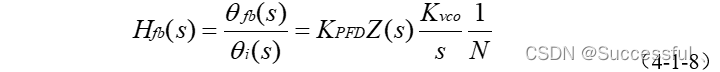1 区域和检索 - 数组不可变
1.1 题目描述

题目链接:https://leetcode.cn/problems/range-sum-query-immutable/
1.2 思路分析
最朴素的想法是存储数组 nums 的值,每次调用 sumRange 时,通过循环的方法计算数组 nums 从下标 i i i 到下标 j j j 范围内的元素和,需要计算 j − i + 1 j−i+1 j−i+1 个元素的和。由于每次检索的时间和检索的下标范围有关,因此检索的时间复杂度较高,如果检索次数较多,则会超出时间限制。
由于会进行多次检索,即多次调用 sumRange,因此为了降低检索的总时间,应该降低 sumRange 的时间复杂度,最理想的情况是时间复杂度 O ( 1 ) O(1) O(1)。为了将检索的时间复杂度降到 O ( 1 ) O(1) O(1),需要在初始化的时候进行预处理。
注意到当 i ≤ j i≤j i≤j 时,sumRange(i,j) 可以写成如下形式:
sum Range ( i , j ) = ∑ k = i j n u m s [ k ] = ∑ k = 0 j n u m s [ k ] − ∑ k = 0 i − 1 n u m s [ k ] \begin{aligned} & \operatorname{sum} \operatorname{Range}(i, j) \\ = & \sum_{k=i}^j n u m s[k] \\ = & \sum_{k=0}^j n u m s[k]-\sum_{k=0}^{i-1} n u m s[k]\end{aligned} ==sumRange(i,j)k=i∑jnums[k]k=0∑jnums[k]−k=0∑i−1nums[k]
由此可知,要计算 sumRange(i,j),则需要计算数组 nums 在下标 j j j 和下标 i − 1 i−1 i−1 的前缀和,然后计算两个前缀和的差。
如果可以在初始化的时候计算出数组 nums 在每个下标处的前缀和 pre_sum,即可满足每次调用 sumRange 的时间复杂度都是 O ( 1 ) O(1) O(1)。
示例代码:
class NumArray:
def __init__(self, nums: List[int]):
self.pre_sum = [0] # 便于计算累加和,若直接分配数组空间,计算效率更高
for i in range(len(nums)):
self.pre_sum.append(self.pre_sum[i] + nums[i]) # 计算nums累加和
def sumRange(self, left: int, right: int) -> int:
return self.pre_sum[right+1] - self.pre_sum[left]
下面以数组 [1, 12, -5, -6, 50, 3] 为例,展示了求 pre_sum 的过程。

复杂度分析
- 时间复杂度:初始化 O ( n ) O(n) O(n),每次检索 O ( 1 ) O(1) O(1),其中 n n n 是数组 nums 的长度。初始化需要遍历数组 nums 计算前缀和,时间复杂度是 O ( n ) O(n) O(n)。每次检索只需要得到两个下标处的前缀和,然后计算差值,时间复杂度是 O ( 1 ) O(1) O(1)。
- 空间复杂度: O ( n ) O(n) O(n),其中 n n n 是数组 nums 的长度。需要创建一个长度为 n + 1 n+1 n+1 的前缀和数组。
2 二维区域和检索 - 矩阵不可变
2.1 题目描述

题目链接:https://leetcode.cn/problems/range-sum-query-2d-immutable/
2.2 思路分析
这部分借鉴自:笨猪爆破组的题解————从暴力法开始优化 「二维前缀和」做了什么事 | leetcode.304
1. 暴力法
对二维矩阵,求子矩阵 ( n ∗ m ) (n*m) (n∗m) 的和。两重循环,累加求和。
每次查询时间复杂度 O ( n ∗ m ) O(n∗m) O(n∗m),n和m是子矩阵的行数和列数。查询的代价大。
2. 第一步优化
上面的暴力法其实也分了 n 步:第一行的求和,到第 n 行的求和,它们是 n 个一维数组。
昨天我们学习了一维前缀和,我们可以对这n个一维数组求前缀和,得到n个一维pre_sum数组。
为了节省查询的时间,我们求出整个矩阵每一行的一维pre_sum数组
根据前缀和定义: p r e _ s u m [ i ] = n u m s [ 0 ] + n u m s [ 1 ] + ⋯ + n u m s [ i ] {pre}\_{sum}[i]=nums[0]+nums[1]+\cdots+nums[i] pre_sum[i]=nums[0]+nums[1]+⋯+nums[i],求出前缀和(下图红字):

