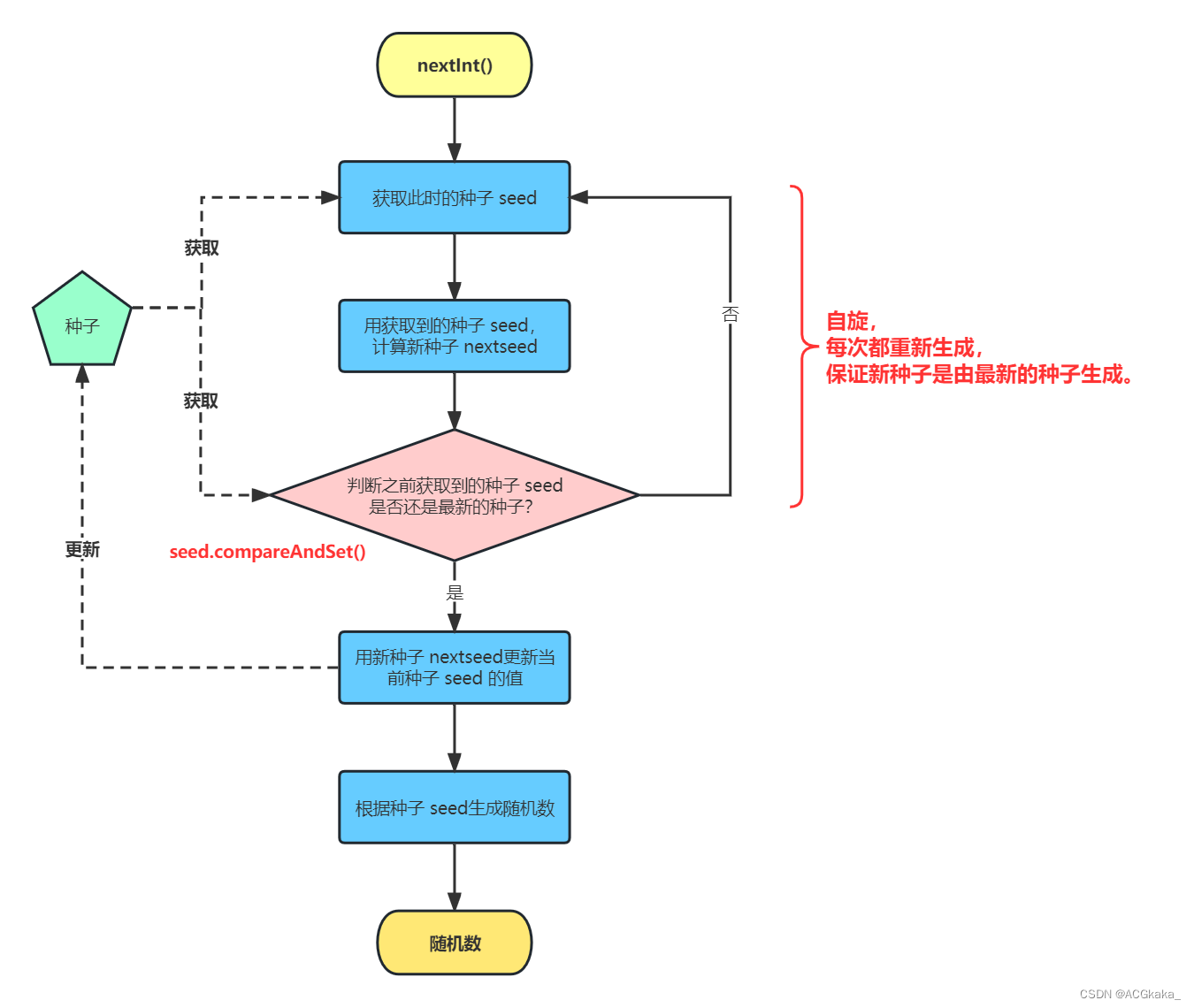
订单ID不能采用自增长的原因:
1、规律变化太明显。两天下单的ID的差值,能够计算出商城的订单量;
2、如果采用自增长,订单数据是会不断产生的,到时候要分表,但是每个表的ID都是从0开始增长的,这样ID就重复了。
全局ID生成器:
分布式系统环境下,用来生成全局唯一ID的工具。
1、唯一性;有个increment的特性;
2、高可用;能搭建集群
3、高性能;基于内存,效率高
4、递增型;【有利于数据库创建索引,提高数据库的查询速度】
5、安全性;
符号位:1bit,永远是0,代表正数;
时间戳:31bit,以秒为单位,可以使用69年;
序列号:32bit(Redis的递增值) 支持每秒产生2^32个ID【42亿】
Redis实现全局唯一生成器
package com.hmdp.utils;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.data.redis.core.StringRedisTemplate;
import org.springframework.stereotype.Component;
import java.time.LocalDateTime;
import java.time.ZoneOffset;
import java.time.format.DateTimeFormatter;
@Component
public class RedisIdWorker {
/**
* 开始时间戳
*/
private static final long BEGIN_TIMESTAMP = 1676037454L;
/**
* 序列号的位数【32个比特位】 2^32=40亿
*/
private static final int COUNT_BITS = 32;
@Autowired
private StringRedisTemplate stringRedisTemplate;
public long nextId(String keyPrefix) {
// 1.生成时间戳【秒时间戳】
LocalDateTime now = LocalDateTime.now();
long nowSecond = now.toEpochSecond(ZoneOffset.UTC);
long timestamp = nowSecond - BEGIN_TIMESTAMP;
// 2.生成序列号
// 2.1.获取当前日期,精确到天
String date = now.format(DateTimeFormatter.ofPattern("yyyy:MM:dd"));
// 2.2.自增长 【大概是每天40亿的上限】
long count = stringRedisTemplate.opsForValue().increment("icr:" + keyPrefix + ":" + date);
// 3.拼接并返回 【0 永远是第一位 31位的时间戳 32位的订单ID自增长】
return timestamp << COUNT_BITS | count;
}
}
有些优惠券需要买,比如说美团红包。8元人民币买10元的红包。
tb_voucher:优惠券的基本信息,优惠金额、使用规则等。
有些优惠券需要抢【秒杀】,比如说政府为刺激消费,发放的汽车消费券,是有限的。
tb_seckill_voucher:优惠券的库存、开始抢购时间,结束抢购时间。特价优惠券才需要填写这些信息。
抢购秒杀券时,需要判断
1、秒杀是否开始和结束
2、库存是否充足
【1、根据前端提交的优惠券id,获取优惠券信息】
【2、如果秒杀场景正确,可以考虑减库存。这里应该要使用到事务】
【3、创建订单信息给前端,让其支付】
基本下单和秒杀下单
**【超卖】**使用JMeter压测后,库存本来是100的,结果成了负数。新建的订单量竟然大于库存量,这就是在高并发环境的出现的情况。
需要加锁来解决。
1、悲观锁
认为线程安全问题一定会发生,因此在操作数据之前,先获取锁,确保线程串行执行。
例如:Synchronized、Lock都属于悲观锁。性能差了点,高并发环境下并不是很适合。
2、乐观锁【更新数据】
认为线程安全问题不一定会发生。只有在数据更新时,才会判断有没有其他线程对数据进行了修改。如果没有修改,则认为是安全的,自己才更新数据;如果数据已经被其他线程修改,则说明发生了安全性问题,此时可以重试或者是抛出异常。【对于要修改的数据,有一个版本号,如果查询出来的版本和where 筛选的版本号码一致,则可以进行修改,实际上是不加锁的。】
用数据本身有没有变化,来作为是否修改的条件。版本号,用数据本身来代替,简化了操作。CAS方案
弊端:虽然没有发生了超卖,但是优惠券抢购,只发生了21次,但是一共是100的库存量呀。
原因:多线程条件下,库存量快速变化,导致的其它线程,发生了扣减失败的情况,但是不出错。【成功率太低,没有业务上的安全问题】
where id = ? and stock = ? ==========》 where id = ? and stock > 0
