实现一个call
call做了什么:
- 将函数设为对象的属性
- 执行&删除这个函数
- 指定this到函数并传入给定参数执行函数
- 如果不传入参数,默认指向为 window
// 模拟 call bar.mycall(null);
//实现一个call方法:
Function.prototype.myCall = function(context) {
//此处没有考虑context非object情况
context.fn = this;
let args = [];
for (let i = 1, len = arguments.length; i < len; i++) {
args.push(arguments[i]);
}
context.fn(...args);
let result = context.fn(...args);
delete context.fn;
return result;
};
手写常见排序
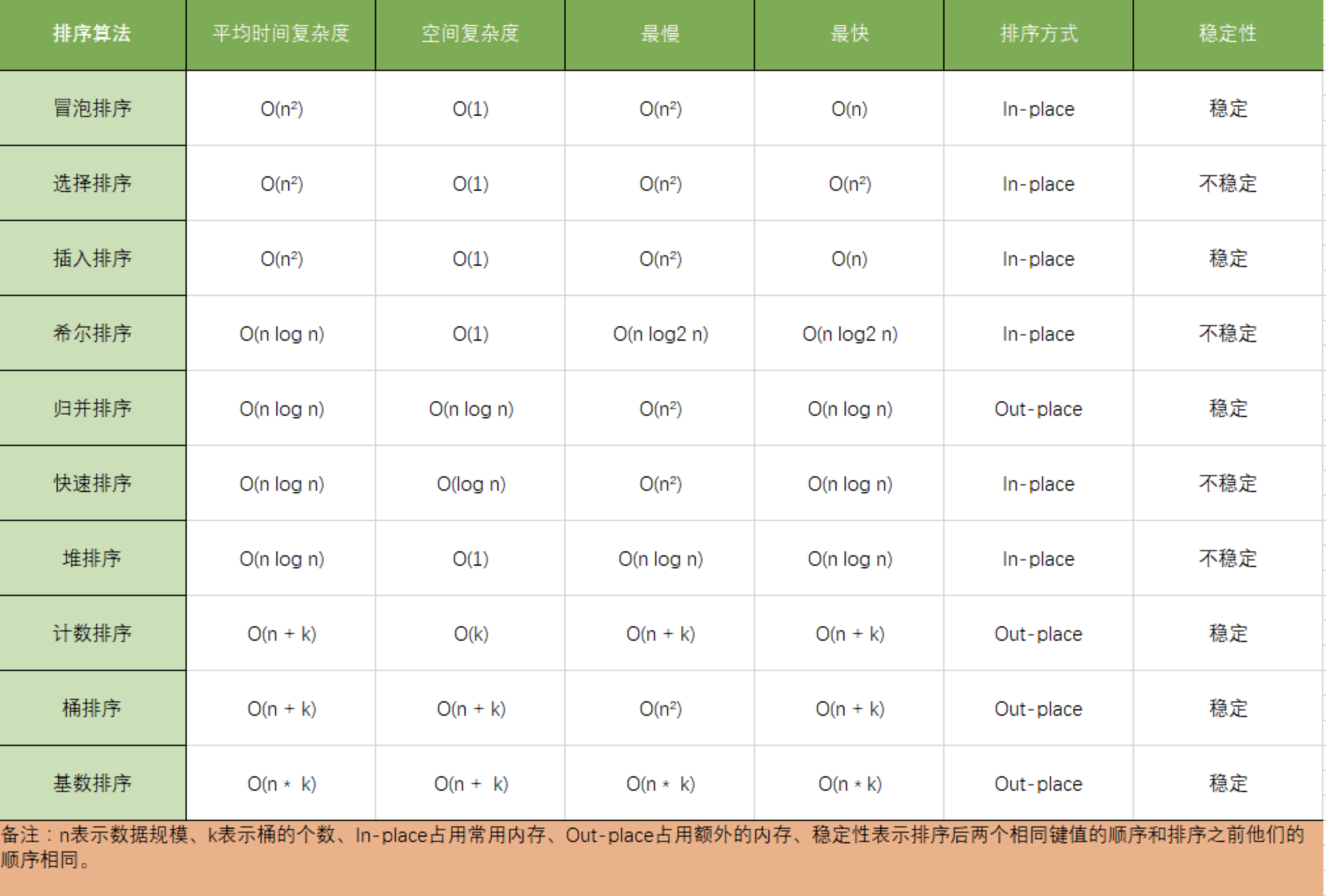
冒泡排序
冒泡排序的原理如下,从第一个元素开始,把当前元素和下一个索引元素进行比较。如果当前元素大,那么就交换位置,重复操作直到比较到最后一个元素,那么此时最后一个元素就是该数组中最大的数。下一轮重复以上操作,但是此时最后一个元素已经是最大数了,所以不需要再比较最后一个元素,只需要比较到
length - 1的位置。
function bubbleSort(list) {
var n = list.length;
if (!n) return [];
for (var i = 0; i < n; i++) {
// 注意这里需要 n - i - 1
for (var j = 0; j < n - i - 1; j++) {
if (list[j] > list[j + 1]) {
var temp = list[j + 1];
list[j + 1] = list[j];
list[j] = temp;
}
}
}
return list;
}
快速排序
快排的原理如下。随机选取一个数组中的值作为基准值,从左至右取值与基准值对比大小。比基准值小的放数组左边,大的放右边,对比完成后将基准值和第一个比基准值大的值交换位置。然后将数组以基准值的位置分为两部分,继续递归以上操作
ffunction quickSort(arr) {
if (arr.length<=1){
return arr;
}
var baseIndex = Math.floor(arr.length/2);//向下取整,选取基准点
var base = arr.splice(baseIndex,1)[0];//取出基准点的值,
// splice 通过删除或替换现有元素或者原地添加新的元素来修改数组,并以数组形式返回被修改的内容。此方法会改变原数组。
// slice方法返回一个新的数组对象,不会更改原数组
//这里不能直接base=arr[baseIndex],因为base代表的每次都删除的那个数
var left=[];
var right=[];
for (var i = 0; i<arr.length; i++){
// 这里的length是变化的,因为splice会改变原数组。
if (arr[i] < base){
left.push(arr[i]);//比基准点小的放在左边数组,
}
}else{
right.push(arr[i]);//比基准点大的放在右边数组,
}
return quickSort(left).concat([base],quickSort(right));
}
选择排序
function selectSort(arr) {
// 缓存数组长度
const len = arr.length;
// 定义 minIndex,缓存当前区间最小值的索引,注意是索引
let minIndex;
// i 是当前排序区间的起点
for (let i = 0; i < len - 1; i++) {
// 初始化 minIndex 为当前区间第一个元素
minIndex = i;
// i、j分别定义当前区间的上下界,i是左边界,j是右边界
for (let j = i; j < len; j++) {
// 若 j 处的数据项比当前最小值还要小,则更新最小值索引为 j
if (arr[j] < arr[minIndex]) {
minIndex = j;
}
}
// 如果 minIndex 对应元素不是目前的头部元素,则交换两者
if (minIndex !== i) {
[arr[i], arr[minIndex]] = [arr[minIndex], arr[i]];
}
}
return arr;
}
// console.log(selectSort([3, 6, 2, 4, 1]));
插入排序
function insertSort(arr) {
for (let i = 1; i < arr.length; i++) {
let j = i;
let target = arr[j];
while (j > 0 && arr[j - 1] > target) {
arr[j] = arr[j - 1];
j--;
}
arr[j] = target;
}
return arr;
}
// console.log(insertSort([3, 6, 2, 4, 1]));
实现一个JS函数柯里化
预先处理的思想,利用闭包的机制
- 柯里化的定义:接收一部分参数,返回一个函数接收剩余参数,接收足够参数后,执行原函数
- 函数柯里化的主要作用和特点就是
参数复用、提前返回和延迟执行
- 柯里化把多次传入的参数合并,柯里化是一个高阶函数
- 每次都返回一个新函数
- 每次入参都是一个
当柯里化函数接收到足够参数后,就会执行原函数,如何去确定何时达到足够的参数呢?
