文章目录
- Prometheus本地存储简介
- block
- WAL
- 本地存储配置参数
- VictoriaMetrics
- 简介
- 单机版部署使用
- 安装VictoriaMetrics
- 配置Prometheus使用Victoriametrics
- 配置Grafana以Victoriametrics作为数据源
- 集群版部署使用
- 部署vmstorage
- 部署vmselect
- 部署vminsert
- 配置Prometheus使用vminsert
- 配置Grafana以vmselect为数据源
- 开启数据复制
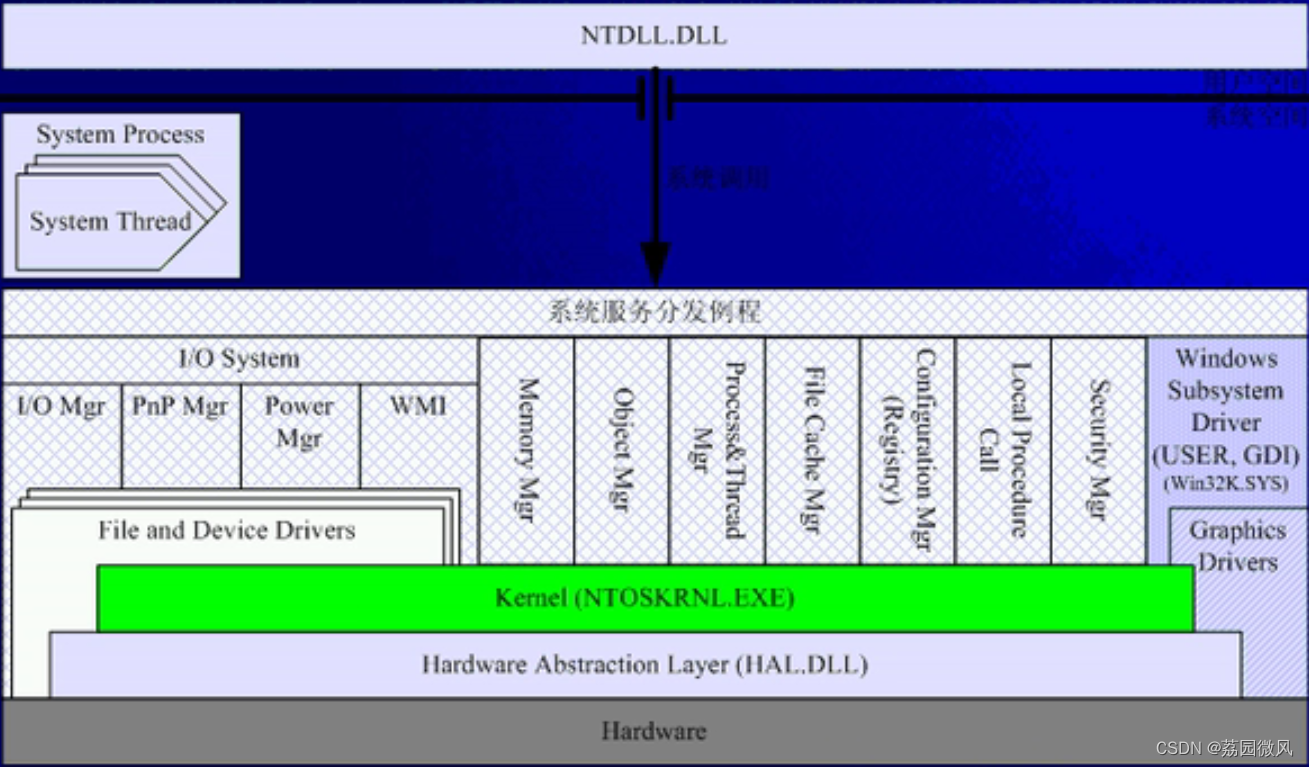
Prometheus提供了两种存储方式,分别是本地存储和远端存储
Prometheus本地存储简介
Prometheus的本地存储被称为Prometheus TSDB,目前是V3版本,根据官方介绍其有着非常高效的时间序列数据存储方法,每个采样数据仅占3.5byte左右空间,上百万条时间序列,30s间隔,保存60天,仅占200多G空间
默认情况下,Prometheus将采集到的数据保存在本地的TSDB数据库中,默认目录为Prometheus安装目录下的data目录。数据写入过程为先把数据写入wal日志并放在内存中,然后2个小时后将内存数据放入一个新的block块,同时再把新的数据写入内存并在2小时后再保存至一个新的block块,依次类推
这里涉及到两个组成部分:block和wal
block
Prometheus TSD将存储的监控数据按时间分割为block,block的大小并不固定,默认最小的block保存2h的数据,随着数据量的不断增加,TSDB会将小的block合并为大的block,例如将3个2h的block合并为一个6h的block,这样不仅可以减少数据存储,还可以减少block个数,便于对数据进行检索。
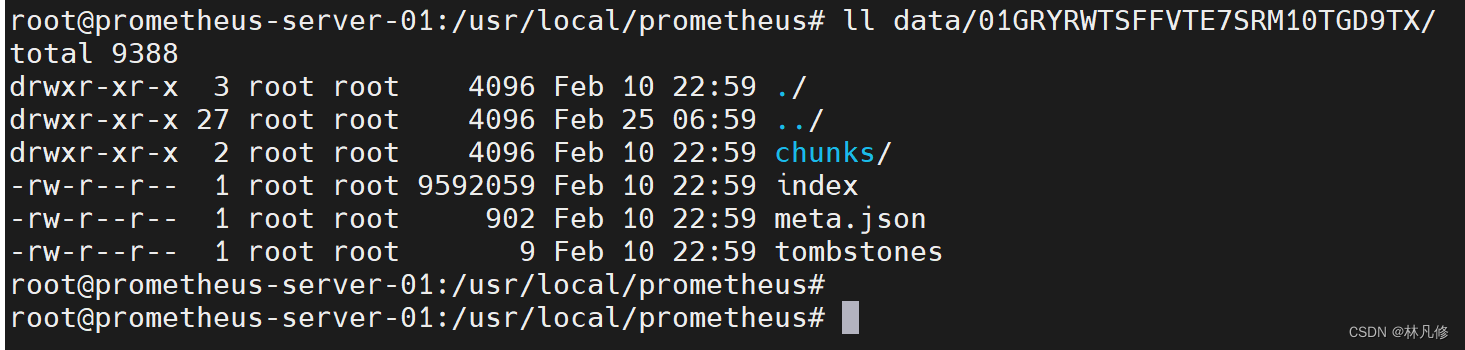
在实际存储中,block就是Prometheus TSDB数据目录下那些以01开头的存储目录,如下图:
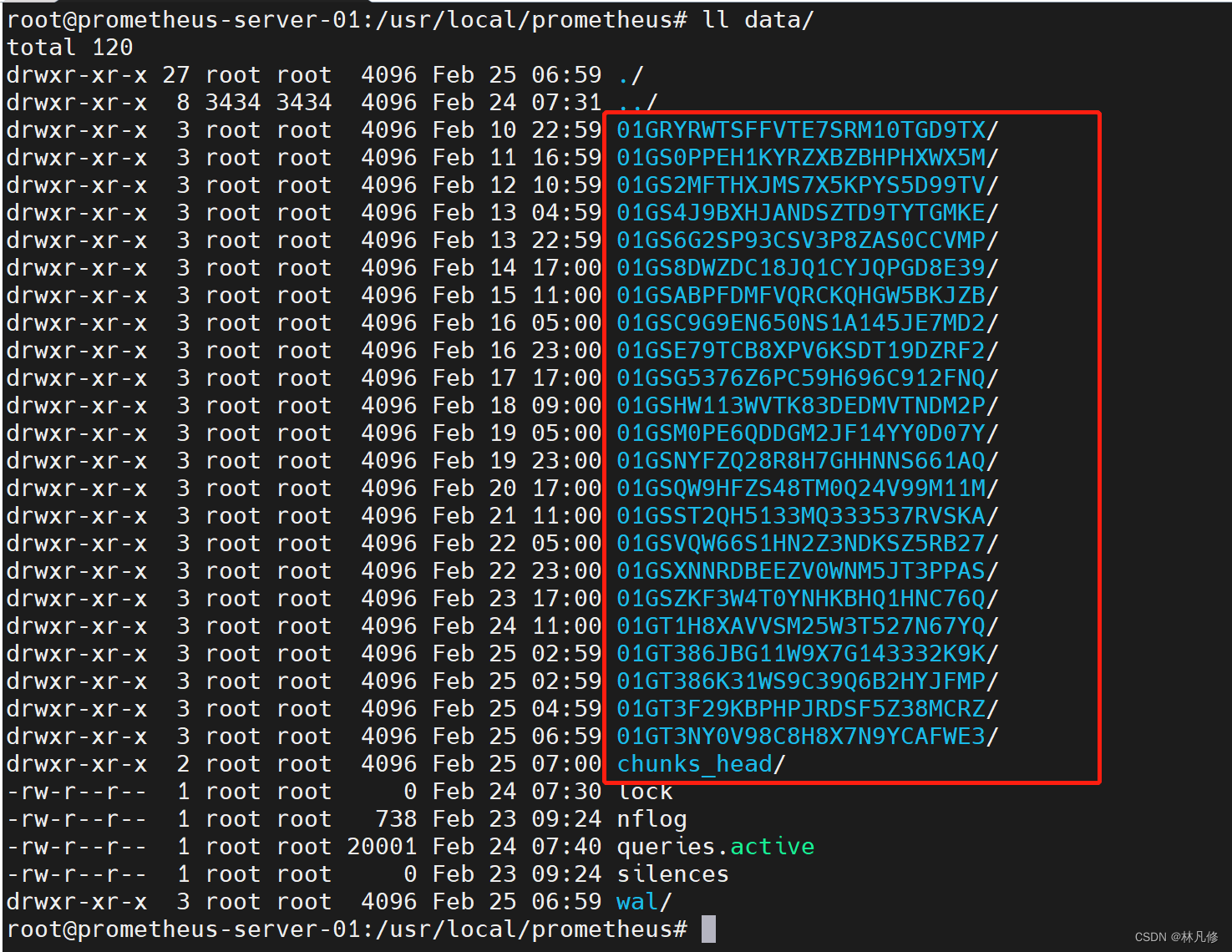
block主要包含4个部分:chunks、index、meta.josn、tombstones,如下图:
1. chunks
chunks主要用于保存压缩后的时序数据。每个chunk的大小为512M,如果超过,则会被分割为多个chunk保存,且以数字编号命名
2. index
index是为了对时序数据进行快速检索和查询而设计,主要用来记录chunk中时序的偏移位置
3. meta.json
