StatefulPersistenceContext createPersistenceContext() {
return new StatefulPersistenceContext( this );
}
我们通过上⾯的讲述,知道了 PersistenceContext 的创建和销毁机制,那么 EntityManger 如何获得呢?需要通过 @PersistenceContext 的⽅式进⾏获取,代码如下:
@PersistenceContext
private EntityManager em;
⽽其中 @PersistenceContext 的属性配置有如下这些。
@Repeatable(PersistenceContexts.class)
@Target({TYPE, METHOD, FIELD})
@Retention(RUNTIME)
public @interface PersistenceContext {
/**
* 在引用上下文的环境中访问实体管理器的名称;使用依赖注入时不需要。
*/
String name() default "";
/**
* PersistenceContextUnit 的名字,多数据源的时候有⽤
*/
String unitName() default "";
/**
* 是指创建的 EntityManager 的⽣命周期是存在事务内还是可以跨事务,默认为⽣命周期和事务⼀样;
*/
PersistenceContextType type() default PersistenceContextType.TRANSACTION;
/**
* 同步的类型:只有 SYNCHRONIZED 和 UNSYNCHRONIZED 两个值⽤来表示,但开启事务的时候是否⾃动加⼊已开启的事务⾥⾯,默认 SYNCHRONIZED 表示⾃动加⼊,不创建新的事务。⽽ UNSYNCHRONIZED 表示,不⾃动加⼊上下⽂已经有的事务,⾃动开启新的事务;这⾥你使⽤的时候需要注意看⼀下事务的⽇志
*/
SynchronizationType synchronization() default SynchronizationType.SYNCHRONIZED;
/**
* 持久化的配置属性,hibernate 中 AvailableSettings ⾥⾯的值
*/
PersistenceProperty[] properties() default {};
}
⼀般情况下保持默认即可,你也可以根据实际情况⾃由组合,我再举个复杂点的例⼦。
@PersistenceContext(
unitName = "slave",// 采⽤ slave 数据源
// 可以跨事务的 EntityManager
type = PersistenceContextType.EXTENDED,
properties = {
// 通过 properties 改变⼀下⾃动 flush 的机制
@PersistenceProperty(
name="org.hibernate.flushMode",
value= "MANUAL" // 改成⼿动刷新⽅式
)
}
)
private EntityManager entityManager;
以上就是 Persistence Context 的相关基础概念。其中,实体的⽣命周期指的是什么呢?我们来了解⼀下。
21.2 实体对象的生命周期
既然 PersistenceContext 是存储 Entity 的,那么 Entity 在 PersistenceContext ⾥⾯肯定有不同的状态。对此,JPA 协议定义了四种状态:new、manager、detached、removed。我们通过⼀个图来整体认识⼀下。

21.2.1 第一种:New 状态
当我们使⽤关键字 new 的时候创建的实体对象,称为 new 状态的 Entity 对象。它需要同时满⾜两个条件:new 状态的实体 Id 和 Version 字段都是 null;new 状态的实体没有在PersistenceContext 中出现过。
那么如果我们要把 new 状态的 Entity 放到 PersistenceContext ⾥⾯,有两种⽅法:执⾏ entityManager.persist(entity) ⽅法;通过关联关系的实体关系配置 cascade=PERSIST or cascade=ALL 这种类型,并且关联关系的⼀⽅,也执⾏了 entityManager.persist(entity) ⽅法。
我们使⽤⼀个案例来说明⼀下。
@PersistenceContext
private EntityManager entityManager;
@Test
void testPersist() {
User user = User.builder().name("zzn").build();
// 通过 contains ⽅法可以验证对象是否在 PersistenceContext ⾥⾯,此时不在
Assertions.assertFalse(entityManager.contains(user));
//通过 persist ⽅法把对象放到 PersistenceContext ⾥⾯
entityManager.persist(user);
//通过 contains ⽅法可以验证对象是否在 PersistenceContext ⾥⾯,此时在
Assertions.assertTrue(entityManager.contains(user));
Assertions.assertNotNull(user.getId());
}
这就是 new 状态的实体对象,我们再来看⼀下和它类似的 Deteched 状态的对象。
21.2.2 第二种:Detached 状态
Detached 状态的对象表示和 PersistenceContext 脱离关系的 Entity 对象。它和 new 状态的对象的不同点在于:
- Detached 是 new 状态的实体对象,有 ID 和 version,但是还没有持久化 ID;
- 变成持久化对象需要进⾏ merger 操作,merger 操作会 copy ⼀个新的实体对象,然后把新的实体对象变成 Manager 状态。
⽽ Detached 和 new 状态的对象相同点也有两个⽅⾯:
- 都和 PersistenceContext 脱离了关系;
- 当执⾏ flush 操作或者 commit 操作的时候,不会进⾏数据库同步。
如果想让 Manager(persist) 状态的对象从 PersistenceContext ⾥⾯游离出来变成 Detached 的状态,可以通过 EntityManager 的 Detach ⽅法实现,如下⾯这⾏代码。
entityManager.detach(entity);