有两种思路:
- 通过函数的
length属性,获取函数的形参个数,形参的个数就是所需的参数个数 - 在调用柯里化工具函数时,手动指定所需的参数个数
将这两点结合一下,实现一个简单 curry 函数
通用版
// 写法1
function curry(fn, args) {
var length = fn.length;
var args = args || [];
return function(){
newArgs = args.concat(Array.prototype.slice.call(arguments));
if (newArgs.length < length) {
return curry.call(this,fn,newArgs);
}else{
return fn.apply(this,newArgs);
}
}
}
// 写法2
// 分批传入参数
// redux 源码的compose也是用了类似柯里化的操作
const curry = (fn, arr = []) => {// arr就是我们要收集每次调用时传入的参数
let len = fn.length; // 函数的长度,就是参数的个数
return function(...args) {
let newArgs = [...arr, ...args] // 收集每次传入的参数
// 如果传入的参数个数等于我们指定的函数参数个数,就执行指定的真正函数
if(newArgs.length === len) {
return fn(...newArgs)
} else {
// 递归收集参数
return curry(fn, newArgs)
}
}
}
// 测试
function multiFn(a, b, c) {
return a * b * c;
}
var multi = curry(multiFn);
multi(2)(3)(4);
multi(2,3,4);
multi(2)(3,4);
multi(2,3)(4)
ES6写法
const curry = (fn, arr = []) => (...args) => (
arg => arg.length === fn.length
? fn(...arg)
: curry(fn, arg)
)([...arr, ...args])
// 测试
let curryTest=curry((a,b,c,d)=>a+b+c+d)
curryTest(1,2,3)(4) //返回10
curryTest(1,2)(4)(3) //返回10
curryTest(1,2)(3,4) //返回10
// 柯里化求值
// 指定的函数
function sum(a,b,c,d,e) {
return a + b + c + d + e
}
// 传入指定的函数,执行一次
let newSum = curry(sum)
// 柯里化 每次入参都是一个参数
newSum(1)(2)(3)(4)(5)
// 偏函数
newSum(1)(2)(3,4,5)
// 柯里化简单应用
// 判断类型,参数多少个,就执行多少次收集
function isType(type, val) {
return Object.prototype.toString.call(val) === `[object ${type}]`
}
let newType = curry(isType)
// 相当于把函数参数一个个传了,把第一次先缓存起来
let isString = newType('String')
let isNumber = newType('Number')
isString('hello world')
isNumber(999)
实现bind方法
bind的实现对比其他两个函数略微地复杂了一点,涉及到参数合并(类似函数柯里化),因为bind需要返回一个函数,需要判断一些边界问题,以下是bind的实现
bind返回了一个函数,对于函数来说有两种方式调用,一种是直接调用,一种是通过new的方式,我们先来说直接调用的方式- 对于直接调用来说,这里选择了
apply的方式实现,但是对于参数需要注意以下情况:因为bind可以实现类似这样的代码f.bind(obj, 1)(2),所以我们需要将两边的参数拼接起来 - 最后来说通过
new的方式,对于new的情况来说,不会被任何方式改变this,所以对于这种情况我们需要忽略传入的this
简洁版本
- 对于普通函数,绑定
this指向 - 对于构造函数,要保证原函数的原型对象上的属性不能丢失
Function.prototype.myBind = function(context = window, ...args) {
// this表示调用bind的函数
let self = this;
//返回了一个函数,...innerArgs为实际调用时传入的参数
let fBound = function(...innerArgs) {
//this instanceof fBound为true表示构造函数的情况。如new func.bind(obj)
// 当作为构造函数时,this 指向实例,此时 this instanceof fBound 结果为 true,可以让实例获得来自绑定函数的值
// 当作为普通函数时,this 指向 window,此时结果为 false,将绑定函数的 this 指向 context
return self.apply(
this instanceof fBound ? this : context,
args.concat(innerArgs)
);
}
// 如果绑定的是构造函数,那么需要继承构造函数原型属性和方法:保证原函数的原型对象上的属性不丢失
// 实现继承的方式: 使用Object.create
fBound.prototype = Object.create(this.prototype);
return fBound;
}
// 测试用例
function Person(name, age) {
console.log('Person name:', name);
console.log('Person age:', age);
console.log('Person this:', this); // 构造函数this指向实例对象
}
// 构造函数原型的方法
Person.prototype.say = function() {
console.log('person say');
}
// 普通函数
function normalFun(name, age) {
console.log('普通函数 name:', name);
console.log('普通函数 age:', age);
console.log('普通函数 this:', this); // 普通函数this指向绑定bind的第一个参数 也就是例子中的obj
}
var obj = {
name: 'poetries',
age: 18
}
// 先测试作为构造函数调用
var bindFun = Person.myBind(obj, 'poetry1') // undefined
var a = new bindFun(10) // Person name: poetry1、Person age: 10、Person this: fBound {}
a.say() // person say
// 再测试作为普通函数调用
var bindNormalFun = normalFun.myBind(obj, 'poetry2') // undefined
bindNormalFun(12) // 普通函数name: poetry2 普通函数 age: 12 普通函数 this: {name: 'poetries', age: 18}
注意:
bind之后不能再次修改this的指向,bind多次后执行,函数this还是指向第一次bind的对象
Promise实现
基于Promise封装Ajax
- 返回一个新的
Promise实例 - 创建
HMLHttpRequest异步对象 - 调用
open方法,打开url,与服务器建立链接(发送前的一些处理) - 监听
Ajax状态信息 - 如果
xhr.readyState == 4(表示服务器响应完成,可以获取使用服务器的响应了)xhr.status == 200,返回resolve状态xhr.status == 404,返回reject状态
xhr.readyState !== 4,把请求主体的信息基于send发送给服务器
function ajax(url) {
return new Promise((resolve, reject) => {
let xhr = new XMLHttpRequest()
xhr.open('get', url)
xhr.onreadystatechange = () => {
if (xhr.readyState == 4) {
if (xhr.status >= 200 && xhr.status <= 300) {
resolve(JSON.parse(xhr.responseText))
} else {
reject('请求出错')
}
}
}
xhr.send() //发送hppt请求
})
}
let url = '/data.json'
ajax(url).then(res => console.log(res))
.catch(reason => console.log(reason))
实现Object.freeze
Object.freeze冻结一个对象,让其不能再添加/删除属性,也不能修改该对象已有属性的可枚举性、可配置可写性,也不能修改已有属性的值和它的原型属性,最后返回一个和传入参数相同的对象
function myFreeze(obj){
// 判断参数是否为Object类型,如果是就封闭对象,循环遍历对象。去掉原型属性,将其writable特性设置为false
if(obj instanceof Object){
Object.seal(obj); // 封闭对象
for(let key in obj){
if(obj.hasOwnProperty(key)){
Object.defineProperty(obj,key,{
writable:false // 设置只读
})
// 如果属性值依然为对象,要通过递归来进行进一步的冻结
myFreeze(obj[key]);
}
}
}
}
参考 前端进阶面试题详细解答
实现一个双向绑定
defineProperty 版本