meta.json记录block的元数据信息,主要包括一个数据块记录样本的起始时间、截至时间、样本数、时序数和数据源等信息,这些元数据信息在后期对block进行维护(删除过期block、合并block等)时会用到。
下面是一个meta.json文件示例
{
"ulid": "01GT3F29KBPHPJRDSF5Z38MCRZ", #blcok的Id
"minTime": 1677290405717, #block的起始时间
"maxTime": 1677297600000, #block的截至时间
"stats": {
"numSamples": 1374480, #样本数量
"numSeries": 2573, #时序数量
"numChunks": 11454 #chunk数量
},
"compaction": {
"level": 1, #压缩级别
"sources": [
"01GT3F29KBPHPJRDSF5Z38MCRZ" #此block由哪些block压缩合并而来
]
},
"version": 1
}
4. tombstones
tombstones用于对数据进行软删除。TSDB在删除block数据块时会将整个目录删除,但如果只删除一部分数据块的内容,则可以通过 tombstones进行软删除
这些block按照时间顺序被分割为一个个block,其中第一个block被称为head-block,它被存储在内存中并且允许修改,而后面的block以只读的方式存储在硬盘中。如下图:
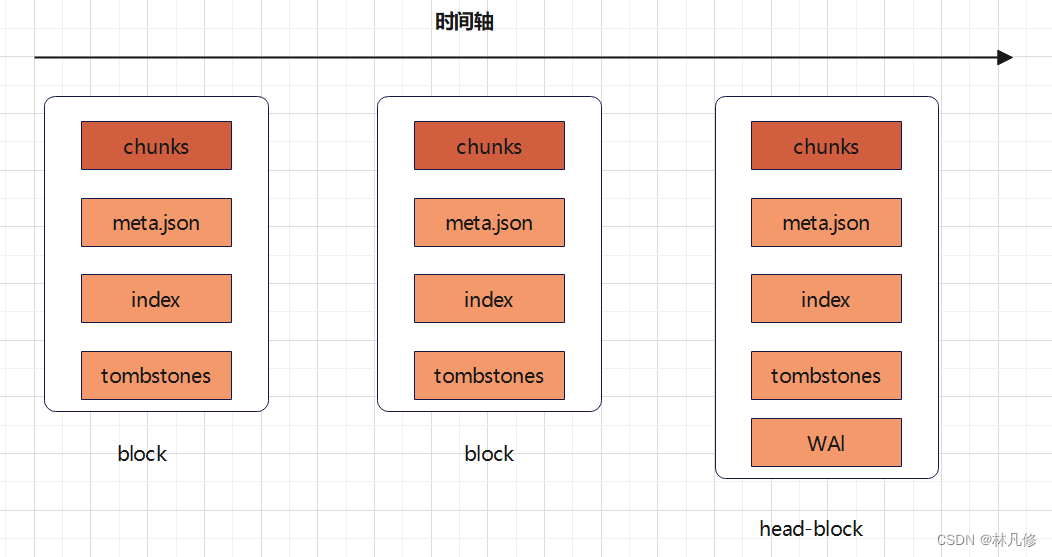
head-block和后面的block都被初始设定为保存2h的数据,当head-block超过1.5倍大小(3h)的时候,它将被重新分割成2h和1h两部分,前面一部分变为只读块被保存到硬盘中。
WAL
WAL(write-ahead logging,预写日志)是关系型数据库中利用日志来实现事务性和持久性的一种技术,即在进行某个操作之前先将这件事情记录下来,以便之后对数据进行回滚、重试等操作并保证数据可靠性。
Prometheus为了防止丢失暂存在内存中的还未被写入磁盘的监控数据’、引入了WAL机制。WAL被分割为默认大小为128M的文件段,文件段以数字命名,例如00000001、00000002等,以此类推。
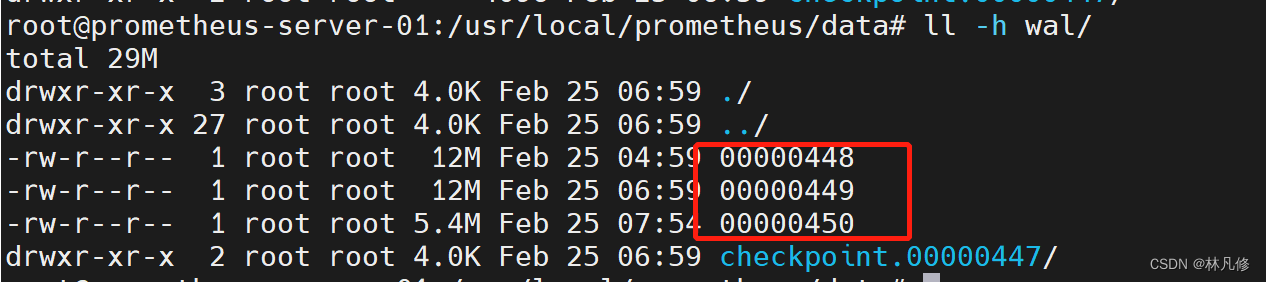
按照每种对象设定的采集周期,Prometheus会将周期性采集的监控数据先写入head-block中,但这些数据没有被持久化,TSDB通过WAL将提交的数据先保存到磁盘中,在TSDB宕机重启后,会首先启动多协程读取WAL,从而恢复之前的状态。