当执⾏完 entityManager.clear()、entityManager.close(),或者事务 commit()、事务 rollback() 之后,所有曾经在 PersistenceContext ⾥⾯的实体都会变成 Detached 状态。
⽽游离状态的对象想回到 PersistenceContext ⾥⾯变成 manager 状态的话,只能执⾏ entityManager 的 merge ⽅法,也就是下⾯这⾏代码。
entityManager.merge(entity);
游离状态的实体执⾏ EntityManager 中 persist ⽅法的时候就会报异常,我们举个例⼦:
@Test
void testMergeException() {
// 通过 new 的⽅式构建⼀个游离状态的对象
User user = User.builder().name("zzn").build();
user.setId(1L);
user.setVersion(1);
// 验证是否存在于 persistence context ⾥⾯,new 的肯定不存在
Assertions.assertFalse(entityManager.contains(user));
// 当执⾏ persist ⽅法的时候就会报异常
Assertions.assertThrows(PersistenceException.class,
() -> entityManager.persist(user));
// detached 状态的实体通过 merge 的⽅式保存在了 persistence context ⾥⾯
User user2 = entityManager.merge(user);
// 验证⼀下存在于持久化上下⽂⾥⾯
Assertions.assertTrue(entityManager.contains(user2));
}
以上就是 new 和 Detached 状态的实体对象,我们再来看第三种——Manager 状态的实体⼜是什么样的呢?
21.2.3 第三种:Managed 状态
Manager 状态的实体,顾名思义,是指在 PersistenceContext ⾥⾯管理的实体,⽽此种状态的实体当我们执⾏事务的 commit(),或者 entityManager 的 flush ⽅法的时候,就会进⾏数据库的同步操作。可以说是和数据库的数据有映射关系。
New 状态如果要变成 Manager 的状态,需要执⾏ persist ⽅法;⽽ Detached 状态的实体如果想变成 Manager 的状态,则需要执⾏ merge ⽅法。在 session 的⽣命周期中,任何从数据库⾥⾯查询到的 Entity 都会⾃动成为 Manager 的状态,如 entityManager.findById(id)、entityManager.getReference 等⽅法。
⽽ Manager 状态的 Entity 要同步到数据库⾥⾯,必须执⾏ EntityManager ⾥⾯的 flush ⽅法。也就是说我们对 Entity 对象做的任何增删改查,必须通过 entityManager.flush() 执⾏之后才会变成 SQL 同步到 DB ⾥⾯。什么意思呢?我们看个例⼦。
@Test
@Rollback(value = false)
void testManagerException() {
User user = User.builder().name("zzn").build();
entityManager.persist(user);
System.out.println("没有执⾏ flush() ⽅法,没有产⽣ insert sql");
entityManager.flush();
System.out.println("执⾏了 flush() ⽅法,产⽣ insert sql");
Assertions.assertTrue(entityManager.contains(user));
}
执⾏完之后,我们可以看到如下输出:
没有执⾏ flush() ⽅法,没有产⽣ insert sql
Hibernate: insert into user (create_user_id, created_date, deleted, last_modified_date, last_modified_user_id, version, age, email, name, sex, id) values (?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?)
执⾏了 flush() ⽅法,产⽣ insert sql
那么这个时候你可能会问了,并没有看到我们在之前写的 Repository 例⼦⾥⾯⼿动执⾏过任何 flush() 操作呀,那么请你带着这个问题继续往下看。了解下实体的第四个状态:Removed。
21.2.4 第四种:Removed 状态
Removed 的状态,顾名思义就是指删除了的实体,但是此实体还在 PersistenceContext ⾥⾯,只是在其中表示为 Removed 的状态,它和 Detached 状态的实体最主要的区别就是不在 PersistenceContext ⾥⾯,但都有 ID 属性。
⽽ Removed 状态的实体,当我们执⾏ entityManager.flush() ⽅法的时候,就会⽣成⼀条 delete 语句到数据库⾥⾯。Removed 状态的实体,在执⾏ flush() ⽅法之前,执⾏ entityManger.persist(removedEntity) ⽅法时候,就会去掉删除的表示,变成 Managed 的状态实例。我们还是看个例⼦。
@Test
void testDelete() {
User user = User.builder().name("zzn").build();
entityManager.persist(user);
entityManager.flush();
System.out.println("执⾏了 flush() ⽅法,产⽣了 insert sql");
entityManager.remove(user);
entityManager.flush();
Assertions.assertFalse(entityManager.contains(user));
System.out.println("执⾏了 flush() ⽅法之后,⼜产⽣了 delete sql");
}
执⾏完之后可以看到如下⽇志:
Hibernate: insert into user (create_user_id, created_date, deleted, last_modified_date, last_modified_user_id, version, age, email, name, sex, id) values (?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?)
