一、Redis定位与特性
Redis是一个速度非常快的非关系数据库(non-relational database),用 Key-Value 的形式来存储数据。数据主要存储在内存中,所以Redis的速度非常快,另外Redis也可以将内存中的数据持久化到硬盘上。
Redis主要特性:
1、速度快
Redis数据存放在内存中,读取速度非常快。
2、单线程
Redis使用单线程架构,避免了多线程可能产生的竞争开销
3、基于K-V的数据结构
Redis使用 Key-Value 的形式来存储数据
4、功能相对丰富
支持RDB和AOF两种持久化机制
支持多种键过期策略
支持Lua脚本
支持简单事务
支持发布订阅模式
5、高可用和分布式
Redis从2.8版本正式提供了高可用实现哨兵模式,可以保证Redis节点的故障发现和故障自动转移,
Redis从3.0版本后开始支持集群模式
支持主从复制
6、支持多种编程语言
Redis提供了简单的TCP通信协议,这样使得很多编程语言可以很方便的接入Redis
Redis基本操作命令:
#存值
set testkey testvalue
#取值
get testkey
#查看所有键
keys *
#获取键总数
dbsize
#查看键是否存在
exists testKey
#删除键
del testKey1 testKey2
#重命名键
rename oldkey newkey
#查看类型
type testkey
两个Redis命令学习网站
Redis 命令参考:http://redisdoc.com/index.html
Redis中文网站:http://www.redis.cn
二、Redis数据结构
Redis常用的基本数据结构有五种,分别是String、List、Hash、Set、Zset。其他数据类型还有Hyperloglog、Geo、Streams。
Redis的五种常用的数据类型底层结构如下图所示。
redis底层原理图:
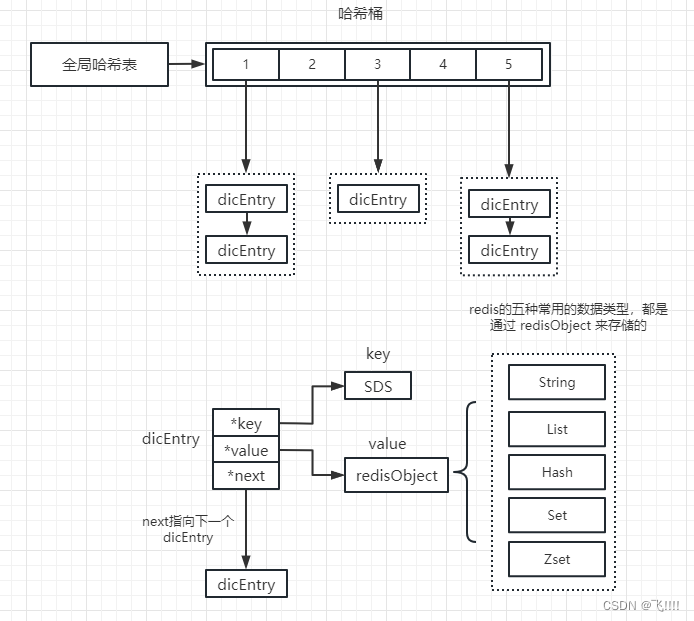
Redis是基于K-V的,它是通过hashtable实现的,这个叫做全局Hash表,每个键值对都是一个dictEntry,里面指向了key和value的指针。next指向下一个dictEntry。key是字符串,但是 Redis没有直接使用C的字符数组,而是存储在自定义的SDS
中。value既不是直接作为字符串存储,也不是直接存储在SDS中,而是存储在redisObject中。实际上五种常用的数据类型的任何一种,都是通过redisObject来存储的。
redisObject 源码:
typedef struct redisObject {
unsigned type:4; /* 对象的类型,包括:OBJ_STRING、OBJ_LIST、OBJ_HASH、OBJ_SET、OBJ_ZSET */
unsigned encoding:4; /* 具体的数据结构 */
unsigned lru:LRU_BITS; /* 24 位,对象最后一次被命令程序访问的时间,与内存回收有关 */
int refcount; /* 引用计数。当 refcount 为 0 的时候,表示该对象已经不被任何对象引用,则可以进行垃圾回收了
*/
void *ptr; /* 指向对象实际的数据结构 */
} robj;
1、String字符串
(1)存储类型
String类型可以用来存储字符串、整数、浮点数。
(2)操作命令
##带参数的命令 EX表示秒,PX表示毫秒,都是用来设置过期时间的,
##NX表示只在键不存在时, 才对键进行设置操作,等同于SETNX
##XX只在键已经存在时, 才对键进行设置操作。
set key value [expiration EX seconds|PX milliseconds][NX|XX]
#示例
set test abc EX 10 NX
