1,要学习Python机器学习,第一步就是读入数据,这里我们以读入excel的数据为例,利用jupyter notebook来编码,具体教程看这个视频
推荐先上传到jupyter notebook,再用名字.xlsx来导入
Jupyter notebook导入Excel数据的两种方法介绍_哔哩哔哩_bilibili
2,同一目录下的代码互相关联,也就是你在这个项目里import的库或者初始化的变量,可以在下一个项目使用,所以提交单个代码时可能会报错
目录
1,Pandas的数据加工处理
2,空气质量监测数据预处理
3,空气质量检测数据基本分析
1,Pandas的数据加工处理
import numpy as np
import pandas as pd
from pandas import Series,DataFrame
df1 = DataFrame({'key':['a','d','c','a','b','d','c'],'var1':range(7)}) #基于字典建立数据框
print('df1的数据:\n{0}'.format(df1))
df2 = DataFrame({'key':['a','b','c','c'],'var2':[0,1,2,2]})
print('df2的数据:\n{0}'.format(df2))
df = pd.merge(df1,df2,on='key',how='outer')
df.iloc[0,2]=np.NaN
df.iloc[5,1]=np.NaN
print('合并后的数据:\n{0}'.format(df))
df = df.drop_duplicates()
print('删除重复数据行后的数据:\n{0}'.format(df))
print('判断是否为缺失值:\n{0}'.format(df.isnull()))
print('判断是否不为缺失值:\n{0}'.format(df.notnull()))
print('删除缺失值后的数据:\n{0}'.format(df.dropna()))
fill_value=df[['var1','var2']].apply(lambda x:x.mean())
print('以均值替代缺失值:\n{0}'.format(df.fillna(fill_value)))1,
第4,6行,字典的优势在于引入键,通过键访问数据更灵活
从数据集的角度,key和var1两个键对应两个变量(即数据集的两个列)
两组值则对应数据集两列的取值
df1行索引取值范围0至6,列索引名为key和var1
注意!基于字典建立数据库的“字典”,各组键的值的个数要相等,否则有些样本观测在某个变量上没有具体取值
2,
第8行,pandas.merge()将两个数据框按指定关键字横向合并,也就是这个关键字这一列合并了,其他不变,但是个数会增多
.iloc[]=numpy.NaN指定样本观测的某变量为NaN,NaN在Numpy表示缺失值,不参与数据建模分析
3,
.drop_duplicates()剔除在所有变量上都重复取值的样本观测
.isnull(),.notnull(),判断是否为NaN,输出True或False
.dropna()剔除取NaN的样本观测
.apply() + lambda计算各变量均值
.apply()实现循环处理,lambda告知了循环处理的步骤
.fillna()将所有NaN替换为指定值
df1的数据:
key var1
0 a 0
1 d 1
2 c 2
3 a 3
4 b 4
5 d 5
6 c 6
df2的数据:
key var2
0 a 0
1 b 1
2 c 2
3 c 2
合并后的数据:
key var1 var2
0 a 0.0 NaN
1 a 3.0 0.0
2 d 1.0 NaN
3 d 5.0 NaN
4 c 2.0 2.0
5 c NaN 2.0
6 c 6.0 2.0
7 c 6.0 2.0
8 b 4.0 1.0
删除重复数据行后的数据:
key var1 var2
0 a 0.0 NaN
1 a 3.0 0.0
2 d 1.0 NaN
3 d 5.0 NaN
4 c 2.0 2.0
5 c NaN 2.0
6 c 6.0 2.0
8 b 4.0 1.0
判断是否为缺失值:
key var1 var2
0 False False True
1 False False False
2 False False True
3 False False True
4 False False False
5 False True False
6 False False False
8 False False False
判断是否不为缺失值:
key var1 var2
0 True True False
1 True True True
2 True True False
3 True True False
4 True True True
5 True False True
6 True True True
8 True True True
删除缺失值后的数据:
key var1 var2
1 a 3.0 0.0
4 c 2.0 2.0
6 c 6.0 2.0
8 b 4.0 1.0
以均值替代缺失值:
key var1 var2
