PySpark算法开发实战
一、PySpark介绍
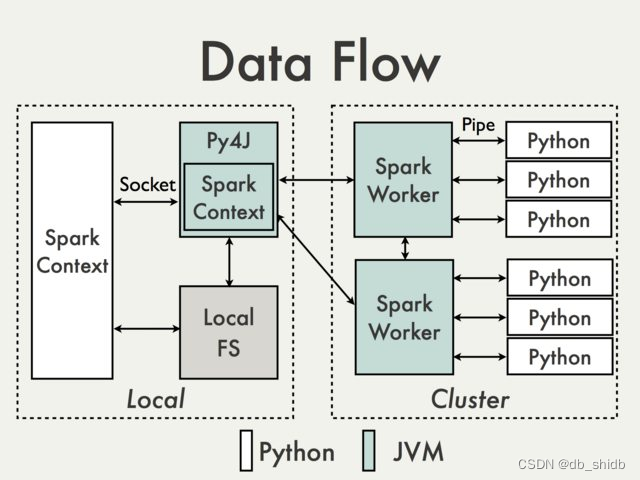
Spark是一种快速、通用、可扩展的大数据分析引擎,PySpark是Spark为Python开发者提供的API。在有非常多可视化和机器学习算法需求的应用场景,使用PySpark比Spark-Scala可以更好地和python中丰富的库配合使用。
使用Python开发Spark需要使用到pyspark,pyspark是Spark为Python开发者提供的API。pyspark使用Py4J库,使得Python可以使用JVM对象。
二、运行环境搭建
操作系统 CentOS Linux release 7.8.2003 (Core)
Java 1.8.0_151
Python 3.6.13
Spark 2.4.0
Miniconda 4.5.4
pyspark 3.2.1
pyarrow 6.0.1
Miniconda
- 安装Miniconda
conda和virtualenv是Python的包管理与环境管理工具。conda的安装程序中包含conda软件包管理器和Python,不需要再单独安装Python,使用起来较为方便。Miniconda为conda精简版,大小约为50M。
由于我们使用的Spark版本与Python版本为历史版本,需要用4.5.4版本的Miniconda(对应Python 3.6)进行安装。当前官网下载页的miniconda支持到最低3.7版本Python,需要在https://repo.anaconda.com/miniconda/上下载。根据机型选择Miniconda2-4.5.4-Linux-x86_64.sh下载。
下载完成之后运行脚本Miniconda2-4.5.4-Linux-x86_64.sh进行安装。完成之后可以使用conda -V检查安装结果。
conda -V conda 4.5.4 - 设置用于Spark的虚拟环境
首先建立一个pyspark_env的环境
conda create --name pyspark_env python=3.6
新建完成之后可以从过conda activate进入虚拟环境
conda activate pyspark_env
进入环境之后命令行会有环境名的标识用于区分
创建好并进入pyspark_env的虚拟环境之后,我们需要安装两个Spark相关的库,pyspark和pyarrow。可以使用conda install安装或者也可使用pip,这里以使用pip安装为例:
pip3 install pyarrow pyspark
安装完毕之后可以使用conda list查看安装好的库
此,环境搭建中的conda部分已经完成。详细的操作可以参考Spark的最新文档,pyspark conda部署的部分是多版本通用的:Installation - PySpark 3.2.1 documentation
Spark
-
下载Spark
我们下载Spark已经编译好的压缩包,所有的历史版本可以在这个链接中找到:https://archive.apache.org/dist/spark/,
本文下载spark-2.4.0-bin-hadoop2.7.tgz
下载完成之后解压文件。完成之后可以进入目录运行bin/spark-shell进行测试
-
Standalone模式启动集群
Spark的集群模式总共分为四种
- Standalone
- Apache Mesos
