文章目录
- string 类用法介绍及模拟实现
- 一、string介绍
- 二、string类常用接口
- 1. string类对象的常见构造接口
- 2.string类对象的常见容量接口
- 3.string类对象的常见修改接口
- 4. string类对象的常见访问及遍历接口
- 5.string其他接口
- 1.不常用查找接口
- 2.字符替换
- 3.字符串拼接
- 4.字符串排序
- 5.字符串比较
- 6.细看string中某个函数接口的用法
- 三、string类模拟实现及函数解析
- (1)迭代器开始起始位置返回
- (2)构造和拷贝函数
- (3)赋值重载和析构函数
- (4)返回重载和打印打符串
- (5)字符串字符个数和容量大小函数
- (6)字符串比较重载函数
- (7)字符串两类扩容函数
- (8)字符串插入函数和删除函数
- (9)字符串拼接和拼接重载函数
- (10)字符串交换和查找函数及清理函数
- (11)流插入和流提取的重载函数
- 四、string类模拟实现代码
- (1)simulate_string.h
- (2)test.cpp
- (3)运行结果
- 五、深浅拷贝及其他说明
string 类用法介绍及模拟实现
一、string介绍
背景:在C语言中,字符串是以’\0’结尾的一些字符的集合,为了操作方便,C标准库中提供了一些str系列的库函数,但是这些库函数与字符串是分离开的,不太符合OOP的思想,而且底层空间需要用户自己管理,稍不留神可能还会越界访问。这时候就要用到C++的string类。这样就不必担心内存是否足够、字符串长度等。
介绍:string 是 C++ 中常用的一个类,也是C++标准库的重要组成部分,主要用于字符串处理 。string类本不是STL的容器,但是它与STL容器有着很多相似的操作。而且作为一个类出现,他集成的操作函数基本能完成我们大多数情况下的需要。我们可以把它看成是C++的基本数据类型。
另外还要注意这里的头文件是<string>,不是<string.h>,它是C字符串头文件。
关键结论:
string类是basic_string模板类的一个实例,它使用char来实例化basic_string模板类
1.string是表示字符串的字符串类
2.该类的接口与常规容器的接口基本相同,再添加了一些专门用来操作string的常规操作。
3. string在底层实际是:basic_string模板类的别名,typedef basic_string<char, char_traits, allocator>string。
4. 不能操作多字节或者变长字符的序列。
二、string类常用接口
1. string类对象的常见构造接口
string str:生成空字符串
string s(str):生成字符串为str的复制品
string s(str,begin,strlen):将字符串str中从下标begin开始、长度为strlen的部分作为字符串初值
string s(str, len):以str前len个字符串作为字符串s的初值
string s(num ,c):生成num个c字符的字符串
string s(str, x):将字符串str中从下标x开始到字符串结束的位置作为字符串初值
string(const string&s) :拷贝构造函数
string str1; //生成空字符串
string str2("asdf"); //生成"asdf"的复制品
string str3("12345", 1, 4);//结果为"2345"
string str4("012345", 5); //结果为"01234"
string str5(6, 'a'); //结果为"aaaaaa"
string str6(str2, 2); //结果为"df"
string s3(s2); // 拷贝构造s3
2.string类对象的常见容量接口
size: 返回字符串有效字符长度
length :返回字符串有效字符长度
capacity:返回空间总大小
empty :检测字符串释放为空串,是返回true,否则返回false
clear:清空有效字符
reserve:为字符串预留空间,不改变有效元素个数,当reserve的参数小于
string的底层空间总大小时,reserve不会改变容量大小。
resize:将有效字符的个数该成n个,多出的空间用字符填充,不够进行扩容再初始化。删除数据,容量大小不会变。如果将元素个数增多,size会变,可能会改变底层容量的大小。
在扩容的时候vs下是从15开始的,先以二倍进行扩容一次,后面都是以1.5倍进行扩容。
string s("hello nza");
cout << s.size() << endl;//9
cout << s.length() << endl;//9
cout << s.capacity() << endl;//15
s.clear(); // 将s中的字符串清空,注意清空时只是将size清0,不改变底层空间的大小
cout << s << endl;空
cout << s.size() << endl;//0
cout << s.capacity() << endl;//15
s.resize(10, 'a');//将s中有效字符个数增加到10个,多出位置用'a'进行填充
cout << s.size() << endl;//10
cout << s.capacity() << endl;//15
s.resize(16);// 将s中有效字符个数增加到16个,多出位置用缺省值'\0'进行填充,空间原来为15,不够进行扩容
cout << s.size() << endl;//16
cout << s.capacity() << endl;//已扩容
cout << s << endl;
s.resize(5);// 将s中有效字符个数缩小到5个
cout << s.size() << endl;//5
cout << s.capacity() << endl;//31
cout << s << endl;//aaaaa
string s("aaa");
s.reserve(166);//175
cout << s.size() << endl;//3
cout << s.capacity() << endl;//175
s.reserve(50);
cout << s.size() << endl;//3
cout << s.capacity() << endl;//175
}
3.string类对象的常见修改接口
push_back:在字符串后尾插字符c
append:在字符串后追加一个字符串
operator+= :在字符串后追加字符串str
c_str:返回C格式字符串
find: 在当前字符串的pos(默认0)索引位置开始,查找子串s,返回找到的位置索引.
