目录
- 1、数仓
- 数据仓库主流开发语言--SQL
- 2、Apache Hive入门
- 2.1 hive定义
- 2.2 为什么使用Hive
- 2.3 Hive和Hadoop关系
- 2.4 场景设计:如何模拟实现Hive功能
- 2.5 Apache Hive架构、组件
- 3、Apache Hive安装部署
- 3.1 metastore配置方式
- 4、Hive SQL语言:DDL建库、建表
- 4.1 数据库与建库
- 4.2 表与建表
- 4.2.1 数据类型
- 4.2.2 分隔符指定语法
- 4.2.3 案例:结构化文件映射成表
- 4.3 Hive Show语法
- 4.4 注释comment中文乱码问题解决
1、数仓
数据仓库(英语:Data Warehouse,简称数仓、DW),是一个用于存储、分析、报告的数据系统。
数据仓库的目的是构建面向分析的集成化数据环境,分析结果为企业提供决策支持
- 数据仓库本身并不“生产”任何数据,也不需要“消费”任何的数据
- 数仓为了分析数据而来
- 业务数据存储在联机事务处理系统(OLTP)中,前台接收数据后,快速给出处理结果
关系型数据库(RDBMS)是OLTP典型应用,比如:Oracle、MySQL、SQL Server等。 - ,数仓是一个用于存储、分析、报告的数据系统,目的是构建面向分析的集成化数据环境。我们把这种面向分析、支持分析的系统称之为OLAP(联机分析处理)系统
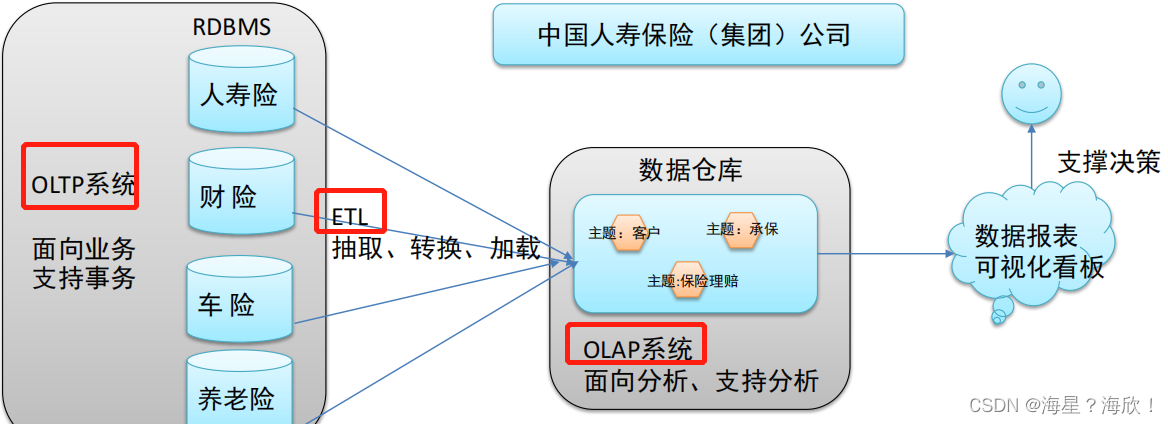
数仓主要特征:面向主题、集成性、非易失性、时变性
数据仓库主流开发语言–SQL
结构化查询语言(Structured Query Language)简称SQL,是一种数据库查询和程序设计语言,用于存取数据以及查询、更新和管理数据
SQL应用广泛原因:学习成本低,对数据分析友好
结构化数据也称作行数据,是由二维表结构来逻辑表达和实现的数据
非结构化数据,包括所有格式的办公文档、XML、HTML、各类报表、图片和音频、视频信息等。
SQL主要语法分为两个部分:数据定义语言 (DDL)和数据操纵语言 (DML) 。
- DDL语法使我们有能力创建或删除表,以及数据库、索引等各种对象,但是不涉及表中具体数据操作:
CREATE DATABASE - 创建新数据库
CREATE TABLE - 创建新表 - DML语法是我们有能力针对表中的数据进行插入、更新、删除、查询操作:
SELECT - 从数据库表中获取数据
UPDATE - 更新数据库表中的数据