然后套用通式: n u m s [ i ] + ⋯ + n u m s [ j ] = p r e _ s u m [ j ] − p r e _ s u m [ i − 1 ] nums[i]+\cdots+nums[j]=pre\_sum[j]-pre\_sum[i-1] nums[i]+⋯+nums[j]=pre_sum[j]−pre_sum[i−1]
即可求出粉色子阵列的和,计算情况如下图。

可见,如果想多次查询子阵列的和,我们可以提前求出每一行数组的一维前缀和。
那么查询阶段,求出一行子数组的求和,就只是 O ( 1 ) O(1) O(1),查询 n 行的子阵列,每次就查询花费 O ( n ) O(n) O(n),比 O ( n 2 ) O(n^2) O(n2) 好
3. 示例代码:
class NumMatrix:
def __init__(self, matrix: List[List[int]]):
m, n = len(matrix), len(matrix[0]) # 矩阵的行和列
self.pre_sum = [[0] for _ in range(m)] # 构造一维前缀和矩阵
for i in range(m):
for j in range(n):
self.pre_sum[i].append(self.pre_sum[i][j]+matrix[i][j])
def sumRegion(self, row1: int, col1: int, row2: int, col2: int) -> int:
return sum([self.pre_sum[i][col2+1]-self.pre_sum[i][col1] for i in range(row1, row2+1)])
4. 第二步优化
还可以继续优化吗?
我们引入一个概念:二维前缀和,定义式如下

pre_sum[i][j] 表示:左上角为 arr[0][0],右下角为 arr[i][j] 的阵列的求和.
我们把这个阵列拆分成四个部分,如图中的色块。
要想求出 pre_sum[i][j],根据上图,由容斥原理,有:

移项后:
a r r [ i ] [ j ] = p r e _ s u m [ i ] [ j ] + p r e _ s u m [ i − 1 ] [ j − 1 ] − p r e _ s u m [ i − 1 ] [ j ] − p r e _ s u m [ i ] [ j − 1 ] arr[i][j] = pre\_sum[i][j] + pre\_sum[i-1][j-1] - pre\_sum[i-1][j] - pre\_sum[i][j-1] arr[i][j]=pre_sum[i][j]+pre_sum[i−1][j−1]−pre_sum[i−1][j]−pre_sum[i][j−1]
现在想求:行 从 a 到 A,列 从 b 到 B 的子阵列的和。叠加上式,各种相消后。得:

回到粉色子阵列,求她的和,就是如下图的 4 个 pre_sum 矩阵元素相加减。

问题来了,怎么求出 pre_sum 二维阵列的每一项?
就是用遍历原矩阵,两层循环,套下图的公式。
注意到上图黄字,在 -1 位置上预置了 0,只是为了让处于边界的 preSum 元素,也能套用下面的通式。