防止请求对数据库的压力
一人一单,规避黄牛【新增数据】
做一个查询,如果表中存在,就不允许下单了。
出现的问题:并发环境下,库存竟然少了10,订单量一个人竟然有10单。虽然做了一人一单的判断,但是多线程环境下不管用。
还是那个并发安全问题,只能使用悲观锁方案。
从查询订单,到判断,到新增,做一个封装。
应该是先提交事务之后,再进行锁的释放。
如果先进行锁的释放,事务如果没有提交的话,下一个线程来查询时,还是出问题。
this.createVouther();this拿到的是service的对象,而spring的事务要想生效,是对当前service类对象做了代理,用代理对象做了事务处理。
所以使用类对象,可能会使得事务不生效。
1、添加依赖aspectjweaver
2、@EnableAspectJAutoProxy(exposeProxy = true);
通过加锁,可以解决在单体项目下的问题,那么如何解决多实例下的并发安全问题呢?
多体项目并发安全性问题

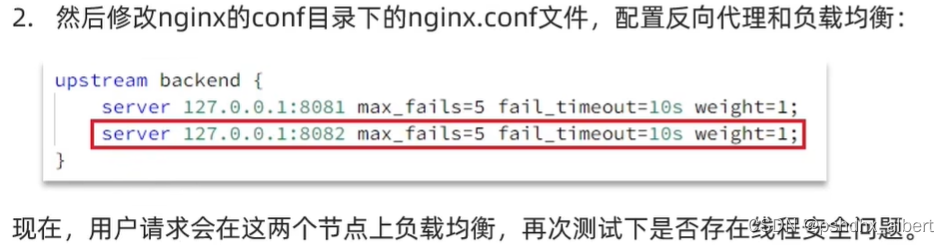
选择好左下角的服务,ctrl+D之后,修改端口-Dserver.port=8082
Redis的分布式锁实现多实例并发安全
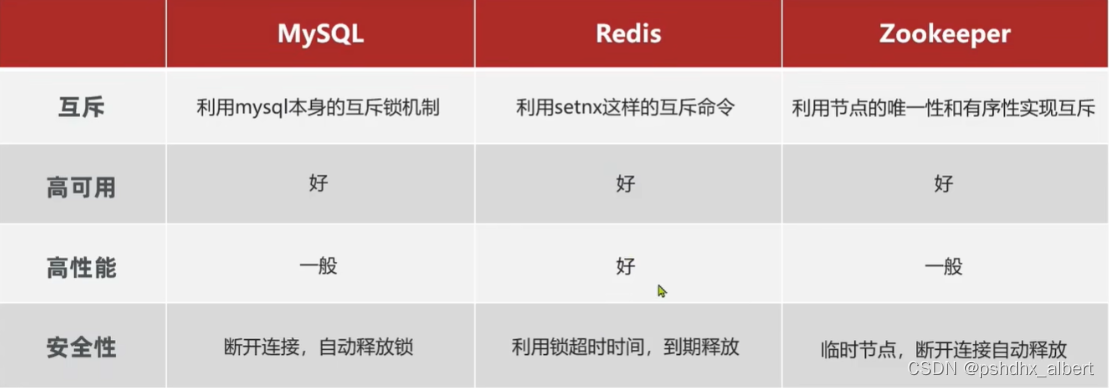
分布式锁:满足分布式系统或集群模式下多线程可见,并且互斥的锁。
多进程可见:【独立于JVM】
互斥:【只有一个人能获取到】
高可用:【不能获取锁的动作经常出问题】
高性能:【加锁本身呢,会影响业务的性能,串行执行会变慢】
安全性:【锁获取了,异常挂了怎么办,产生死锁怎么处理呢】
Redis实现最简单的分布式锁
利用redis作为第三方中间件,给分布式项目的服务加锁。
public interface ILock {
/**
* 尝试获取锁
* @param timeoutSec 锁持有的超时时间,过期后自动释放
* @return true代表获取锁成功; false代表获取锁失败
*/
boolean tryLock(long timeoutSec);
/**
* 释放锁
*/
void unlock();
}
package com.pshdhx.utils;
import cn.hutool.core.lang.UUID;
import org.springframework.core.io.ClassPathResource;
import org.springframework.data.redis.core.StringRedisTemplate;
import org.springframework.data.redis.core.script.DefaultRedisScript;
import java.util.Collections;
import java.util.concurrent.TimeUnit;
public class SimpleRedisLock implements ILock {
private String name;
private StringRedisTemplate stringRedisTemplate;
private static final String KEY_PREFIX = "lock:";
private static final String ID_PREFIX = UUID.randomUUID().toString(true) + "-";
public SimpleRedisLock(String name, StringRedisTemplate stringRedisTemplate) {
this.name = name;
this.stringRedisTemplate = stringRedisTemplate;
}
@Override
public boolean tryLock(long timeoutSec) {
// 获取线程标示
String threadId = ID_PREFIX + Thread.currentThread().getId();
// 获取锁
Boolean success = stringRedisTemplate.opsForValue()
.setIfAbsent(KEY_PREFIX + name, threadId, timeoutSec, TimeUnit.SECONDS);
return Boolean.TRUE.equals(success);
}
//删除自己线程的锁,不能因为本线程阻塞处理完成后(自己的锁过期了),删除别的线程的锁。
@Override
public void unlock() {
// 获取线程标示
String threadId = ID_PREFIX + Thread.currentThread().getId();
// 获取锁中的标示
String id = stringRedisTemplate.opsForValue().get(KEY_PREFIX + name);
// 判断标示是否一致