DELETE - 从数据库表中删除数据
INSERT - 向数据库表中插入数据
2、Apache Hive入门
2.1 hive定义
Apache Hive是一款建立在Hadoop之上的开源数据仓库系统,可以将存储在Hadoop文件中的结构化、半结构化数据文件映射为一张数据库表,基于表提供了一种类似SQL的查询模型,称为Hive查询语言(HQL),用于访问和分析存储在Hadoop文件中的大型数据集。
Hive核心是将HQL转换为MapReduce程序,然后将程序提交到Hadoop群集执行
2.2 为什么使用Hive
使用Hadoop MapReduce直接处理数据所面临的问题:
- 人员学习成本太高 需要掌握java语言
- MapReduce实现复杂查询逻辑开发难度太大
使用Hive处理数据的好处:
- 操作接口采用类SQL语法,提供快速开发的能力(简单、容易上手)
- 避免直接写MapReduce,减少开发人员的学习成本
- 支持自定义函数,功能扩展很方便
- 背靠Hadoop,擅长存储分析海量数据集
2.3 Hive和Hadoop关系
从功能来说,数据仓库软件,至少需要具备下述两种能力:
存储数据的能力、分析数据的能力
Apache Hive作为一款大数据时代的数据仓库软件,当然也具备上述两种能力。只不过Hive并不是自己实现了上述两种能力,而是借助Hadoop。
Hive利用HDFS存储数据,利用MapReduce查询分析数据。
这样突然发现Hive没啥用,不过是套壳Hadoop罢了。其实不然,Hive的最大的魅力在于用户专注于编写HQL,Hive帮您转换成为MapReduce程序完成对数据的分析
hive可以理解为sql on hadoop
2.4 场景设计:如何模拟实现Hive功能
Hive能将数据文件映射成为一张表,这个映射是指什么?
文件和表之间的对应关系
Hive软件本身到底承担了什么功能职责?
SQL语法解析编译成MapReduce
在hive中能够写sql处理的前提是针对表,而不是针对文件,因此需要将文件和表之间的对应关系描述记录清楚。
映射信息专业的叫法称之为元数据信息(元数据是指用来描述数据的数据 metadata)。
元数据信息应该包括:
- 表对应着哪个文件(位置信息)
- 表的列对应着文件哪一个字段(顺序信息)
- 文件字段之间的分隔符是什么
用户写完sql之后,hive需要针对sql进行语法校验,并且根据记录的元数据信息解读sql背后的含义,制定执行计划
并且把执行计划转换成MapReduce程序来具体执行,把执行的结果封装返回给用户。