rfind:从字符串pos(默认npos)位置开始往前找字符c,返回该字符在字符串中的位置
substr:在str中从pos位置开始,截取n个字符,然后将其返回
insert(pos,char):在指定的位置pos前插入字符char
iterator erase(iterator p);删除字符串中p所指的字符
iterator erase(iterator first, iterator last):删除字符串中迭代器区间[first,last)上所有字符
string& erase(size_t pos = 0, size_t len = npos):删除字符串中从索引位置pos开始的len个字符
string str;
str.append("hello"); // 在str后追加一个字符"hello"
str += 'n'; // 在str后追加一个字符'n'
str += "za"; // 在str后追加一个字符串"za"
cout << str << endl;//hellonza
cout << str.c_str() << endl; // 以C语言的方式打印hellonza
string f("string.cpp");
size_t pos = f.rfind('.');6
string sub1(f.substr(pos, 3));
cout << sub1<< endl;.cp
string url("http://www.nzanzanza.com/kd/kd/kd/");
size_t start = url.find("://");//4
start += 3;//变为7
size_t finish = url.find('/', start);//24
string address = url.substr(start, finish - start);
cout << address << endl;//www.nzanzanza.com
//插入一个字符
string s("aaaa");
s.insert(1,"555");
cout << s << endl;//a555aaa
string s1("rrrr");
s1.insert(0, 1, 'z');
cout << s1;//zrrrr
string s1("abc");
cout<<s1<<endl; // s1:abc
s1.insert(s1.begin(),'1');// insert(pos,char):在指定的位置pos前插入字符char
cout<<s1<<endl; // s1:1abc
// 尾插一个字符
string s1;
s1.push_back('a');
s1.push_back('b');
s1.push_back('c');
cout<<s1<<endl; // s1:abc
//删除一个字符
string s1 = "123456789";
s1.erase(s1.begin()+1); // 结果:13456789
s1.erase(s1.begin()+1,s1.end()-2); // 结果:189
s1.erase(1,6); // 结果:189
4. string类对象的常见访问及遍历接口
operator[] :返回pos位置的字符,const string类对象调用
begin+ end:(正向迭代器)begin获取一个字符的迭代器 + end获取最后一个字符下一个位置的迭代器
rbegin + rend:(反向迭代器)begin获取一个字符的迭代器 + end获取最后一个字符下一个位置的迭代器
范围for :C++11支持更简洁的范围for的新遍历方式
string s("hello nza");
// 1. for+operator[]
for (size_t i = 0; i < s.size(); ++i)
{
cout << s[i];
}
cout << endl;
// 2.迭代器
string::iterator it = s.begin();
while (it != s.end())
{
cout << *it ;
++it;
}
cout << endl;//hellonza
string::reverse_iterator rit = s.rbegin();
// C++11之后,直接使用auto定义迭代器,让编译器推到迭代器的类型
//auto rit=s.rbegin();
while (rit != s.rend())
{
cout << *rit ;
++rit;
}
cout << endl;//aznolleh
// 3.范围for
for (auto ch : s)
cout << ch;//hellonza
5.string其他接口
1.不常用查找接口
1.size_tfind_first_of (const char* s, size_t pos = 0) const:在当前字符串的pos索引位置开始,查找子串s的字符,返回找到的位置索引,-1表示查找不到字符
2.size_tfind_first_not_of (const char* s, size_t pos = 0) const:在当前字符串的pos索引位置开始,查找第一个不位于子串s的字符,返回找到的位置索引,-1表示查找不到字符
3.size_t find_last_of(const char* s, size_t pos = npos) const:当前字符串的pos索引位置开始,查找最后一个位于子串s的字符,返回找到的位置索引,-1表示查找不到字符
4.size_tfind_last_not_of (const char* s, size_t pos = npos) const:在当前字符串的pos索引位置开始,查找最后一个不位于子串s的字符,返回找到的位置索引,-1表示查找不到子串
string s("ddd bbrb ccccccc bbrb ccc");
cout << s.find_first_of("mmmmbr98") << endl;
// 结果是:4
cout << s.find_first_not_of("hhh ddd ") << endl;
// 结果是:4
cout << s.find_last_of("13r98") << endl;
// 结果是:19
cout << s.find_last_not_of("teac") << endl;
// 结果是:21
2.字符替换
- string& replace(size_t pos, size_t n, const char *s);将当前字符串从pos索引开始的n个字符,替换成字符串s
- string& replace(size_t pos, size_t n, size_t n1, char c); 将当前字符串从pos索引开始的n个字符,替换成n1个字符c
- string& replace(iterator i1, iterator i2, const char* s);将当前字符串[i1,i2)区间中的字符串替换为字符串s
string s1("hello world?");
cout<<s1.size()<<endl; // 结果:12
s1.replace(s1.size()-2,2,3,'.'); // 结果:hello worl...
s1.replace(6,5,"green"); // 结果:hello green.