// 数据
const data = {
text: 'default'
};
const input = document.getElementById('input');
const span = document.getElementById('span');
// 数据劫持
Object.defineProperty(data, 'text', {
// 数据变化 --> 修改视图
set(newVal) {
input.value = newVal;
span.innerHTML = newVal;
}
});
// 视图更改 --> 数据变化
input.addEventListener('keyup', function(e) {
data.text = e.target.value;
});
proxy 版本
// 数据
const data = {
text: 'default'
};
const input = document.getElementById('input');
const span = document.getElementById('span');
// 数据劫持
const handler = {
set(target, key, value) {
target[key] = value;
// 数据变化 --> 修改视图
input.value = value;
span.innerHTML = value;
return value;
}
};
const proxy = new Proxy(data, handler);
// 视图更改 --> 数据变化
input.addEventListener('keyup', function(e) {
proxy.text = e.target.value;
});
实现深拷贝
简洁版本
简单版:
const newObj = JSON.parse(JSON.stringify(oldObj));
局限性:
- 他无法实现对函数 、RegExp等特殊对象的克隆
- 会抛弃对象的
constructor,所有的构造函数会指向Object - 对象有循环引用,会报错
面试简版
function deepClone(obj) {
// 如果是 值类型 或 null,则直接return
if(typeof obj !== 'object' || obj === null) {
return obj
}
// 定义结果对象
let copy = {}
// 如果对象是数组,则定义结果数组
if(obj.constructor === Array) {
copy = []
}
// 遍历对象的key
for(let key in obj) {
// 如果key是对象的自有属性
if(obj.hasOwnProperty(key)) {
// 递归调用深拷贝方法
copy[key] = deepClone(obj[key])
}
}
return copy
}
调用深拷贝方法,若属性为值类型,则直接返回;若属性为引用类型,则递归遍历。这就是我们在解这一类题时的核心的方法。
进阶版
- 解决拷贝循环引用问题
- 解决拷贝对应原型问题
// 递归拷贝 (类型判断)
function deepClone(value,hash = new WeakMap){ // 弱引用,不用map,weakMap更合适一点
// null 和 undefiend 是不需要拷贝的
if(value == null){ return value;}
if(value instanceof RegExp) { return new RegExp(value) }
if(value instanceof Date) { return new Date(value) }
// 函数是不需要拷贝
if(typeof value != 'object') return value;
let obj = new value.constructor(); // [] {}
// 说明是一个对象类型
if(hash.get(value)){
return hash.get(value)
}
hash.set(value,obj);
for(let key in value){ // in 会遍历当前对象上的属性 和 __proto__指代的属性
// 补拷贝 对象的__proto__上的属性
if(value.hasOwnProperty(key)){
// 如果值还有可能是对象 就继续拷贝
obj[key] = deepClone(value[key],hash);
}
}
return obj
// 区分对象和数组 Object.prototype.toString.call
}
// test
var o = {};
o.x = o;
var o1 = deepClone(o); // 如果这个对象拷贝过了 就返回那个拷贝的结果就可以了
console.log(o1);
实现完整的深拷贝
1. 简易版及问题
JSON.parse(JSON.stringify());
估计这个api能覆盖大多数的应用场景,没错,谈到深拷贝,我第一个想到的也是它。但是实际上,对于某些严格的场景来说,这个方法是有巨大的坑的。问题如下:
- 无法解决
循环引用的问题。举个例子:
const a = {val:2};
a.target = a;
拷贝
a会出现系统栈溢出,因为出现了无限递归的情况。
- 无法拷贝一些特殊的对象,诸如
RegExp, Date, Set, Map等 - 无法拷贝
函数(划重点)。
因此这个api先pass掉,我们重新写一个深拷贝,简易版如下:
const deepClone = (target) => {
if (typeof target === 'object' && target !== null) {
const cloneTarget = Array.isArray(target) ? []: {};
for (let prop in target) {
if (target.hasOwnProperty(prop)) {
cloneTarget[prop] = deepClone(target[prop]);
}
}
return cloneTarget;
} else {
return target;
}
}
现在,我们以刚刚发现的三个问题为导向,一步步来完善、优化我们的深拷贝代码。
2. 解决循环引用
现在问题如下:
let obj = {val : 100};
obj.target = obj;
deepClone(obj);//报错: RangeError: Maximum call stack size exceeded
这就是循环引用。我们怎么来解决这个问题呢?
创建一个Map。记录下已经拷贝过的对象,如果说已经拷贝过,那直接返回它行了。
const isObject = (target) => (typeof target === 'object' || typeof target === 'function') && target !== null;
const deepClone = (target, map = new Map()) => {
if(map.get(target))
return target;
if (isObject(target)) {
map.set(target, true);
const cloneTarget = Array.isArray(target) ? []: {};
for (let prop in target) {
if (target.hasOwnProperty(prop)) {
cloneTarget[prop] = deepClone(target[prop],map);
}
}
return cloneTarget;
} else {
return target;
}
}
现在来试一试:
const a = {val:2};
a.target = a;
let newA = deepClone(a);
console.log(newA)//{ val: 2, target: { val: 2, target: [Circular] } }
好像是没有问题了, 拷贝也完成了。但还是有一个潜在的坑, 就是map 上的 key 和 map 构成了强引用关系,这是相当危险的。我给你解释一下与之相对的弱引用的概念你就明白了
在计算机程序设计中,弱引用与强引用相对,
被弱引用的对象可以在任何时候被回收,而对于强引用来说,只要这个强引用还在,那么对象无法被回收。拿上面的例子说,map 和 a一直是强引用的关系, 在程序结束之前,a 所占的内存空间一直不会被释放。
怎么解决这个问题?
很简单,让 map 的 key 和 map 构成弱引用即可。ES6给我们提供了这样的数据结构,它的名字叫WeakMap,它是一种特殊的Map, 其中的键是弱引用的。其键必须是对象,而值可以是任意的
稍微改造一下即可:
const deepClone = (target, map = new WeakMap()) => {
//...
}
3. 拷贝特殊对象
可继续遍历
对于特殊的对象,我们使用以下方式来鉴别:
Object.prototype.toString.call(obj);
梳理一下对于可遍历对象会有什么结果:
["object Map"]
["object Set"]
["object Array"]
["object Object"]
["object Arguments"]
以这些不同的字符串为依据,我们就可以成功地鉴别这些对象。
const getType = Object.prototype.toString.call(obj);
const canTraverse = {
'[object Map]': true,
'[object Set]': true,
'[object Array]': true,
'[object Object]': true,
'[object Arguments]': true,
};
const deepClone = (target, map = new Map()) => {
if(!isObject(target))
return target;
let type = getType(target);
let cloneTarget;
if(!canTraverse[type]) {
// 处理不能遍历的对象
return;
}else {
// 这波操作相当关键,可以保证对象的原型不丢失!