- Hadoop YARN
- Kubernetes
2、3、4都比较好理解,Standalone模式是Spark自身实现的资源调度框架。
复制spark根目录下的conf/spark-env.sh.template -> conf/spark-env.sh
在其中添加
SPARK_MASTER_HOST = [hostname] # master的主机名
SPARK_MASTER_PORT= 7077
在master节点上运行
./sbin/start-master.sh
启动之后可以登录webui查看,地址为IP:8080
同样,在slave节点设置好环境变量之后运行
./sbin/start-slave.sh
三、Spark分布式运行算法
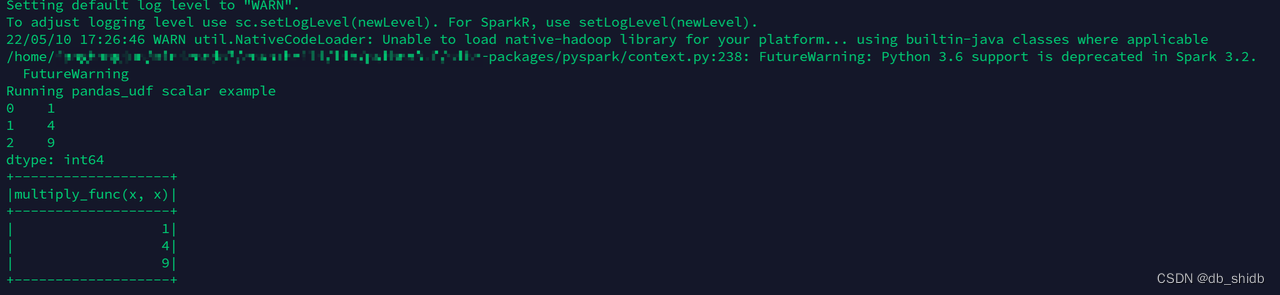
下面的代码是Spark 运行Pandas UDF的例子。
def scalar_pandas_udf_example(spark):
import pandas as pd
from pyspark.sql.functions import col, pandas_udf
from pyspark.sql.types import LongType
def multiply_func(a, b):
return a * b
multiply = pandas_udf(multiply_func, returnType=LongType())
x = pd.Series([1, 2, 3])
print(multiply_func(x, x))
df = spark.createDataFrame(pd.DataFrame(x, columns=["x"]))
df.select(multiply(col("x"), col("x"))).show()
if __name__ == "__main__":
spark = SparkSession \
.builder \
.master('local')\
.appName("UDFTest") \
.getOrCreate()
print("Running pandas_udf scalar example")
scalar_pandas_udf_example(spark)
spark.stop()
首先生成一个SparkSession对象,参数master->'local’指的是local模式运行,如果是集群的话这里local换成spark:\masterip:7077,appName->'UDFTest’定义了任务名称
spark = SparkSession \
.builder \
.master('local')\
.appName("UDFTest") \
.getOrCreate()
定义一个简单的函数
def multiply_func(a, b):
return a * b
生成UDF对象
multiply = pandas_udf(multiply_func, returnType=LongType())
生成一个pandas的数据
x = pd.Series([1, 2, 3])
创建一个Spark dataframe对象并让spark执行UDF
df = spark.createDataFrame(pd.DataFrame(x, columns=["x"]))
df.select(multiply(col("x"), col("x"))).show()
