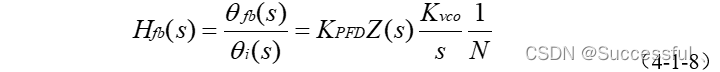序列化的作用及自定义协议
- 序列化的重要性
- 大小对比
- 效率对比
- 自定义协议
- 序列化
- 数据结构
- 自定义编码器
- 自定义解码器
- 安全性
- 验证
- NettyClient
- NettyServer
- NettyClientTestHandler
- NettyServerTestHandler
- 结果
上一章已经说了怎么解决沾包和拆包的问题,但是这样离一个成熟的通信还是有一点距离,我们还需要让服务端和客户端使用同一个"语言"来沟通,要不然一个讲英文一个讲中文,两个都听不懂岂不是很尴尬?这种语言就叫协议。
Netty自身就支持很多种协议比如Http、Websocket等等,但如果用来作为自己的RPC框架通常会自定义协议,所以这也是本文的重点!
序列化的重要性
在说协议之前,我们需要先知道什么是序列化,序列化是干嘛的?
我们要知道数据在传输的过程中是以0和1的形式传输的,而把对象转化成二进制的过程就叫序列化,将二进制转化为对象的过程就叫反序列化。
为什么要说这个很重要呢?因为序列化和反序列化是需要耗时的,而序列化后的字节大小也会影响到传输的效率,所以选对一种高效的序列化方式是非常之重要的,下面我们以JDK自带的序列化和我们常用的JSON序列化来做一个对比,序列化后大小的对比、序列化效率的对比
大小对比
我们先准备一个实体类SerializeTestVO实现Serializable 接口
public class SerializeTestVO implements Serializable {
private Integer id;
private String name;
private Integer age;
private Integer sex;
private Integer bodyWeight;
private Integer height;
private String school;
//Set、get方法省略
}
测试方法:
public static void main(String[] args) throws IOException {
// 普普通通的实体类
SerializeTestVO serializeTestVO = new SerializeTestVO();
serializeTestVO.setAge(18);
serializeTestVO.setBodyWeight(120);
serializeTestVO.setHeight(180);
serializeTestVO.setId(10000);
serializeTestVO.setName("张三");
serializeTestVO.setSchool("XXXXXXXXXXXX");
// JDK序列化
ByteArrayOutputStream byteArrayOutputStream = new ByteArrayOutputStream();
ObjectOutputStream objectOutputStream = new ObjectOutputStream(byteArrayOutputStream);
objectOutputStream.writeObject(serializeTestVO);
objectOutputStream.flush();
objectOutputStream.close();