// s1.begin(),s1.begin()+5 是左闭右开区间
s1.replace(s1.begin(),s1.begin()+5,"red"); // 结果:red green.
cout<<s1<<endl;
3.字符串拼接
append() & + 操作符:拼接字符串
string s1("aaa");
s1.append("bbb");
cout<<"s1:"<<s1<<endl; // s1:aaabbb
// 方法二:+ 操作符
string s2 = "aaa";
string s3 = "bbb";
s2 += s3.c_str();
cout<<s2<<endl; // s2:aaabbb
4.字符串排序
sort(s.begin(),s.end()):排序 (要加#include <algorithm>头文件)
string s = "cdefba";
sort(s.begin(),s.end());
cout<<s<<endl; // 结果:abcdef
5.字符串比较
- C ++字符串支持常见的比较操作符(>,>=,<,<=,==,!=),两个字符串自左向右逐个字符相比(按ASCII值大小相比较),直到出现不同的字符或遇’\0’为止。
cout << (string("1") < string("4")) << endl;//打印为1
string str1("666");
string str2("222");
bool ret;
ret = str1 > str2;
cout << ret << endl; // 1
str1 = "111";
ret = str1 > str2;
cout <<ret << endl; // 0
str1 = "111";
ret = str1 <str2;
cout <<ret<< endl;//1
string s1("fds");
cout << (s1 < "few") << endl;//1
- 第二种用成员函数compare()。支持多参数处理,用索引值和长度定位子串来进行比较。 他返回一个整数来表示比较结果:1表示大于 ,-1表示小于, 0表示相等。
string A("dag");
string B("cvb");
string C("2111");
string D("9850");
cout<< A.compare(B) << endl; // dag和cvbv比较 打印为1
cout << A.compare(1, 1, B) << endl;// 拿A的第一个位置起一个字符和B比较 结果:-1
cout << C.compare(0, 3, D, 0, 3) << endl;//C第0位置前三个字符211和D前三个字符985比较,结果为-1
6.细看string中某个函数接口的用法
可登录www.cplusplus.com查看
三、string类模拟实现及函数解析
(1)迭代器开始起始位置返回
typedef char* iterator;
typedef const char* const_iterator;
iterator begin()
{
return _str;
}
iterator end()
{
return _str + _size;
}
const_iterator begin() const
{
return _str;
}
const_iterator end() const
{
return _str + _size;
}
开始直接返回首元素地址,结束返回的是最后一个元素的下一个位置的地址,另外迭代器还有const类型的,与它构成函数重载。
(2)构造和拷贝函数
string(const char* str = "")
:_size(strlen(str))
{
_capacity = _size == 0 ? 3 : _size;
_str = new char[_capacity + 1];
strcpy(_str, str);
}
string(const string& s)
:_size(s._size)
, _capacity(s._capacity)
{
_str = new char[s._capacity + 1];
strcpy(_str, s._str);
}
1、构造函数:在构造函数里面传常量,那么私有域里面的_str就要加const,就变成在常量区,这样_str就不允许修改,扩容也不扩不了,而这里还需要修改内容,不够还需要扩容,所以最好空间是new出来的,从堆上申请出来的。
2、现在初始化列表就初始化一个_size,因为初始化列表是按private里面的顺序进行初始化,私有域一修改,可能会出现问题,而且用多了strlen,会造成时间浪费,所以后面的开空间和_capacity初始化操作放在里面。capacity+1存的是有效字符。
3、里面并给缺省值,这里面不能给空指针,strlen会对它进行解引用会崩溃,遇到\0终止,也不能’\0‘,类型不匹配,char转变成了int,也会当成空指针,还是一个崩溃,正确写法"\0",这是一个常量字符串,遇到\0终止,长度为0或者写成" "因为默认都是以\0结束的。
4、拷贝构造函数:如果是默认生成是浅拷贝,如果涉及空间问题就得手动写,因为会指向同一个空间,析构两次,会崩溃,修改还会互相影响。所以要有独立的空间,先把size和capacity放在初始化列表,里面开一个和是s.capacity一样大的空间,最后strcpy。
(3)赋值重载和析构函数
string& operator=(const string& s)
{
if (this != &s)
{
char* tmp = new char[s._capacity + 1];
strcpy(tmp, s._str);
delete[] _str;
_str = tmp;
_size = s._size;
_capacity = s._capacity;
}
return *this;
}
~string()
{
delete[] _str;
_str = nullptr;
_size = _capacity = 0;
}