另外从Prometheus v2.19.0开始,Prometheus引入了内存映射,将head-block中已填充的完整的chunk,刷新到磁盘(即保存在chunks_head目录下的数据)并从磁盘进行内存映射,同时仅将引用存储在内存中。通过内存映射,可以在需要时使用该引用将chunk动态加载到内存中。这是操作系统提供的功能。通过引入内存映射,减少了Prometheus的内存消耗,虽然填充完毕的chunk会被刷到磁盘上,但是对于该部分的操作预写入日志不会被删除,直到该chunk所属的block完整落盘
本地存储配置参数
--storage.tsdb.path #指定数据保存位置
--storage.tsdb.retention.time #指定数据保存时间,默认15d
--storage.tsdb.retention.size #指定block可以保存的数据大小
--query.timeout #最大查询超时时间,默认2m
--query.max-concurrency #最大查询并发数,默认20
VictoriaMetrics
简介
VictoriaMetrics是一个快速、支持高可用且可扩展的开源时序数据库和监控解决方案。可用做Promethazine的远端存储。
VictoriaMetrics官网:https://victoriametrics.com/
官方文档:https://docs.victoriametrics.com/
项目地址:https://github.com/VictoriaMetrics
VictoriaMetrics的优点:
- 兼容Prometheus相关API,可以直接用作Grafana的数据源
- 内存占用率低
- 查询速度快
- 设置和操作简单
- 支持水平扩容和HA(集群版)
- 高压缩比等等
VictoriaMetrics分为集群版和单机版,根据实际需求选择即可。
- 单机版:直接通过二进制文件运行即可,官方建议采集数据点(data points)低于100w/s,推荐VM单节点版,简单好维护,但不支持告警。
- 集群版:支持数据水平拆分,根据功能拆分为不同的组件vmselect、vminsert、vmstorage,如果替换Prometheus还可以加上vmagent和vmalert
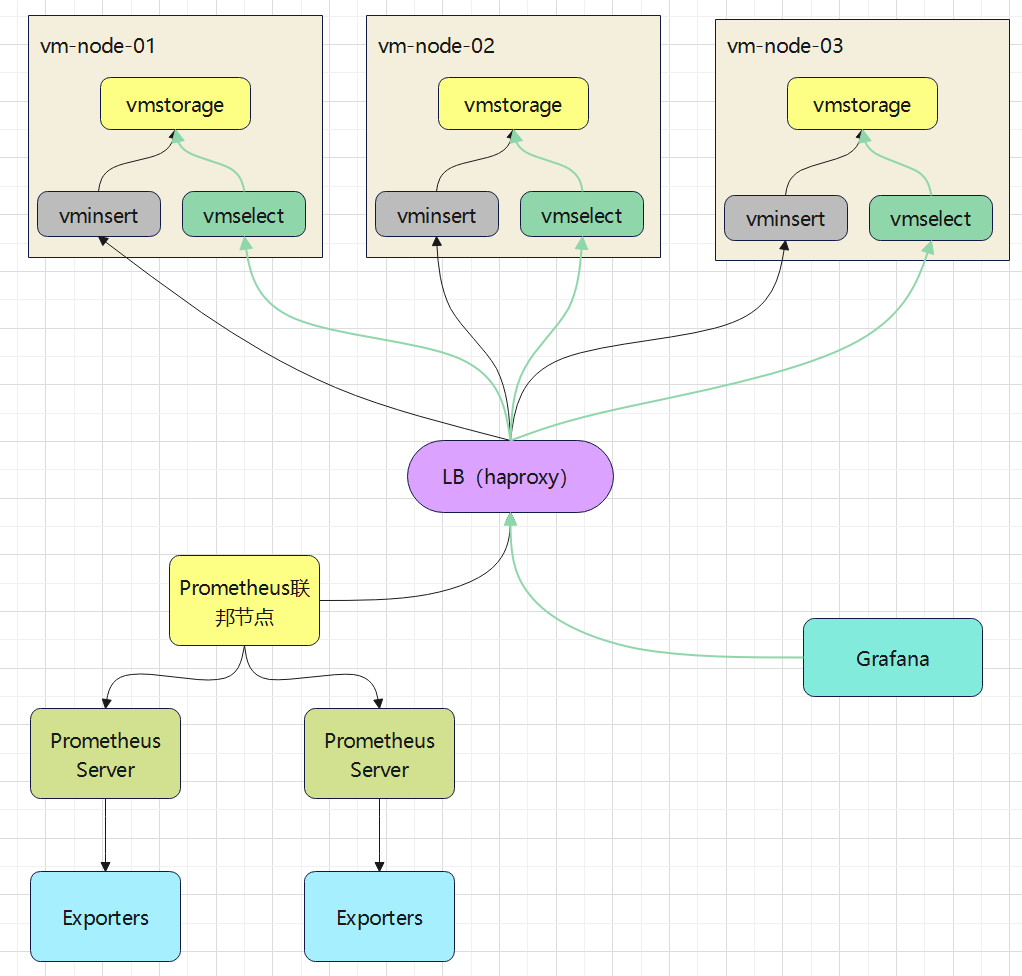
下图是集群版的架构图:
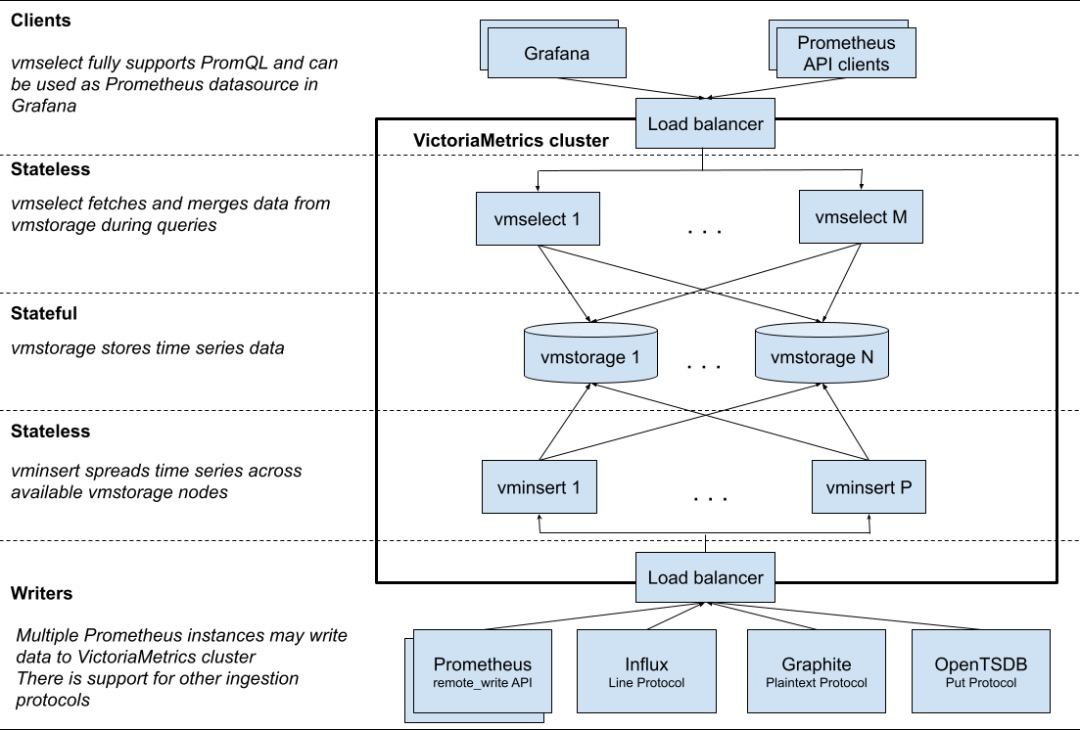
相关组件作用如下:
- vmstorage:数据存储即查询结果返回,默认端口8482