System.out.println("JDK 序列化大小: "+(byteArrayOutputStream.toByteArray().length));
byteArrayOutputStream.close();
//JSON序列化
System.out.println("JSON 序列化大小: " + JSON.toJSONString(serializeTestVO).getBytes().length);
}
结果:
可以看到序列化后大小相差了好几倍,这也意味着传输效率的几倍
效率对比
实体类保持不变,我们序列化300W次,看看结果
public static void main(String[] args) throws IOException {
SerializeTestVO serializeTestVO = new SerializeTestVO();
serializeTestVO.setAge(18);
serializeTestVO.setBodyWeight(120);
serializeTestVO.setHeight(180);
serializeTestVO.setId(10000);
serializeTestVO.setName("张三");
serializeTestVO.setSchool("XXXXXXXXXXXX");
long start = System.currentTimeMillis();
for (int i = 0; i < 3000000; i++) {
ByteArrayOutputStream byteArrayOutputStream = new ByteArrayOutputStream();
ObjectOutputStream objectOutputStream = new ObjectOutputStream(byteArrayOutputStream);
objectOutputStream.writeObject(serializeTestVO);
objectOutputStream.flush();
objectOutputStream.close();
byte[] bytes = byteArrayOutputStream.toByteArray();
byteArrayOutputStream.close();
}
System.out.println("JDK 序列化耗时: " + (System.currentTimeMillis() - start));
long start1 = System.currentTimeMillis();
for (int i = 0; i < 3000000; i++) {
byte[] bytes = JSON.toJSONString(serializeTestVO).getBytes();
}
System.out.println("JSON 序列化耗时: " + (System.currentTimeMillis() - start1));
}
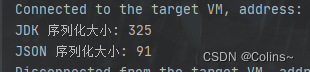
结果:
几乎6倍的差距,结合序列化后的大小综合来看,选择一种好的序列化方式是多么的重要
自定义协议
其实到现在我们已经掌握了自定义协议里面最关键的几个点了,序列化、数据结构、编解码器,我们一个一个来
序列化
直接采用我们常用且熟悉的JSON序列化
数据结构
我们设置为消息头和消息体,结构如下:
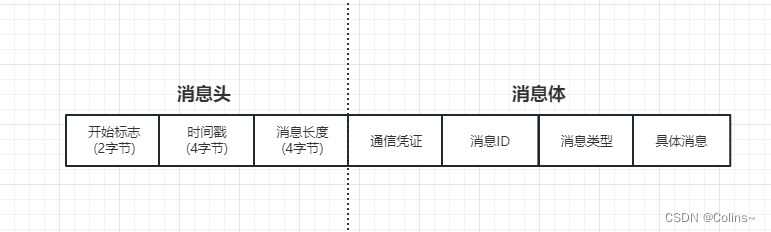
消息头包含:开始标志、时间戳、消息体长度
消息体包含:通信凭证、消息ID、消息类型、消息
实体类如下:
@Data
public class NettyMsg {
private NettyMsgHead msgHead=new NettyMsgHead();
private NettyBody nettyBody;
public NettyMsg(ServiceCodeEnum codeEnum, Object msg){
this.nettyBody=new NettyBody(codeEnum, msg);
}
}
@Data
public class NettyMsgHead {
// 开始标识
private short startSign = (short) 0xFFFF;
// 时间戳
private final int timeStamp;
public NettyMsgHead(){
this.timeStamp=(int)(DateUtil.current() / 1000);
}
}
@Data
public class NettyBody {
// 通信凭证
private String token;
// 消息ID
private String msgId;
// 消息类型
private short msgType;
// 消息 这里序列化采用JSON序列化
// 所以这个msg可以是实体类的msg 两端通过消息类型来判断实体类类型
private String msg;
public NettyBody(){
}
public NettyBody(ServiceCodeEnum codeEnum,Object msg){
this.token=""; // 鉴权使用
this.msgId=""; // 拓展使用
this.msgType=codeEnum.getCode();
this.msg= JSON.toJSONString(msg);
}
}
消息类型枚举
@JsonFormat(shape = JsonFormat.Shape.OBJECT)
public enum ServiceCodeEnum {
TEST_TYPE((short) 0xFFF1, "测试");
private final short code;
private final String desc;
ServiceCodeEnum(short code, String desc) {
this.code = code;
this.desc = desc;
}
public short getCode() {
return code;
}
}
自定义编码器
编码器的作用就是固定好我们的数据格式,无需在每次发送数据的时候还需要去对数据进行格式编码
public class MyNettyEncoder extends MessageToByteEncoder<NettyMsg> {
@Override
protected void encode(ChannelHandlerContext channelHandlerContext, NettyMsg msg, ByteBuf out) throws Exception {
// 写入开头的标志
out.writeShort(msg.getMsgHead().getStartSign());
// 写入秒时间戳