1、赋值重载:赋值同样会涉及到深拷贝和浅拷贝问题,如果被赋值的空间比要赋值的空间大,赋值过去,前者另外的空间会浪费掉,那就先开一个和后者一样大的临时空间,再把旧空间(前者)释放掉,再把开的空间赋值给前者,这样还间接解决了如果被赋值的空间比要赋值的空间小的问题。还有一个问题自己给自己赋值,会出现随机值,因为旧空间释放掉了,会变成随机值,所以加一个if判断语句,如果相等直接返回this。(而且因new失败而破坏旧空间,需要把delete放到new后面)。
2、析构函数:先释放_str,并把它置为空,并把size和capacity置为0。
(4)返回重载和打印打符串
const char* c_str()
{
return _str;
}
const char& operator[](size_t pos) const
{
assert(pos < _size);
return _str[pos];
}
char& operator[](size_t pos)
{
assert(pos < _size);
return _str[pos];
}
1、打印字符串,直接返回首地址,进行打印。
2、返回值重载:为了能让实例化的对象进行[]访问元素,进行赋值重载,为了防止越界,需要断言一下,返回_str数组对应的下标元素。为了适应传来的const对象并能够进行顺利返回,需要进行函数重载。
(5)字符串字符个数和容量大小函数
size_t size() const
{
return _size;
}
size_t capacity() const
{
return _capacity;
}
1、字符个数:直接返回_size,因为实例化对象调用构造函数就算出来_size。
2、容量大小:同理。
(6)字符串比较重载函数
bool operator>(const string& s) const
{
return strcmp(_str, s._str) > 0;
}
bool operator==(const string& s) const
{
return strcmp(_str, s._str) == 0;
}
bool operator>=(const string& s) const
{
return *this > s || s == *this;
}
bool operator<(const string& s) const
{
return !(*this >= s);
}
bool operator<=(const string& s) const
{
return !(*this > s);
}
bool operator!=(const string& s) const
{
return !(*this == s);
}
1、字符串比较重载函数: 为了能让对象进行比较,进行比较重载,先写出两个>,==,里面直接调用strcmp,其余的进行复用。
(7)字符串两类扩容函数
void resize(size_t n, char ch = '\0')
{
if (n < _size)
{
// 删除数据--保留前n个
_size = n;
_str[_size] = '\0';
}
else if (n > _size)
{
if (n > _capacity)
{
reserve(n);
}
size_t i = _size;
while (i < n)
{
_str[i] = ch;
++i;
}
_size = n;
_str[_size] = '\0';
}
}
void reserve(size_t n)
{
if (n > _capacity)
{
char* tmp = new char[n + 1];
strcpy(tmp, _str);
delete[] _str;
_str = tmp;
_capacity = n;
}
}
1、resize扩容函数:它的特点是开空间初始化,size会随传入的n的大小而变化,如果是<当前的_size会删除数据,反之会补充剩余的字符。用一个if esle语句去解决,如果小于就把_size更新成n,并把最后一个位置置为0,else里面需要看是否扩容,如果需要直接复用reserve,反之用while循环进行插入,最后更新_size。
2、reserve扩容函数: 它的特点是提前开好空间,size不会变,如果传入的n大于当前容量,就异地扩,开辟另一个空间,把_str的内容赋值过去,再释放掉_str,然后把tmp重新赋给_str,再更新容量。
(8)字符串插入函数和删除函数
void push_back(char ch)
{
/*if (_size + 1 > _capacity)
{
reserve(_capacity * 2);
}
_str[_size] = ch;
++_size;
_str[_size] = '\0';*/
insert(_size, ch);
}
void push_back(const char* str)
{
insert(_size, str);
}
string& insert(size_t pos, char ch)
{
assert(pos <= _size);
if (_size + 1 > _capacity)
{
reserve(2 * _capacity);
}
size_t end = _size + 1;
while (end > pos)
{
_str[end] = _str[end - 1];
--end;
}
_str[pos] = ch;
++_size;
return *this;
}
string& insert(size_t pos, const char* str)
{
assert(pos <= _size);
size_t len = strlen(str);
if (_size + len > _capacity)
{
reserve(_size + len);
}
// 挪动数据
size_t end = _size + len;
while (end > pos + len - 1)
{
_str[end] = _str[end - len];
--end;
}
// 拷贝插入
