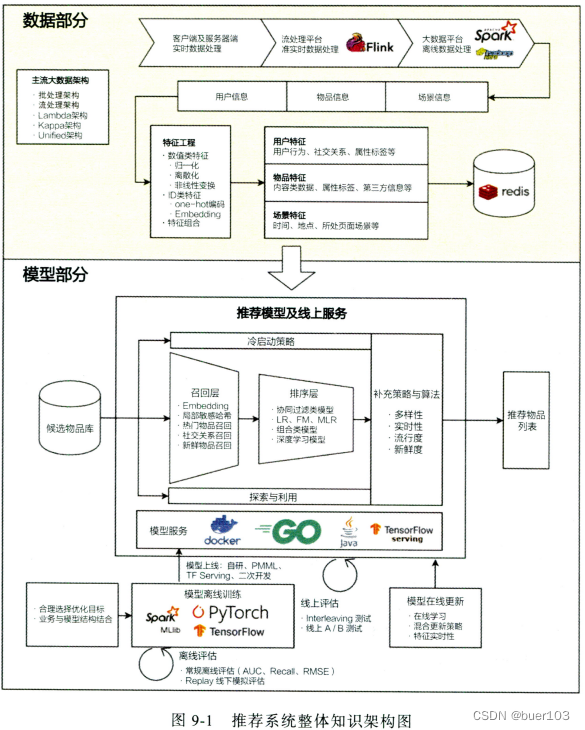
推荐系统整体知识架构
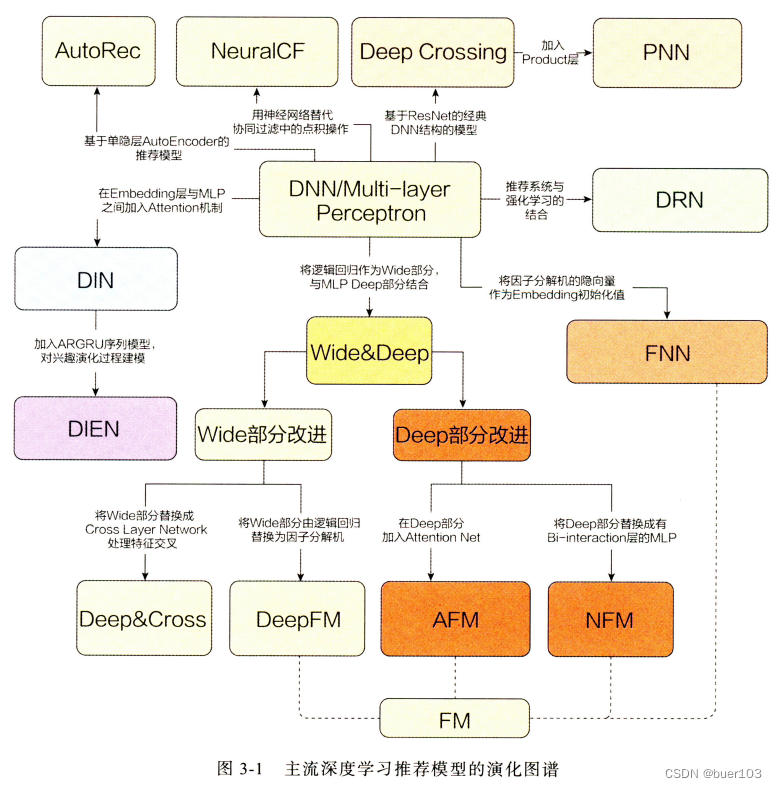
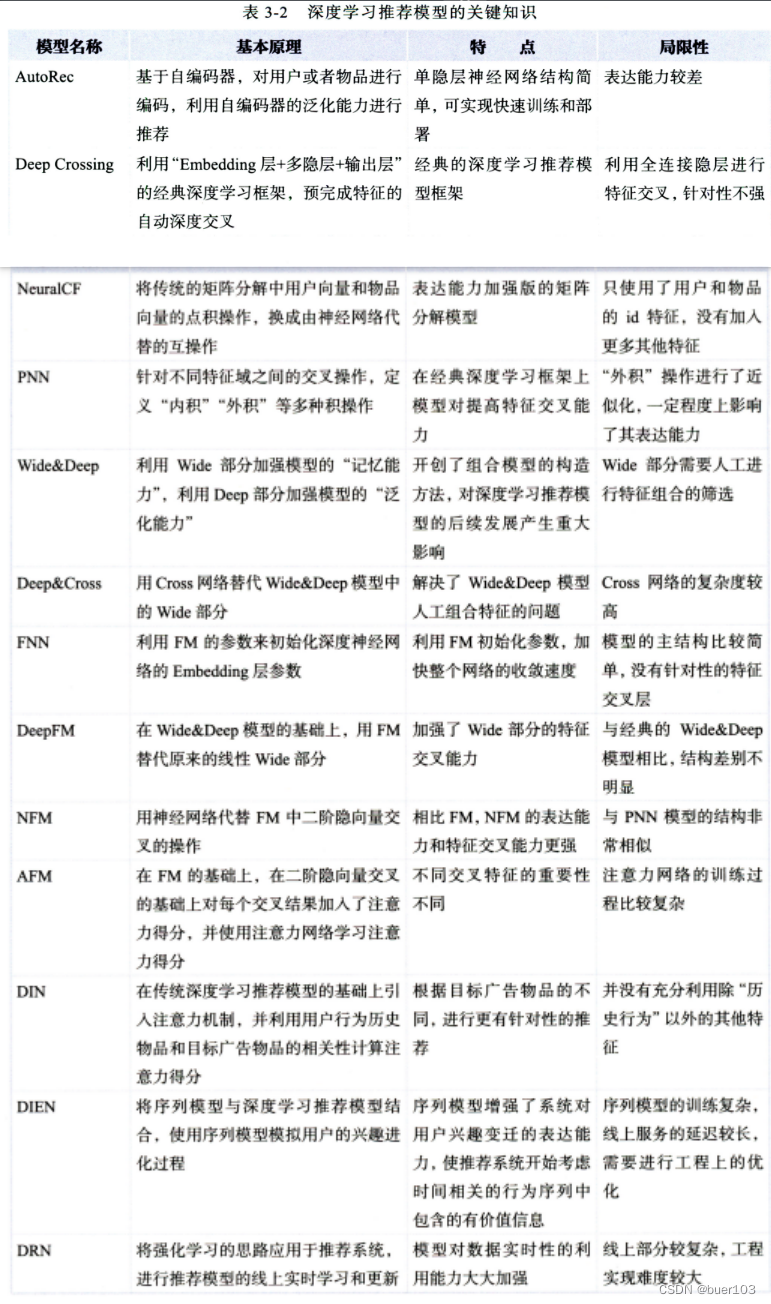
推荐模型发展
工业
CTR模型的三个改进大点:显性特征交叉, 特征重要度, user历史信息的挖掘
- 显性特征交叉: 针对的是隐性无脑交叉的DNN的不足, 针对一些重要的关键特征进行显性特征交叉, 提取出再一个层次上的重要特征来, 然后再去无脑隐性。 代表模型: PNN,NeuralFM,DeepFM,NFM,DCN等。 改进思路:①内积 ②哈达玛积 ③外积 ④DCN的交叉网络(这是个亮点思路)
- 特征重要度: 对原始特征和线性交叉特征做重要性排序,或者加权,代表模型:AFM,DIN,DIEN等。 改进思路: ①注意力机制 ②哈达玛积做交叉 ③FiBiNet里面用的双线性的思路(这个模型后期会整理)