out.writeInt(msg.getMsgHead().getTimeStamp());
byte[] bytes = JSON.toJSON(msg.getNettyBody()).toString().getBytes();
// 写入消息长度
out.writeInt(bytes.length);
// 写入消息主体
out.writeBytes(bytes);
}
}
自定义解码器
解码器的第一个作用就是解决沾包和拆包的问题,第二个作用就是对数据有效性的校验,比如数据协议是否匹配、数据是否被篡改、数据加解密等等
所以我们直接继承LengthFieldBasedFrameDecoder类,重写decode方法,利用父类来解决沾包和拆包问题,自定义来解决数据有效性问题
public class MyNettyDecoder extends LengthFieldBasedFrameDecoder {
// 开始标记
private final short HEAD_START = (short) 0xFFFF;
public MyNettyDecoder(int maxFrameLength, int lengthFieldOffset, int lengthFieldLength) {
super(maxFrameLength, lengthFieldOffset, lengthFieldLength);
}
public MyNettyDecoder(int maxFrameLength, int lengthFieldOffset, int lengthFieldLength, int lengthAdjustment, int initialBytesToStrip) {
super(maxFrameLength, lengthFieldOffset, lengthFieldLength, lengthAdjustment, initialBytesToStrip);
}
public MyNettyDecoder(int maxFrameLength, int lengthFieldOffset, int lengthFieldLength, int lengthAdjustment, int initialBytesToStrip, boolean failFast) {
super(maxFrameLength, lengthFieldOffset, lengthFieldLength, lengthAdjustment, initialBytesToStrip, failFast);
}
public MyNettyDecoder(ByteOrder byteOrder, int maxFrameLength, int lengthFieldOffset, int lengthFieldLength, int lengthAdjustment, int initialBytesToStrip, boolean failFast) {
super(byteOrder, maxFrameLength, lengthFieldOffset, lengthFieldLength, lengthAdjustment, initialBytesToStrip, failFast);
}
@Override
protected Object decode(ChannelHandlerContext ctx, ByteBuf in) throws Exception {
