文章目录
- 1.source
- 2.channel
- 3.sink
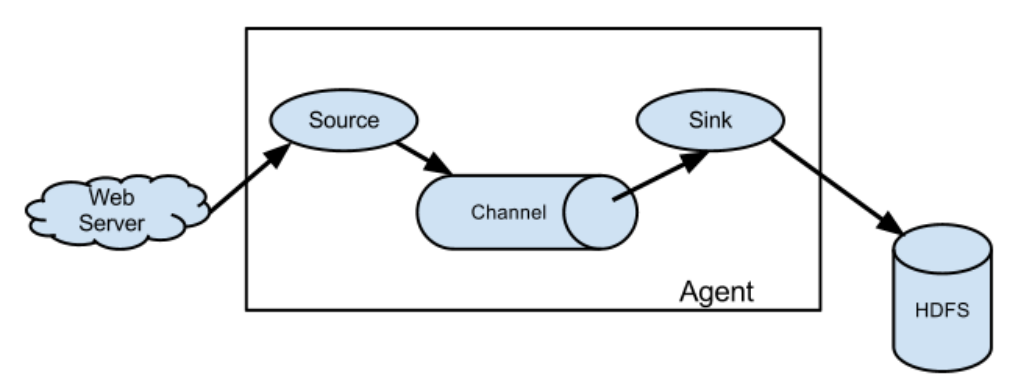
1.source
Source: 数据源:通过source组件可以指定让Flume读取哪里的数据,然后将数据传递给后面的 channel
Flume内置支持读取很多种数据源,基于文件、基于目录、基于TCP\UDP端口、基于HTTP、Kafka的 等等、当然了,如果这里面没有你喜欢的,他也是支持自定义的
1.taildir source: 实时读取文件数据,并且支持断点续传
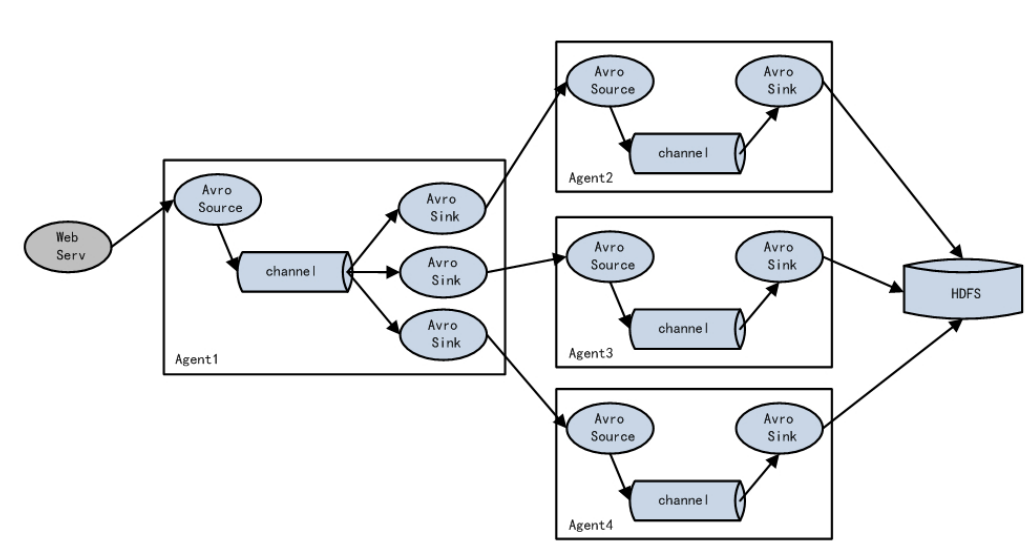
2.avro source: Flume之间互相进行数据传输一般配合avro sink使用
3.nc source: 接收网络端口的
4.exec source: 监控文件,不支持断点续传
5.spooling source: 监控文件夹,支持断点续传,传输进去一个写好的文件,丢进来是什么样就传输出去(时效性差)
6.kafka source: 读取kafka中的数据
2.channel
接受Source发出的数据,可以把channel理解为一个临时存储数据的管道
Channel的类型有很多:内存、文件,内存+文件、JDBC等
1.file channel:
慢,基于磁盘,但可以优化,有一个索引(在内存中)机制,从随机读写,到指定位置读写,索引也会备份到磁盘中,也可以进行二次备份