0 a 0.0 1.4
1 a 3.0 0.0
2 d 1.0 1.4
3 d 5.0 1.4
4 c 2.0 2.0
5 c 3.0 2.0
6 c 6.0 2.0
8 b 4.0 1.02,空气质量监测数据预处理
import numpy as np
import pandas as pd
from pandas import Series,DataFrame
data=pd.read_excel('北京市空气质量数据.xlsx') #pandas.read_excel()将excel格式数据读入数据框
data=data.replace(0,np.NaN) #数据框函数.replace(0,numpy.NaN)将0替换为缺失值NaN
data['年']=data['日期'].apply(lambda x:x.year) #.apply(lambda x:x.year)基于'日期'变量得到年份
month=data['日期'].apply(lambda x:x.month)
quarter_month={'1':'一季度','2':'一季度','3':'一季度', #建立一个关于月份和季度的字典quarter_month
'4':'二季度','5':'二季度','6':'二季度',
'7':'三季度','8':'三季度','9':'三季度',
'10':'四季度','11':'四季度','12':'四季度'}
data['季度']=month.map(lambda x:quarter_month[str(x)]) #month.map(lambda x:quarter_month...)将month中的1,2,3等月份映射到相应季度标签变量
bins=[0,50,100,150,200,300,1000] #生成一个列表bins,用于对后续AQI分组,它描述了AQI和空气质量等级的数值对应关系
data['等级']=pd.cut(data['AQI'],bins,labels=['一级优','二级良','三级轻度污染','四级中度污染','五级重度污染','六级严重污染'])
print('对AQI的分组结果:\n{0}'.format(data[['日期','AQI','等级','季度']])) #pandas.cut()对AQI分组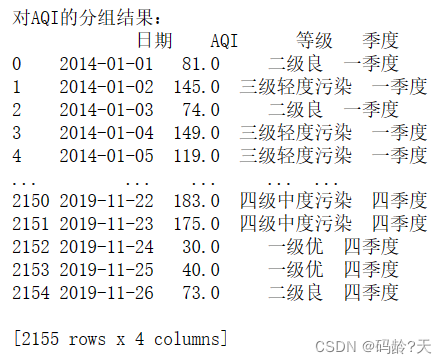
3,空气质量检测数据基本分析
import pandas as pd
data=pd.read_excel('北京市空气质量数据.xlsx') #pandas.read_excel()将Excel格式数据读入数据框
month=data['日期'].apply(lambda x:x.month) #基于日期变量, 得到每个样本观测的月份
quarter_month={'1':'一季度','2':'一季度','3':'一季度',
'4':'二季度','5':'二季度','6':'二季度',
'7':'三季度','8':'三季度','9':'三季度', #建立一个关于月份和季度的字典
'10':'四季度','11':'四季度','12':'四季度'}
data['季度']=month.map(lambda x:quarter_month[str(x)]) #.map()将序列month中月份映射到对应季度标签上
bins=[0,50,100,150,200,300,1000] #列表bins, 描述AQI
data['等级']=pd.cut(data['AQI'],bins,labels=['一级优','二级良','三级轻度污染','四级中度污染','五级重度污染','六级严重污染'])
print('各季度的AQI和Pm2.5的均值:\n{0}'.format(data.loc[:,['AQI','PM2.5']].groupby(data['季度']).mean()))
print('各季度AQI和PM2.5的描述统计量:\n',data.groupby(data['季度'])['AQI','PM2.5'].apply(lambda x:x.describe()))
def top(df, n = 10, column='AQI'):
return df.sort_values(by=column, ascending=False)[:n]
print('空气质量最差的5天:\n',top(data,n=5)[['日期','AQI','PM2.5','等级']])
print('各季度空气质量最差3天:\n',data.groupby(data['季度']).apply(lambda x:top(x, n=3)[['日期','AQI','PM2.5','等级']]))
print('各季度空气质量情况:\n',pd.crosstab(data['等级'],data['季度'],margins=True,margins_name='总计',normalize=False))各季度的AQI和Pm2.5的均值:
AQI PM2.5
季度
一季度 109.125693 77.083179
三季度 98.731884 49.438406
二季度 108.766972 54.744954
四季度 109.400387 77.046422
