现在超算中心已经迅速发展
合肥:
合肥先进中心
合肥曙光超算中心平台
合肥安徽大学超算中心
合肥中科大超算中心
合肥中科院超算中心
合肥大一点的公司都会有自己的集群,
超算中心又称为集群,一般集群是小型服务器组成,超算中心是更大概念的,有很多小型服务器组成。
超算中心一般指的是大型集群,核数达到上千核数,核数多很多节点成为队列。
一般超算中心都会有3-5个队列,会根据投资多少,决定了队列的节点,有的节点是40核数,有的是48核数,有的是28核数,有的是128核数。
超算中心一般会有一台login登录节点,或者几台,几十台。就我们实验室的服务器集群5台,一台login节点,其余是运行节点。login电脑一般会限制终端数量。
关于超算中心一般有超算文件说明,那么关于如何使用超算中心是很多人关注的重点。队列的使用,集群是否和自己电脑上的linux使用方法是一样的。
"Linux下PBS(torque)任务排队管理系统的安装配置" 笔者推荐了集群管理系统torque,但是常常有朋友反应torque容易出故障与shell兼容不太好。笔者自从用了天河、成都超算和本校超算后,发现它们都用的slurm作为集群管理系统。
# su root #进入root用户
#slrum要进行munge密钥认证,所以要先安装munge并生成密钥
# apt-get install munge # 安装munge
# /usr/sbin/create-munge-key # 生成munge密钥安装slurm
# systemctl start slurmctld
# systemctl status slurmctld
# systemctl enable slurmctld
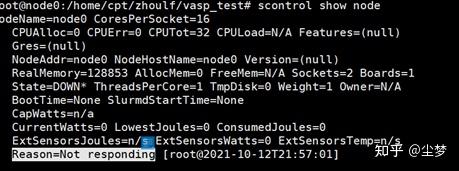
输入命令sinfo -N查看集群状态,可以到这个单节点是处于down状态的。此时提交任务即使服务器资源没有被占用,任务也会一直处于PD状态。因此需要把节点调为idle状态。
输入:scontrol show node可以看到故障原因为Not_responding
输入以下命名可以解决:
scontrol update NodeName=node0 State=DOWN Reason=Not_responding
slurmd restart
scontrol update NodeName=node0 State=RESUME
再输入sinfo -N时节点状态已经为idle了。

提交任务测试可以看到,提交上去任务立马运行,此时slurm集群管理系统安装成功。

附录:
#slurm常用的三个命令
sbatch #提交任务,使用方法sbatch run.sh 其中run.sh为任务脚本
squeue #查看队列
scancel #kill任务,使用方法 scancel JOB_ID
一个提交LAMMPS/VASP的slrum脚本如下
#!/bin/bash
#SBATCH --nodes=1
#SBATCH --job-name="cascade"
#SBATCH --ntasks-per-node=32
source ~/scripts/intel2019.sh
export PATH=~/Code/bin:$PATH
ulimit -c unlimited
ulimit -s unlimited
#mpd &
#mpirun -np 32 lammps < in.relax #核数可以自定义
mpirun -np 32 vasp > out.txt
命令1:sinfo (查看集群运行状态)
对于我这个初学者而言,SLURM 学习还是有一定难度。本文参考:slurm入门,在此谢谢作者!
1. SLURM 的安装和使用
# 安装slurm及其依赖
sudo apt-get install slurm-llnl
2. 配置slurm
可使用
在线是slurm 配置器,由它为我生成基于表单数据的配置文件。注意:需根据自己超算的情况进行修改。
面向单节点集群的SLURM 配置文件,这个还没弄,到时候再看!