if(threadId.equals(id)) {
// 释放锁
stringRedisTemplate.delete(KEY_PREFIX + name);
}
}
}
直接使用线程的ID作为锁的值,是不合适的,线程ID值是递增的,因为多个JVM的线程号可能会相同。
Redis的分布式锁的原子性问题
如果在释放锁的过程中,发生了FullGC,然后释放锁的过程被阻塞,该锁超时自动释放了。则其余线程能够正常获取锁,此时阻塞的线程恢复了,把其余线程获取的锁给释放了,所以要保证释放锁的原子性。
Redis的事务可以保证其原子性,但是无法保证其一致性。而且事务里边的多个操作,是个批处理,是最终一次性执行。
所以使用Lua脚本来执行。
Redis提供了Lua脚本功能,在一个脚本中编写多条Redis命令,确保多条命令执行时的原子性。Lua是一种编程语言,它的基本语法可以参考
www.runoob.com/lua/lua-tutorial.html
在Shell中执行:
EVAL “return redis.call(‘set’,‘name’,‘jack’)” 0个参数
EVAL “return redis.call(‘set’,KEYS[1],ARGV[1])” 1 name Rose
unlock.lua 放入到resources里边
-- 比较线程标示与锁中的标示是否一致
if(redis.call('get', KEYS[1]) == ARGV[1]) then
-- 释放锁 del key
return redis.call('del', KEYS[1])
end
return 0
改进Redis的分布式锁
需求:基于Lua脚本实现分布式锁的释放锁逻辑
提示:RedisTemplate调用Lua脚本的api如下:
public <T> T execute(RedisScript<T> script, List<K> keys, Object... args) {
return this.scriptExecutor.execute(script, keys, args);
}
package com.pshdhx.utils;
import cn.hutool.core.lang.UUID;
import org.springframework.core.io.ClassPathResource;
import org.springframework.data.redis.core.StringRedisTemplate;
import org.springframework.data.redis.core.script.DefaultRedisScript;
import java.util.Collections;
import java.util.concurrent.TimeUnit;
public class SimpleRedisLock implements ILock {
private String name;
private StringRedisTemplate stringRedisTemplate;
public SimpleRedisLock(String name, StringRedisTemplate stringRedisTemplate) {
this.name = name;
this.stringRedisTemplate = stringRedisTemplate;
}
private static final String KEY_PREFIX = "lock:";
private static final String ID_PREFIX = UUID.randomUUID().toString(true) + "-";
private static final DefaultRedisScript<Long> UNLOCK_SCRIPT;
static {
UNLOCK_SCRIPT = new DefaultRedisScript<>();
UNLOCK_SCRIPT.setLocation(new ClassPathResource("unlock.lua"));
UNLOCK_SCRIPT.setResultType(Long.class);
}
@Override
public boolean tryLock(long timeoutSec) {
// 获取线程标示
String threadId = ID_PREFIX + Thread.currentThread().getId();
// 获取锁
Boolean success = stringRedisTemplate.opsForValue()
.setIfAbsent(KEY_PREFIX + name, threadId, timeoutSec, TimeUnit.SECONDS);
return Boolean.TRUE.equals(success);
}
@Override
public void unlock() {
// 调用lua脚本
stringRedisTemplate.execute(
UNLOCK_SCRIPT,