基于上面分析,hive架构图应该如下:
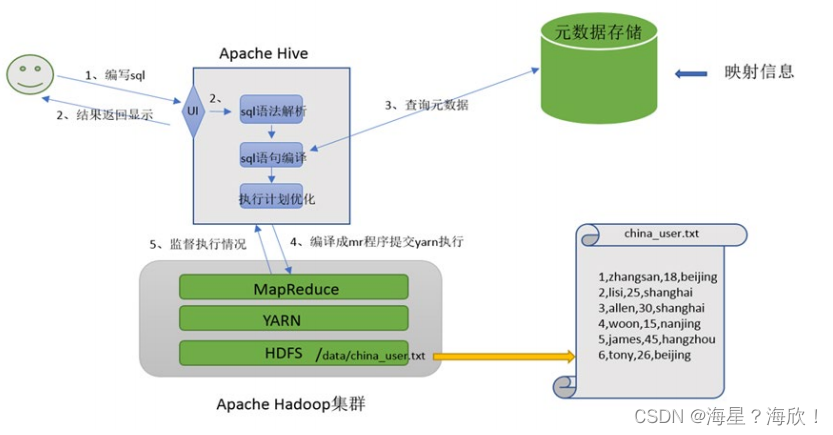
2.5 Apache Hive架构、组件
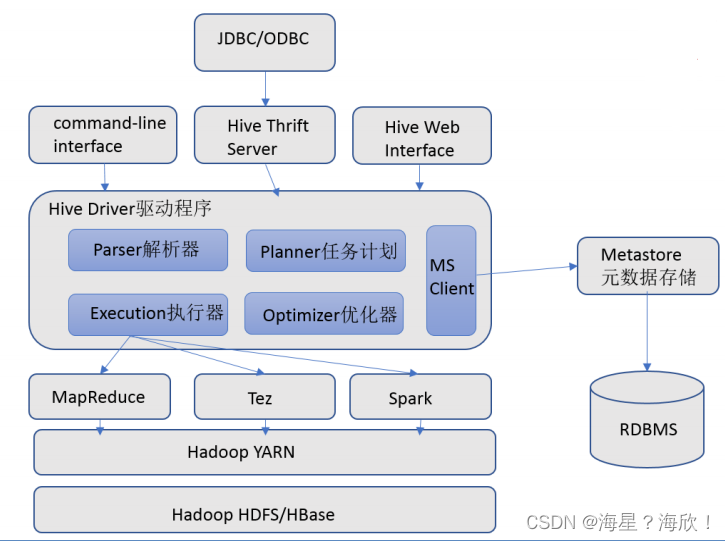
Hive组件:
-
用户接口:包括 CLI、JDBC/ODBC、WebGUI。其中,CLI(command line interface)为shell命令行;Hive中的Thrift服务器允许外部客户端通过网络与Hive进行交互,类似于JDBC或ODBC协议。WebGUI是通过浏览器访问Hive。
-
元数据存储:通常是存储在关系数据库如 mysql/derby中。Hive 中的元数据包括表的名字,表的列和分区及其属性,表的属性(是否为外部表等),表的数据所在目录等
我们分析的表数据在HDFS上,而元数据是存储在MySQL上的 -
Driver驱动程序,包括语法解析器、计划编译器、优化器、执行器
完成 HQL 查询语句从词法分析、语法分析、编译、优化以及查询计划的生成。生成的查询计划存储在 HDFS 中,并在随后有执行引擎调用执行 -
执行引擎
Hive本身并不直接处理数据文件。而是通过执行引擎处理。当下Hive支持MapReduce、Tez、Spark3种执行引擎。
3、Apache Hive安装部署
Metadata元数据:描述数据的数据
元数据存储在关系型数据库中,如hive内置的Derby、或者第三方如MySQL等
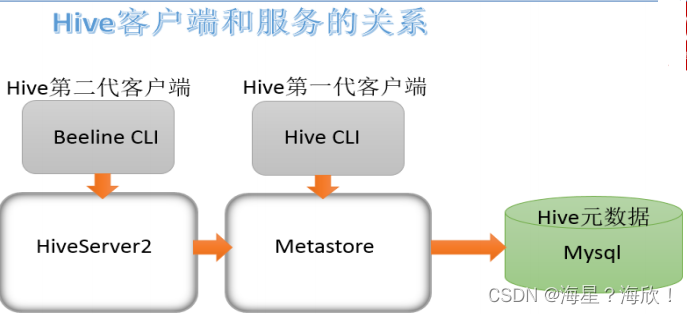
Metastore即元数据服务。Metastore服务的作用是管理metadata元数据,对外暴露服务地址,让各种客户端通过连接metastore服务,由metastore再去连接MySQL数据库来存取元数据
有了metastore服务,就可以有多个客户端同时连接,而且这些客户端不需要知道MySQL数据库的用户名和密码,只需要连接metastore 服务即可。某种程度上也保证了hive元数据的安全
使用Metastore原因 :保证元数据的安全
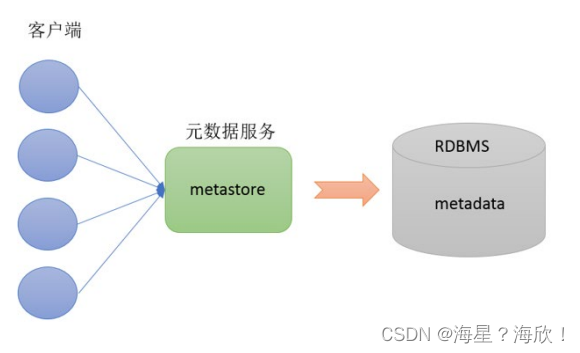
3.1 metastore配置方式
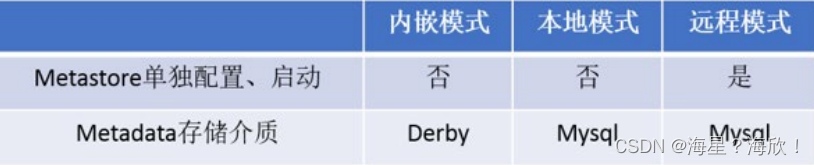
metastore服务配置有3种模式:内嵌模式、本地模式、远程模式。
区分3种配置方式的关键是弄清楚两个问题:
- Metastore服务是否需要单独配置、单独启动?