strncpy(_str + pos, str, len);
_size += len;
return *this;
}
string& erase(size_t pos, size_t len = npos)
{
assert(pos < _size);
if (len == npos || pos + len >= _size)
{
_str[pos] = '\0';
_size = pos;
}
else
{
strcpy(_str + pos, _str + pos + len);
_size -= len;
}
return *this;
}
1、**push_back函数:**尾插插入用常规思路去写,如果需要扩容,就reserve,反之就进行尾插赋值,最后一个位置置为\0。
第二种就复用insert,因为它是在pos位置前面插入,所以只需要传最后一个位置的参数即可,也就是在\0前面插入就形成了尾插效果。另外为了方便进行字符串尾插,进行函数重载一下即可。
2、insert函数:
插入字符:先看是否能扩容,接下来就是挪动,一般是从最后一个位置开始挪动加上while(end>=pos)条件,可结果出错,这里的end是无符号,无符号end再–,减到-1,被当成全1,是无符号最大值,造成错误,同样这里也不能改成int,因为会发生隐式转换,有符号变成无符号,除非上面参数pos也改成int,就能解决或者把pos强转int。但是这是模拟实现,下标都常用无符号。
解决:可以把end位置往后挪一位,也即从最后一个位置的下一个位置开始挪动。把end-1的数赋给end,这样end等于pos的时候就停止,而且第一个位置也已经被挪动。就能成功运行。再进行赋值并更新_size。
插入字符串 :大致思路和上面一样,注意的是终止条件并不是pos位置,如果是pos位置的话会发生越界,因为字符串已经挪完,end还没有到pos,end是从end+len的位置开始的。所以这里应该是挪完的时候在pos+len,停的位置就再减一。最后空出的位置直接进行字符串拷贝,更新_size。
3、erase函数: 删除分为两种情况,一种是pos+len长度大于等于size,意思是把pos位置之后的全删掉,那就把pos位置置为\0,在更新_size。
第二种是长度小于size,就把后面的数据往前挪动,可以用拷贝函数进行从前往后覆盖,直接注意的是len == npos要单独写,否则会溢出,因为如果n是npos,已经是最大值了,再加就会绕回去,所以防止用缺省值和pos相加出错,分开来写。
(9)字符串拼接和拼接重载函数
void append(const char* str)
{
//size_t len = strlen(str);
//if (_size+len > _capacity)
//{
// reserve(_size + len);
//}
strcat(_str, str);
//_size += len;
insert(_size, str);
}
string& operator+=(char ch)
{
push_back(ch);
return *this;
}
string& operator+=(const char* str)
{
push_back(str);
//append(str);
return *this;
}
1、append拼接函数:两种方法,一种是算长度,看是否要扩容,然后直接调用字符串追加函数strcat进行追加,另一种是复用insert。
2、拼接重载函数:字符重载函数,直接复用push_back,字符串重载函数复用append和push_back都可行。
(10)字符串交换和查找函数及清理函数
void swap(string& s)
{
std::swap(_str, s._str);
std::swap(_capacity, s._capacity);
std::swap(_size, s._size);
}
size_t find(char ch, size_t pos = 0)
{
assert(pos < _size);
for (size_t i = pos; i < _size; ++i)
{
if (_str[i] == ch)
{
return i;
}
}
return npos;
}
size_t find(const char* str, size_t pos = 0)
{
assert(pos < _size);
char* p = strstr(_str + pos, str);
if (p == nullptr)
{
return npos;
}
else
{
return p - _str;
}
}
void zero()
{
_str[0] = '\0';
_size = 0;
}
1、交换函数
string库里面的交换函数是void swap(string& x, string& y),里面需要创建临时变量进行赋值,发生了三次深拷贝,而这模拟实现可以是void swap(string& s),在里面调用C++标准库里面的swap把三个成员换一下就可以,效率可以提升很多。
2、查找函数:对于字符查找函数,用for循环进行遍历,如果找了就返回下标,否则返回npos。
对于字符串查找函数,直接调用子串搜索函数并返回它的首地址,如果找不到返回npos,否则返回它的地址减去首地址。
3、清0函数:把size的位置置为\0,并把size置为0和流插入函数结合用。
(11)流插入和流提取的重载函数
ostream& operator<<(ostream& out, const string& s)
{
for (auto ch : s)
{
out << ch;
}
return out;
}
istream& operator>>(istream& in, string& s)
{
s.zero();
char ch = in.get();
char tmp[128];
size_t i = 0;
while (ch != ' ' && ch != '\n')
{
tmp[i++] = ch;
if (i == 127)
{
tmp[127] = '\0';
s += tmp;