#设置多个值(批量操作,原子性)
mset key1 a key1 b
#取多个值
mget key1 key2
#(整数)值递增
incr testkey
#(整数)值递增100
incrby testkey 100
#(整数)值递减
decr testkey
decrby testkey 100
#浮点数增量
set fkey 2.6
incrbyfloat fkey 7.3
#获取值长度
strlen key1
#字符串追加内容
append key1 hello
#获取指定范围的字符 0 -1 表示取所有
getrange key1 0 8
(3)底层原理
String类型的内部编码有三种:
1、int,存储 8 个字节的长整型(long,2^63-1)。
2、embstr, 存储小于 44 个字节的字符串。
3、raw,存储大于 44 个字节的字符串(3.2 版本之前是 39 字节)。
注:为啥是39可以查看该文章:https://www.zhihu.com/question/25624589
使用以下命令查看编码
#查看对外的类型,例如Sting、list
type k1
#查看内部的数据结构 例如embstr int
object encoding k1
其中embstr和raw实际上都是使用SDS(Simple Dynamic String 简单动态字符串)来存储的。
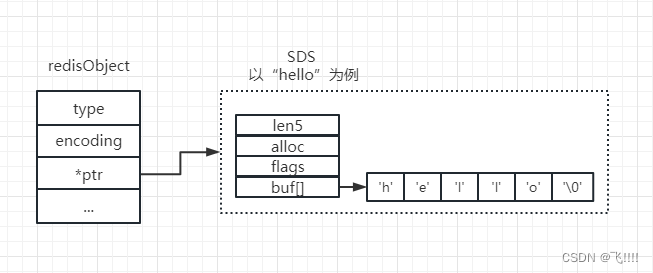
SDS
Redis 中字符串的实现。在3.2以后的版本中,SDS又有多种结构:sdshdr5、sdshdr8、sdshdr16、sdshdr32、sdshdr64,用于存储不同的长度的字符串,分别代表 25=32byte、28=256byte、216=65536byte=64KB、232=4GB。
SDS源码:
/* sds.h */
struct __attribute__ ((__packed__)) sdshdr8 {
uint8_t len; /* 当前字符数组的长度 */
uint8_t alloc; /*当前字符数组总共分配的内存大小 */
unsigned char flags; /* 当前字符数组的属性、用来标识到底是 sdshdr8 还是 sdshdr16 等 */
char buf[]; /* 字符串真正的值 */
};
SDS与C的字符数组对比
C 语言本身没有字符串类型(只能用字符数组 char[]实现)。
字符数组特点:
1、使用字符数组必须先给目标变量分配足够的空间,否则可能会溢出。
2、如果要获取字符长度,必须遍历字符数组,时间复杂度是 O(n)。
3、C 字符串长度的变更会对字符数组做内存重分配。
4、通过从字符串开始到结尾碰到的第一个’\0’来标记字符串的结束,因此不能保存图片、音频、视频、压缩文件等二进制(bytes)保存的内容,二进制不安全。
SDS的特点:
1、不用担心内存溢出问题,如果需要会对SDS进行扩容。
2、获取字符串长度时间复杂度为O(1),因为定义了len属性。
3、通过“空间预分配”( sdsMakeRoomFor)和“惰性空间释放”,防止多次重分配内存。
4、判断是否结束的标志是 len 属性(它同样以’\0’结尾是因为这样就可以使用C语言中函数库操作字符串的函数了),可以包含’\0’。
空间预分配:
空间预分配是用于优化 SDS 字符串增长操作的,简单来说就是当字节数组空间不足触发重分配的时候,总是会预留一部分空闲空间。
惰性空间释放:
惰性空间释放是用于优化 SDS 字符串缩短操作的。简单来说就是当字符串缩短时,并不立即使用内存重分配来回收多出来的字节,而是用 free 属性记录,等待将来使用。
| C字符数组 | SDS |
|---|---|
| 获取字符串长度的复杂度为 O(N) | 获取字符串长度的复杂度为 O(1) |
| API 是不安全的,可能会造成缓冲区溢出 | API 是安全的,不会早晨个缓冲区溢出 |