- Metadata是存储在内置的derby中,还是第三方RDBMS,比如MySQL。
- 企业推荐模式–远程模式部署
4、Hive SQL语言:DDL建库、建表
4.1 数据库与建库
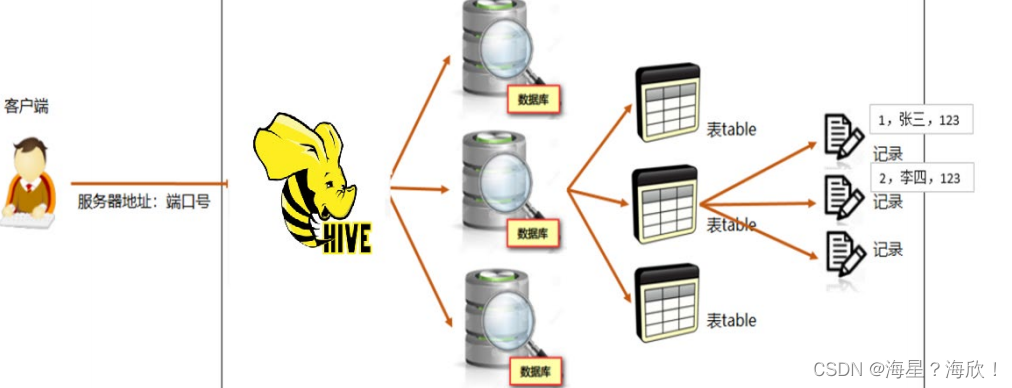
数据在表中,表在库中
数据定义语言 (Data Definition Language, DDL),是SQL语言集中对数据库内部的对象结构进行创建,删除,修改等的操作语言,这些数据库对象包括database、table等
DDL核心语法由CREATE、ALTER与DROP三个所组成。DDL并不涉及表内部数据的操作。
HQL中create语法(尤其create table)将是学习掌握Hive DDL语法的重中之重。
建表是否成功直接影响数据文件是否映射成功,进而影响后续是否可以基于SQL分析数据
create database:
create database用于创建新的数据库
COMMENT:数据库的注释说明语句
LOCATION:指定数据库在HDFS存储位置,默认/user/hive/warehouse/dbname.db
WITH DBPROPERTIES:用于指定一些数据库的属性配置。
node1中:
create database ithei
可以回到node1:9870中Hadoop的/user/hive/warehouse/中找到ithei.db文件
use database
选择特定的数据库,切换当前会话使用哪一个数据库进行操作
drop database
删除数据库
默认行为是RESTRICT,这意味着仅在数据库为空时才删除它。
要删除带有表的数据库(不为空的数据库),我们可以使用CASCADE
#删除库itca ,itca库下没有表可以直接删除
drop database itca
4.2 表与建表
CREATE TABLE [IF NOT EXISTS] [db_name.]table_name
(col_name data_type [COMMENT col_comment], … )
[COMMENT table_comment]
[ROW FORMAT DELIMITED …];
create table [if not exists] [库名.]表名 (列名 数据类型 [comment "注释内容"],...)