Collections.singletonList(KEY_PREFIX + name),
ID_PREFIX + Thread.currentThread().getId());
}
/*@Override
public void unlock() {
// 获取线程标示
String threadId = ID_PREFIX + Thread.currentThread().getId();
// 获取锁中的标示
String id = stringRedisTemplate.opsForValue().get(KEY_PREFIX + name);
// 判断标示是否一致
if(threadId.equals(id)) {
// 释放锁
stringRedisTemplate.delete(KEY_PREFIX + name);
}
}*/
}
核心代码
private static final DefaultRedisScript<Long> UNLOCK_SCRIPT;
static {
UNLOCK_SCRIPT = new DefaultRedisScript<>();
UNLOCK_SCRIPT.setLocation(new ClassPathResource("unlock.lua"));
UNLOCK_SCRIPT.setResultType(Long.class);
}
@Override
public void unlock() {
// 调用lua脚本
stringRedisTemplate.execute(
UNLOCK_SCRIPT,
Collections.singletonList(KEY_PREFIX + name),
ID_PREFIX + Thread.currentThread().getId());
}
不可重入锁
方法A获取了锁,然后去调用方法B,此时,方法B也想要获取锁,但是无法获取了。
不可重入:同一个线程无法多次获取同一把锁。
不可重试:尝试锁只尝试获取一次就返回false,没有重试机制。
超时释放:锁超时释放虽然可以避免死锁,但是如果业务执行耗时长,也会导致锁的释放,存在一定的安全隐患。
主从一致性【读写分离】:如果Redis提供了主从集群,主从同步存在延迟。在主节点set操作获取了锁,尚未同步到从节点,突然主节点宕机,选择新的从节点作为主,但是从节点没有锁,所以新的线程会重新set锁。
Redisson
提供了一系列分布式的常用对象,还提供了许多分布式服务,其中就包括了各种分布式锁的实现。
1、可重入锁
2、公平锁
3、联锁
4、红锁
5、读写锁
6、信号量
7、可过期性信号量
8、闭锁
可重入锁原理:
使用了哈希值的方式,进行可重入锁的是设计。但凡是在一个线程之中,无论是里边有多少个业务方法要获取锁,只管将对应的value值加一即可;如果需要释放锁,则将value值减一即可。如果减到了0,则进行锁的删除操作。
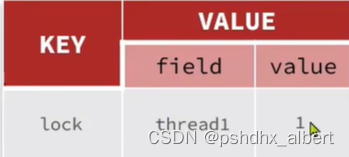
value值不断的增加,只要是同一个线程想要获取锁,value值就+1,【记得重置下有效期】
释放锁操作,就减1,如果减为0,则可以删除这把锁了。
local key = KEYS[1]; --锁的key
local threadId = ARGV[1]; -- 线程唯一标识
local releaseTime = ARGV[2]; --锁的自动释放时间
--判断当前锁是否还是被自己持有
if(redis.call('HEXISTS',key,threadId) == 0) then
return nil; --如果不是自己,则直接返回
end;
-- 是自己的锁,则重入次数-1
local count = redis.call('HINCRBY',key,threadId,-1);
if(count > 0) then
redis.call('Expire',key,releaseTime);
return nil;
else
redis.call('del',key);
return nil;
end;
1、重试机制
2、超时释放,此时业务未完成;
3、主从一致性问题;
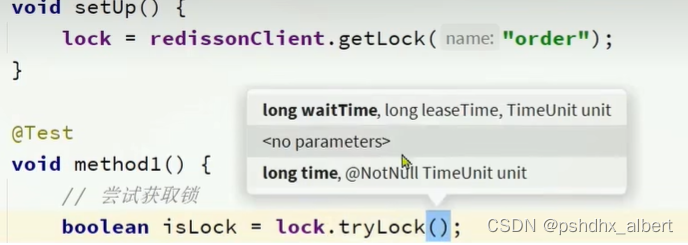
waitTime:获取锁的最大等待时长。第一次获取锁失败后,不会立即返回,而是在最大等待时间内不断的尝试获取锁。如果在最大等待时间内,还没有获取锁,则返回false。
leaseTime:存活时间
TimeUnit:时间单位
分布式锁默认的超时释放时间-看门狗
private <T> RFuture<Long> tryAcquireAsync(long waitTime, long leaseTime, TimeUnit unit, long threadId) {
if (leaseTime != -1L) {
return this.tryLockInnerAsync(waitTime, leaseTime, unit, threadId, RedisCommands.EVAL_LONG);
} else {