该代码运行的结果为:
四、Spark数据处理的缺点
- 一般生产环境下的数据想要使用Spark做计算,数据需要从存储的数据库->落盘文件/消息队列->Spark集群数据链路需要建设和维护
- PySpark + Pandas UDF处理数据,尽管利用了Apache Arrow,核心还是需要JVM与Python之间数据传输,开销大,不适用于性能敏感的场景。
YMatrix+ PLPython处理方式
上文描述了Spark在车联网信号分析的实际使用案例。Spark的优点很明显,作为分布式的内存计算引擎,社区活跃、支持多语言开发、易于融合其他如Hadoop等框架。但使用上的缺点在上文中也有描述:需要搭建并维护一整条新的数据链路;并且除去Scala,使用Python等其他语言研发不适合在性能要求高的场景下使用。
那么回到我们实现车联网信号分析这个案例上,实际上最终的需求是从一部分数据中取出想要的数据、并且经过一定的要求与计算,筛选出最终的数据结果——实际上就是简单的一条SQL+代码实现算法处理数据。上述例子中,“一条SQL”变成了整条数据链路,从数据库取出数据处理完丢进消息队列,“代码实现算法”的代码加载到了Spark分布式的消费数据和运行。如果能够把“代码实现算法”这部分与下沉到数据库这层,那么我们不仅减少了维护一整套数据链路的开销,还能利用数据库的算力提供性能,加速数据流转。想要利用数据库帮我们进行数据分析与计算,我们需要MPP架构的数据库。
一、YMatrix与PLPython介绍
YMatrix
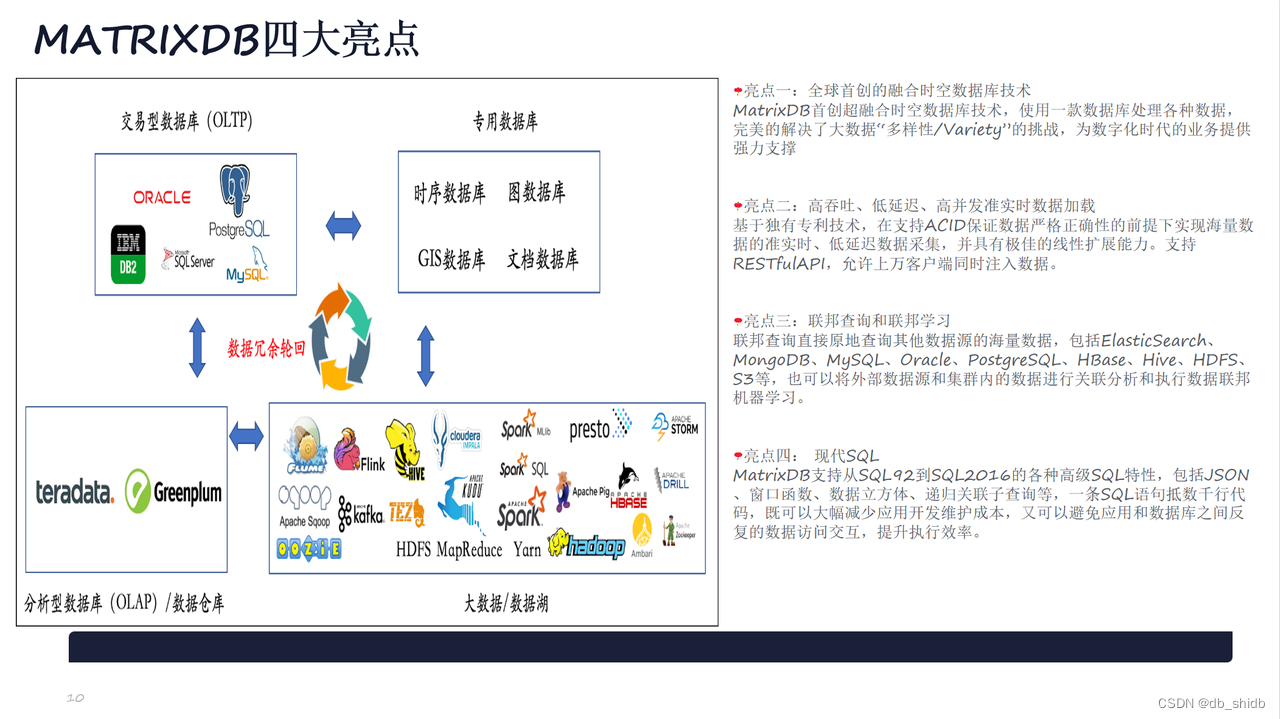
YMatrix是超融合数据库,将交易型数据库(OLTP)、分析型数据库(OLAP)和时序数据库能力融为一体的超融合型分布式数据库产品,具备严格分布式事务一致性、水平在线扩容、安全可靠、成熟稳定、兼容PostgreSQL/Greenplum协议和生态等重要特性。为万物互联的智能时代提供坚实、简洁的智能数据核心基础设施,为物联网应用、工业互联网、智能运维、智慧城市、实时数仓、智能家居、车联网等场景提供一站式高效解决方案,YMatrix为公司自主研发的国产数据库,公司拥有该产品全部知识产权。产品的架构如下。

YMatrix不但对经典的Greenplum数据仓库场景进行了大幅增强,而且可以极佳的支持大规模时序数据处理、支持时空数据、结构化数据和半结构化数据,一套数据库解决各种数据类型,避免为了处理不同类型数据引入不同类型的产品。实现提高开发运维效率、提升系统性能、降低整体成本的目标。
PLPython
PL/Python过程语言允许用Python编写 PostgreSQL函数。Python有非常多成熟的库能够提供给我们做数据分析,如numpy、pandas等。
使用PLPython方便数据分析的算法实现,可以充分利用YMatrix分布式储存和算力。

二、PLPython调用外部Python代码
上文中描述了如何使用Python开发Spark应用,让我们的算法能够使用Spark的分布式计算能力,整体的数据流程是从csv的数据文件中读取数据->Spark Arrow内存的数据类型中->Spark分布式计算输出结果。
相同的算法也可以通过PLPython,将数据转存到YMatrix查询计算实现
将数据导入YMatrix
使用Mxgate将csv中的数据导入数据库,在此之前需要新建表
vin text,
daq_time DATE,
status INT,