| 修改字符串长度N次必然需要执行N次内存重分配 | 修改字符串长度 N 次最多需要执行 N 次内存重分配 |
| 只能保存文本数据 | 可以保存文本或者二进制数据 |
| 可以使用所有<string.h>库中的函数 | 可以使用一部分<string.h>库中的函数 |
embstr和raw
1、embstr的使用只分配一次内存空间(因为RedisObject和SDS是连续的),而raw需要分配两次内存空间(分别为 RedisObject和 SDS分配空间)。因此embstr相比于raw,好处是在创建和删除时都会少操作一次空间分配或释放,而且空间是连续的,寻找方便。embstr的坏处是如果字符串的长度增加需要重新分配内存时,整个RedisObject和SDS都需要重新分配空间,因此Redis中的embstr实现为只读。
编码转换
1、当int数据不再是整数 , 或大小超过了long的范围(2^63-1)时,自动转化为embstr。
2、对于embstr,由于其实现是只读的,因此在对embstr对象进行修改(append)时,都会先转化为raw再进行修改。因此,只要是修改embstr对象,修改后的对象一定是raw的,无论是否达到了44个字节。
3、编码转换在Redis写入数据时完成,且转换过程不可逆,只能从小内存编码向大内存编码转换(但是不包括重新set)。
(4)使用场景
1、缓存。热点数据缓存
2、数据共享分布式。分布式 Session。
3、分布式锁。使用setnx
4、全局ID、计数器。使用INCRBY
5、位计算。使用BitMaps
2、Hash哈希
(1)存储类型
Redis的Hash类型适用于存储对象、字典等有多个子项的场景,类似于java中的map,每一个子项都是一个键值对。如下图所示。
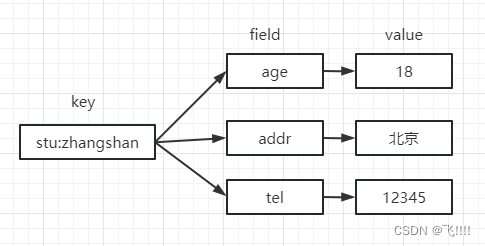
value 只能是字符串,不能嵌套其他类型。
同样是存储字符串,Hash相比于String的优缺点:
优点:
1、把相关的数据聚集到同一个key中,节省空间,并且减少key冲突。
2、获取批量值时,只需要一个命令,减少I/O操作的事件。
缺点:
1、field不能单独设置过期时间
2、没有bit操作
(2)操作命令
#设置值 hset key field value
hset k1 f1 a
#批量设置
hmset k1 f2 b f3 c f4 d
#获取
hget k1 f1
#批量获取
hmget k1 f1 f2 f3
#拿到k1的所以field
hkeys k1
#拿到k1的所有value
hvals k1
#拿到k1的所以 field-value
hgetall k1
#判断f1是否存在于k1中
hexists k1 f1
#删除field
hdel k1 f1 f2
#计算field的数量
hlen k1
(3)底层原理
Redis本身的K-V的实现使用了hashtable,称为全局哈希或者外层哈希(具体参考上文redis底层原理图)。而Redis的Hash本身也是一个K-V 的结构,类似于Java中的HashMap,称为内层的哈希,内层的哈希底层使用了两种数据结构:
ziplist:OBJ_ENCODING_ZIPLIST(压缩列表)
hashtable:OBJ_ENCODING_HT(哈希表)
ziplist 压缩列表
ziplist 是一个经过特殊编码的双向链表,它不存储指向上一个链表节点和指向下一个链表节点的指针,而是存储上一个节点长度和当前节点长度,通过牺牲部分读写性能,来换取高效的内存空间利用率,是一种时间换空间的思想。只用在字段个数少,字段值小的场景里面。
内部结构如下:
ziplist.c 源码第 16 行的注释:
*<zlbytes> <zltail> <zllen> <entry> <entry> … <entry> <zlend>