// 经过父解码器的处理 我们就不需要在考虑沾包和半包了
// 当然,想要自己处理沾包和半包问题也不是不可以
ByteBuf decode = (ByteBuf) super.decode(ctx, in);
if (decode == null) {
return null;
}
// 开始标志校验 开始标志不匹配直接 过滤此条消息
short startIndex = decode.readShort();
if (startIndex != HEAD_START) {
return null;
}
// 时间戳
int timeIndex = decode.readInt();
// 消息体长度
int lenOfBody = decode.readInt();
// 读取消息
byte[] msgByte = new byte[lenOfBody];
decode.readBytes(msgByte);
String msgContent = new String(msgByte);
// 将消息转成实体类 传递给下面的数据处理器
return JSON.parseObject(msgContent, NettyBody.class);
}
}
安全性
上述的协议里面,我只预留了三种简单的校验,一个是开始标识,二是消息凭证,三是时间戳,实时上这太简单了,下面我说几种可以加上去拓展的:
消息整体加密:消息头添加一个加密类型,客户端和服务端都内置几种加解密手段,在发送消息的时候随机一种加密方式对加密类型、消息长度以外的其他内容加密,接收的时候再解密,但是要注意加密后不能影响沾包和拆包的处理
消息体加密:添加结束标识放入消息体,和上述方式类似,但是是对消息体中的内容再次加密,可和上述方式结合,形成二次加密
时间戳:可以对长时间才接收到的消息拒收,或者要求重发根据消息ID
加签和验签:对具体的消息加签和验签,防止篡改
凭证:这个很熟悉了,就比如登录凭证
复杂格式:上述的数据格式还是过于简单,实际可以整了更加复杂
验证
主体代码呢还是之前的,我们改动几个地方
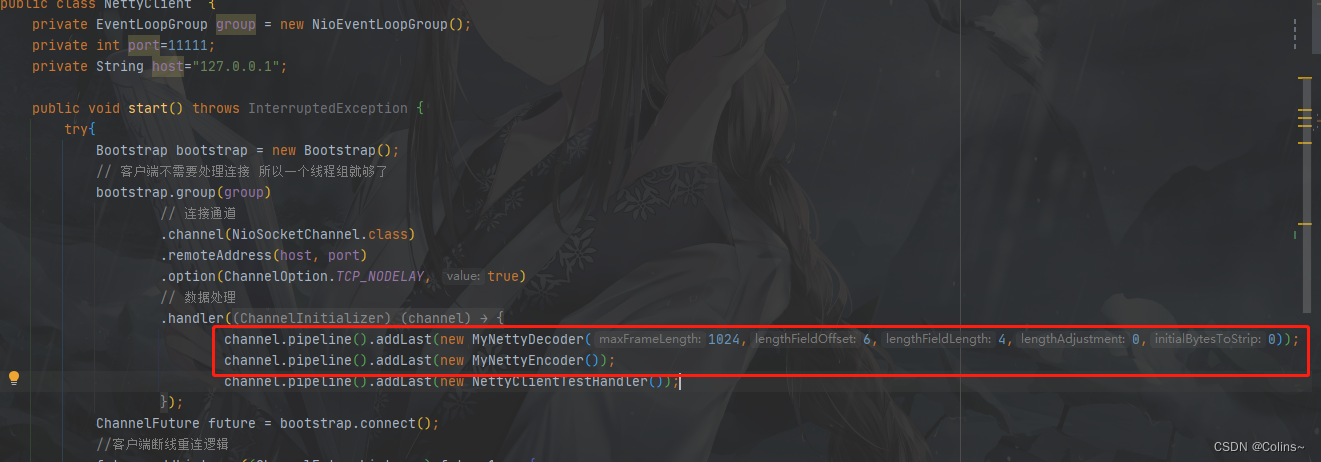
NettyClient
解码器是继承的LengthFieldBasedFrameDecoder,所以参数也一样,不懂的看一下上一篇
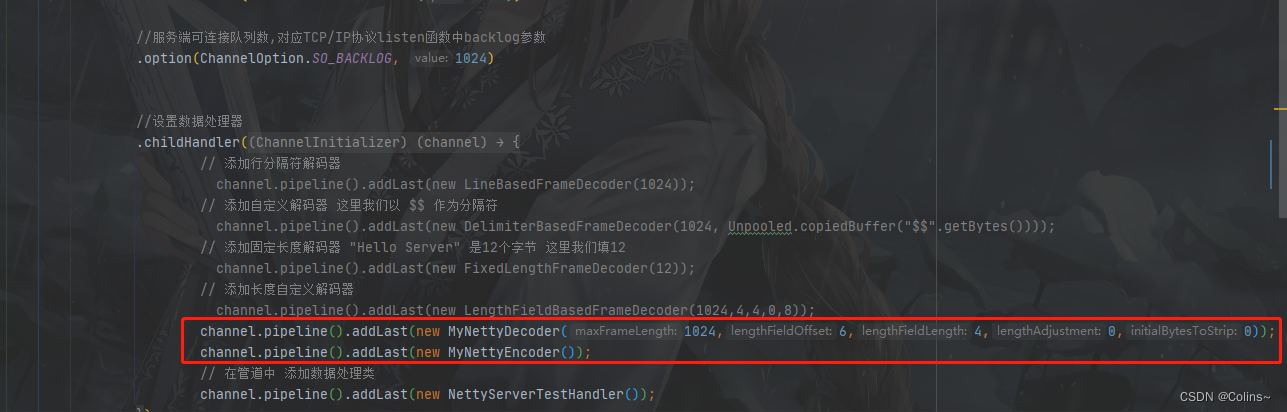
NettyServer
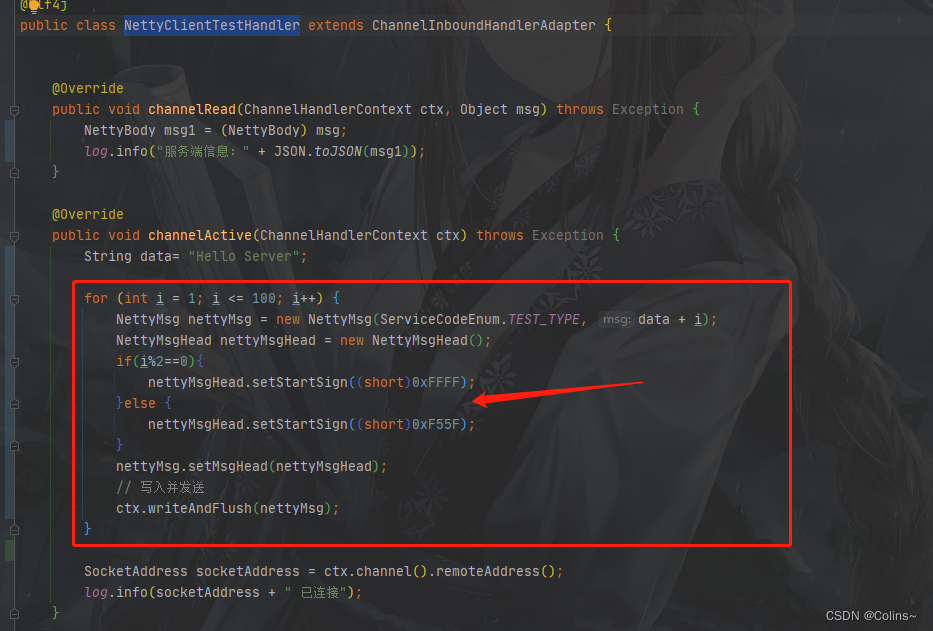
NettyClientTestHandler
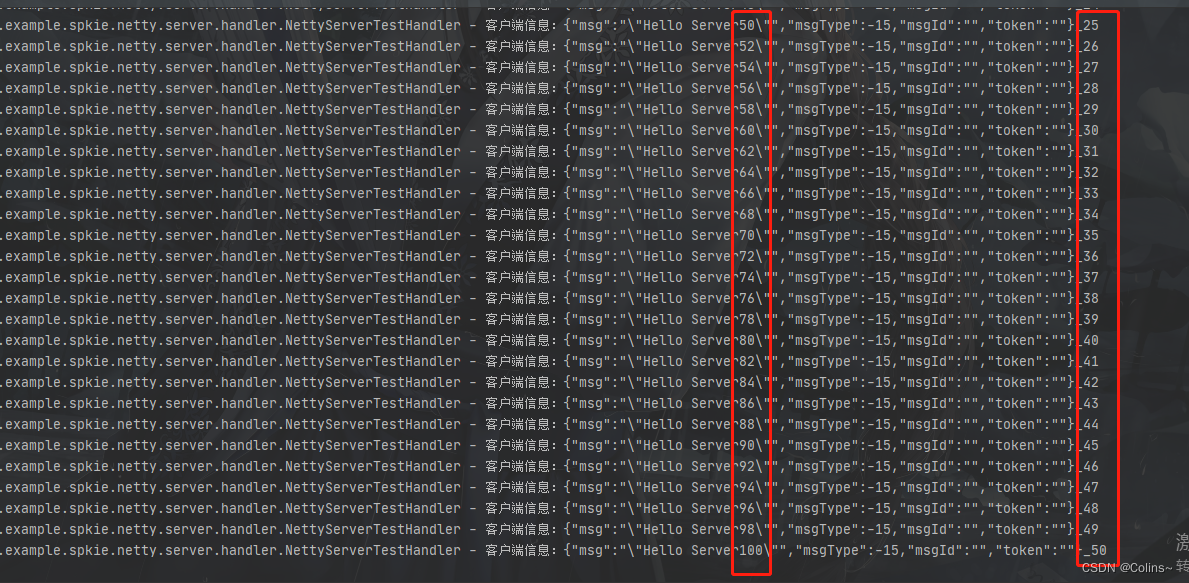
发送100次是为了验证沾包和拆包,发送不同的开始标志,是为了验证接收的时候是否有过滤无效数据
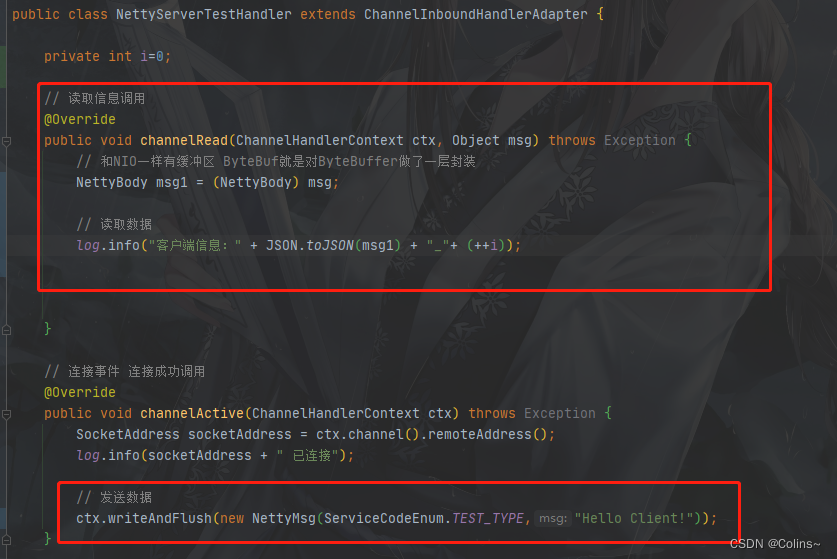
NettyServerTestHandler
有了编码器,发送可以直接发送实体类,有了解码器我们可以直接用实体类接收数据,因为解码器里面往下传递的是过滤了消息头的实体类
结果
一共接收到了50条消息,而且都是偶数消息,说明无效消息被过滤了,也没有沾包和拆包







![数组(二)-- LeetCode[303][304] 区域和检索 - 数组不可变](https://img-blog.csdnimg.cn/fe21a1cc648045e395a5b4d1eae42cc4.png#pic_center)