- vminsert:写入组件,vminsert负责接收数据写入请求并根据对数据的hash结果将数据写入到后端不同的vmstorage之上,实现数据分片。默认端口8480,属于无状态服务可水平扩展
- vmselect:查询组件,负责接收查询请求,并连接到vmstorage查询数据。默认端口8481,属于无状态服务可水平扩展
另外还有一些可选组件:
- vmagent:类似于Prometheus,负责从各种数据来源收集指标数据
- vmalert:类似于Alertmanager,负责实现告警功能
- vmctl:命令行工具
单机版部署使用
安装VictoriaMetrics
下载单机版安装包
wget https://github.com/VictoriaMetrics/VictoriaMetrics/releases/download/v1.87.2/victoria-metrics-linux-amd64-v1.87.2.tar.gz
tar xf victoria-metrics-linux-amd64-v1.87.2.tar.gz
mv victoria-metrics-prod /usr/bin/
victoria-metrics-prod -h #查看参数
准备service文件
root@vm-node-01:~# cat /lib/systemd/system/victoria-metrics.service
[Unit]
Description=For Victoria-metrics-prod single service
After=network.target
[Service]
ExecStart=/usr/bin/victoria-metrics-prod -httpListenAddr=0.0.0.0:8428 -storageDataPath=/data/victoria-metrics
-retentionPeriod=3
[Install]
WantedBy=multi-user.target
启动服务
mkdir -p /data/victoria-metrics
systemctl daemon-reload
systemctl start victoria-metrics.service
systemctl status victoria-metrics.service
systemctl enable victoria-metrics.service
服务启动后可以访问VictoriaMetrics的默认界面,从这里可以选择跳转到其他界面,例如数据查询界面、targets页面等

配置Prometheus使用Victoriametrics
修改Prometheus配置,添加remote_write配置
global:
..........
