redis为什么快?
首先可以想到内存读写数据本来就快,然后IO复用快,单线程没有静态消耗和锁机制快。
还有就是数据结构的设计快。这是因为,键值对是按一定的数据结构来组织的,操作键值对最终就是对数据结构进行增删改查操作,所以高效的数据结构是 Redis 快速处理数据的基础。
redis的值的数据类型:就是 String(字符串)、List(列表)、Hash(哈希)、Set(集合)和 Sorted Set(有序集合)。而这里,我们说的数据结构,是要去看看它们的底层实现。
底层数据结构一共有 6 种,分别是简单动态字符串、双向链表、压缩列表、哈希表、跳表和整数数组。它们和数据类型的对应关系如下图所示:
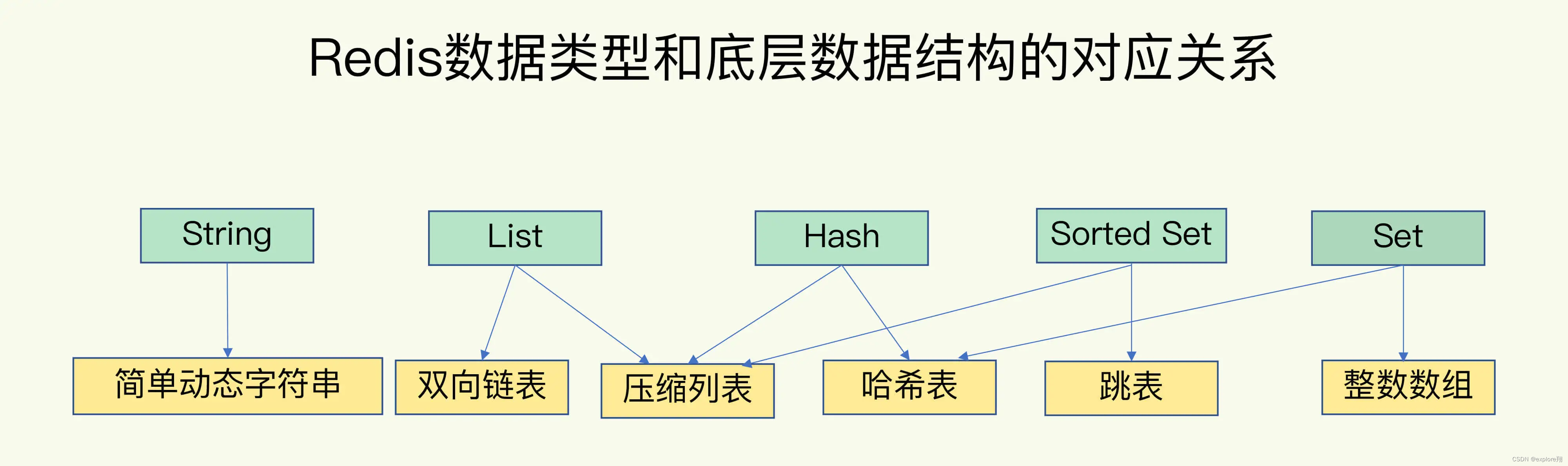
可以看到,String 类型的底层实现只有一种数据结构,也就是简单动态字符串。而 List、Hash、Set 和 Sorted Set 这四种数据类型,都有两种底层实现结构。通常情况下,我们会把这四种类型称为集合类型,它们的特点是一个键对应了一个集合的数据。(这里应该是错的,有序集合使用了压缩列表、哈希表、跳表三种数据结构,并且哈希表和跳表共存,哈希表是为了点查使用,跳表是为了扫描使用。)
这些都是值的底层结构,那么键和值怎么组织的?