RFuture<Long> ttlRemainingFuture = this.tryLockInnerAsync(waitTime, this.commandExecutor.getConnectionManager().getCfg().getLockWatchdogTimeout(), TimeUnit.MILLISECONDS, threadId, RedisCommands.EVAL_LONG);
ttlRemainingFuture.onComplete((ttlRemaining, e) -> {
if (e == null) {
if (ttlRemaining == null) {
this.scheduleExpirationRenewal(threadId);
}
}
});
return ttlRemainingFuture;
}
}
this.commandExecutor.getConnectionManager().getCfg().getLockWatchdogTimeout(),
有个看门狗的超时时间,30 000L ====30秒
RFuture<RedissonLockEntry> subscribeFuture = this.subscribe(threadId);
他这个获取锁失败以后,会尝试再次获取。但是,也不是马上尝试获取的,因为别的业务应该还在执行,这样只能加大cpu的负担。此时会进行订阅操作,订阅的是释放锁的信号。
protected RFuture<Boolean> unlockInnerAsync(long threadId) {
return this.evalWriteAsync(this.getName(), LongCodec.INSTANCE, RedisCommands.EVAL_BOOLEAN, "if (redis.call('hexists', KEYS[1], ARGV[3]) == 0) then return nil;end; local counter = redis.call('hincrby', KEYS[1], ARGV[3], -1); if (counter > 0) then redis.call('pexpire', KEYS[1], ARGV[2]); return 0; else redis.call('del', KEYS[1]); redis.call('publish', KEYS[2], ARGV[1]); return 1; end; return nil;", Arrays.asList(this.getName(), this.getChannelName()), LockPubSub.UNLOCK_MESSAGE, this.internalLockLeaseTime, this.getLockName(threadId));
}
这是释放锁的代码,此时释放锁,会进行一个发布的命令。
尝试获取锁的线程,此时进行了订阅。
if (!subscribeFuture.await(time, TimeUnit.MILLISECONDS)) {
if (!subscribeFuture.cancel(false)) {
subscribeFuture.onComplete((res, e) -> {
if (e == null) {
this.unsubscribe(subscribeFuture, threadId);
}
});
}
this.acquireFailed(waitTime, unit, threadId);
return false;
}
在等待订阅的过程中,它也不是无限制等待的,最大等待时间就是这个time【最大剩余等待时间】,如果此时间内还未返回释放锁的通知,超时了,就取消订阅,则返回false。
if (ttl >= 0L && ttl < time) {
((RedissonLockEntry)subscribeFuture.getNow()).getLatch().tryAcquire(ttl, TimeUnit.MILLISECONDS);
} else {
((RedissonLockEntry)subscribeFuture.getNow()).getLatch().tryAcquire(time, TimeUnit.MILLISECONDS);
}
通过信号量机制,不断尝试获取锁。
保证锁是业务执行完成了释放,而不是锁超时了释放
ttlRemainingFuture.onComplete((ttlRemaining, e) -> {
if (e == null) {
if (ttlRemaining == null) {
this.scheduleExpirationRenewal(threadId);
}
}
});
会进行过期时间续约;
redis分布式锁的原理
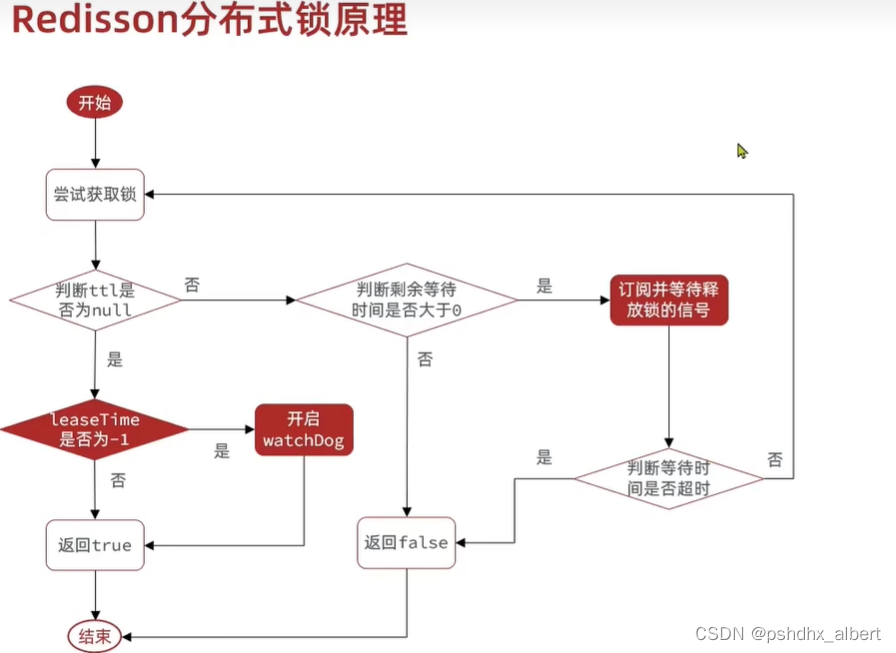
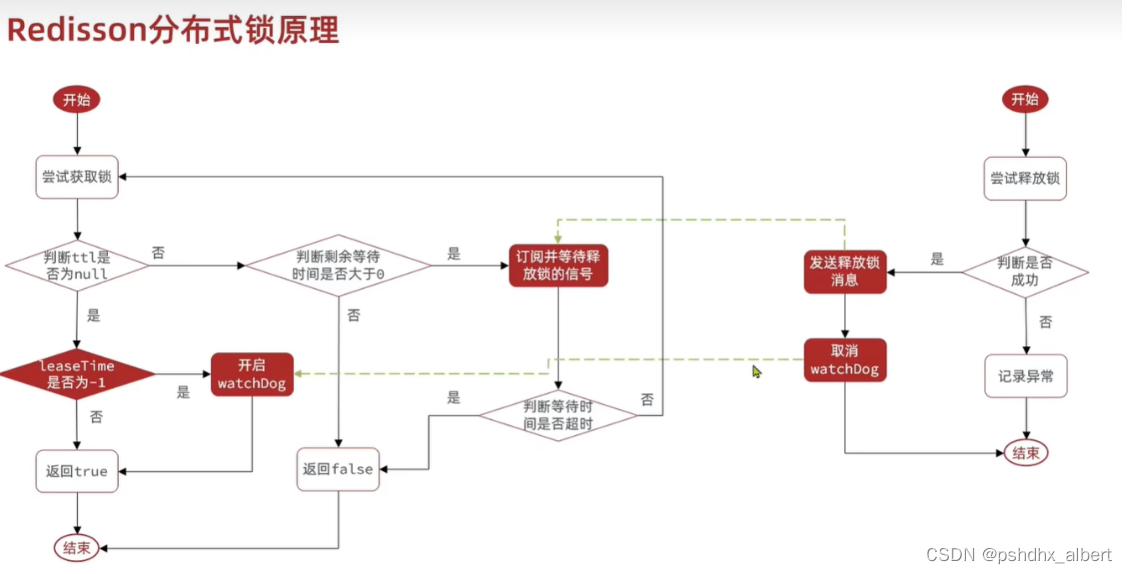
可重入:利用Hash结构,记录线程ID和重入的次数。
可重试:利用信号量和PubSub功能,实现等待、唤醒、获取锁失败的重试机制。