remote_write:
- url: http://192.168.122.24:8428/api/v1/write
配置修改完成后重启Prometheus
systemctl restart prometheus
然后可以在Victoriametrics的界面,查询是否已经有数据写入
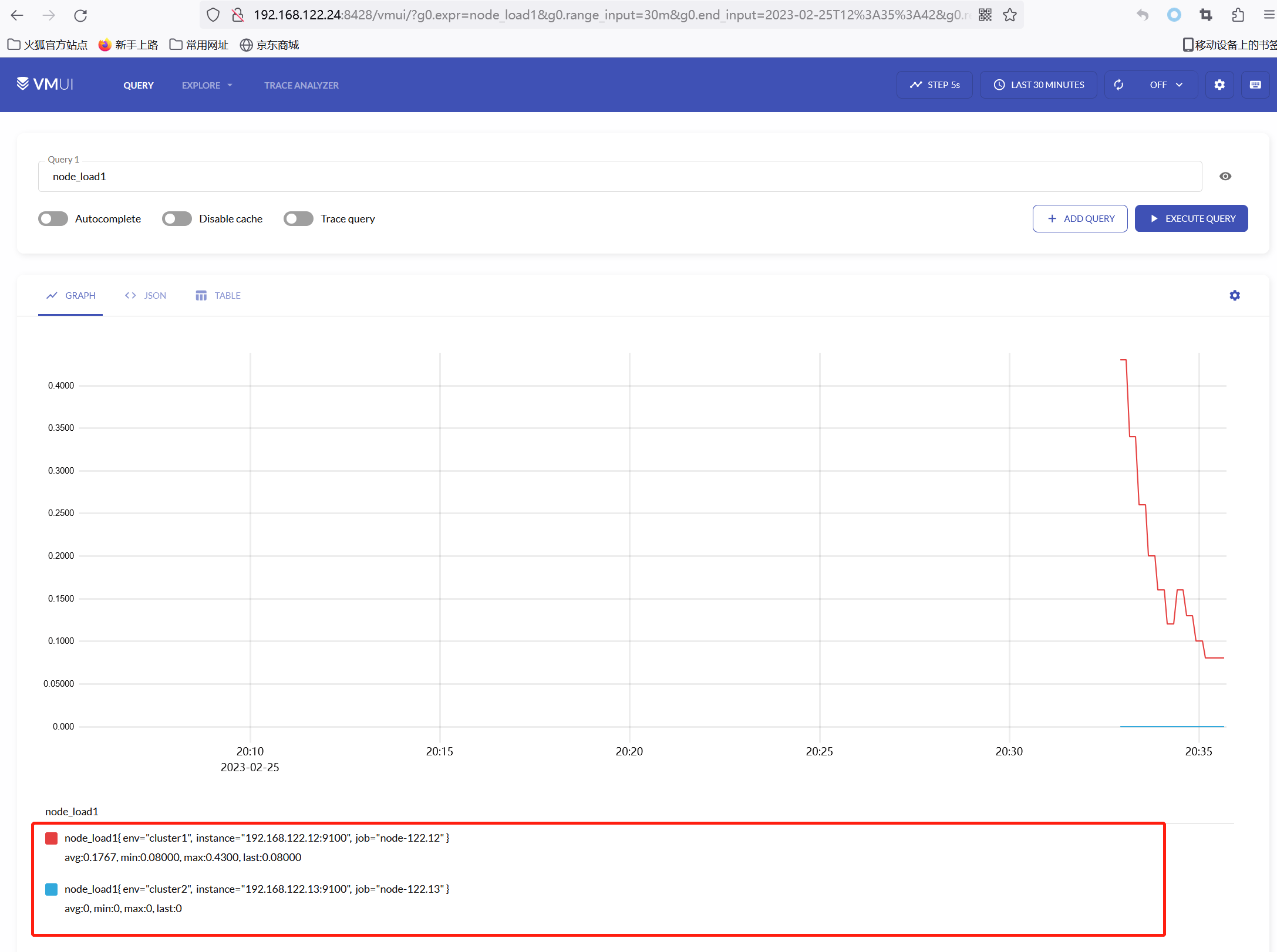
如上图所示,可以看到node-exporter的数据指标已经写入到Victoriametrics
配置Grafana以Victoriametrics作为数据源
添加数据源,类型选择Prometheus
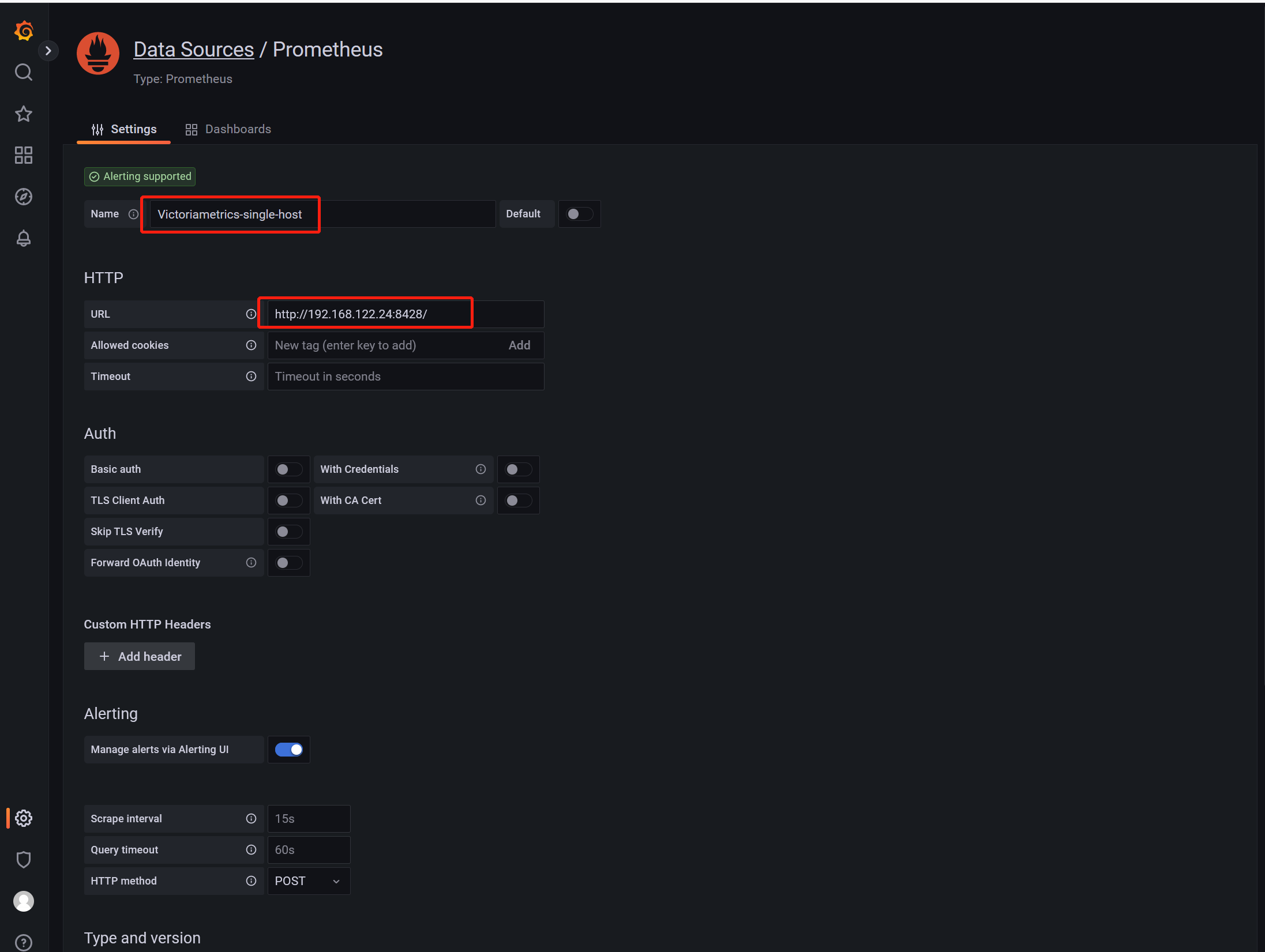
导入node-exporter模板验证数据,模板ID 11074
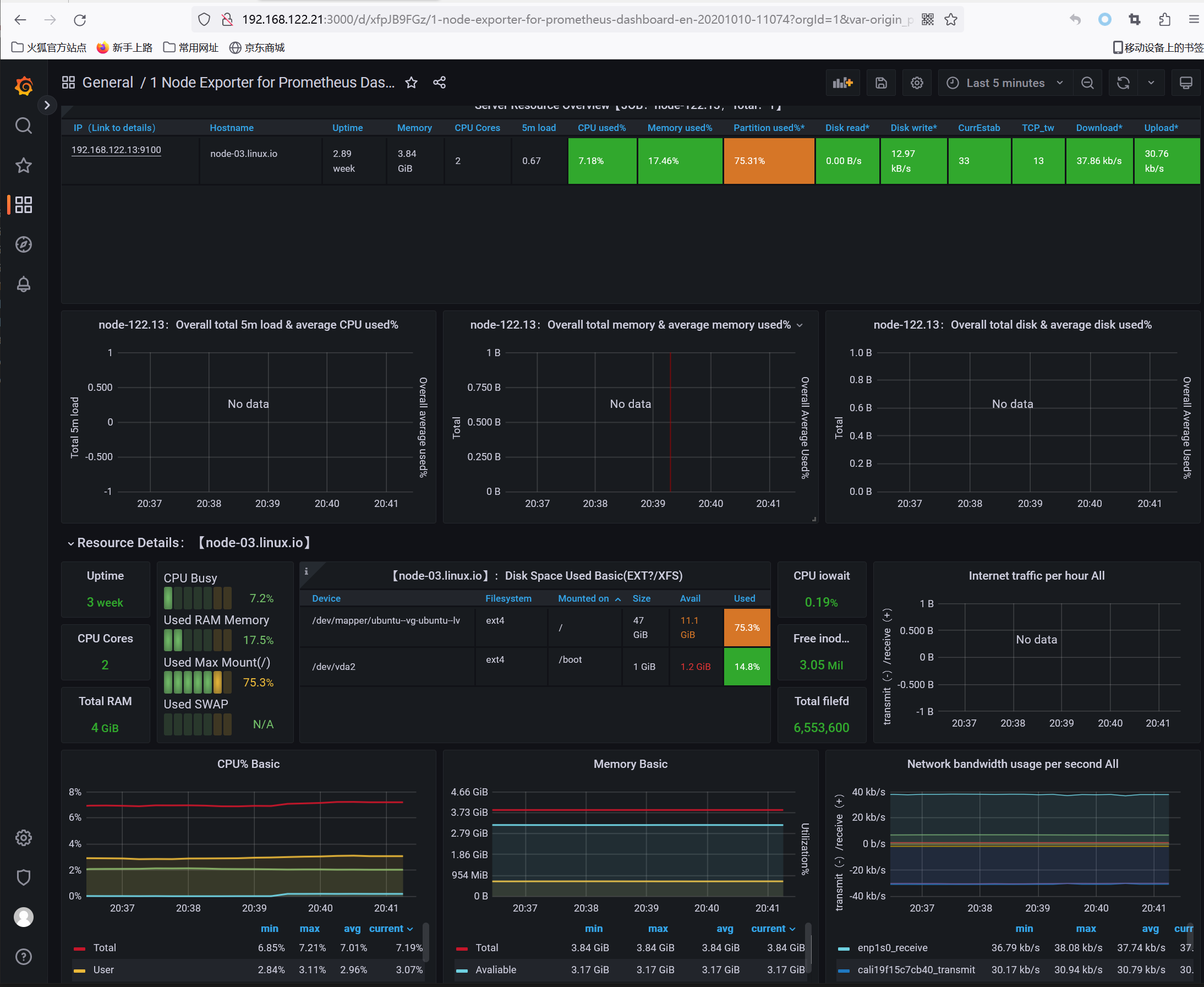
如上图所示,模板正常显示数据,表示可以从Victoriametrics单机获取数据
集群版部署使用
环境规划
192.168.122.24 vm-node-01 vmselect/vminsert/vmstorage
192.168.122.25 vm-node-02 vmselect/vminsert/vmstorage
192.168.122.26 vm-node-03 vmselect/vminsert/vmstorage
192.168.122.14 haproxy-node-01 haproxy/keepalived
192.168.122.15 haproxy-node-02 haproxy/keepalived
192.168.122.19 VIP
整体结构如下图:
分别在3个节点执行以下部署步骤
部署vmstorage
下载集群版的安装包
wget https://github.com/VictoriaMetrics/VictoriaMetrics/releases/download/v1.87.2/victoria-metrics-linux-amd64-v1.87.2-cluster.tar.gz
tar xf victoria-metrics-linux-amd64-v1.87.2-cluster.tar.gz
mv vminsert-prod vmselect-prod vmstorage-prod /usr/bin/
vmstorage-prod -h #查看运行参数
准备service文件
root@vm-node-01:~# cat /lib/systemd/system/vmstorage.service
[Unit]
Description=Vmstorage Server
After=network.target
[Service]
Restart=on-failure
WorkingDirectory=/tmp
ExecStart=/usr/bin/vmstorage-prod -loggerTimezone Asia/Shanghai -storageDataPath /data/vmstorage-data -httpListenAddr :8482 -vminsertAddr :8400 -vmselectAddr :8401
[Install]
WantedBy=multi-user.target
vmstorage会监听3个端口,8482是自身API端口;8400提供给vminsert,负责处理数据写入;8401提供给vmselect,负责数据读取。
启动vmstorage服务
mkdir --p /data/vmstorage-data
systemctl daemon-reload
systemctl start vmstorage.service
systemctl status vmstorage.service
systemctl enable vmstorage.service
部署vmselect
准备service文件
vmselect自身监听8481端口对外提供服务,-storageNode用于指定vmstorage地址