zlentry源码:
typedef struct zlentry {
unsigned int prevrawlensize; /* 上一个链表节点占用的长度 */
unsigned int prevrawlen; /* 存储上一个链表节点的长度数值所需要的字节数 */
unsigned int lensize; /* 存储当前链表节点长度数值所需要的字节数 */
unsigned int len; /* 当前链表节点占用的长度 */
unsigned int headersize; /* 当前链表节点的头部大小(prevrawlensize + lensize),即非数据域的大小 */
unsigned char encoding; /* 编码方式 */
unsigned char *p; /* 压缩链表以字符串的形式保存,该指针指向当前节点起始位置 */
} zlentry;
编码 encoding(ziplist.c 源码第 204 行)
#define ZIP_STR_06B (0 << 6) //长度小于等于 63 字节
#define ZIP_STR_14B (1 << 6) //长度小于等于 16383 字节
#define ZIP_STR_32B (2 << 6) //长度小于等于 4294967295 字节
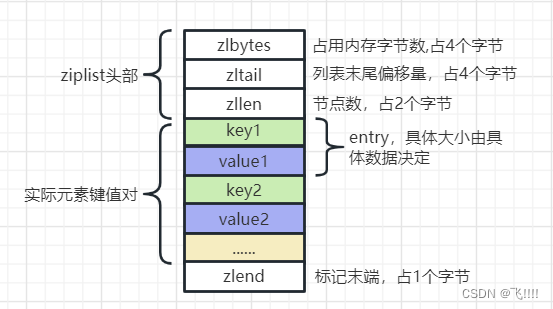
ziplist特点
1、ziplist结构本身就是一个连续的内存块,空间连续,避免内存碎片,节省内存。
2、也由于是使用的连续内存,不适合存储存储太大或者元素个数太多,这样会导致申请的内存块太大,使用起来不灵活
3、每次插入或删除一个元素时,都需要进行频繁的进行内存的扩展或减小,然后进行数据”搬移”,甚至可能引发连锁更新,造成严重效率的损失。
使用ziplist
当hash对象同时满足以下两个条件的时候,使用ziplist编码:
1、所有的键值对的健和值的字符串长度都小于等于64byte(一个英文字母
一个字节)
2、哈希对象保存的键值对数量小于512个。
hashtable
在Redis中,hashtable被称为字典(dictionary),它是一个数组+链表的结构。Redis的K-V结构是通过一个dictEntry来实现的,而Redis通过对dictEntry进行多次封装,构成Hash底层的另一种结构hashtable。
dictEntry源码:
typedef struct dictEntry {
void *key; /* key 关键字定义 */
union {
void *val; uint64_t u64; /* value 定义 */
int64_t s64; double d;
} v;
struct dictEntry *next; /* 指向下一个键值对节点 */
} dictEntry;
dictEntry 放到了 dictht:
typedef struct dictht {
dictEntry **table; /* 哈希表数组 */
unsigned long size; /* 哈希表大小 */
unsigned long sizemask; /* 掩码大小,用于计算索引值。总是等于 size-1 */
unsigned long used; /* 已有节点数 */
} dictht;
ht 放到了 dict 里面:
typedef struct dict {
dictType *type; /* 字典类型 */
void *privdata; /* 私有数据 */
dictht ht[2]; /* 一个字典有两个哈希表 */
long rehashidx; /* rehash 索引 */
unsigned long iterators; /* 当前正在使用的迭代器数量 */
} dict;
从最底层到最高层 dictEntry——dictht——dict.