各季度AQI和PM2.5的描述统计量:
AQI PM2.5
季度
一季度 count 541.000000 541.000000
mean 109.125693 77.083179
std 80.468322 73.141507
min 0.000000 0.000000
25% 48.000000 24.000000
50% 80.000000 53.000000
75% 145.000000 109.000000
max 470.000000 454.000000
三季度 count 552.000000 552.000000
mean 98.731884 49.438406
std 45.637813 35.425541
min 0.000000 0.000000
25% 60.000000 23.000000
50% 95.000000 41.000000
75% 130.250000 67.000000
max 252.000000 202.000000
二季度 count 545.000000 545.000000
mean 108.766972 54.744954
std 50.129711 36.094890
min 0.000000 0.000000
25% 71.000000 27.000000
50% 98.000000 47.000000
75% 140.000000 73.000000
max 500.000000 229.000000
四季度 count 517.000000 517.000000
mean 109.400387 77.046422
std 84.248549 76.652706
min 0.000000 0.000000
25% 55.000000 25.000000
50% 78.000000 51.000000
75% 137.000000 101.000000
max 485.000000 477.000000
空气质量最差的5天:
日期 AQI PM2.5 等级
1218 2017-05-04 500 0 六级严重污染
723 2015-12-25 485 477 六级严重污染
699 2015-12-01 476 464 六级严重污染
1095 2017-01-01 470 454 六级严重污染
698 2015-11-30 450 343 六级严重污染
各季度空气质量最差3天:
日期 AQI PM2.5 等级
季度
一季度 1095 2017-01-01 470 454 六级严重污染
45 2014-02-15 428 393 六级严重污染
55 2014-02-25 403 354 六级严重污染
三季度 186 2014-07-06 252 202 五级重度污染
211 2014-07-31 245 195 五级重度污染
183 2014-07-03 240 190 五级重度污染
二季度 1218 2017-05-04 500 0 六级严重污染
1219 2017-05-05 342 181 六级严重污染
103 2014-04-14 279 229 五级重度污染
四季度 723 2015-12-25 485 477 六级严重污染
699 2015-12-01 476 464 六级严重污染
698 2015-11-30 450 343 六级严重污染
各季度空气质量情况:
季度 一季度 三季度 二季度 四季度 总计
等级
一级优 145 96 38 108 387
二级良 170 209 240 230 849
三级轻度污染 99 164 152 64 479
四级中度污染 57 72 96 33 258
五级重度污染 48 10 14 58 130
六级严重污染 21 0 2 23 46
总计 540 551 542 516 2149pd.get_dummies(data['等级']) #pandas.get_dummies()得到分类型变量等级的虚拟变量
data.join(pd.get_dummies(data['等级'])) #数据框的.join()将原始数据与虚拟变量按行索引横向合并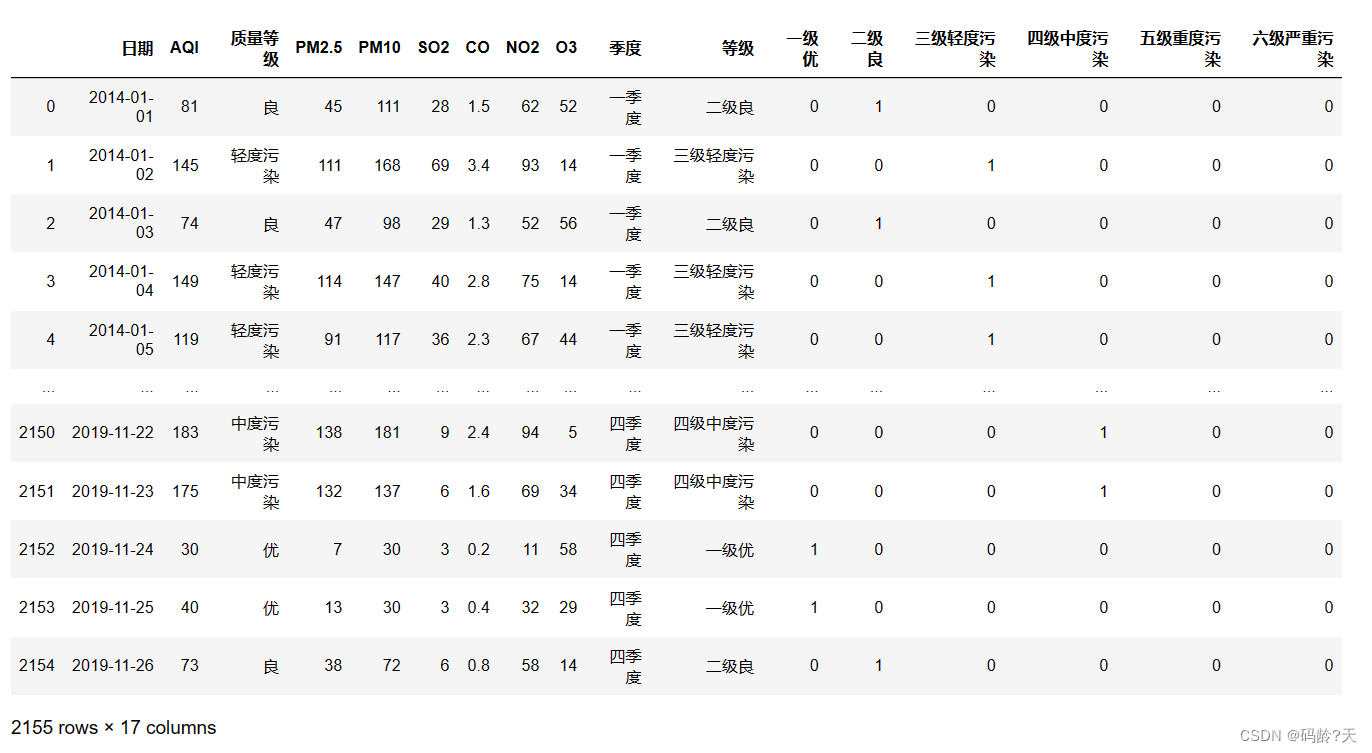
import numpy as np #导入numpy库
np.random.seed(123)#随机数种子
sampler=np.random.randint(0,len(data),10) #numpy.random.randint()指定范围随机抽取指定个数
print(sampler)
sampler=np.random.permutation(len(data))[:10] #numpy.random.permutation()随机打乱重排, 再抽取前10个
print(sampler)
data.take(sampler) #数据框.take()基于指定随机数获得数据集的一个随机子集
data.loc[data['质量等级']=='优',:] #数据框访问方式,抽取满足指定条件的行的数据子集

![[8]云计算概念、技术与架构Thomas Erl-第九章 云管理机制|week9|10月29日](https://img-blog.csdnimg.cn/fd98f8ef447c4066b6ec74ce55e8537a.png)