let ctor = target.prototype;
cloneTarget = new ctor();
}
if(map.get(target))
return target;
map.put(target, true);
if(type === mapTag) {
//处理Map
target.forEach((item, key) => {
cloneTarget.set(deepClone(key), deepClone(item));
})
}
if(type === setTag) {
//处理Set
target.forEach(item => {
target.add(deepClone(item));
})
}
// 处理数组和对象
for (let prop in target) {
if (target.hasOwnProperty(prop)) {
cloneTarget[prop] = deepClone(target[prop]);
}
}
return cloneTarget;
}
不可遍历的对象
const boolTag = '[object Boolean]';
const numberTag = '[object Number]';
const stringTag = '[object String]';
const dateTag = '[object Date]';
const errorTag = '[object Error]';
const regexpTag = '[object RegExp]';
const funcTag = '[object Function]';
对于不可遍历的对象,不同的对象有不同的处理。
const handleRegExp = (target) => {
const { source, flags } = target;
return new target.constructor(source, flags);
}
const handleFunc = (target) => {
// 待会的重点部分
}
const handleNotTraverse = (target, tag) => {
const Ctor = targe.constructor;
switch(tag) {
case boolTag:
case numberTag:
case stringTag:
case errorTag:
case dateTag:
return new Ctor(target);
case regexpTag:
return handleRegExp(target);
case funcTag:
return handleFunc(target);
default:
return new Ctor(target);
}
}
4. 拷贝函数
- 虽然函数也是对象,但是它过于特殊,我们单独把它拿出来拆解。
- 提到函数,在JS种有两种函数,一种是普通函数,另一种是箭头函数。每个普通函数都是
- Function的实例,而箭头函数不是任何类的实例,每次调用都是不一样的引用。那我们只需要
- 处理普通函数的情况,箭头函数直接返回它本身就好了。
那么如何来区分两者呢?
答案是: 利用原型。箭头函数是不存在原型的。
const handleFunc = (func) => {
// 箭头函数直接返回自身
if(!func.prototype) return func;
const bodyReg = /(?<={)(.|\n)+(?=})/m;
const paramReg = /(?<=\().+(?=\)\s+{)/;
const funcString = func.toString();
// 分别匹配 函数参数 和 函数体
const param = paramReg.exec(funcString);
const body = bodyReg.exec(funcString);
if(!body) return null;
if (param) {
const paramArr = param[0].split(',');
return new Function(...paramArr, body[0]);
} else {
return new Function(body[0]);
}
}
5. 完整代码展示
const getType = obj => Object.prototype.toString.call(obj);
const isObject = (target) => (typeof target === 'object' || typeof target === 'function') && target !== null;
const canTraverse = {
'[object Map]': true,
'[object Set]': true,
'[object Array]': true,
'[object Object]': true,
'[object Arguments]': true,
};
const mapTag = '[object Map]';
const setTag = '[object Set]';
const boolTag = '[object Boolean]';
const numberTag = '[object Number]';
const stringTag = '[object String]';
const symbolTag = '[object Symbol]';
const dateTag = '[object Date]';
const errorTag = '[object Error]';
const regexpTag = '[object RegExp]';
const funcTag = '[object Function]';
const handleRegExp = (target) => {
const { source, flags } = target;
return new target.constructor(source, flags);
}
const handleFunc = (func) => {
// 箭头函数直接返回自身
if(!func.prototype) return func;
const bodyReg = /(?<={)(.|\n)+(?=})/m;
const paramReg = /(?<=\().+(?=\)\s+{)/;
const funcString = func.toString();
// 分别匹配 函数参数 和 函数体
const param = paramReg.exec(funcString);
const body = bodyReg.exec(funcString);
if(!body) return null;
if (param) {
const paramArr = param[0].split(',');
return new Function(...paramArr, body[0]);
} else {
return new Function(body[0]);
}
}
const handleNotTraverse = (target, tag) => {
const Ctor = target.constructor;
switch(tag) {
case boolTag:
return new Object(Boolean.prototype.valueOf.call(target));
case numberTag:
return new Object(Number.prototype.valueOf.call(target));
case stringTag:
return new Object(String.prototype.valueOf.call(target));
case symbolTag:
return new Object(Symbol.prototype.valueOf.call(target));
case errorTag:
case dateTag:
return new Ctor(target);
case regexpTag:
return handleRegExp(target);
case funcTag:
return handleFunc(target);
default:
return new Ctor(target);
}
}
const deepClone = (target, map = new WeakMap()) => {
if(!isObject(target))
return target;
let type = getType(target);
let cloneTarget;
if(!canTraverse[type]) {
// 处理不能遍历的对象
return handleNotTraverse(target, type);
}else {
// 这波操作相当关键,可以保证对象的原型不丢失!
let ctor = target.constructor;
cloneTarget = new ctor();
}
if(map.get(target))
return target;
map.set(target, true);
if(type === mapTag) {
//处理Map
target.forEach((item, key) => {
cloneTarget.set(deepClone(key, map), deepClone(item, map));
})