2.memory channel:
优点是效率高,因为就不涉及磁盘IO
缺点有两个
1:可能会丢数据,如果Flume的agent挂了,那么channel中的数据就丢失了。
2:内存是有限的,会存在内存不够用的情况
3.kafka channel: 数据存储在kafka集群
将数据发送到kafka消息队列中,这个也是比较常见的,主要针对实时计算场景,数据不落盘,实时传输,最后使用实时计算框架直接处理。
①结合source和sink使用
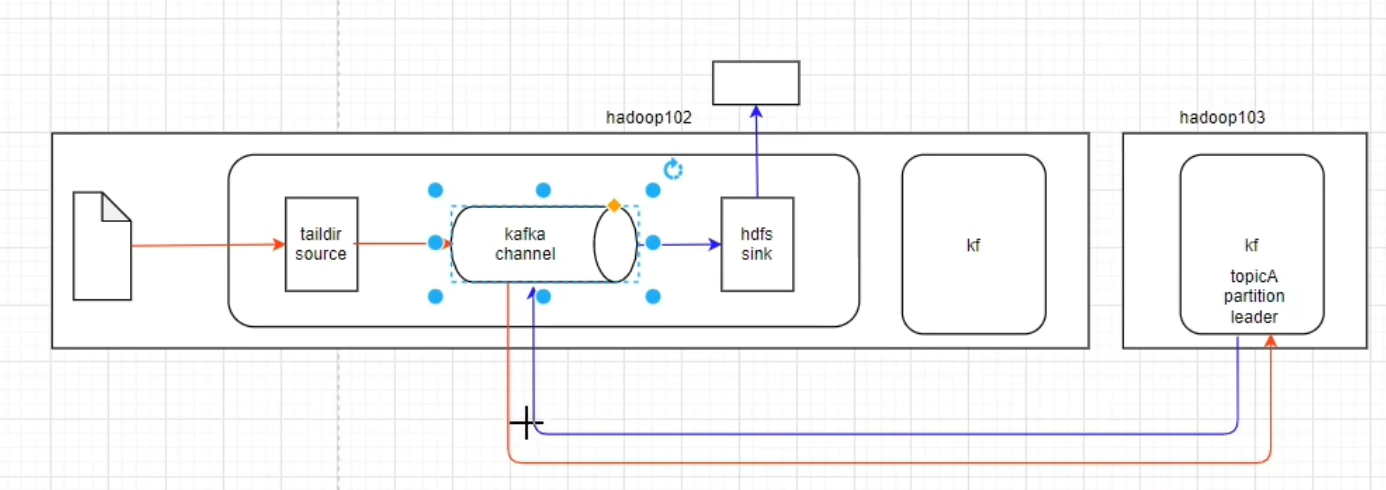
②结合source 和拦截器直接将数据写入到kafka中
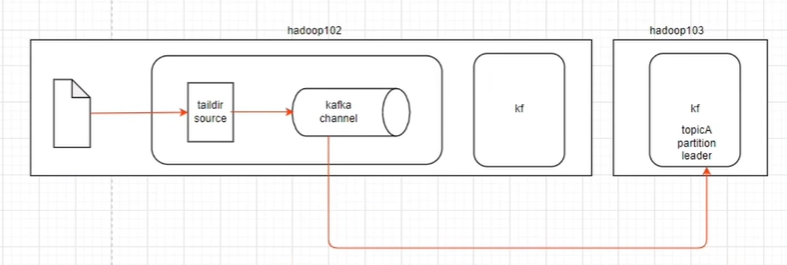
③直接使用kafka channel结合sink使用
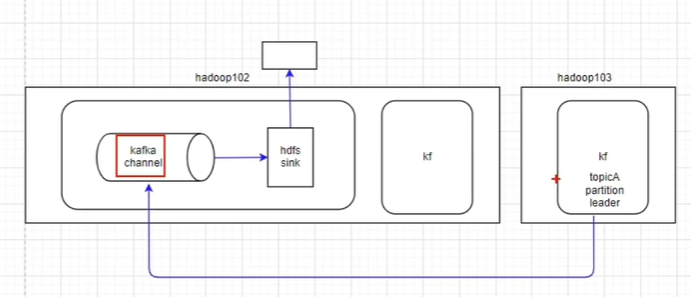
3.sink
从Channel中读取数据并存储到指定目的地
Sink的表现形式有很多:打印到控制台、HDFS、Kafka等,
1.hdfs sink
将数据传输到HDFS中,这个是比较常见的,主要针对离线计算的场景
2.kafka sink
将数据发送到kafka消息队列中,这个也是比较常见的,主要针对实时计算场景,数据不落盘,实时传输,最后使用实时计算框架直接处理。
3.avro sink
用于多个flume之间的信息传递