原理如下图所示。
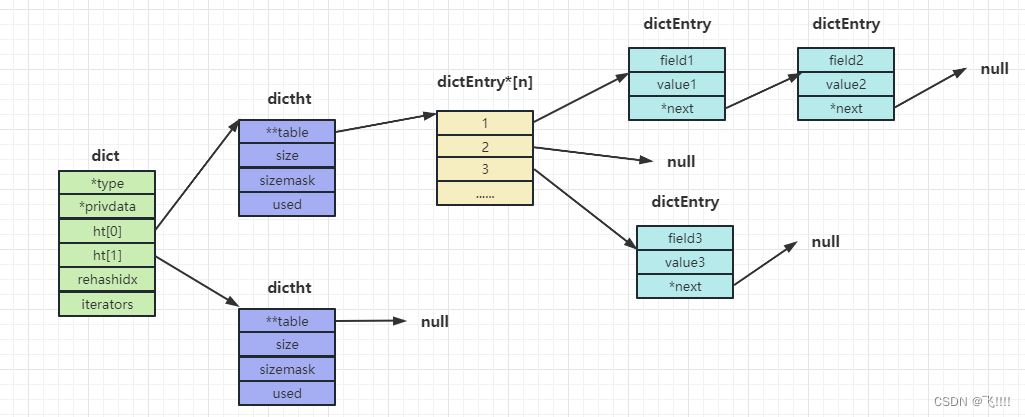
注:dictht 后面是NULL说明第二个 ht 还没用到。dictEntry*后面是NULL说明没有hash到这个地址。dictEntry 后面是NUL 说明没有发生哈希冲突。
扩容/缩容——rehash
Redis的Hash默认使用的是 ht[0],ht[1]不会初始化和分配空间。哈希表dictht是用链地址法来解决碰撞问题的,所以哈希表的性能取决于它的大小(size 属性)和它所保存的节点的数量(used 属性)之间的比率(也叫负载因子)。
- 比率在 1:1 时(一个哈希表 ht 只存储一个节点 entry),哈希表的性能最好;
- 如果节点数量比哈希表的大小要大很多的话(这个比例用 ratio 表示,5 表示平均一个 ht 存储 5 个 entry),那么哈希表就会退化成多个链表,哈希表本身的性能优势就不再存在。
在这种情况下需要扩容。相反的,当元素数量比较少的时候就需要缩容以节约不必要的内存。Redis 里面的这种操作叫做rehash。具体步骤如下:
1、为ht[1]哈希表分配空间,这个哈希表的空间大小取决于要执行的操作,以及 ht[0]当前包含的键值对的数量。
扩容,那么ht[1] 的大小为第一个大于等于ht[0] .used*2的2的n次幂
缩容,那么ht[1] 的大小为第一个大于等于ht[0].used 的2的n次幂
2、将所有的 ht[0]上的节点 rehash 到 ht[1]上,重新计算 hash 值和索引,然后放入指定的位置。
3、当 ht[0]的数据全部迁移到了ht[1]之后,释放 ht[0]的空间,将 ht[1]设置为 ht[0]表,然后创建新的 ht[1],为下次 rehash 做准备。
触发rehash的条件:
扩容:(满足任一即可)
- a)Redis服务器目前没有在执行BGSAVE或BGREWRITEAOF命令,并且哈希表的负载因子大于等于1。
- b)Redis服务器目前在执行BGSAVE或BGREWRITEAOF命令,并且哈希表的负载因子大于等于5。
缩容:哈希表的负载因子小于0.1
渐进式rehash
在元素数量较少时,rehash会非常快,但是当数据量非常大时,rehash会非常耗时,而且占用资源,可能会导致Redis在一段时间内停止服务。所以rehash这个动作不能一次性、集中式的完成,而是分多次、渐进式地完成。
步骤:
1、为ht[1]分配空间,让dict同时持有ht[0]和ht[1]两个哈希表。
2、在dict中有一个索引计数器变量rehashidx,将它的值设为0,表示rehash工作正式开始。
3、在rehash进行期间,每次对Hash做增删改查操作时,将ht[0]哈希表在rehashidx索引上的所有键值对rehash到ht[1],完成后,rehashidx+1。
4、当ht[0]上所有的键值对都被rehash到ht[1]后,将rehashidx属性的值设为-1,表示rehash完成。
(4)使用场景
购物车:
key:用户id
field-value:商品id-商品数量
3、List列表
(1)存储类型
存储有序的字符串,元素可以重复。可以充当队列和栈的角色。数据总容量是有限的,最多 2^32-1个元素 (40 亿左右)。
(2)操作命令
#将一个或多个值value插入到列表的表头(从左插入)
lpush listkey v1 v2
#将一个或多个值value插入到列表的表尾(从右插入)
rpush listkey v1 v2
#从列表的表头移除并返回第一个元素(从左取出)
lpop listkey
#从列表的表尾移除并返回第一个元素(从右取出)
rpop listkey