i = 0;
}
ch = in.get();
}
if (i != 0)
{
tmp[i] = '\0';
s += tmp;
}
return in;
}
这两个函数不能写到里成员函数,因为this指针就把第一个位置抢了,cout做不了第一个左操作数,得写成全局,不一定要用友元函数。
流插入函数: 直接cout<<s,和cout<<c_str,有区别,后者遇到\0停止,里面直接用for循环进行打印。
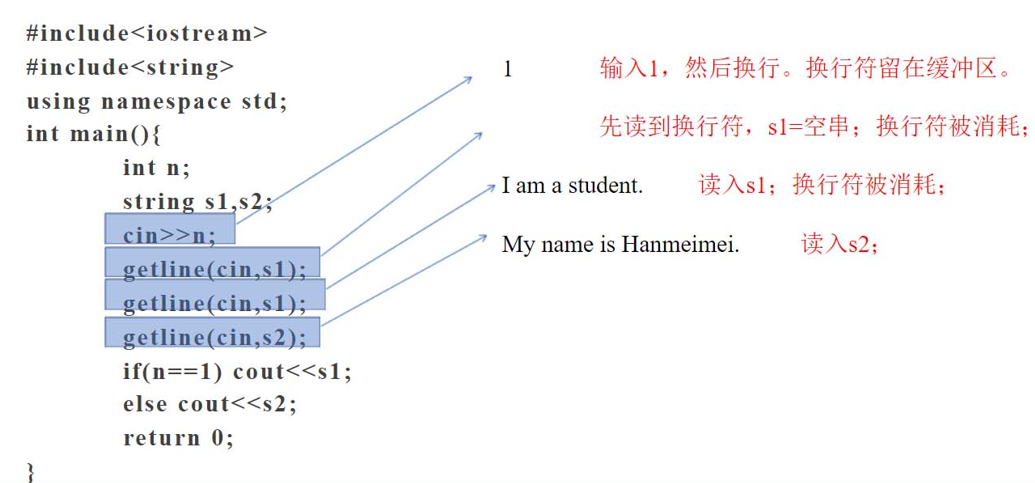
流提取函数:1、C/C++规定输入多个字符,会把\n和空格当成多个字符之间的间隔,cin流对象缓冲区会拿不到\n和空格,用get就不会把它两当成间隔,把它们拿到,wihle就能终止。
2、流提取前要清理一下,设置\0,防止出现乱码。
3、如果插入的字符串很长啊,+=会频繁扩容,先创建一个tmp临时数组,输入一个字符,填到数组里,如果快要填满的时候,就在最后填上\0,把这个数组加到s上去,i置为0。每满一次往s上加。如果最后i不等于0,就直接就把tmp i的位置置为\0,最后还要判断一下i是否为0,如果不为0,说明tmp里面还没有加进去完。
四、string类模拟实现代码
(1)simulate_string.h
#pragma once
#include<assert.h>
namespace mould
{
class string
{
public:
typedef char* iterator;
typedef const char* const_iterator;
iterator begin()
{
return _str;
}
iterator end()
{
return _str + _size;
}
const_iterator begin() const
{
return _str;
}
const_iterator end() const
{
return _str + _size;
}
string(const char* str = "")
:_size(strlen(str))
{
_capacity = _size == 0 ? 3 : _size;
_str = new char[_capacity + 1];
strcpy(_str, str);
}
string(const string& s)
:_size(s._size)
, _capacity(s._capacity)
{
_str = new char[s._capacity + 1];
strcpy(_str, s._str);
}
// s1 = s3;
// s1 = s1;
string& operator=(const string& s)
{
if (this != &s)
{
char* tmp = new char[s._capacity + 1];
strcpy(tmp, s._str);
delete[] _str;
_str = tmp;
_size = s._size;
_capacity = s._capacity;
}
return *this;
}
~string()
{
delete[] _str;
_str = nullptr;
_size = _capacity = 0;
}
const char* c_str()
{
return _str;
}
const char& operator[](size_t pos) const
{
assert(pos < _size);
return _str[pos];
}
char& operator[](size_t pos)
{
assert(pos < _size);
return _str[pos];
}
size_t size() const
{
return _size;
}
size_t capacity() const
{
return _capacity;
}
// 不修改成员变量数据的函数,最好都加上const
bool operator>(const string& s) const
{
return strcmp(_str, s._str) > 0;
}
bool operator==(const string& s) const
{
return strcmp(_str, s._str) == 0;
}
bool operator>=(const string& s) const
{
return *this > s || s == *this;
}
bool operator<(const string& s) const
{
return !(*this >= s);
}
bool operator<=(const string& s) const
{
return !(*this > s);
}
bool operator!=(const string& s) const
{
return !(*this == s);
}
void resize(size_t n, char ch = '\0')
{
if (n < _size)
{
// 删除数据--保留前n个
_size = n;
_str[_size] = '\0';
}
else if (n > _size)
{
if (n > _capacity)
{
reserve(n);
}
size_t i = _size;
while (i < n)
{
_str[i] = ch;
++i;
}
_size = n;
_str[_size] = '\0';
}
}
void reserve(size_t n)
{
if (n > _capacity)
{
char* tmp = new char[n + 1];
strcpy(tmp, _str);
delete[] _str;
_str = tmp;
_capacity = n;
}
}
void push_back(char ch)
{
insert(_size, ch);
}
void push_back(const char* str)
{
insert(_size, str);
}