为了实现从键到值的快速访问,Redis 使用了一个哈希表来保存所有键值对。
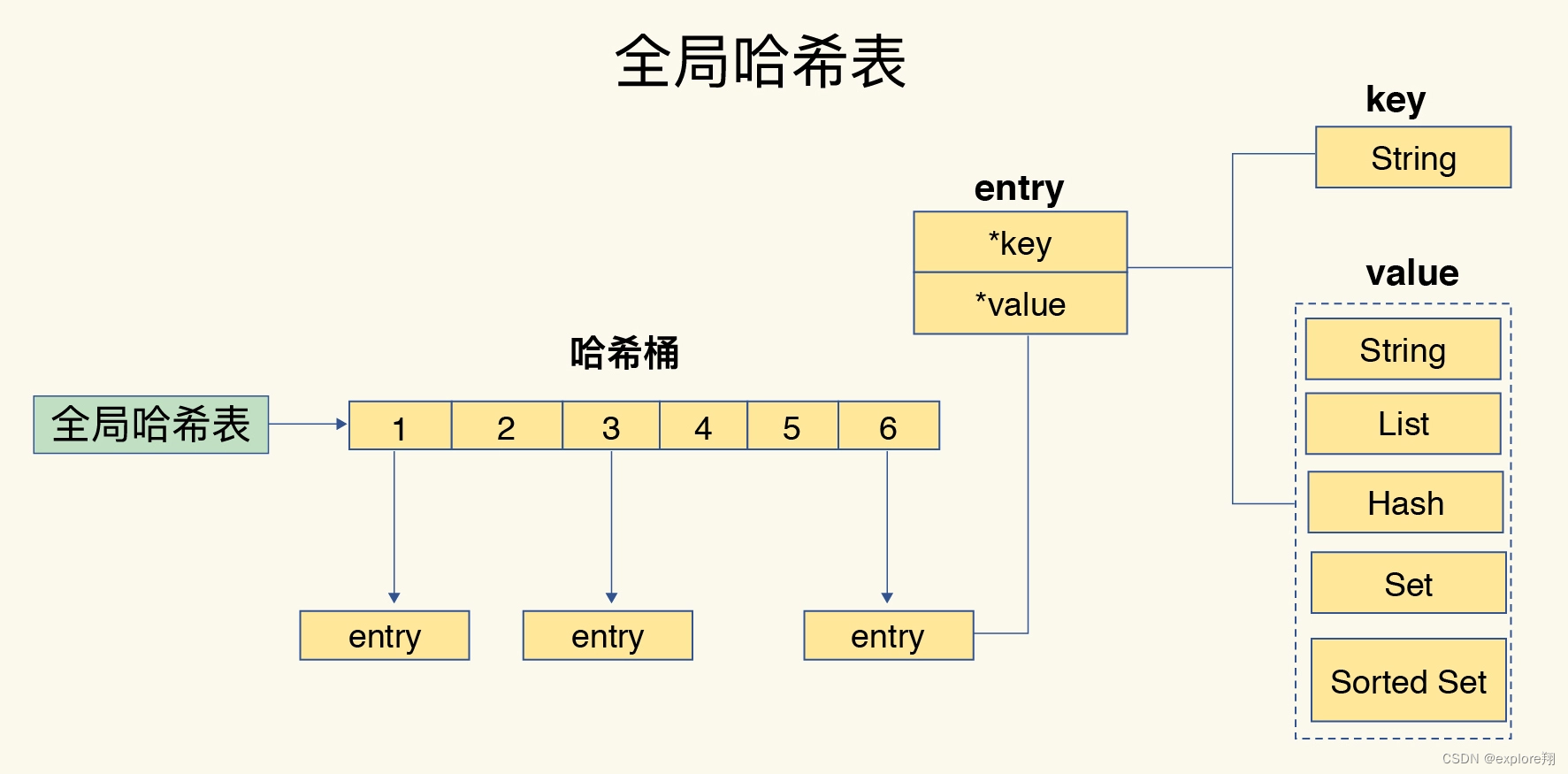
哈希表的最大好处很明显,就是让我们可以用 O(1) 的时间复杂度来快速查找到键值对——我们只需要计算键的哈希值,就可以知道它所对应的哈希桶位置,然后就可以访问相应的 entry 元素。
为什么哈希表操作变慢了?