#阻塞式的lpop,当给定列表内没有任何元素可供弹出的时候,连接将被 BLPOP 命令阻塞,直到等待超时或发现可弹出元素为止
blpop listkey
#阻塞式的rpop,当给定列表内没有任何元素可供弹出的时候,连接将被 BRPOP 命令阻塞,直到等待超时或发现可弹出元素为止
brpop listkey
#返回列表的长度
llen listkey
#将listkey下表为0的元素设置为v1
lset listkey 0 v1
#返回列表下标为1的元素(不会移除)
lindex listkey 1
#返回列表指定区间的元素(不会移除)-1表示末尾元素
lrange listkey 0 -1
(3)底层原理
在早期版本中,数据量较小时用ziplist存储,达到临界值时转换为linkedlist进行存储,分别对应 OBJ_ENCODING_ZIPLIST和OBJ_ENCODING_LINKEDLIST。3.2版本之后,统一用quicklist来存储。quicklist存储了一个双向链表,每个节点都是一个ziplist。
quicklist
quicklist(快速列表)是ziplist和linkedlist的结合体。
quicklist源码:
typedef struct quicklist {
quicklistNode *head; /* 指向双向列表的表头 */
quicklistNode *tail; /* 指向双向列表的表尾 */
unsigned long count; /* 所有的 ziplist 中一共存了多少个元素 */
unsigned long len; /* 双向链表的长度,node 的数量 */
int fill : 16; /* fill factor for individual nodes */
unsigned int compress : 16; /* 压缩深度,0:不压缩; */
} quicklist;
quicklist由一个个的quicklistNode双向链表节点构成,head和tail指向双向链表的表头和表尾元素。
quicklistNode源码:
typedef struct quicklistNode {
struct quicklistNode *prev; /* 前一个节点 */
struct quicklistNode *next; /* 后一个节点 */
unsigned char *zl; /* 指向实际的 ziplist */
unsigned int sz; /* 当前 ziplist 占用多少字节 */
unsigned int count : 16; /* 当前 ziplist 中存储了多少个元素,占 16bit(下同),最大 65536 个 */
unsigned int encoding : 2; /* 是否采用了 LZF 压缩算法压缩节点,1:RAW 2:LZF */
unsigned int container : 2; /* 2:ziplist,未来可能支持其他结构存储 */
unsigned int recompress : 1; /* 当前 ziplist 是不是已经被解压出来作临时使用 */
unsigned int attempted_compress : 1; /* 测试用 */
unsigned int extra : 10; /* 预留给未来使用 */
} quicklistNode;
原理图如下:
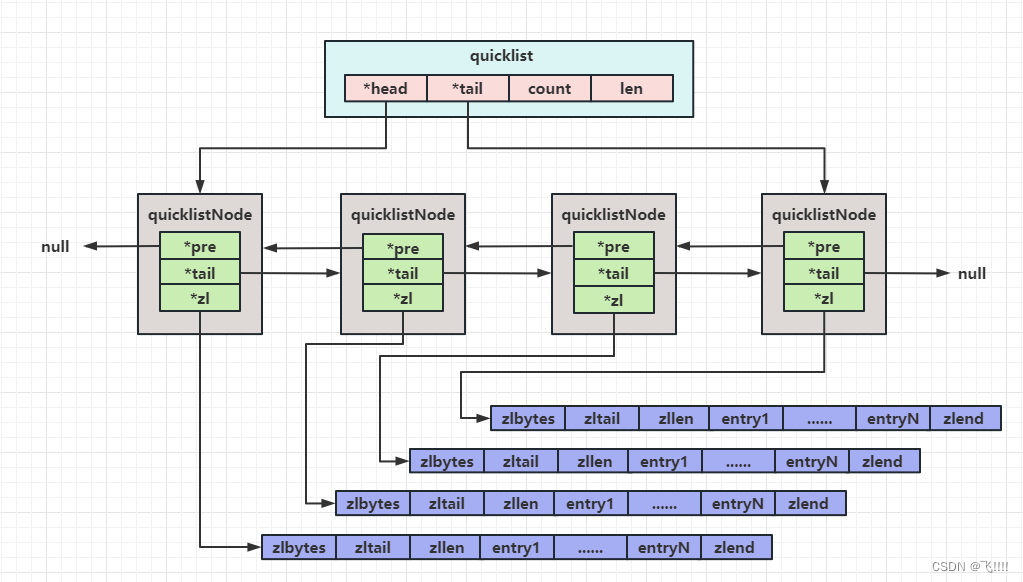
ziplist原理参考上文Hash的底层原理。
(4)使用场景
1、消息队列。rpush lpop,左进右出。先进先出
2、栈。rpush rpop。坐进左出,先进后出。
4、Set 集合
(1)存储类型
String或者int类型的无序集合,最大存储数量 2^32-1(40 亿左右)。