超时续约:利用WatchDog,每隔一段时间(ReleaseTime/3),重置超时时间。
redisson解决主从一致性
redis的各个节点,连锁。但凡有一个获取到锁,则整体失败。
@Configuration
public class RedissonConfig {
@Bean
public RedissonClient redissonClient(){
// 配置
Config config = new Config();
config.useSingleServer().setAddress("redis://192.168.150.101:6379").setPassword("123321");
// 创建RedissonClient对象
return Redisson.create(config);
}
@Bean
public RedissonClient redissonClient2(){
// 配置
Config config = new Config();
config.useSingleServer().setAddress("redis://192.168.150.101:6380").setPassword("123321");
// 创建RedissonClient对象
return Redisson.create(config);
}
@Bean
public RedissonClient redissonClient3(){
// 配置
Config config = new Config();
config.useSingleServer().setAddress("redis://192.168.150.101:6381").setPassword("123321");
// 创建RedissonClient对象
return Redisson.create(config);
}
}
class RedissonTest {
@Resource
private RedissonClient redissonClient;
@Resource
private RedissonClient redissonClient2;
@Resource
private RedissonClient redissonClient3;
private RLock lock;
@BeforeEach
void setUp() {
RLock lock1 = redissonClient.getLock("order");
RLock lock2 = redissonClient2.getLock("order");
RLock lock3 = redissonClient3.getLock("order");
lock = redissonClient.getMultiLock(lock1,lock2,lock3);
}
@Test
void method1() throws InterruptedException {
// 尝试获取锁
boolean isLock = lock.tryLock(1L, TimeUnit.SECONDS);
}
}
异步秒杀思路:
1、查询优惠券库存是否充足
2、查询优惠券是否过期
3、每个人只能抢一张优惠券【分布式锁】
4、抢完优惠券之后,扣减库存,关联用户,创建优惠券的订单【事务】
我们是否可以用主线程进行判断,如果用户有资格抢优惠券,那么我们就新开一个线程,进行扣库存和创建订单的操作。
此时,我们好像可以使用消息队列了。
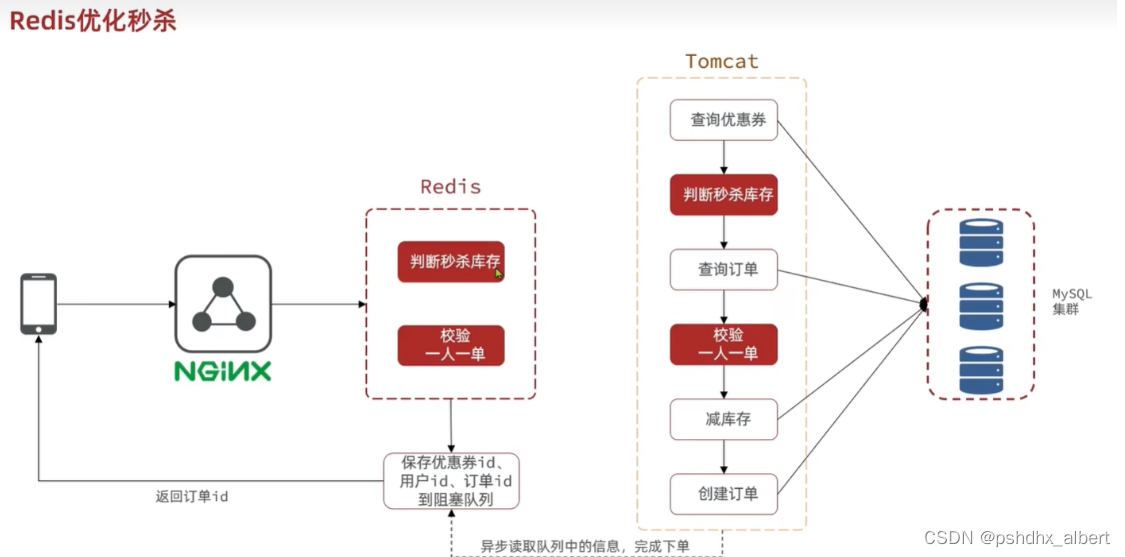
Redis异步秒杀的判断逻辑:
1、判断库存是否冲突。【模拟扣减库存】
2、判断用户是否下过该订单【将userID存入到set集合中】
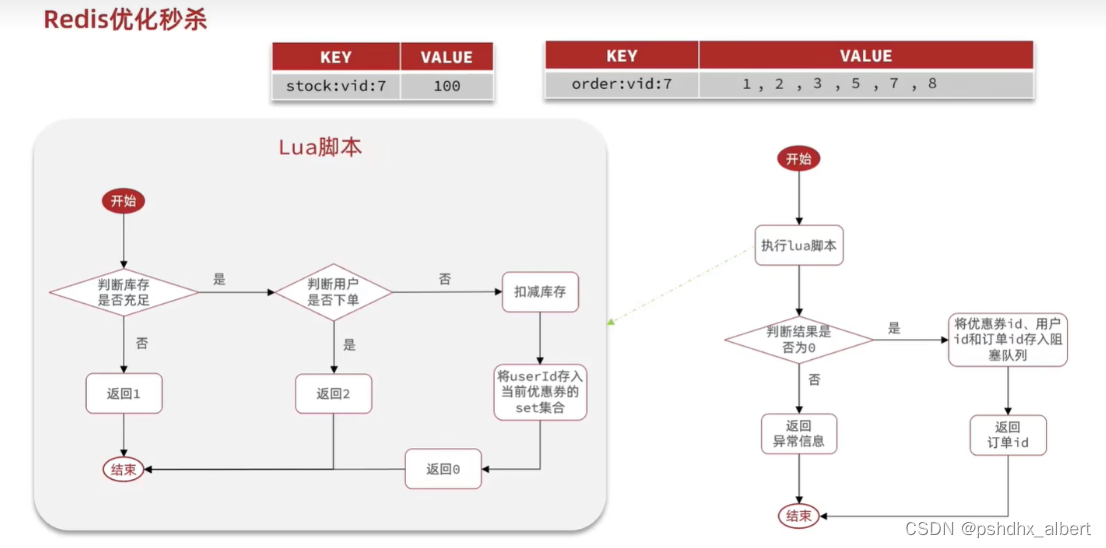
阻塞队列:
如果从队列中获取不到值,就一直阻塞。直到队列中获取值。
private BlockingQueue orderTasks = new ArrayBlockingQueue<>(1024*1024);
private static final ExecutorService SECKILL_ORDRE_EXECUTOR = Executors.newSingleThreadExecutor();
private class VoucherOrderHandler implements Runnable{
@Override
public void run(){
}
}
@PostConstruct
private void init(){
SECKILL_ORDER_EXECUTOR.submit(new VoucherOrderHandler());
}
@PostConstruct 是当前类加载完毕后,就执行这个方法的。
总结:
秒杀业务的优化思路是什么?
1、先利用Redis完成库存余量、一人一单判断,完成抢单业务。【Redis快】
2、再将下单业务放入阻塞队列,利用独立线程异步下单。【异步快】
基于阻塞队列的异步秒杀存在什么问题?