这其实是因为你忽略了一个潜在的风险点,那就是哈希表的冲突问题和 rehash 可能带来的操作阻塞。
如果采用拉链法的话,数据太多,拉链太长,就会增加查找时间,就不快了。
所以采用的是rehash法。Redis 默认使用了两个全局哈希表:哈希表 1 和哈希表 2。一开始,当你刚插入数据时,默认使用哈希表 1,此时的哈希表 2 并没有被分配空间。随着数据逐步增多,Redis 开始执行 rehash,这个过程分为三步:给哈希表 2 分配更大的空间,例如是当前哈希表 1 大小的两倍;把哈希表 1 中的数据重新映射并拷贝到哈希表 2 中;释放哈希表 1 的空间。
第二步设涉及的拷贝操作很多,会造成 Redis 线程阻塞,无法服务其他请求。
所以是渐进式rehash。第二步是每处理一次客户端请求,把一个数组的位置进行转移。
压缩列表
压缩列表实际上类似于一个数组,数组中的每一个元素都对应保存一个数据。和数组不同的是,压缩列表在表头有三个字段 zlbytes、zltail 和 zllen,分别表示列表长度、列表尾的偏移量和列表中的 entry 个数;压缩列表在表尾还有一个 zlend,表示列表结束。

在压缩列表中,如果我们要查找定位第一个元素和最后一个元素,可以通过表头三个字段的长度直接定位,复杂度是 O(1)。而查找其他元素时,就没有这么高效了,只能逐个查找,此时的复杂度就是 O(N) 了。
跳表
具体来说,跳表在链表的基础上,增加了多级索引,通过索引位置的几个跳转,实现数据的快速定位,如下图所示:
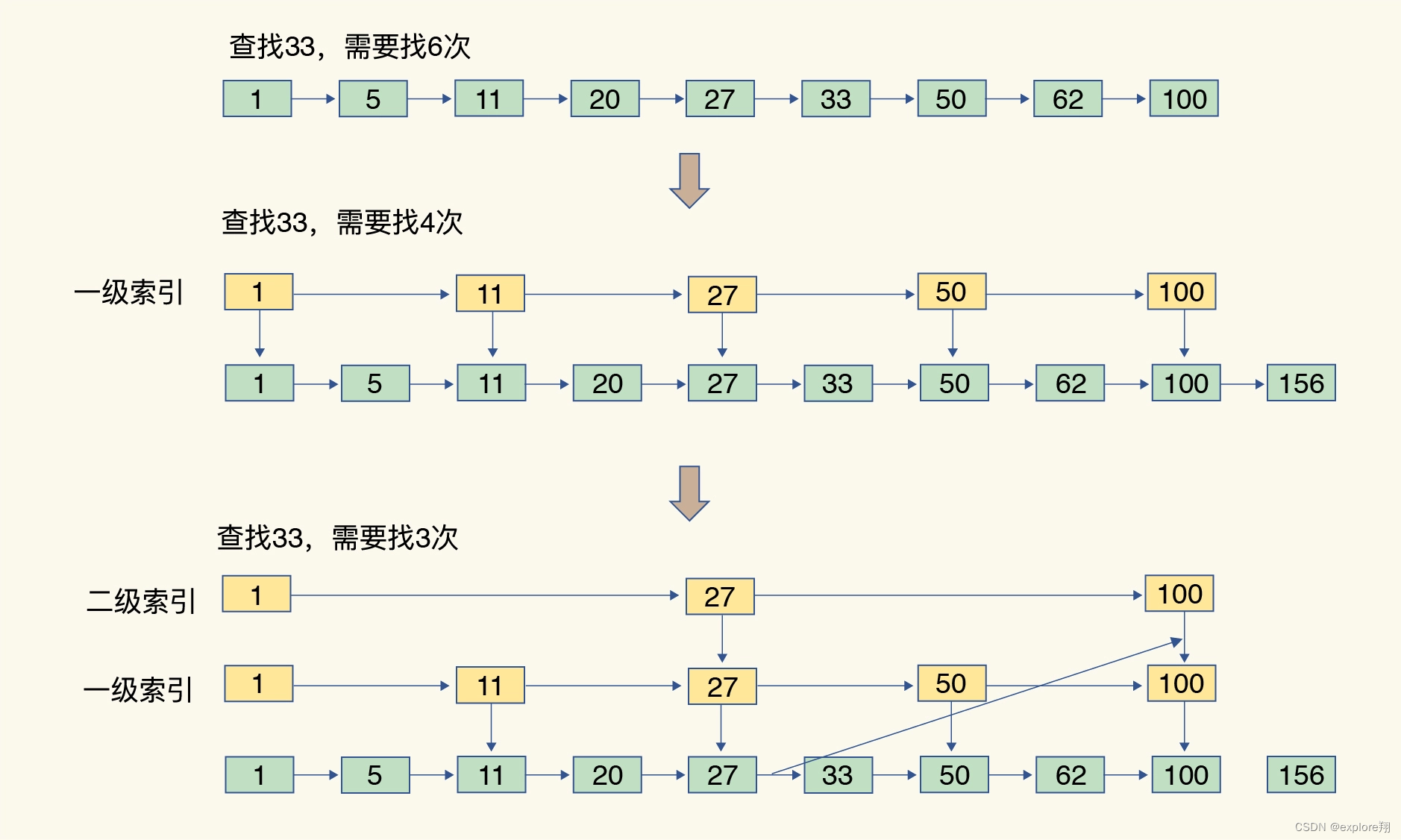
可以看到,这个查找过程就是在多级索引上跳来跳去,最后定位到元素。这也正好符合“跳”表的叫法。当数据量很大时,跳表的查找复杂度就是 O(logN)。
(其实是空间换时间的做法,而且链表必须是有序的)
操作复杂度分析
1.单元素操作,是指每一种集合类型对单个数据实现的增删改查操作。例如,Hash 类型的 HGET、HSET 和 HDEL,Set 类型的 SADD、SREM、SRANDMEMBER 等。这些操作的复杂度由集合采用的数据结构决定,例如,HGET、HSET 和 HDEL 是对哈希表做操作,所以它们的复杂度都是 O(1);Set 类型用哈希表作为底层数据结构时,它的 SADD、SREM、SRANDMEMBER 复杂度也是 O(1)。