}
if(type === setTag) {
//处理Set
target.forEach(item => {
cloneTarget.add(deepClone(item, map));
})
}
// 处理数组和对象
for (let prop in target) {
if (target.hasOwnProperty(prop)) {
cloneTarget[prop] = deepClone(target[prop], map);
}
}
return cloneTarget;
}
实现async/await
分析
// generator生成器 生成迭代器iterator
// 默认这样写的类数组是不能被迭代的,缺少迭代方法
let likeArray = {'0': 1, '1': 2, '2': 3, '3': 4, length: 4}
// // 使用迭代器使得可以展开数组
// // Symbol有很多元编程方法,可以改js本身功能
// likeArray[Symbol.iterator] = function () {
// // 迭代器是一个对象 对象中有next方法 每次调用next 都需要返回一个对象 {value,done}
// let index = 0
// return {
// next: ()=>{
// // 会自动调用这个方法
// console.log('index',index)
// return {
// // this 指向likeArray
// value: this[index],
// done: index++ === this.length
// }
// }
// }
// }
// let arr = [...likeArray]
// console.log('arr', arr)
// 使用生成器返回迭代器
// likeArray[Symbol.iterator] = function *() {
// let index = 0
// while (index != this.length) {
// yield this[index++]
// }
// }
// let arr = [...likeArray]
// console.log('arr', arr)
// 生成器 碰到yield就会暂停
// function *read(params) {
// yield 1;
// yield 2;
// }
// 生成器返回的是迭代器
// let it = read()
// console.log(it.next())
// console.log(it.next())
// console.log(it.next())
// 通过generator来优化promise(promise的缺点是不停的链式调用)
const fs = require('fs')
const path = require('path')
// const co = require('co') // 帮我们执行generator
const promisify = fn=>{
return (...args)=>{
return new Promise((resolve,reject)=>{
fn(...args, (err,data)=>{
if(err) {
reject(err)
}
resolve(data)
})
})
}
}
// promise化
let asyncReadFile = promisify(fs.readFile)
function * read() {
let content1 = yield asyncReadFile(path.join(__dirname,'./data/name.txt'),'utf8')
let content2 = yield asyncReadFile(path.join(__dirname,'./data/' + content1),'utf8')
return content2
}
// 这样写太繁琐 需要借助co来实现
// let re = read()
// let {value,done} = re.next()
// value.then(data=>{
// // 除了第一次传参没有意义外 剩下的传参都赋予了上一次的返回值
// let {value,done} = re.next(data)
// value.then(d=>{
// let {value,done} = re.next(d)
// console.log(value,done)
// })
// }).catch(err=>{
// re.throw(err) // 手动抛出错误 可以被try catch捕获
// })
// 实现co原理
function co(it) {// it 迭代器
return new Promise((resolve,reject)=>{
// 异步迭代 需要根据函数来实现
function next(data) {
// 递归得有中止条件
let {value,done} = it.next(data)
if(done) {
resolve(value) // 直接让promise变成成功 用当前返回的结果
} else {
// Promise.resolve(value).then(data=>{
// next(data)
// }).catch(err=>{
// reject(err)
// })
// 简写
Promise.resolve(value).then(next,reject)
}
}
// 首次调用
next()
})
}
co(read()).then(d=>{
console.log(d)
}).catch(err=>{
console.log(err,'--')
})
整体看一下结构
function asyncToGenerator(generatorFunc) {
return function() {
const gen = generatorFunc.apply(this, arguments)
return new Promise((resolve, reject) => {
function step(key, arg) {
let generatorResult
try {
generatorResult = gen[key](arg)
} catch (error) {
return reject(error)
}
const { value, done } = generatorResult
if (done) {
return resolve(value)
} else {
return Promise.resolve(value).then(val => step('next', val), err => step('throw', err))
}
}
step("next")
})
}
}
分析
function asyncToGenerator(generatorFunc) {
// 返回的是一个新的函数
return function() {
// 先调用generator函数 生成迭代器
// 对应 var gen = testG()
const gen = generatorFunc.apply(this, arguments)
// 返回一个promise 因为外部是用.then的方式 或者await的方式去使用这个函数的返回值的
// var test = asyncToGenerator(testG)
// test().then(res => console.log(res))
return new Promise((resolve, reject) => {
// 内部定义一个step函数 用来一步一步的跨过yield的阻碍
// key有next和throw两种取值,分别对应了gen的next和throw方法
// arg参数则是用来把promise resolve出来的值交给下一个yield
function step(key, arg) {
let generatorResult
// 这个方法需要包裹在try catch中
// 如果报错了 就把promise给reject掉 外部通过.catch可以获取到错误
try {
generatorResult = gen[key](arg)
} catch (error) {
return reject(error)
}
// gen.next() 得到的结果是一个 { value, done } 的结构
const { value, done } = generatorResult
if (done) {
// 如果已经完成了 就直接resolve这个promise
// 这个done是在最后一次调用next后才会为true
// 以本文的例子来说 此时的结果是 { done: true, value: 'success' }
// 这个value也就是generator函数最后的返回值
return resolve(value)
} else {
// 除了最后结束的时候外,每次调用gen.next()
// 其实是返回 { value: Promise, done: false } 的结构,
// 这里要注意的是Promise.resolve可以接受一个promise为参数
// 并且这个promise参数被resolve的时候,这个then才会被调用
return Promise.resolve(
// 这个value对应的是yield后面的promise
value
).then(