1、内存限制问题【订单的阻塞队列是有长度限制的,满了如何处理?】
2、数据安全问题【订单的阻塞队列是存在内存里边的,如果丢失了怎么处理?新开的线程处理订单失败了怎么处理?相当于任务丢失了!!!!】
认识消息队列
1、在高并发的情况下,JVM的内存不可能任意使用。
2、服务重启或者宕机,内存的数据无法持久化,会丢失数据。
生产者->Message Queue ->消费者
基于List结构的消息队列:
list是一个双向链表结构,用来模拟队列的效果。
LPush LPop RPush RPop命令来存取消息。
不过要注意的是,当队列中没有消息时,RPOP和LPOP操作会返回nil,并不像JVM的阻塞队列那种会阻塞并等待消息。
因此这里应该使用BRPOP或者是BLPOP来实现阻塞的效果。
消费者:
BRPOP l1 20
生产者:
LPush l1 e1 e2 //往l1中添加两个元素。
此时,BRPop 回返回l1和 e1;再次调用会返回l2和e2,再次调用就会阻塞。
优点:
1、利用redis存储,不受限于JVM内存的上限。
2、基于Redis的持久化机制,数据安全性有保障
3、满足了消息的有序性。
缺点:
1、无法避免消息丢失,一旦消息被pop,消费者处理消息时,挂掉了,消息丢失。
2、只支持单消费者。有时候,我们一条消息会被多个消费者消费,此种场景不能够被满足。
基于Pub/Sub的消息队列
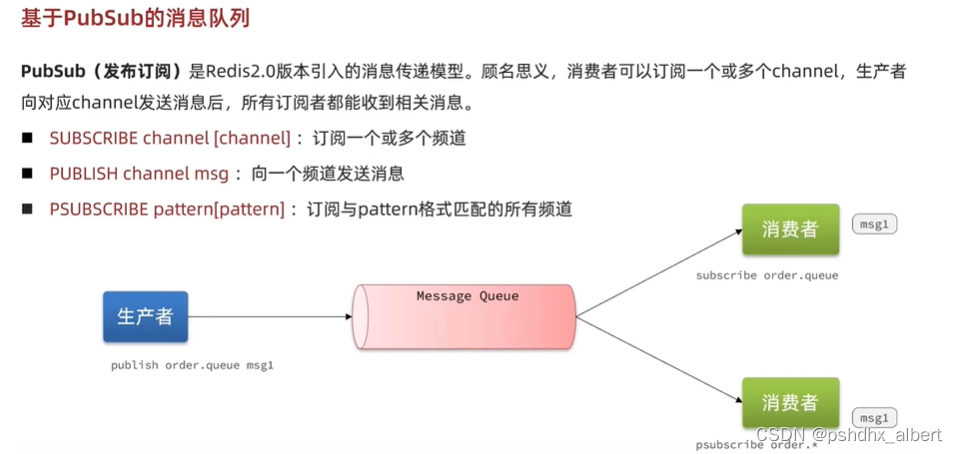
优点:
采用发布/订阅模型、支持多生产、多消费
缺点:
不支持数据持久化。
无法避免消息丢失。如果消费者发布消息,此时没有消费者监听,那么消息就没了呀。
消息堆积【消费者处理慢,容易堆积】有上限、超出时数据丢失。
基于Streams消息队列模型*
Streams是Redis5.0以后,引入的全新数据类型,可以实现一个功能非常完善的消息队列。
XADD 发送
key --队列名称
[nomkstream] --没有队列自动创建
[maxlen | minId [=|~ threshold [limit count]] --消息队列最大长度
- |ID --消息的唯一ID,时间戳+数字,由Redis自动生成。
- field value [field value…] --消息内容为键值对
举例:
1、XADD users * name jack age 21
2、xadd s1 * k1 v1
返回的都是消息的ID
xlen s1 返回消息队列的数量。
XREAD 读取消息
xread
[Count count] --每次读取消息的最大数量
[Block milliseconds] --当没有消息时,是否阻塞,阻塞时长
streams key [key …] – 从那个队列开始读取,key是队列名
ID [id…] – 启示ID,只返回大于该ID的消息。0代表从第一个消息开始,$代表最先的消息开始。
实例:
客户端1:xread count 1 streams s1 0 返回了xadd s1 * k1 v1添加的值。
客户端2:xread count 1 streams s1 0 返回了xadd s1 * k1 v1添加的值。
所以,Streams方式,是可以重复消费消息的,永久存在的。
读取最新消息:
xread count 1 streams s1 $ 返回了nil,因为没有最新的消息,已有的消息已经被消费过了。
等待最新的消息:
xread count 1 block 0 streams s1 $ --0是代表永久阻塞,并进行等待消息。
此时,Xadd s1 * k2 v2 执行完成后,阻塞读取成功。
阻塞的伪代码
while(true){
//尝试读取队列中的消息,最多阻塞两秒
Object msg = redis.execute("XRead count 1 block 2000 streams users $");
if(msg == null){
continue;
}
//处理消息
handleMessage(msg);
}
Xread $符号的bug
当我们指定起始ID为$符号时,代表读取最新的消息,如果我们处理消息的过程中,又有超过1条以上的消息到达消息队列,则下次读取时,也只能获取最新的一条消息,会出现漏读消息的问题。
总结
1、消息可以回溯:消息读取完成后,不会消失,永久存在。
2、一个消息可以被多个消费者读取:因为消息不丢失。
3、可以阻塞读取;
4、有消息漏读的风险。
stream的消费者组模式
消费者组:将多个消费者划分到一个组中,监听同一个队列,其具有以下特点。
1、消息分流:
队列中的消息,会分流给组内的不通消费者,而不是重复消费,从而处理消息的处理速度。如果多个消费者都要获取到消息,可以设立多个消费者组。
2、消息标识:
消费者组会维护一个标识,记录最后一个被处理的消息,哪怕消费者宕机重启,还会从标识之后继续读取消息,确保每一个消息都被消费。【避免xread $的漏读问题。】
3、消息确认:
消费者获取消息后,消息处于一个pending的状态,并存入一个pending-list。当处理完成后,需要通过xack来确认消息,标记消息处理完成,才会从pending-list中移除。
创建消费者组
xgroup create key groupName ID [mkstream]
key:队列名称
mkstream:队列不存在时,自动创建。
实例:
xgroup create s1 g1 0 返回ok
删除指定的消费者组
xgroup destory key groupName
给指定的消费者组添加消费者
xgroup createconsumer key groupname consumername
删除消费者组中的指定消费者
xgroup delconsumer key groupname consumername
从消费者组读取消息
xreadgroup Group groupName consumerName [Count count] [Block mill] [noAck] streams key[key …] ID [ID…]
ID:“>” 从下一个未消费的消息开始。
其他:根据指定ID从pending-list中获取已消费,但是未确认的消息。例如0,是从pending-list中第一个消息开始。
XACK
xack s1 g1 id1 id2
查询pending-list
xpending key group
实例:
xpending s1 g1 - + 10 取出所有范围内的10条。
xreadgroup Group g1 c1 count 1 block 2000 streams s1 0
取出pending-list中的一条。返回ID值。
确认pending-list
xack s1 g1 ID1
此时,再次执行,xreadgroup Group g1 c1 count 1 block 2000 streams s1 0 ,返回empty array.
