数据仓库是企业级的,能为整个企业各个部门的运作提供决策支持;而数据集市则是部门级的,一般只能为某个局部范围内的管理人员服务,因此也称之为部门级数据仓库。
1、两种数据集市结构
数据集市按数据的来源分为以下两种
(1)从属数据集市
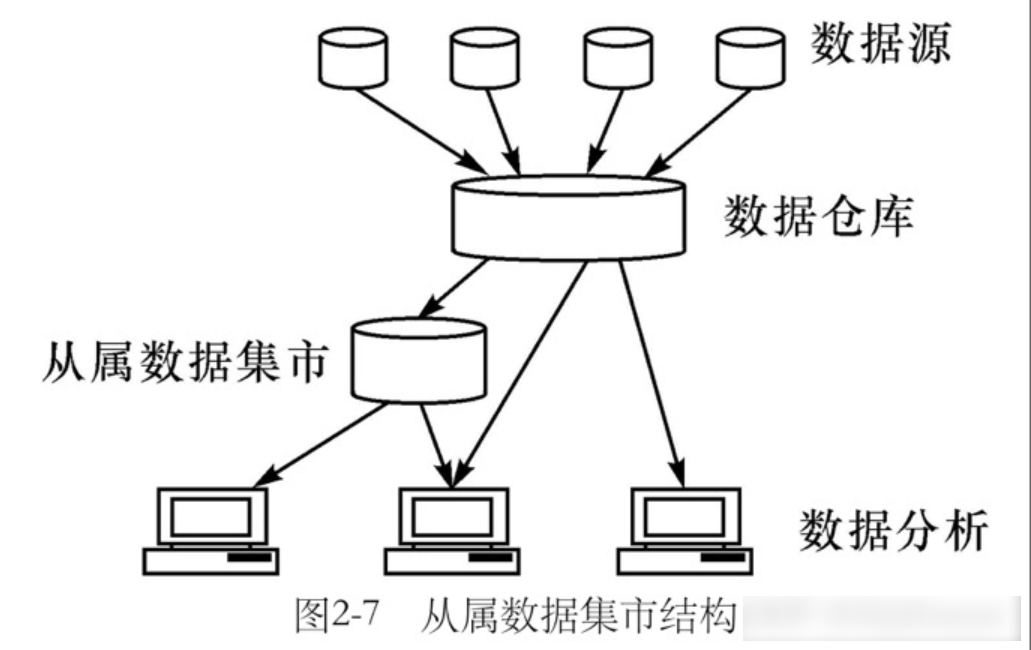
所谓从属,是指其数据直接来自于中央数据仓库。该结构能保持数据的一致性。
一般为那些访问数据仓库十分频繁的关键业务部门建立从属的数据集市,能提高查询反应速度。
(2)独立数据集市
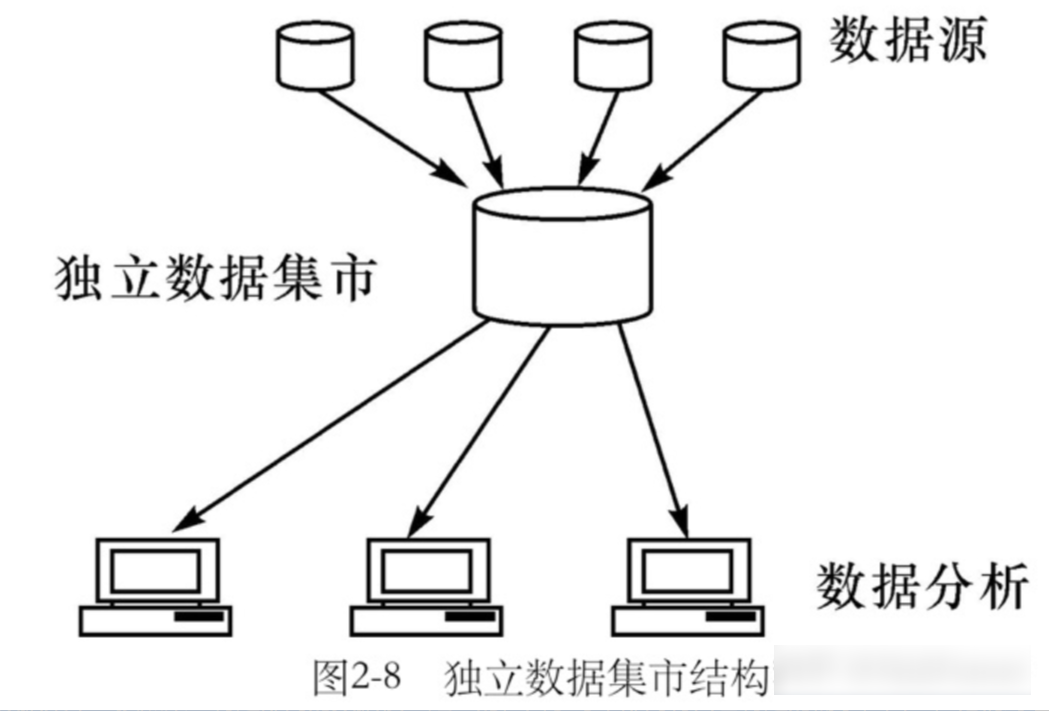
独立数据集市的数据子集来源于各生产系统,许多企业在计划实施数据仓库时,往往处于投资方面的考虑,首先建成独立数据集市,用来解决个别部门较迫切的决策问题。
2、数据仓库与数据集市的区别
(1)数据仓库:基于整个企业的数据模型建立,面向企业范围内的主题;
数据集市:按照某一特定部门的数据模型建立的,由于每个部门有自己特定的需求,因此,他们对数据集市的期望也不同。 部门主题与企业主题之间可能存在关联,也可能不存在。
(2)数仓存储整个企业内非常详细的数据;数据集市数据详细程度低一些,包含概要和综合数据多一些。
(3)数据集市的数据组织一般采用星形模型。大型数仓的数据组织,星形或雪花形都可以。
(4)数据集市较少保留历史数据。
@二东东
RE: (3)数据集市的数据组织一般采用星形模型。大型数仓的数据组织,星形或雪花形都可以。
在云上数据仓库时代(Redshift, BigQuery, Snowflake 出现的2016年之后)数据集市的数据组织一般采用宽表Wide Table就好了 因为:
宽表可以直接用于BI或者分析师进行分析 (他们习惯于直接分析一个二维表格,而不是拿星形模型再去join)星形模型的cost优势不存在了 因为在云上数据仓库时代 贵的是人工而不是数据存储 所以最省时省力可直接分析的的宽表 在成本上才有优势至于星型模型的另外两个优势performance and understandability 也是不如宽表的
综上 在这个时代 数据集市的数据组织应该是宽表