(2)操作命令
#添加一个或者多个元素
sadd myset a b c d e f g
#获取所有元素
smembers myset
#统计元素个数
scard myset
#随机获取一个元素
srandmember key
#随机移除并返回一个元素
spop myset
#移除一个或者多个元素
srem myset d e f
#查看元素是否存在
sismember myset a
(3)底层原理
Redis用intset或hashtable存储set。如果元素都是整数类型,就用intset存储。如果不是整数类型,就用 hashtable,如果元素个数超过 512 个,也会用 hashtable 存储。
intset
源码:
typedef struct intset {
uint32_t encoding; // 编码方式
uint32_t length; // 集合中元素的个数,也就是contents数组的长度
int8_t contents[]; // 保存元素的数组
} intset;
contents数组是整数集合的底层实现:整数集合中的每一个元素就是contents数组中的一个元素,每个元素在数组中按照从小到大的顺序排列,并且没有重复元素。
hashtable
hashtable的原理查看上文Hash的底层原理章节。这里不再复述。不同的是set集合里的元素存在key上,value上为null。
(4)使用场景
1、抽奖。spop随机取值
2、点赞、签到、打卡等。用户id集合
3、商品标签。标签集合。
4、商品筛选。不同属性的商品集合取交集、差集、并集。
5、ZSet 有序集合
zset和set一样是不可重复的,区别在于多了score值,用来代表排序的权重,当score相同时,按照 key的 ASCII码排序。
(1)存储类型
同set。
(2)操作命令
#添加元素
zadd testkey 10 a 30 b 40 c 60 d 20 e
#获取指定区间内的元素,按score值从小到大
zrange testkey 0 -1 withscores
#获取指定区间内的元素,按score值从大到小
zrevrange testkey 0 -1 withscores
#根据分值区间获取元素
zrangebyscore testkey 10 40
#移除元素
zrem testkey a b
#统计元素个数
zcard testkey
#增加元素的sorce值
zincrby testkey 10 d
#根据分值统计个数
zcount testkey 10 60
#获取元素排名
zrank testkey e
#获取元素 score
zsocre testkey d
(3)底层原理
zset的编码有两种,分别是:ziplist、skiplist。当zset的长度小于 128,并且所有元素的长度都小于 64 字节时,使用ziplist存储;否则使用 skiplist 存储。
ziplist
ziplist原理查看上文,这里不再复述。zset使用ziplist时,在ziplist的内部,按照 score 排序递增来存储。插入的时候要移动之后的数据。
skiplist
skiplist也叫跳跃表,了解skiplist前先来看一下有序链表,如下图。

在有序链表中,如果我们要查找某个数据,那么需要从头开始逐个进行比较,直到找到包含数据的那个节点,或者找到第一个比给定数据大的节点为止(没找到)。也就是说,时间复杂度为 O(n)。同样,当我们要插入新数据的时候,也要经历同样的查找过程,从而确定插入位置。而二分查找法只适用于有序数组,不适用于链表。
这时候假如我们每相邻两个节点增加一个指针,让指针指向下下个节点,这样所有新增加的指针在原来的基础上连成了一个新的链表,但它包含的节点个数只有原来的一半。如果这时候数据量还是很大,再通过这种方式形成一层新的链表,直到最新的链表足够小。