void append(const char* str)
{
insert(_size, str);
}
string& operator+=(char ch)
{
push_back(ch);
return *this;
}
string& operator+=(const char* str)
{
append(str);
return *this;
}
string& insert(size_t pos, char ch)
{
assert(pos <= _size);
if (_size + 1 > _capacity)
{
reserve(2 * _capacity);
}
size_t end = _size + 1;
while (end > pos)
{
_str[end] = _str[end - 1];
--end;
}
_str[pos] = ch;
++_size;
return *this;
}
string& insert(size_t pos, const char* str)
{
assert(pos <= _size);
size_t len = strlen(str);
if (_size + len > _capacity)
{
reserve(_size + len);
}
// 挪动数据
size_t end = _size + len;
while (end > pos + len - 1)
{
_str[end] = _str[end - len];
--end;
}
// 拷贝插入
strncpy(_str + pos, str, len);
_size += len;
return *this;
}
string& erase(size_t pos, size_t len = npos)
{
assert(pos < _size);
if (len == npos || pos + len >= _size)
{
_str[pos] = '\0';
_size = pos;
}
else
{
strcpy(_str + pos, _str + pos + len);
_size -= len;
}
return *this;
}
void swap(string& s)
{
std::swap(_str, s._str);
std::swap(_capacity, s._capacity);
std::swap(_size, s._size);
}
size_t find(char ch, size_t pos = 0)
{
assert(pos < _size);
for (size_t i = pos; i < _size; ++i)
{
if (_str[i] == ch)
{
return i;
}
}
return npos;
}
size_t find(const char* str, size_t pos = 0)
{
assert(pos < _size);
// kmp
char* p = strstr(_str + pos, str);
if (p == nullptr)
{
return npos;
}
else
{
return p - _str;
}
}
void zero()
{
_str[0] = '\0';
_size = 0;
}
private:
char* _str;
size_t _capacity;
size_t _size;
static const size_t npos;
};
const size_t mould::string::npos = -1;
}
(2)test.cpp
#include<iostream>
#include"simulate_string.h"
using namespace std;
void Print(const mould:: string& s)
{
for (size_t i = 0; i < s.size(); ++i)
{
cout << s[i] ;
}
cout << endl;
mould::string::const_iterator it = s.begin();
while (it != s.end())
{
//*it = 'x';
++it;
}
for (auto ch : s)
{
cout << ch ;
}
}
ostream& operator<<(ostream& out, const string& s)
{
for (auto ch : s)
{
out << ch;
}
return out;
}
istream& operator>>(istream& in, string& s)
{
s.clear();
char ch = in.get();
char tmp[128];
size_t i = 0;
while (ch != ' ' && ch != '\n')
{
tmp[i++] = ch;
if (i == 127)
{
tmp[127] = '\0';
s += tmp;
i = 0;
}
ch = in.get();
}
if (i != 0)
{
tmp[i] = '\0';
s += tmp;
}
return in;
}
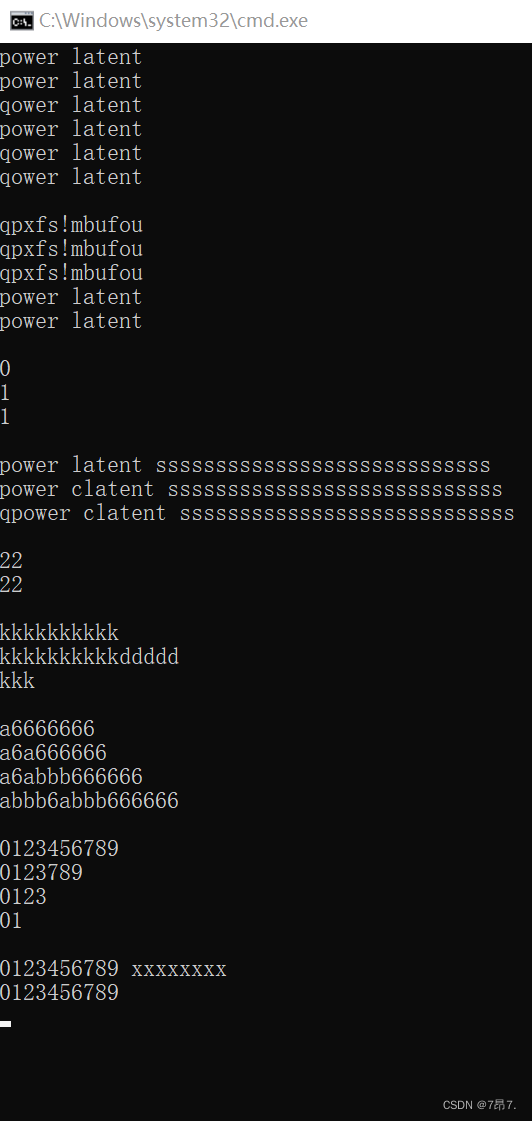
void _string1()
{
mould::string s1("power latent");
cout << s1.c_str() << endl;
s1[0]++;
cout << s1.c_str() << endl;
cout << endl;
}
void _string2()
{
mould::string s2("power latent");
mould::string s3(s2);
mould::string s1;
cout << s2.c_str() << endl;
cout << s3.c_str() << endl;
s2[0]++;
cout << s2.c_str() << endl;
cout << s3.c_str() << endl;
s1 = s2;