# slurm.conf file generated by configurator.html.
# Put this file on all nodes of your cluster.
# See the slurm.conf man page for more information.
#
ControlMachine=mtj-VirtualBox
#
AuthType=auth/none
CacheGroups=0
CryptoType=crypto/openssl
MpiDefault=none
ProctrackType=proctrack/pgid
ReturnToService=1
SlurmctldPidFile=/var/run/slurmctld.pid
SlurmctldPort=6817
SlurmdPidFile=/var/run/slurmd.pid
SlurmdPort=6818
SlurmdSpoolDir=/tmp/slurmd
SlurmUser=slurm
StateSaveLocation=/tmp
SwitchType=switch/none
TaskPlugin=task/none
#
# TIMERS
InactiveLimit=0
KillWait=30
MinJobAge=300
SlurmctldTimeout=120
SlurmdTimeout=300
Waittime=0
#
# SCHEDULING
FastSchedule=1
SchedulerType=sched/backfill
SchedulerPort=7321
SelectType=select/linear
#
# LOGGING AND ACCOUNTING
AccountingStorageType=accounting_storage/none
ClusterName=cluster
JobCompType=jobcomp/none
JobCredentialPrivateKey = /usr/local/etc/slurm.key
JobCredentialPublicCertificate = /usr/local/etc/slurm.cert
JobAcctGatherFrequency=30
JobAcctGatherType=jobacct_gather/none
SlurmctldDebug=3
SlurmdDebug=3
#
# COMPUTE NODES
NodeName=mtj-VirtualBox State=UNKNOWN
PartitionName=debug Nodes=mtj-VirtualBox default=YES MaxTime=INFINITE State=UP
最后一步说是生成一组作业凭证秘钥,且使用openssl 作为其凭证秘钥。
清单2. 为slurm 创建凭证
$ sudo openssl genrsa -out /usr/local/etc/slurm.key 1024
Generating RSA private key, 1024 bit long modulus
.................++++++
............................................++++++
e is 65537 (0x10001)
$ sudo openssl rsa -in /usr/local/etc/slurm.key -pubout -out /usr/local/etc/slurm.cert
writing RSA key
完成凭证后,可以启动slurm 并与其交互。
3. 启动slurm
$ sudo /etc/init.d/slurm-llnl start
清单3. 使用sinfo命令来查看集群
$ info
================================================================
PARTITION AVAIL TIMELIMIT NODES STATE NODELIST
debug* up infinite 1 idle mtj-VirtualBox
================================================================
4. 更多的slurm命令
slurm
Slurm Workload Manager - Documentation
# apt-get install slurm-llnl
配置slurm配置文件:
笔者的配置文件如下,最重要的是开头一行和最后两行,其余的可以保持默认,具体可参考网站:https://www.ityww.cn/1470.html
ontrolMachine=node0
SlurmctldPort=6817
SlurmdPort=6818
AuthType=auth/munge
StateSaveLocation=/tmp
SlurmdSpoolDir=/tmp/slurmd
SwitchType=switch/none
MpiDefault=none
SlurmctldPidFile=/var/run/slurm-llnl/slurmctld.pid
SlurmdPidFile=/var/run/slurm-llnl/slurmd.pid
ProctrackType=proctrack/pgid
CacheGroups=0
ReturnToService=2
TaskPlugin=task/affinity
# make the default memory per core
DefMemPerNode=2048
MaxJobCount=10000
MinJobAge=180
# TIMERS
SlurmctldTimeout=120
SlurmdTimeout=120
InactiveLimit=0
KillWait=30
Waittime=0
# SCHEDULING
SchedulerType=sched/backfill
#SchedulerPort=7321
SelectType=select/cons_res
SelectTypeParameters=CR_CPU_Memory
FastSchedule=0
# LOGGING
SlurmctldDebug=3
#SlurmctldLogFile=/var/log/slurmctld.log
SlurmdDebug=3
#SlurmdLogFile=/var/log/slurmd.log
JobCompType=jobcomp/none
#JobCompLoc=
JobAcctGatherType=jobacct_gather/none
# COMPUTE NODES
NodeName=node0 CPUs=32 Sockets=2 CoresPerSocket=16 Procs=32 RealMemory=128853 State=UNKNOWN
PartitionName=compute Nodes=ALL Default=YES Shared=YES State=UP
启动munge:
# systemctl start munge
# systemctl status munge
# systemctl enable munge
开启:slurm