- user历史信息的挖掘: 这个就是考虑用户的历史行为特征,对这些历史行为进行信息挖掘。 典型的DIN,DIEN,DSIN(下一篇)等。 改进思路:序列加上,然后Attention ②RNN系列的网络提取,包括transformer, 计算量大, 部署困难 ③先根据时间段分组,然后pooling ④ 引入sideinfo信息之后,分组, 然后pooling。
工业上常用的推荐模型:
- 传统模型:LR, GBDT+LR, FM,FFM
- Deep 模型: wide&Deep, deepFM, DIN, PNN, DCN, Fi-BiNet
常用程度:
- 第一梯队: LR, GBDT+LR, FM
- 第二梯队: DeepFM, W&D
- 第三梯队: DIN, FFM, PNN 等
一些很复杂的模型, 虽然可能理论上效果比较好,但是在真正工程实践中并不是很常用。 可能的原因是部署复杂,且训练难度很大。此外,还有模型增量更新的问题, 增量训练是定时更新某层模型参数, 所以树模型是没法进行增量训练的。一训练就改变树结构了,一般,模型是梯度更新的那种,比如LR ,FM, W&D, deepFM等可以增量训练。 而GBDT+LR的话,只能增量更新LR的部分
一直在写论文投稿。。。。持续学习ing
学习参考_大佬栏目
代码参考_DeepCTR