root@vm-node-01:~# cat /lib/systemd/system/vmselect.service
[Unit]
Description=Vmselect Server
After=network.target
[Service]
Restart=on-failure
WorkingDirectory=/tmp
ExecStart=/usr/bin/vmselect-prod -httpListenAddr :8481 -storageNode=192.168.122.24:8401,192.168.122.25:8401,192.168.122.26:8401
[Install]
WantedBy=multi-user.target
启动vmstorage服务
systemctl daemon-reload
systemctl start vmselect.service
systemctl status vmselect.service
systemctl enable vmselect.service
在haproxy中添加vmselect后端配置
listen vmselect-8481
bind 192.168.122.19:8481
option tcplog
mode tcp
balance source
server vmselect-node1 192.168.122.24:8481 check inter 2000 fall 3 rise 5
server vmselect-node2 192.168.122.25:8481 check inter 2000 fall 3 rise 5
server vmselect-node3 192.168.122.26:8481 check inter 2000 fall 3 rise 5
部署vminsert
准备service文件
vminsert自身监听8480端口对外提供服务,-storageNode用于指定vmstorage地址
root@vm-node-01:~# cat /lib/systemd/system/vminsert.service
[Unit]
Description=Vminsert Server
After=network.target
[Service]
Restart=on-failure
WorkingDirectory=/tmp
ExecStart=/usr/bin/vminsert-prod -httpListenAddr :8480 -storageNode=192.168.122.24:8400,192.168.122.25:8400,192.168.122.26:8400
[Install]
WantedBy=multi-user.target
启动服务
systemctl daemon-reload
systemctl start vminsert.service
systemctl status vminsert.service
systemctl enable vminsert.service
在haproxy中添加vminsert后端配置
listen vminsert-8480
bind 192.168.122.19:8480
option tcplog
mode tcp
balance source
server vminsert-node1 192.168.122.24:8480 check inter 2000 fall 3 rise 5
server vminsert-node2 192.168.122.25:8480 check inter 2000 fall 3 rise 5
server vminsert-node3 192.168.122.26:8480 check inter 2000 fall 3 rise 5
配置Prometheus使用vminsert
修改Prometheus配置,添加remote_write配置
global:
..........