// value这个promise被resove的时候,就会执行next
// 并且只要done不是true的时候 就会递归的往下解开promise
// 对应gen.next().value.then(value => {
// gen.next(value).value.then(value2 => {
// gen.next()
//
// // 此时done为true了 整个promise被resolve了
// // 最外部的test().then(res => console.log(res))的then就开始执行了
// })
// })
function onResolve(val) {
step("next", val)
},
// 如果promise被reject了 就再次进入step函数
// 不同的是,这次的try catch中调用的是gen.throw(err)
// 那么自然就被catch到 然后把promise给reject掉啦
function onReject(err) {
step("throw", err)
},
)
}
}
step("next")
})
}
}
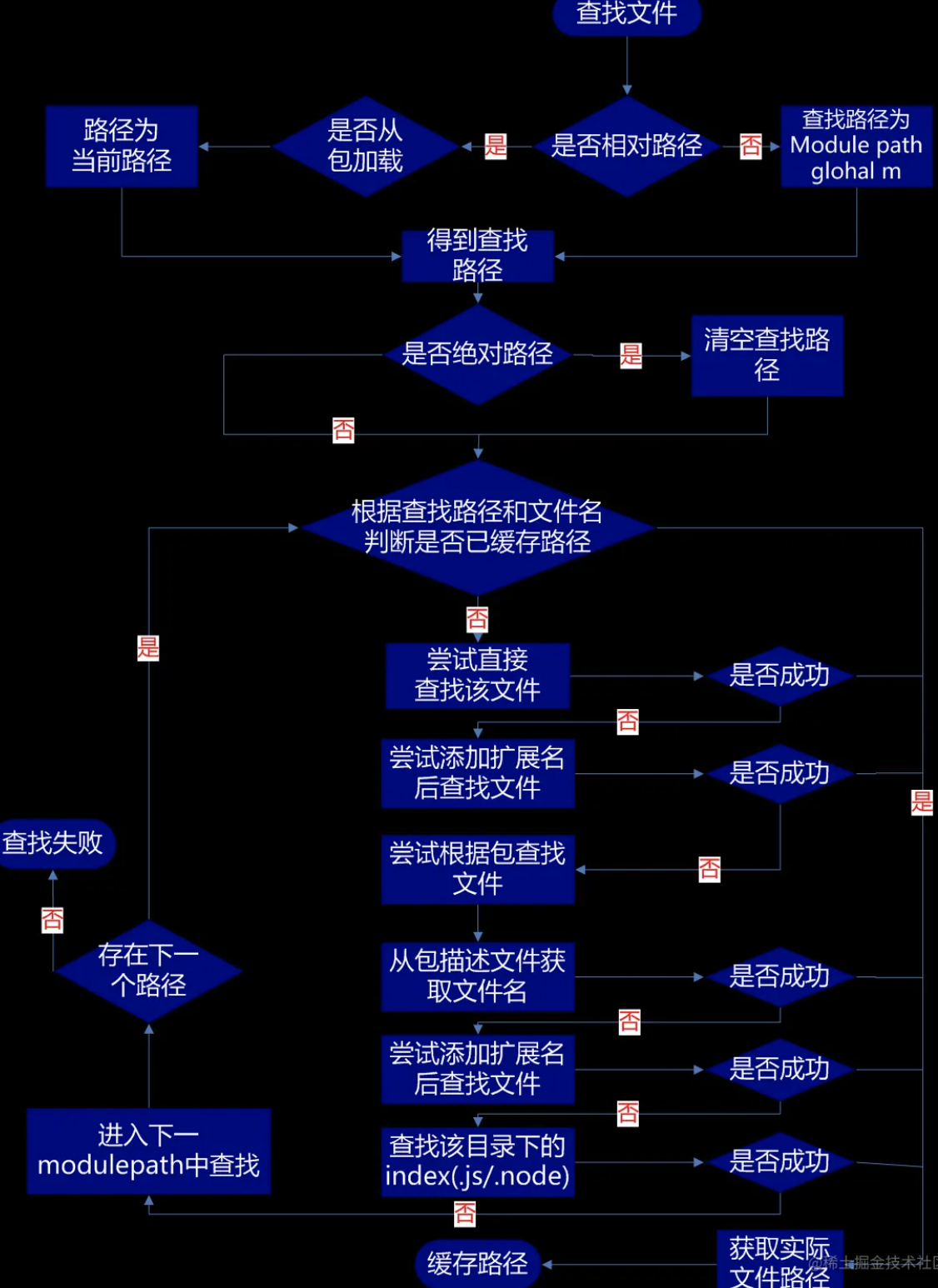
实现Node的require方法
require 基本原理
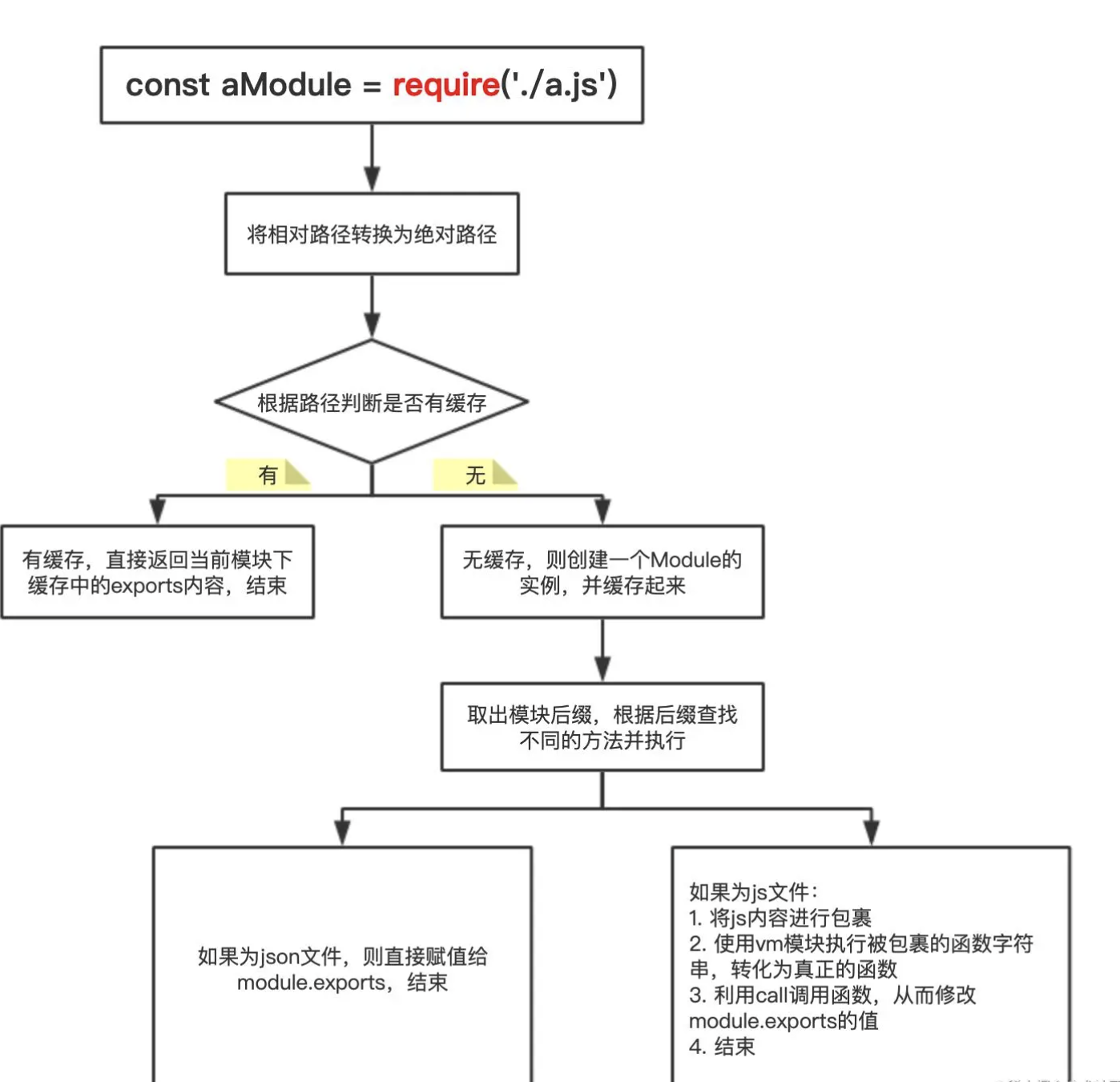
require 查找路径
require和module.exports干的事情并不复杂,我们先假设有一个全局对象{},初始情况下是空的,当你require某个文件时,就将这个文件拿出来执行,如果这个文件里面存在module.exports,当运行到这行代码时将module.exports的值加入这个对象,键为对应的文件名,最终这个对象就长这样:
{
"a.js": "hello world",
"b.js": function add(){},
"c.js": 2,
"d.js": { num: 2 }
}
当你再次
require某个文件时,如果这个对象里面有对应的值,就直接返回给你,如果没有就重复前面的步骤,执行目标文件,然后将它的module.exports加入这个全局对象,并返回给调用者。这个全局对象其实就是我们经常听说的缓存。所以require和module.exports并没有什么黑魔法,就只是运行并获取目标文件的值,然后加入缓存,用的时候拿出来用就行
手写实现一个require
const path = require('path'); // 路径操作
const fs = require('fs'); // 文件读取
const vm = require('vm'); // 文件执行
// node模块化的实现
// node中是自带模块化机制的,每个文件就是一个单独的模块,并且它遵循的是CommonJS规范,也就是使用require的方式导入模块,通过module.export的方式导出模块。
// node模块的运行机制也很简单,其实就是在每一个模块外层包裹了一层函数,有了函数的包裹就可以实现代码间的作用域隔离
// require加载模块
// require依赖node中的fs模块来加载模块文件,fs.readFile读取到的是一个字符串。
// 在javascrpt中我们可以通过eval或者new Function的方式来将一个字符串转换成js代码来运行。
// eval
// const name = 'poetry';
// const str = 'const a = 123; console.log(name)';
// eval(str); // poetry;
// new Function
// new Function接收的是一个要执行的字符串,返回的是一个新的函数,调用这个新的函数字符串就会执行了。如果这个函数需要传递参数,可以在new Function的时候依次传入参数,最后传入的是要执行的字符串。比如这里传入参数b,要执行的字符串str
// const b = 3;
// const str = 'let a = 1; return a + b';
// const fun = new Function('b', str);
// console.log(fun(b, str)); // 4
// 可以看到eval和Function实例化都可以用来执行javascript字符串,似乎他们都可以来实现require模块加载。不过在node中并没有选用他们来实现模块化,原因也很简单因为他们都有一个致命的问题,就是都容易被不属于他们的变量所影响。
// 如下str字符串中并没有定义a,但是确可以使用上面定义的a变量,这显然是不对的,在模块化机制中,str字符串应该具有自身独立的运行空间,自身不存在的变量是不可以直接使用的
// const a = 1;
// const str = 'console.log(a)';
// eval(str);
// const func = new Function(str);
// func();
// node存在一个vm虚拟环境的概念,用来运行额外的js文件,他可以保证javascript执行的独立性,不会被外部所影响
// vm 内置模块
// 虽然我们在外部定义了hello,但是str是一个独立的模块,并不在村hello变量,所以会直接报错。
// 引入vm模块, 不需要安装,node 自建模块
// const vm = require('vm');
// const hello = 'poetry';
// const str = 'console.log(hello)';
// wm.runInThisContext(str); // 报错
// 所以node执行javascript模块时可以采用vm来实现。就可以保证模块的独立性了
// 分析实现步骤
// 1.导入相关模块,创建一个Require方法。
// 2.抽离通过Module._load方法,用于加载模块。
// 3.Module.resolveFilename 根据相对路径,转换成绝对路径。
// 4.缓存模块 Module._cache,同一个模块不要重复加载,提升性能。
// 5.创建模块 id: 保存的内容是 exports = {}相当于this。
// 6.利用tryModuleLoad(module, filename) 尝试加载模块。
// 7.Module._extensions使用读取文件。
// 8.Module.wrap: 把读取到的js包裹一个函数。
// 9.将拿到的字符串使用runInThisContext运行字符串。
// 10.让字符串执行并将this改编成exports
// 定义导入类,参数为模块路径
function Require(modulePath) {
// 获取当前要加载的绝对路径
let absPathname = path.resolve(__dirname, modulePath);
// 自动给模块添加后缀名,实现省略后缀名加载模块,其实也就是如果文件没有后缀名的时候遍历一下所有的后缀名看一下文件是否存在
// 获取所有后缀名
const extNames = Object.keys(Module._extensions);
let index = 0;
// 存储原始文件路径
const oldPath = absPathname;
function findExt(absPathname) {
if (index === extNames.length) {
throw new Error('文件不存在');
}
try {
fs.accessSync(absPathname);
return absPathname;
} catch(e) {
const ext = extNames[index++];
findExt(oldPath + ext);
}
}
// 递归追加后缀名,判断文件是否存在
absPathname = findExt(absPathname);
// 从缓存中读取,如果存在,直接返回结果
if (Module._cache[absPathname]) {
return Module._cache[absPathname].exports;
}
// 创建模块,新建Module实例
const module = new Module(absPathname);
// 添加缓存
Module._cache[absPathname] = module;
// 加载当前模块
tryModuleLoad(module);
// 返回exports对象
return module.exports;
}
// Module的实现很简单,就是给模块创建一个exports对象,tryModuleLoad执行的时候将内容加入到exports中,id就是模块的绝对路径
// 定义模块, 添加文件id标识和exports属性
function Module(id) {
this.id = id;
// 读取到的文件内容会放在exports中
this.exports = {};
}
Module._cache = {};
// 我们给Module挂载静态属性wrapper,里面定义一下这个函数的字符串,wrapper是一个数组,数组的第一个元素就是函数的参数部分,其中有exports,module. Require,__dirname, __filename, 都是我们模块中常用的全局变量。注意这里传入的Require参数是我们自己定义的Require
// 第二个参数就是函数的结束部分。两部分都是字符串,使用的时候我们将他们包裹在模块的字符串外部就可以了