cout << s1.c_str() << endl;
cout << s2.c_str() << endl;
cout << endl;
}
void _string3()
{
mould::string s1("power latent");
for (size_t i = 0; i < s1.size(); ++i)
{
s1[i]++;
}
for (size_t i = 0; i < s1.size(); ++i)
{
cout << s1[i];
}
cout << endl;
Print(s1);
mould::string::iterator it = s1.begin();
while (it != s1.end())
{
(*it)--;
++it;
}
cout << endl;
it = s1.begin();
while (it != s1.end())
{
cout << *it ;
++it;
}
cout << endl;
for (auto ch : s1)
{
cout << ch ;
}
cout << endl;
cout << endl;
}
void _string4()
{
mould::string s1("power latent");
mould::string s2("power latent");
mould::string s3("aa");
cout << (s1 < s2) << endl;
cout << (s1 == s2) << endl;
cout << (s1 >= s2) << endl;
cout << endl;
}
void _string5()
{
mould::string s1("power latent");
s1 += ' ';
s1 += "ssssssssssssssssssssssssssss";
cout << s1.c_str() << endl;
s1.insert(6, 'c');
cout << s1.c_str() << endl;
s1.insert(0, 'q');
cout << s1.c_str() << endl;
cout << endl;
}
void _string6()
{
mould::string s1("hello world66666666666");
cout << s1.capacity() << endl;
s1.reserve(10);
cout << s1.capacity() << endl;
cout << endl;
}
void _string7()
{
mould::string s1;
s1.resize(10, 'k');
cout << s1.c_str() << endl;
s1.resize(15, 'd');
cout << s1.c_str() << endl;
s1.resize(3);
cout << s1.c_str() << endl;
cout << endl;
}
void _string8()
{
mould::string s1("6666666");
s1.insert(0, 'a');
cout << s1.c_str() << endl;
s1.insert(2, 'a');
cout << s1.c_str() << endl;
s1.insert(3, "bbb");
cout << s1.c_str() << endl;
s1.insert(1, "bbb");
cout << s1.c_str() << endl;
cout << endl;
}
void _string9()
{
mould::string s1("0123456789");
cout << s1.c_str() << endl;
s1.erase(4, 3);
cout << s1.c_str() << endl;
s1.erase(4, 30);
cout << s1.c_str() << endl;
s1.erase(2);
cout << s1.c_str() << endl;
cout << endl;
}
void _string10()
{
string s1("0123456789");
s1 += '\0';
s1 += "xxxxxxxx";
cout<<s1<<endl ;
cout<<s1.c_str() << endl;
string s2;
cin>>s2;
cout<<s2<< endl;
cin>>s1;
cout<<s1<< endl;
}
int main()
{
_string1();
_string2();
_string3();
_string4();
_string5();
_string6();
_string7();
_string8();
_string9();
_string10();
return 0;
}
(3)运行结果
五、深浅拷贝及其他说明
浅拷贝:也叫位拷贝,编译器只是将对象中的值拷贝过来。如果对象中管理资源,最后就会导致多个对象共享同一份资源,当一个对象销毁时就会将该资源释放掉,而此时另一些对象不知道该资源已经被释放,以为还在,所以当继续对资源进项操作时,就会发生发生了非法访问。
深拷贝:可以用深拷贝解决浅拷贝问题,每个对象都有一份独立的资源,不要和其他对象共享,如果一个类中涉及到资源的管理,其拷贝构造函数、赋值运算符重载以及析构函数必须要显式给出。保证多个对象不会因共享资源造成多次释放造成程序崩溃问题。
vs下string的结构:
string总共占28个字节,内部结构复杂。
1、先是有一个联合体,联合体用来定义string中字符串的存储空间:当字符串长度小于16时,使用内部固定的字符数组来存放,当字符串长度大于等于16时,从堆上开辟空间。
2、Mysize存字符串有效长度。
3、Myres存空间容量。
4、还有一个指针。
g++下string的结构:g++下,string是通过写时拷贝实现的,string对象总共占4个字节(64位下是8个字节),内部只包含了一个指针,该指针将来指向一块堆空间,内部包含了如下字段:
1、空间总大小
2、字符串有效长度
3、引用计数