两个关键式 pre_sum[i][j] 的定义式如下,并且预置 pre-sum[-1][j] 和 pre_sum[i][-1] 为 0:
preSum [ i ] [ j ] = ∑ x = 0 i ∑ y = 0 j arr [ x ] [ y ] \operatorname{preSum}[i][j]=\sum_{x=0}^i \sum_{y=0}^j \operatorname{arr}[x][y] preSum[i][j]=x=0∑iy=0∑jarr[x][y]
求:行从 a 到 A,列从 b 到 B 的子阵列的和的通式:
∑
i
=
a
A
∑
i
=
b
B
arr
[
i
]
[
j
]
=
pre_sum
[
A
]
[
B
]
+
pre_sum
[
a
−
1
]
[
b
−
1
]
−
pre_sum
[
A
]
[
b
−
1
]
−
pre_sum
[
a
−
1
]
[
B
]
\sum_{i=a}^A \sum_{i=b}^B \operatorname{arr}[i][j]=\operatorname{pre\_sum}[A][B]+\operatorname{pre\_sum}[a-1][b-1]-\operatorname{pre\_sum}[A][b-1]-\operatorname{pre\_sum}[a-1][B]
i=a∑Ai=b∑Barr[i][j]=pre_sum[A][B]+pre_sum[a−1][b−1]−pre_sum[A][b−1]−pre_sum[a−1][B]
查询的时间复杂度降下来了
因此子阵列的求和,都只需要访问二维 pre_sum 数组的四个值。
预处理阶段,求出二维 pre_sum 数组,需要花费 O ( n ∗ m ) O(n∗m) O(n∗m),n和m是子矩阵的行数和列数。
但之后每次查询,就都是 O ( 1 ) O(1) O(1) 的时间复杂度
5. 调整 pre_sum 矩阵
为了减少特判的代码,我们调整一下 pre_sum 矩阵,原先 arr[i][j] 对应 pre_sum[i][j]
现在错开,arr[i][j] 对应 pre_sum[i+1][j+1]。
如下图所示,pre_sum 阵列会比原矩阵多一行一列,为了让 pre_sum 的 -1 列 -1 行变成 0 行 0 列

现在 preSum[i][j] 的定义式,改一下
pre_sum [ i + 1 ] [ j + 1 ] = ∑ x = 0 i ∑ y = 0 j arr [ x ] [ y ] \operatorname{pre\_sum}[i+1][j+1]=\sum_{x=0}^i \sum_{y=0}^j \operatorname{arr}[x][y] pre_sum[i+1][j+1]=x=0∑iy=0∑jarr[x][y]
并且预置 pre_sum[0][j] 和 pre_sum[i][0] 为 0
求:行从 a 到 A,列从 b 到 B 的子阵列的和,的通式,改一下:
∑
i
=
a
A
∑
i
=
b
B
arr
[
i
]
[
j
]
=
pre_sum
[
A
+
1
]
[
B
+
1
]
+
pre_sum
[
a
]
[
b
]
−
pre_sum
[
A
+
1
]
[
b
]
−
pre_sum
[
a
]
[
B
+
1
]
\sum_{i=a}^A \sum_{i=b}^B \operatorname{arr}[i][j]=\operatorname{pre\_sum}[A+1][B+1]+\operatorname{pre\_sum}[a][b]-\operatorname{pre\_sum}[A+1][b]-\operatorname{pre\_sum}[a][B+1]
i=a∑Ai=b∑Barr[i][j]=pre_sum[A+1][B+1]+pre_sum[a][b]−pre_sum[A+1][b]−pre_sum[a][B+1]
6. 示例代码:
class NumMatrix:
def __init__(self, matrix: List[List[int]]):
m, n = len(matrix), len(matrix[0]) # 矩阵的行和列
self.pre_sum = [[0]*(n+1) for _ in range(m+1)] # 构造一维前缀和矩阵
for i in range(m):
for j in range(n):
self.pre_sum[i+1][j+1] = self.pre_sum[i+1][j] + self.pre_sum[i][j+1] - self.pre_sum[i][j] + matrix[i][j]
def sumRegion(self, row1: int, col1: int, row2: int, col2: int) -> int:
return (self.pre_sum[row2+1][col2+1] - self.pre_sum[row1][col2+1] - self.pre_sum[row2+1][col1] + self.pre_sum[row1][col1])
7. 复杂度分析
- 时间复杂度:初始化 O ( m n ) O(mn) O(mn),每次检索 O ( 1 ) O(1) O(1),其中 m 和 n 分别是矩阵 matrix 的行数和列数。初始化需要遍历矩阵 matrix 计算二维前缀和,时间复杂度是 O ( m n ) O(mn) O(mn)。每次检索的时间复杂度是 O ( 1 ) O(1) O(1)。
- 空间复杂度: O ( m n ) O(mn) O(mn),其中m和n分别是矩阵 matrix 的行数和列数。需要创建一个 m+1 行 n+1 列的二维前缀和数组 pre_sum。
做题心得:以后会不会延伸到张量呢,更高维数的也是总结通式,就比如三维是一个立方体,依然是计算每个小立方体的和。