[row format delimited
fields terminated by "\t"];
4.2.1 数据类型
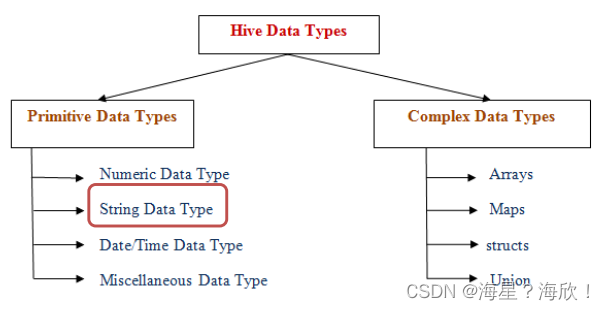
Hive数据类型指的是表中列的字段类型;
- 整体分为两类:原生数据类型(primitive data type)和复杂数据类型(complex data type)。
- 最常用的数据类型是字符串String和数字类型Int。
4.2.2 分隔符指定语法
ROW FORMAT DELIMITED语法用于指定字段之间等相关的分隔符,这样Hive才能正确的读取解析数据。
LazySimpleSerDe是Hive默认的,包含4种子语法,分别用于指定字段之间、集合元素之间、map映射 kv之间、换行的分隔符号

4.2.3 案例:结构化文件映射成表
文件archer.txt:

datagrip中写sql
数值类型int
字符串类型string
--1、创建一张表,将文件archer.txt映射成功
-- 表名
-- 字段、名称、类型、顺序
-- 字段之间的分隔符
create table ithei.t_archer(
id int comment "ID编号",
name string comment "英雄名称",
hp_max int comment "最大生命",
mp_max int comment "最大法力",
attack_max int comment "最高物攻",
defense_max int comment "最大物防",
attack_range string comment "攻击范围",
role_main string comment "主要定位",
role_assist string comment "次要定位"
)
row format delimited
fields terminated by "\t"; --字段之间的分隔符是tab键 制表符
在datagrip中可以直接连接
可以在hdfs网页上上传文件数据,也可以node上上传:
cd ~
mkdir hivedata
cd hivedata/
hadoop fs -put archer.txt /user/hive/warehouse/itheima.db/t_archer
select * from t_archer;#可以显示出上传的表数据
- Hive建表时如果没有row format语法指定分隔符,则采用默认分隔符;
- 默认的分割符是’\001’,是一种特殊的字符,使用的是ASCII编码的值,在文本中显示SOH,在vim编辑中显示^A
4.3 Hive Show语法
1,显示所有数据库
SCHEMAS和DATABASES的用法 功能一样
show databases;
show schemas;
2,显示当前数据库下所有表
show tables;
show tables [in 库名] --指定某个数据库
3,显示一张表的元数据信息
desc formatted 表名;
--会显示字段名,类型,注释等等信息
4.4 注释comment中文乱码问题解决
mysql默认编码不支持中文,支持的是latin1编码。如果中文注释出现???的乱码格式。下面方法解决:
node上:
mysql -u root -p 回车,输入密码
进入MySQL
show databases;
use hive3;
show tables;
在MySQL中复制下面的代码进去执行。ctrl +d结束
alter table hive3.COLUMNS_V2 modify column COMMENT varchar(256) character set utf8;
alter table hive3.TABLE_PARAMS modify column PARAM_VALUE varchar(4000) character set utf8;
alter table hive3.PARTITION_PARAMS modify column PARAM_VALUE varchar(4000) character set utf8 ;
alter table hive3.PARTITION_KEYS modify column PKEY_COMMENT varchar(4000) character set utf8;
alter table hive3.INDEX_PARAMS modify column PARAM_VALUE varchar(4000) character set utf8;
此时改好了编码,但是已经创建的表中文还是错误,需要删除表后再创建即可
drop table 表名; #删除
create table 表名(..) #载创建即可