2、范围操作,是指集合类型中的遍历操作,可以返回集合中的所有数据,比如 Hash 类型的 HGETALL 和 Set 类型的 SMEMBERS,或者返回一个范围内的部分数据,比如 List 类型的 LRANGE 和 ZSet 类型的 ZRANGE。这类操作的复杂度一般是 O(N),比较耗时,我们应该尽量避免(不过,Redis 从 2.8 版本开始提供了 SCAN 系列操作(包括 HSCAN,SSCAN 和 ZSCAN),这类操作实现了渐进式遍历,每次只返回有限数量的数据。这样一来,相比于 HGETALL、SMEMBERS 这类操作来说,就避免了一次性返回所有元素而导致的 Redis 阻塞。)
3、统计操作,是指集合类型对集合中所有元素个数的记录,例如 LLEN 和 SCARD。这类操作复杂度只有 O(1),这是因为当集合类型采用压缩列表、双向链表、整数数组这些数据结构时,这些结构中专门记录了元素的个数统计,因此可以高效地完成相关操作。
第四,例外情况,是指某些数据结构的特殊记录,例如压缩列表和双向链表都会记录表头和表尾的偏移量。这样一来,对于 List 类型的 LPOP、RPOP、LPUSH、RPUSH 这四个操作来说,它们是在列表的头尾增删元素,这就可以通过偏移量直接定位,所以它们的复杂度也只有 O(1),可以实现快速操作。
总结:数据结构为什么快,因为采用了全局哈希表可以快速定位key-value。然后value的数据结构很多采用哈希表实现(比如hash,set,sortedset)。而且有序集合采用了跳表实现logn级别的查找复杂度。当需要遍历时最好用SCAN,比较快。FIFO类型可以用list
问题:整数数组和压缩列表在查找时间复杂度方面并没有很大的优势,那为什么 Redis 还会把它们作为底层数据结构呢?
**内存利用率,数组和压缩列表都是非常紧凑的数据结构,**它比链表占用的内存要更少。Redis是内存数据库,大量数据存到内存中,此时需要做尽可能的优化,提高内存的利用率。
数组对CPU高速缓存支持更友好,所以Redis在设计时,集合数据元素较少情况下,默认采用内存紧凑排列的方式存储,同时利用CPU高速缓存不会降低访问速度。当数据元素超过设定阈值后,避免查询时间复杂度太高,转为哈希和跳表数据结构存储,保证查询效率。
(Redis底层的使用数组和压缩链表对数据大小限制在64个字节以下,当大于64个字节会改变存储数据的数据结构,所以随机访问对于CPU高速缓存没啥影响)










![交换字符使得字符串相同[贪心]](https://img-blog.csdnimg.cn/2697794abadd4002bd7f0c3f9f4c2149.png)