c_stat INT,
mode INT,
speed INT,
mileage INT,
t_volt INT,
t_current INT,
soc INT,
dcdc_stat INT,
isulate_r INT,
lng BIGINT,
lat BIGINT,
max_volt_bat_id INT,
max_volt_cell_id INT,
max_cell_volt INT,
min_volt_bat_id INT,
min_cell_volt_id INT,
min_cell_volt INT,
max_temp_sys_id INT,
max_temp_probe_id INT,
max_temp INT,
min_temp_sys_id INT,
min_temp_probe_id INT,
min_temp INT,
max_alarm_lvl INT,
genral_alarm INT,
cell_volt_list text,
cell_temp_list TEXT,
pdate date)
distributed BY (vin)
表格建好了之后导入数据
tail -n +1 data.csv | mxgate --source stdin --db-database test --db-master-host localhost.localdomain --db-master-port 5432 --db-user mxadmin --time-format raw --target suanfa_data --delimiter ','
编写PLPython函数调用算法
首先我们需要把算法代码上传到服务器上,在本例中路径为/home/mxadmin/plpython/
我们需要查询suanfa_data表中的所有数据,并将结果转化成pandas的Dataframe格式,传递给算法函数去做处理
sql = "SELECT * FROM suanfa_data;"
df = psql.frame_query(sql, cnxn)
create function suanfa_detector() returns void as $$
import sys
sys.path.append('/home/mxadmin/plpython/')
from src.analyzer import analyzer
import pyodbc
import pandas.io.sql as psql
sql_result = plpy.execute("SELECT * FROM suanfa_data;")
df = pd.DataFrame.from_records(sql_result)
result = analyzer(df)
plpy.notice(result)
$$ language plpython3u;
下面是算法函数,输入是我们suanfa_detector()中sql的查询结果转换成的dataframe对象,经过数据处理,最后输出结果的dataframe
Def analyzer(data: pandas.Dataframe)-> pandas.Dataframe:
data_wash(data)
sign_data_veh_state(data)
detect_two_alarm_tuples = detect_two_analyze(data)
return detect_two_alarm_tuples