Module.wrapper = [
"(function(exports, module, Require, __dirname, __filename) {",
"})"
]
// _extensions用于针对不同的模块扩展名使用不同的加载方式,比如JSON和javascript加载方式肯定是不同的。JSON使用JSON.parse来运行。
// javascript使用vm.runInThisContext来运行,可以看到fs.readFileSync传入的是module.id也就是我们Module定义时候id存储的是模块的绝对路径,读取到的content是一个字符串,我们使用Module.wrapper来包裹一下就相当于在这个模块外部又包裹了一个函数,也就实现了私有作用域。
// 使用call来执行fn函数,第一个参数改变运行的this我们传入module.exports,后面的参数就是函数外面包裹参数exports, module, Require, __dirname, __filename
Module._extensions = {
'.js'(module) {
const content = fs.readFileSync(module.id, 'utf8');
const fnStr = Module.wrapper[0] + content + Module.wrapper[1];
const fn = vm.runInThisContext(fnStr);
fn.call(module.exports, module.exports, module, Require,__filename,__dirname);
},
'.json'(module) {
const json = fs.readFileSync(module.id, 'utf8');
module.exports = JSON.parse(json); // 把文件的结果放在exports属性上
}
}
// tryModuleLoad函数接收的是模块对象,通过path.extname来获取模块的后缀名,然后使用Module._extensions来加载模块
// 定义模块加载方法
function tryModuleLoad(module) {
// 获取扩展名
const extension = path.extname(module.id);
// 通过后缀加载当前模块
Module._extensions[extension](module);
}
// 至此Require加载机制我们基本就写完了,我们来重新看一下。Require加载模块的时候传入模块名称,在Require方法中使用path.resolve(__dirname, modulePath)获取到文件的绝对路径。然后通过new Module实例化的方式创建module对象,将模块的绝对路径存储在module的id属性中,在module中创建exports属性为一个json对象
// 使用tryModuleLoad方法去加载模块,tryModuleLoad中使用path.extname获取到文件的扩展名,然后根据扩展名来执行对应的模块加载机制
// 最终将加载到的模块挂载module.exports中。tryModuleLoad执行完毕之后module.exports已经存在了,直接返回就可以了
// 给模块添加缓存
// 添加缓存也比较简单,就是文件加载的时候将文件放入缓存中,再去加载模块时先看缓存中是否存在,如果存在直接使用,如果不存在再去重新,加载之后再放入缓存
// 测试
let json = Require('./test.json');
let test2 = Require('./test2.js');
console.log(json);
console.log(test2);
实现JSONP方法
利用
<script>标签不受跨域限制的特点,缺点是只能支持get请求
- 创建
script标签 - 设置
script标签的src属性,以问号传递参数,设置好回调函数callback名称 - 插入到
html文本中 - 调用回调函数,
res参数就是获取的数据
function jsonp({url,params,callback}) {
return new Promise((resolve,reject)=>{
let script = document.createElement('script')
window[callback] = function (data) {
resolve(data)
document.body.removeChild(script)
}
var arr = []
for(var key in params) {
arr.push(`${key}=${params[key]}`)
}
script.type = 'text/javascript'
script.src = `${url}?callback=${callback}&${arr.join('&')}`
document.body.appendChild(script)
})
}
// 测试用例
jsonp({
url: 'http://suggest.taobao.com/sug',
callback: 'getData',
params: {
q: 'iphone手机',
code: 'utf-8'
},
}).then(data=>{console.log(data)})
- 设置
CORS: Access-Control-Allow-Origin:* postMessage
实现ES6的extends
function B(name){
this.name = name;
};
function A(name,age){
//1.将A的原型指向B
Object.setPrototypeOf(A,B);
//2.用A的实例作为this调用B,得到继承B之后的实例,这一步相当于调用super
Object.getPrototypeOf(A).call(this, name)
//3.将A原有的属性添加到新实例上
this.age = age;
//4.返回新实例对象
return this;
};
var a = new A('poetry',22);
console.log(a);
实现Array.of方法
Array.of()方法用于将一组值,转换为数组
- 这个方法的主要目的,是弥补数组构造函数
Array()的不足。因为参数个数的不同,会导致Array()的行为有差异。 Array.of()基本上可以用来替代Array()或new Array(),并且不存在由于参数不同而导致的重载。它的行为非常统一
Array.of(3, 11, 8) // [3,11,8]
Array.of(3) // [3]
Array.of(3).length // 1
实现
function ArrayOf(){
return [].slice.call(arguments);
}
reduce用法汇总
语法
array.reduce(function(total, currentValue, currentIndex, arr), initialValue);
/*
total: 必需。初始值, 或者计算结束后的返回值。
currentValue: 必需。当前元素。
currentIndex: 可选。当前元素的索引;
arr: 可选。当前元素所属的数组对象。
initialValue: 可选。传递给函数的初始值,相当于total的初始值。
*/
reduceRight()该方法用法与reduce()其实是相同的,只是遍历的顺序相反,它是从数组的最后一项开始,向前遍历到第一项
1. 数组求和
const arr = [12, 34, 23];
const sum = arr.reduce((total, num) => total + num);
// 设定初始值求和
const arr = [12, 34, 23];
const sum = arr.reduce((total, num) => total + num, 10); // 以10为初始值求和
// 对象数组求和
var result = [
{ subject: 'math', score: 88 },
{ subject: 'chinese', score: 95 },
{ subject: 'english', score: 80 }
];
const sum = result.reduce((accumulator, cur) => accumulator + cur.score, 0);
const sum = result.reduce((accumulator, cur) => accumulator + cur.score, -10); // 总分扣除10分
2. 数组最大值
const a = [23,123,342,12];
const max = a.reduce((pre,next)=>pre>cur?pre:cur,0); // 342
3. 数组转对象
var streams = [{name: '技术', id: 1}, {name: '设计', id: 2}];
var obj = streams.reduce((accumulator, cur) => {accumulator[cur.id] = cur; return accumulator;}, {});
4. 扁平一个二维数组
var arr = [[1, 2, 8], [3, 4, 9], [5, 6, 10]];
var res = arr.reduce((x, y) => x.concat(y), []);