执⾏了 flush() ⽅法,产⽣了 insert sql
delete from user where id=? and version=?
执⾏了 flush() ⽅法之后,⼜产⽣了 delete sql
到这⾥四种实体对象的状态就介绍完了,通过上⾯的详细解释,你知道了 Entity 的不同状态的时机是什么样的、不同状态直接的转化⽅式是什么样的,并且知道实体状态的任何变化都是在 Persistence Context 中进⾏的,和数据⼀点关系没有。
这仅仅是 JPA 和 Hibernate 为了提⾼⽅法执⾏的性能⽽设计的缓存实体机制,也是 JPA 和 MyBatis 的主要区别之处。
MyBatis 是对数据库的操作所⻅即所得的模式;⽽使⽤ JPA,你的任何操作都不会产⽣ DB 的 sql。那么什么时间才能进⾏ DB 的 sql 操作呢?我们看⼀下 flush 的实现机制。
21.3 解密 EntityManager 的 flush() 方法
flush ⽅法的⽤法很简单,就是我们在需要 DB 同步 sql 执⾏的时候,执⾏ entityManager.flush() 即可,它的作⽤如下所示。
21.3.1 Flush 的作用
flush 重要的、唯⼀的作⽤,就是将 Persistence Context 中变化的实体转化成 sql 语句,同步执⾏到数据库⾥⾯。换句话来说,如果我们不执⾏ flush() ⽅法的话,通过 EntityManager 操作的任何 Entity 过程都不会同步到数据库⾥⾯。
⽽ flush() ⽅法很多时候不需要我们⼿动操作,这⾥我直接通过 entityManager 操作 flush() ⽅法,仅仅是为了向你演示执⾏过程。实际⼯作中很少会这样操作,⽽是会直接利⽤ JPA 和 Hibernate 底层框架帮我们实现的⾃动 flush 的机制。
21.3.2 Flush 机制
JPA 协议规定了 EntityManager 可以通过如下⽅法修改 FlushMode。
// entity manager ⾥⾯提供的修改 FlushMode 的⽅法
public void setFlushMode(FlushModeType flushMode);
// FlushModeType 只有两个值,⾃动和事务提交之前
public enum FlushModeType {
// 事务 commit 之前
COMMIT,
// ⾃动规则,默认
AUTO
}
⽽ Hiberbernate 还提供了⼀种⼿动触发的机制,可以通过如下代码的⽅式进⾏修改。
@PersistenceContext(properties = {@PersistenceProperty(
name = "org.hibernate.flushMode",
value = "MANUAL" // ⼿动 flush
)})
private EntityManager entityManager;
⼿动和 commit 的时候很好理解,就是⼿动执⾏ flush ⽅法,像我们案例中的写法⼀样;事务就是代码在执⾏事务 commit 的时候,必须要执⾏ flush() ⽅法,否则怎么将 PersistenceContext 中变化了的对象同步到数据库⾥⾯呢?下⾯我重点说⼀下 flush 的⾃动机制。
默认情况下,JPA 和 Hibernate 都是采⽤的 AUTO 的 Flush 机制,⾃动触发的规则如下:
官方文档:https://docs.jboss.org/hibernate/orm/current/userguide/html_single/Hibernate_User_Guide.html#flushing-auto
By default, Hibernate uses the
AUTOflush mode which triggers a flush in the following circumstances:
prior to committing a
Transactionprior to executing a JPQL/HQL query that overlaps with the queued entity actions
before executing any native SQL query that has no registered synchronization
总结起来就是:
- 事务 commit 之前,即指执⾏ transactionManager.commit() 之前都会触发,这个很好理解;
- 执⾏任何的 JPQL 或者 native SQL(代替直接操作 Entity 的⽅法)都会触发 flush。这句话怎么理解呢?我们举个例⼦。
@Test
void testFlush() {
User user = User.builder().name("zzn").build();
// 通过 contains ⽅法可以验证对象是否在 PersistenceContext ⾥⾯,此时不在
Assertions.assertFalse(entityManager.contains(user));
//通过 persist ⽅法把对象放到 PersistenceContext ⾥⾯
entityManager.persist(user);// 是直接操作 Entity 的,不会触发 flush 操作
// entityManager.remove(userInfo);// 是直接操作Entity的,不会触发 flush 操作
System.out.println("没有执⾏ flush() ⽅法,不会产⽣ insert sql");