消费者组伪代码
while(true){
Object msg = redis.call("xreadgroup group g1 c1 count 1 block 2000 streams s1 >");
if(msg == null){
continue;
}
try{
handleMessage(msg);
}catch(Exception e){
while(true){
Object msg = redis.call("xreadgroup group g1 c1 count 1 streams s1 0");
if(msg == null){ //说明没有异常消息,都被确认过了,所以pending-list中为空
break;
}
try{
//说明有异常,再次被处理
handleMessage(msg);
}catch(Exception e){
//再次出现异常,记录日志,继续循环
continue ;
}
}
}
}
消费者组总结:
1、消息可以回溯
2、可以多消费者争抢消息,可以加快消费速度
3、可以阻塞读取
4、没有漏读的风险
5、有消息确认机制,保证消息至少被消费一次
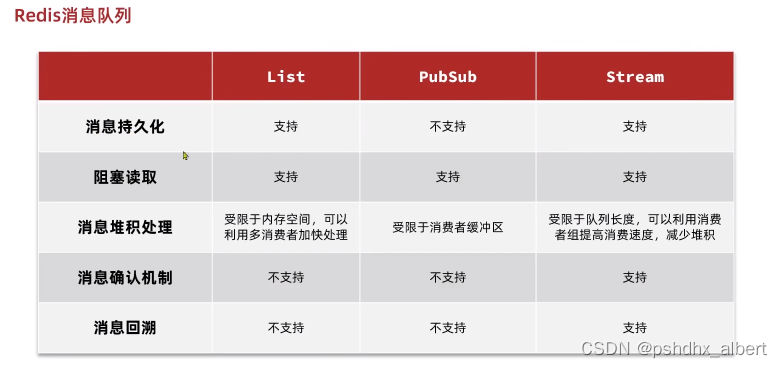
redis三种队列的区别
异步秒杀最终版本:
需求:
1、创建一个stream类型的消息对垒,名称为stream.orders
2、修改之前的lua脚本,在确认有抢购资格后,直接想stream.orders中添加消息,内容包含voucherId,userId,orderId。
3、项目启动时,开启一个线程任务,尝试获取stream.orders中的消息,完成下单。
(1)xgroup create stream.orders g1 0 mkstream
队列和消费者组都创建好了。
(2)
-- 1.参数列表
-- 1.1.优惠券id
local voucherId = ARGV[1]
-- 1.2.用户id
local userId = ARGV[2]
-- 1.3.订单id
local orderId = ARGV[3]
-- 2.数据key
-- 2.1.库存key
local stockKey = 'seckill:stock:' .. voucherId
-- 2.2.订单key
local orderKey = 'seckill:order:' .. voucherId
-- 3.脚本业务
-- 3.1.判断库存是否充足 get stockKey
if(tonumber(redis.call('get', stockKey)) <= 0) then
-- 3.2.库存不足,返回1
return 1
end
-- 3.2.判断用户是否下单 SISMEMBER orderKey userId
if(redis.call('sismember', orderKey, userId) == 1) then
-- 3.3.存在,说明是重复下单,返回2
return 2
end
-- 3.4.扣库存 incrby stockKey -1
redis.call('incrby', stockKey, -1)
-- 3.5.下单(保存用户)sadd orderKey userId
redis.call('sadd', orderKey, userId)
-- 3.6.发送消息到队列中, XADD stream.orders * k1 v1 k2 v2 ...
redis.call('xadd', 'stream.orders', '*', 'userId', userId, 'voucherId', voucherId, 'id', orderId)
return 0
(3)
@Override
public Result seckillVoucher(Long voucherId) {
Long userId = UserHolder.getUser().getId();
long orderId = redisIdWorker.nextId("order");
// 1.执行lua脚本
Long result = stringRedisTemplate.execute(
SECKILL_SCRIPT,
Collections.emptyList(),
voucherId.toString(), userId.toString(), String.valueOf(orderId)
);
int r = result.intValue();
// 2.判断结果是否为0
if (r != 0) {
// 2.1.不为0 ,代表没有购买资格
return Result.fail(r == 1 ? "库存不足" : "不能重复下单");
}
// 3.返回订单id
return Result.ok(orderId);
}
private static final DefaultRedisScript<Long> SECKILL_SCRIPT;
static {
SECKILL_SCRIPT = new DefaultRedisScript<>();
SECKILL_SCRIPT.setLocation(new ClassPathResource("seckill.lua"));
SECKILL_SCRIPT.setResultType(Long.class);
}
private static final ExecutorService SECKILL_ORDER_EXECUTOR = Executors.newSingleThreadExecutor();
@PostConstruct
private void init() {
SECKILL_ORDER_EXECUTOR.submit(new VoucherOrderHandler());
}
private class VoucherOrderHandler implements Runnable {
@Override
public void run() {
while (true) {
try {
// 1.获取消息队列中的订单信息 XREADGROUP GROUP g1 c1 COUNT 1 BLOCK 2000 STREAMS s1 >
List<MapRecord<String, Object, Object>> list = stringRedisTemplate.opsForStream().read(
Consumer.from("g1", "c1"),
StreamReadOptions.empty().count(1).block(Duration.ofSeconds(2)),
StreamOffset.create("stream.orders", ReadOffset.lastConsumed())
);
// 2.判断订单信息是否为空
if (list == null || list.isEmpty()) {
// 如果为null,说明没有消息,继续下一次循环
continue;
}
// 解析数据
MapRecord<String, Object, Object> record = list.get(0);
Map<Object, Object> value = record.getValue();
VoucherOrder voucherOrder = BeanUtil.fillBeanWithMap(value, new VoucherOrder(), true);
// 3.创建订单
createVoucherOrder(voucherOrder);
// 4.确认消息 XACK
stringRedisTemplate.opsForStream().acknowledge("s1", "g1", record.getId());
} catch (Exception e) {
log.error("处理订单异常", e);
handlePendingList();
}
}
}
private void handlePendingList() {
while (true) {
try {
// 1.获取pending-list中的订单信息 XREADGROUP GROUP g1 c1 COUNT 1 BLOCK 2000 STREAMS s1 0
List<MapRecord<String, Object, Object>> list = stringRedisTemplate.opsForStream().read(
Consumer.from("g1", "c1"),
StreamReadOptions.empty().count(1),
StreamOffset.create("stream.orders", ReadOffset.from("0"))
);
// 2.判断订单信息是否为空
if (list == null || list.isEmpty()) {
// 如果为null,说明没有异常消息,结束循环
break;
}
// 解析数据
MapRecord<String, Object, Object> record = list.get(0);
Map<Object, Object> value = record.getValue();
VoucherOrder voucherOrder = BeanUtil.fillBeanWithMap(value, new VoucherOrder(), true);
// 3.创建订单
createVoucherOrder(voucherOrder);
// 4.确认消息 XACK
stringRedisTemplate.opsForStream().acknowledge("s1", "g1", record.getId());
} catch (Exception e) {
log.error("处理订单异常", e);
}
}
}
}