原理如下图所示:

假如我们要插入70,步骤如下:
1、查询L3层,比较1,45,99,共三次。
2、查询L2层,比较88,共一次
3、查询L1层,比较67,共一次。
4、确定70需要插入在67-88之间。
时间复杂度为O(logN)
(4)应用场景
1.延时队列。score作为时间戳,自动按照时间最近的进行排序,启一个线程持续poll并设置park时间,完成延迟队列的设计。
2.排行榜,score作为浏览次数,自动进行排序,但要注意冷数据。
3.滑动窗口限流,score作为时间戳,可统计最近一段时间内内的成员数量,实现滑动窗口限流。
6、其他数据结构
BitMaps
Bitmaps是在字符串类型上面定义的位操作。一个字节由 8 个二进制位组成。
#a 对应的 ASCII 码是 97,转换为二进制数据是 01100001
set k1 a
#获取k1第0位的bit值
getbit k1 0
#修改二进制数据(b 对应的 ASCII 码是 98,转换为二进制数据是 01100010)
setbit k1 6 1
setbit k1 7 0
get k1
#统计二进制位中 1 的个数
bitcount k1
#获取第一个 1 或者 0 的位置
bitpos k1 1
bitpos k1 0
Geospatial
地理位置的存储(经纬度)。
#设置地理位置信息
geoadd location 116.39135 39.90737 tiananmen
#获取地理位置信息
geopos location tiananmen
Hyperloglogs
提供了一种不太准确的基数统计方法,可以用来统计app的日活,月活等。HyperLogLog 的优点是,在输入元素的数量或者体积非常非常大时,计算基数所需的空间总是固定 的、并且是很小的。在 Redis 里面,每个 HyperLogLog 键只需要花费 12 KB 内存,就可以计算接近 2^64 个不同元素的基 数。这和计算基数时,元素越多耗费内存就越多的集合形成鲜明对比。
Streams
5.0 推出的数据类型。支持多播的可持久化的消息队列,用于实现发布订阅功能,借
鉴了 kafka 的设计。
7、总结
数据结构:
| 对象 | 对象type属性值 | type命令输出 | 底层可能的存储结构 | object encoding |
|---|---|---|---|---|
| 字符串对象 | OBJ_STRING | “string” | OBJ_ENCODING_INT、OBJ_ENCODING_EMBSTR、OBJ_ENCODING_RAW | int、embstr、raw |
| 列表对象 | OBJ_LIST | “list” | OBJ_ENCODING_QUICKLIST | quicklist |
| 哈希对象 | OBJ_HASH | “hash” | OBJ_ENCODING_ZIPLIST、OBJ_ENCODING_HT | ziplist、hashtable |
| 集合对象 | OBJ_SET | “set” | OBJ_ENCODING_INTSET、OBJ_ENCODING_HT | intset、hashtable |
| 有序集合对象 | OBJ_ZSET | “zset” | OBJ_ENCODING_ZIPLIST、OBJ_ENCODING_SKIPLIST | ziplist、skiplist |
![[SSD综述 1.3] SSD及固态存储技术半个世纪发展史](https://img-blog.csdnimg.cn/img_convert/7b9e77a9b0fd4e8588ca6ceb7298ee39.png)