remote_write:
- url: http://192.168.122.19:8480/insert/0/prometheus
配置修改完成后重启Prometheus
systemctl restart prometheus
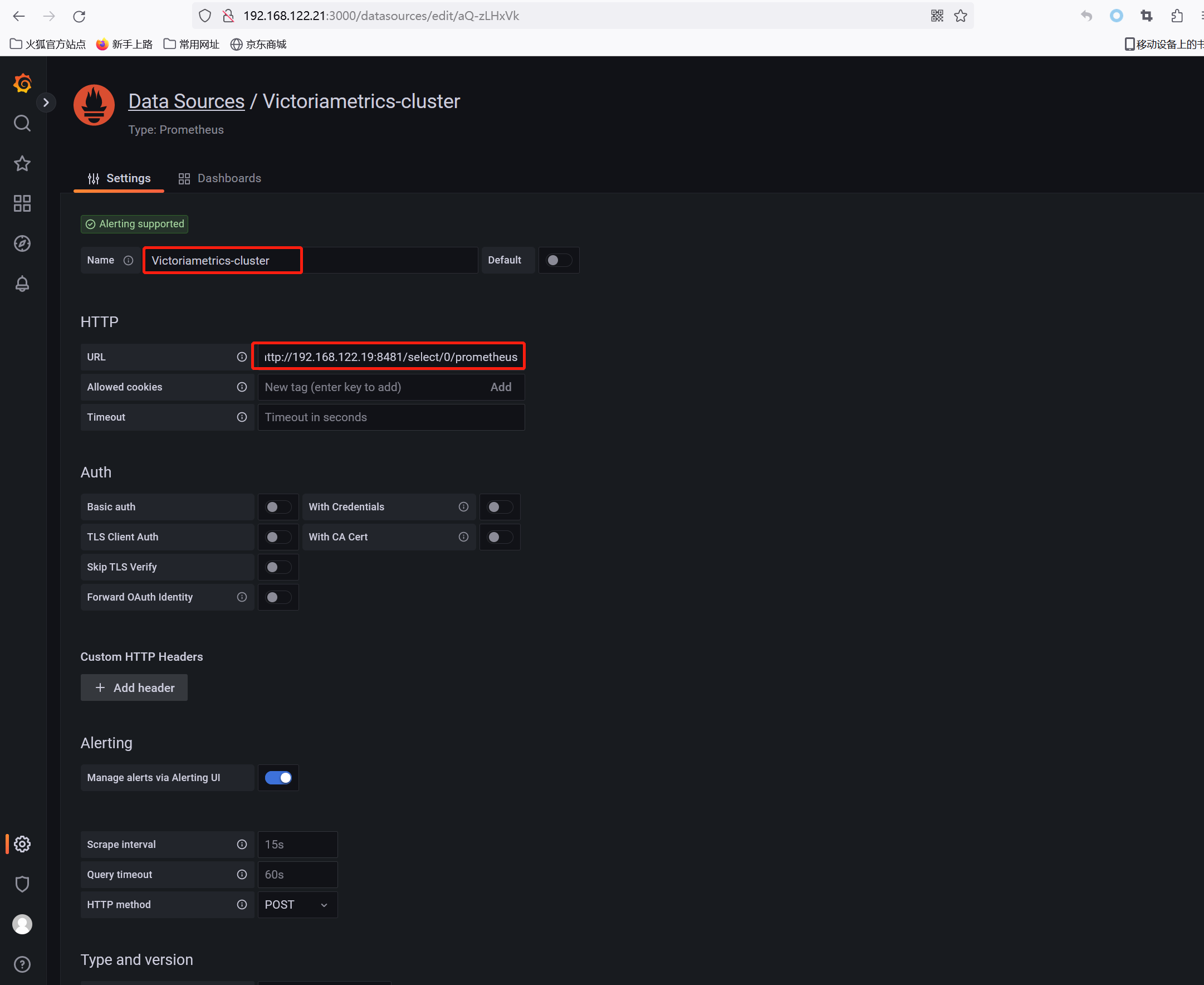
配置Grafana以vmselect为数据源
Grafana添加数据源
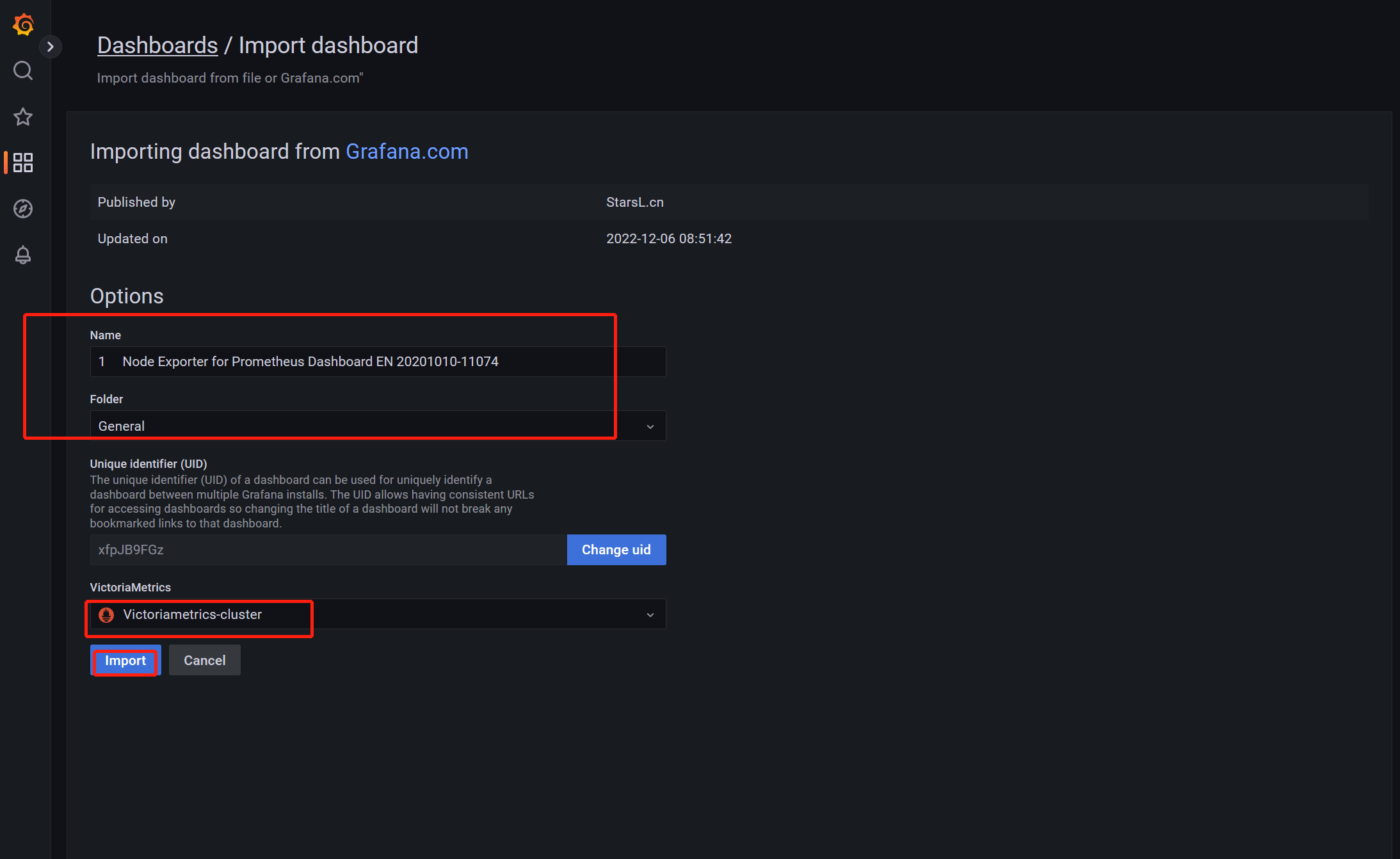
导入模板查看数据,模板ID 11074
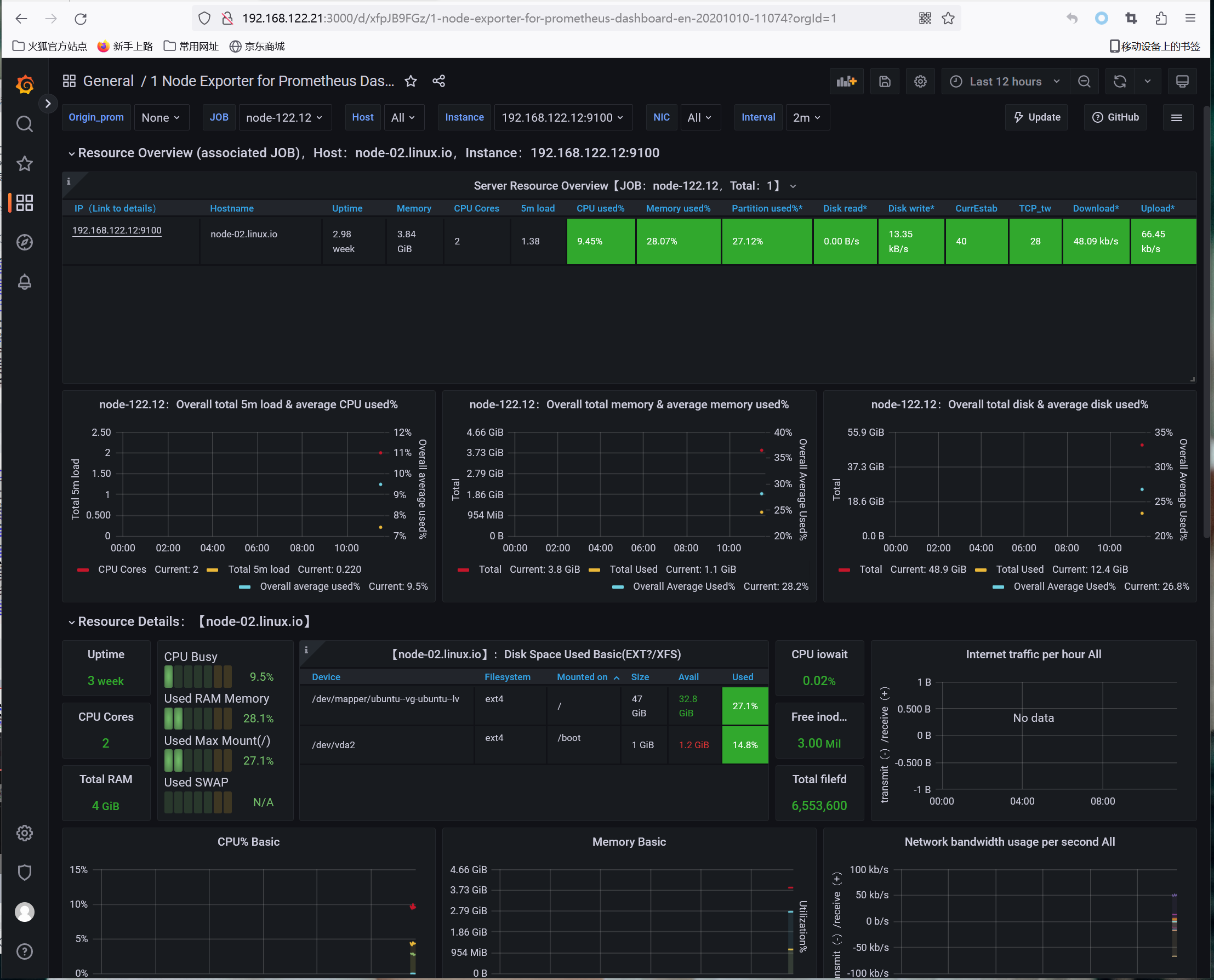
如上图所示,模板正常显示数据,表示可以从vmselect读取数据
开启数据复制
默认情况下,数据被vmselect组件基于hash算法分别写入到不同的vmstorage节点,数据只保存一份,如果有vmstorage节点宕机会造成部分数据丢失。可以启用vminsert组件的-replicationFactor=N参数启用复制功能,将数据分别在N个节点上都写入一份以实现数据的高可用。
但复制功能会增加vmselect和vminsert组件的资源使用率,因为vminsert需要写入多份数据,vmselect从多个vmstorage读取数据之后需要执行去重操作。官方建议还是将数据的高可用交给vmstorage数据存储路径的磁盘(例如使用ceph rbd),并定期备份数据
更多介绍可以参考官方文档: https://docs.victoriametrics.com/Cluster-VictoriaMetrics.html#replication-and-data-safety