5. 数组去重
实现的基本原理如下:
① 初始化一个空数组
② 将需要去重处理的数组中的第1项在初始化数组中查找,如果找不到(空数组中肯定找不到),就将该项添加到初始化数组中
③ 将需要去重处理的数组中的第2项在初始化数组中查找,如果找不到,就将该项继续添加到初始化数组中
④ ……
⑤ 将需要去重处理的数组中的第n项在初始化数组中查找,如果找不到,就将该项继续添加到初始化数组中
⑥ 将这个初始化数组返回
var newArr = arr.reduce(function (prev, cur) {
prev.indexOf(cur) === -1 && prev.push(cur);
return prev;
},[]);
6. 对象数组去重
const dedup = (data, getKey = () => { }) => {
const dateMap = data.reduce((pre, cur) => {
const key = getKey(cur)
if (!pre[key]) {
pre[key] = cur
}
return pre
}, {})
return Object.values(dateMap)
}
7. 求字符串中字母出现的次数
const str = 'sfhjasfjgfasjuwqrqadqeiqsajsdaiwqdaklldflas-cmxzmnha';
const res = str.split('').reduce((pre,next)=>{
pre[next] ? pre[next]++ : pre[next] = 1
return pre
},{})
// 结果
-: 1
a: 8
c: 1
d: 4
e: 1
f: 4
g: 1
h: 2
i: 2
j: 4
k: 1
l: 3
m: 2
n: 1
q: 5
r: 1
s: 6
u: 1
w: 2
x: 1
z: 1
8. compose函数
redux compose源码实现
function compose(...funs) {
if (funs.length === 0) {
return arg => arg;
}
if (funs.length === 1) {
return funs[0];
}
return funs.reduce((a, b) => (...arg) => a(b(...arg)))
}
版本号排序的方法
题目描述:有一组版本号如下 ['0.1.1', '2.3.3', '0.302.1', '4.2', '4.3.5', '4.3.4.5']。现在需要对其进行排序,排序的结果为 ['4.3.5','4.3.4.5','2.3.3','0.302.1','0.1.1']
arr.sort((a, b) => {
let i = 0;
const arr1 = a.split(".");
const arr2 = b.split(".");
while (true) {
const s1 = arr1[i];
const s2 = arr2[i];
i++;
if (s1 === undefined || s2 === undefined) {
return arr2.length - arr1.length;
}
if (s1 === s2) continue;
return s2 - s1;
}
});
console.log(arr);
实现map方法
- 回调函数的参数有哪些,返回值如何处理
- 不修改原来的数组
Array.prototype.myMap = function(callback, context){
// 转换类数组
var arr = Array.prototype.slice.call(this),//由于是ES5所以就不用...展开符了
mappedArr = [],
i = 0;
for (; i < arr.length; i++ ){
// 把当前值、索引、当前数组返回去。调用的时候传到函数参数中 [1,2,3,4].map((curr,index,arr))
mappedArr.push(callback.call(context, arr[i], i, this));
}
return mappedArr;
}
实现一个JSON.parse
JSON.parse(text[, reviver])
用来解析JSON字符串,构造由字符串描述的JavaScript值或对象。提供可选的reviver函数用以在返回之前对所得到的对象执行变换(操作)
第一种:直接调用 eval
function jsonParse(opt) {
return eval('(' + opt + ')');
}
jsonParse(jsonStringify({x : 5}))
// Object { x: 5}
jsonParse(jsonStringify([1, "false", false]))
// [1, "false", falsr]
jsonParse(jsonStringify({b: undefined}))
// Object { b: "undefined"}
避免在不必要的情况下使用
eval,eval()是一个危险的函数,他执行的代码拥有着执行者的权利。如果你用eval()运行的字符串代码被恶意方(不怀好意的人)操控修改,您最终可能会在您的网页/扩展程序的权限下,在用户计算机上运行恶意代码。它会执行JS代码,有XSS漏洞。
如果你只想记这个方法,就得对参数json做校验。
var rx_one = /^[\],:{}\s]*$/;
var rx_two = /\\(?:["\\\/bfnrt]|u[0-9a-fA-F]{4})/g;
var rx_three = /"[^"\\\n\r]*"|true|false|null|-?\d+(?:\.\d*)?(?:[eE][+\-]?\d+)?/g;
var rx_four = /(?:^|:|,)(?:\s*\[)+/g;
if (
rx_one.test(
json
.replace(rx_two, "@")
.replace(rx_three, "]")
.replace(rx_four, "")
)
) {
var obj = eval("(" +json + ")");
}
第二种:Function
核心:Function与eval有相同的字符串参数特性
var func = new Function(arg1, arg2, ..., functionBody);
在转换JSON的实际应用中,只需要这么做
var jsonStr = '{ "age": 20, "name": "jack" }'
var json = (new Function('return ' + jsonStr))();
eval与Function都有着动态编译js代码的作用,但是在实际的编程中并不推荐使用
转化为驼峰命名
var s1 = "get-element-by-id"
// 转化为 getElementById
var f = function(s) {
return s.replace(/-\w/g, function(x) {
return x.slice(1).toUpperCase();
})
}
原生实现
function ajax() {
let xhr = new XMLHttpRequest() //实例化,以调用方法
xhr.open('get', 'https://www.google.com') //参数2,url。参数三:异步
xhr.onreadystatechange = () => { //每当 readyState 属性改变时,就会调用该函数。
if (xhr.readyState === 4) { //XMLHttpRequest 代理当前所处状态。
if (xhr.status >= 200 && xhr.status < 300) { //200-300请求成功
let string = request.responseText
//JSON.parse() 方法用来解析JSON字符串,构造由字符串描述的JavaScript值或对象
let object = JSON.parse(string)
}
}
}
request.send() //用于实际发出 HTTP 请求。不带参数为GET请求
}
小孩报数问题
有30个小孩儿,编号从1-30,围成一圈依此报数,1、2、3 数到 3 的小孩儿退出这个圈, 然后下一个小孩 重新报数 1、2、3,问最后剩下的那个小孩儿的编号是多少?
function childNum(num, count){
let allplayer = [];
for(let i = 0; i < num; i++){
allplayer[i] = i + 1;
}
let exitCount = 0; // 离开人数
let counter = 0; // 记录报数
let curIndex = 0; // 当前下标
while(exitCount < num - 1){
if(allplayer[curIndex] !== 0) counter++;
if(counter == count){
allplayer[curIndex] = 0;
counter = 0;
exitCount++;
}
curIndex++;
if(curIndex == num){
curIndex = 0
};
}
for(i = 0; i < num; i++){
if(allplayer[i] !== 0){
return allplayer[i]
}
}
}
childNum(30, 3)