Spark是一个用于大规模数据处理的统一计算引擎
注意:Spark不仅仅可以做类似于MapReduce的离线数据计算,还可以做实时数据计算,并且它还可以实现类似于Hive的SQL计算,等等,所以说它是一个统一的计算引擎
既然说到了Spark,那就不得不提一下Spark里面最重要的一个特性:内存计算
Spark中一个最重要的特性就是基于内存进行计算,从而让它的计算速度可以达到MapReduce的几十倍甚至上百倍
所以说在这大家要知道,Spark是一个基于内存的计算引擎
Spark特点:
1)速度快
由于Spark是基于内存进行计算的,所以它的计算性能理论上可以比MapReduce快100倍
Spark使用最先进的DAG调度器、查询优化器和物理执行引擎,实现了高性能的批处理和流处理。
注意:批处理其实就是离线计算,流处理就是实时计算。
2)易用

1. 可以使用多种编程语言快速编写应用程序,例如Java、Scala、Python、R和SQL
2. Spark提供了80多个高阶函数,可以轻松构建Spark任务。
3)通用性
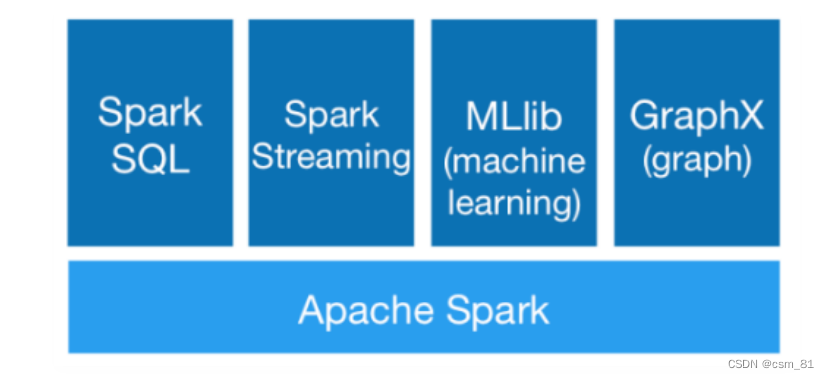
Spark提供了Core、SQL、Streaming、MLlib、GraphX等技术组件,可以一站式地完成大数据领域的离线批处理、SQL交互式查询、流式实时计算,机器学习、图计算等常见的任务
从这可以看出来Spark也是一个具备完整生态圈的技术框架,它不是一个人在战斗。
4)到处运行
你可以在Hadoop YARN、Mesos或Kubernetes上使用Spark集群。
并且可以访问HDFS、Alluxio、Apache Cassandra、Apache HBase、Apache Hive和数百个其它数据源中的数据
Spark 和Hadoop的区别
1. 综合能力
Spark是一个综合性质的计算引擎
Hadoop既包含MapReduce(计算引擎),还包含HDFS(分布式存储)和Yarn(资源管理)
所以说他们两个的定位是不一样的。
从综合能力上来说,hadoop是完胜spark的
2. 计算模型
Spark 任务可以包含多个计算操作,轻松实现复杂迭代计算
而Hadoop中的MapReduce任务只包含Map和Reduce阶段,不够灵活
从计算模型上来说,spark是完胜hadoop的
3)处理速度
Spark 任务的数据是基于内存的,计算速度很快
而Hadoop中MapReduce 任务是基于磁盘的,速度较慢
从处理速度上来说,spark也是完胜hadoop的
4)spark和Hadoop结合使用
底层是Hadoop的HDFS和YARN
Spark core指的是Spark的离线批处理
Spark Streaming指的是Spark的实时流计算
SparkSQL指的是Spark中的SQL计算
Spark Mlib指的是Spark中的机器学习库,这里面集成了很多机器学习算法
最后这个Spark GraphX是指图计算
其实这里面这么多模块,针对大数据开发岗位主要需要掌握的是Spark core、streaming、sql这几个模块,其中Mlib主要是搞算法的岗位使用的,GraphX这个要看是否有图计算相关的需求,所以这两个不是必须要掌握的
不过由于现在我们主要是学习离线批处理相关的内容,所以会先学习Spark core和Spark SQL
,而Spark streaming等到后面我们讲到实时计算的时候再去学习。
Spark的应用场景Spark主要应用在以下这些应用场景中
1. 低延时的海量数据计算需求,这个说的就是针对Spark core的应用
2. 低延时SQL交互查询需求,这个说的就是针对Spark SQL的应用
3. 准实时(秒级)海量数据计算需求,这个说的就是Spark Streaming的应用