// 是直接操作 Entity 的,这个就不会触发 flush 操作
User user2 = entityManager.find(User.class, 1L);
// 是操作 JPQL 的,这个就会先触发 flush 操作;
// userRepository.findByQuery("zzn");
System.out.println("flush() ⽅法,产⽣ insert sql");
//通过 contains ⽅法可以验证对象是否在 PersistenceContext ⾥⾯,此时在
Assertions.assertTrue(entityManager.contains(user));
Assertions.assertNotNull(user.getId());
}
⽽只有执⾏类似 findByQuery() 这个⽅法的时候,才会触发 flush,因为它是⽤的 JPQL 的机制执⾏的。
我们了解完了 flush 的⾃动触发机制还不够,因为 flush 的⾃动刷新机制还会改变 update、insert、delete 的执⾏顺序。
21.3.3 Flush 会改变 SQL 的执行顺序
flush() ⽅法调⽤之后,同⼀个事务内,sql 的执⾏顺序会变成如下模式:insert 的先执⾏、update 的第⼆个执⾏、delete 的第三个执⾏。我们举个例⼦,⽅法如下:
@Test
void testExecuteOrder() {
// given 初始化数据
User user1 = User.builder().name("user1").build();
User user2 = User.builder().name("user2").build();
entityManager.persist(user1);
entityManager.persist(user2);
entityManager.flush();
// when 执行删除,更新,插入,观察执行顺序
entityManager.remove(user2); // 删除
user1.setName("update");
entityManager.merge(user1); // 更新
entityManager.persist(User.builder().name("insert").build()); // 插入
// 执行 flush
entityManager.flush();
}
看⼀下执⾏的 sql 会变成如下模样,即先 insert 后 update,再 delete。
Hibernate: insert into user (create_user_id, created_date, deleted, last_modified_date, last_modified_user_id, version, age, email, name, sex, id) values (?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?)
Hibernate: update user set create_user_id=?, created_date=?, deleted=?, last_modified_date=?, last_modified_user_id=?, version=?, age=?, email=?, name=?, sex=? where id=? and version=?
Hibernate: delete from user where id=? and version=?
这种会改变顺序的现象,主要是由 persistence context 的实体状态机制导致的,所以在 Hibernate 的环境中,顺序会变成如下的 ActionQueue 的模式:
org.hibernate.engine.spi.ActionQueue#EXECUTABLE_LISTS_MAP
- OrphanRemovalAction
- EntityInsertAction or EntityIdentityInsertAction 插入
- EntityUpdateAction 更新
- CollectionRemoveAction 集合删除
- CollectionUpdateAction 集合更新
- CollectionRecreateAction
- EntityDeleteAction 实体删除
flush 的作⽤你已经知道了,它会把 sql 同步执⾏到数据库⾥⾯。但是需要注意的是,虽然 sql 到数据库⾥⾯执⾏了,那么最终数据是不是持久化,是不是被其他事务看到还会受到控制呢?Flush 与事务 Commit 的关系如何?
21.3.4 Flush 与事务提交的关系
⼤概有以下⼏点:
- 在当前的事务执⾏ commit 的时候,会触发 flush ⽅法;
- 在当前的事务执⾏完 commit 的时候,如果隔离级别是可重复读的话,flush 之后执⾏的 update、insert、delete 的操作,会被其他的新事务看到最新结果;
- 假设当前的事务是可重复读的,当我们⼿动执⾏ flush ⽅法之后,没有执⾏事务 commit ⽅法,那么其他事务是看不到最新值变化的,但是最新值变化对当前没有 commit 的事务是有效的;
- 如果执⾏了 flush 之后,当前事务发⽣了 rollback 操作,那么数据将会被回滚(数据库的机制)。
以上介绍的都是 flush 的机制,那么 SimpleJpaRepository ⾥⾯的 saveAndFlush 有什么作⽤呢?
21.3.5 saveAndFlush 和 save 的区别
细⼼的同学会发现 SimpleJpaRepository ⾥⾯有⼀个 saveAndFlush(entity); 的⽅法,我们通过查看可以发现如下内容:
@Transactional
@Override
public <S extends T> S saveAndFlush(S entity) {
// 执⾏了 save ⽅法之后,调⽤了 flush() ⽅法
S result = this.save(entity);
this.flush();
return result;
}
⽽⾥⾯的 save 的⽅法,我们查看其源码如下:
@Transactional
@Override
public <S extends T> S save(S entity) {
Assert.notNull(entity, "Entity must not be null.");
// 没有做 flush 操作,只是,执⾏了 persist 或者 merge 的操作
if (this.entityInformation.isNew(entity)) {
this.em.persist(entity);
return entity;
} else {
return this.em.merge(entity);
}
}
所以这个时候我们应该很清楚 Repository ⾥⾯提供的 saveAndFlush 和 save 的区别,有如下⼏点:
- saveAndFlush 执⾏完,再执⾏ flush,会刷新整个 PersistenceContext ⾥⾯的实体并进⼊到数据库⾥⾯,那么当我们频繁调⽤ saveAndFlush 就失去了 cache 的意义,这个时候就和执⾏ mybatis 的 saveOrUpdate 是⼀样的效果;
- 当多次调⽤相同的 save ⽅法的时候,最终 flush 执⾏只会产⽣⼀条 sql,在性能上会⽐ saveAndFlush ⾼⼀点;
- 不管是 saveAndFlush 还是 save,都受当前事务控制,事务在没有 commit 之前,都只会影响当前事务的操作;
综上,两种本质的区别就是 flush 执⾏的时机不⼀样⽽已,对数据库中数据的事务⼀致性没有任何影响。然⽽有的时候,即使我们调⽤了 flush 的⽅法也是⼀条 sql 都没有,为什么呢?我们再来了解⼀个概念:Dirty。
21.4 Dirty 判断逻辑及其作用
在 PersistenceContext ⾥⾯还有⼀个重要概念,就是当实体不是 Dirty 状态,也就是没有任何变化的时候,是不会进⾏任何 db 操作的。所以即使我们执⾏ flush 和 commit,实体没有变化,就没有必要执⾏,这也能⼤⼤减少数据库的压⼒。
下⾯通过⼀个例⼦,认识⼀下 Dirty 的效果。
21.4.1 Dirty 效果的例子
@Test
@Transactional(propagation = Propagation.REQUIRES_NEW)
@Rollback(value = false)
void testDirty() {
// 我们假设数据库⾥⾯存在⼀条 id=1 的数据,我们不做任何改变执⾏ save 或者 saveAndFlush,除了 select 之外,不会产⽣任何 sql 语句;
User user = userRepository.findById(23L).orElse(null);
Assertions.assertNotNull(user);
log.info("user: {}", JacksonUtil.toString(user));
userRepository.saveAndFlush(user);
userRepository.save(user);
}
21.4.2 Entity 判断 Dirty 的过程
如果我们通过 debug ⼀步⼀步分析的话可以找到,DefaultFlushEntityEventListener 的源码⾥⾯ isUpdateNecessary 的关键⽅法如下所示:
org.hibernate.event.internal.DefaultFlushEntityEventListener#isUpdateNecessary(org.hibernate.event.spi.FlushEntityEvent, boolean)

我们进⼀步 debug 看 dirtyCheck 的实现,可以看发现如下关键点,从⽽找出发⽣变化的 proerties。

我们再仔细看 persister.findDirty(values, loadedState, entity, session),可以看出来源码⾥⾯是通过⼀个字段⼀个字段⽐较的,所以可以知道 PsersistenceContext 中的前后两个 Entity 的哪些字段发⽣了变化。因此当我们执⾏完 save 之后,没有产⽣任何 sql(因为没有变化)。你知道了这个原理之后,就不⽤再为此“⼤惊⼩怪”了。
总结起来就是,在 flush 的时候,Hibernate 会⼀个个判断实体的前后对象中哪个属性发⽣变化了,如果没有发⽣变化,则不产⽣ update 的 sql 语句;只有变化才会才⽣ update sql,并且可以做到同⼀个事务⾥⾯的多次 update 合并,从⽽在⼀定程度上可以减轻 DB 的压⼒。
21.5 本章小结
这⼀讲我为你介绍了 PersistenceContext 的概念、EntityManager 的作⽤,以及 flush 操作是什么时机进⾏的,它和事务的关系如何。如果你能完全理解这⼀讲的内容,那么对于 JPA 和 Hibernate 的核⼼原理你算是掌握⼀⼤半了







![[2]MyBatis+Spring+SpringMVC+SSM整合一套通关](https://img-blog.csdnimg.cn/8292acd91dab45c39860de2a3ceaddf6.png#pic_center)