李宏毅《机器学习》Bert笔记和工作原理解释
- 1.参考
- 2. self-supervised learning--bert
- 3. bert的一些用法
- 3.1情感分析
- 3.2词性标注
- 3.3常识推理和NLI
- 3.4 QA问题
- 4.bert的工作原理解释
1.参考
bert论文
李宏毅《机器学习》自监督训练-bert
2. self-supervised learning–bert
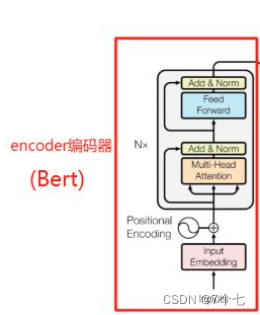
Bert模型结构实际上是Transformer的编码器,
Transformer
bert训练时,对模型的输入进行处理,将部分输入遮盖或者用其他数据替,输出后与被遮盖的数据做损失函数来进行多次训练,相当于在训练完形填空,这就是self-supervised learning,自监督训练
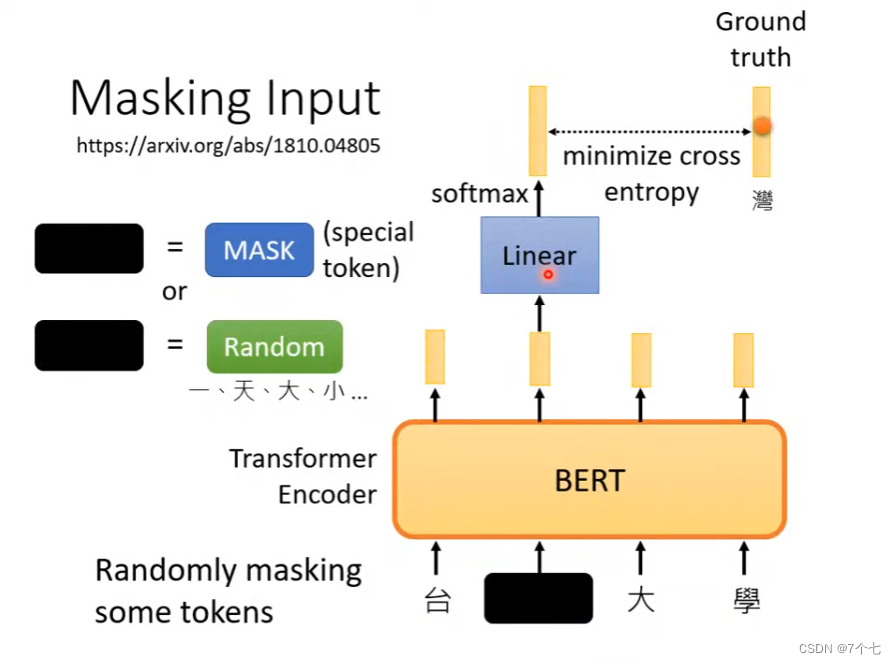
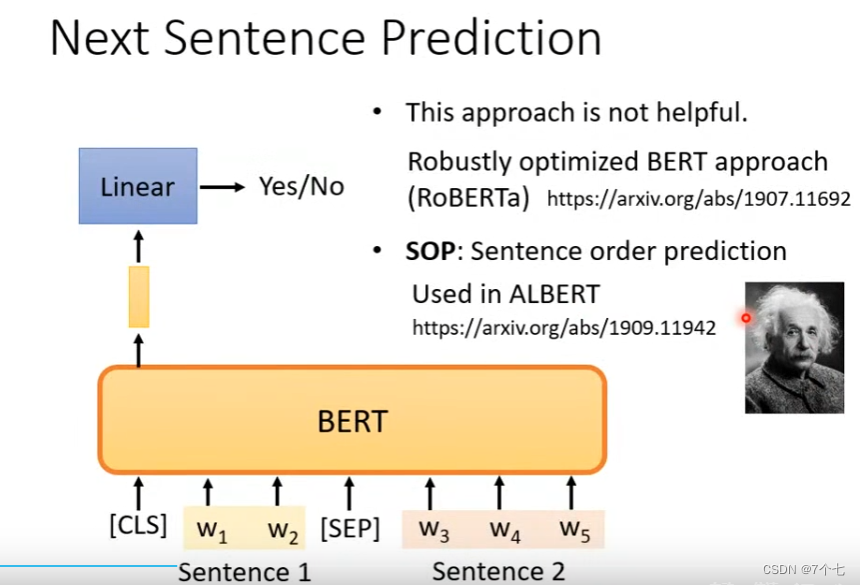
不但如此,bert在训练时还会训练另一个方法,Next Sentence Prediction(效果不太好)
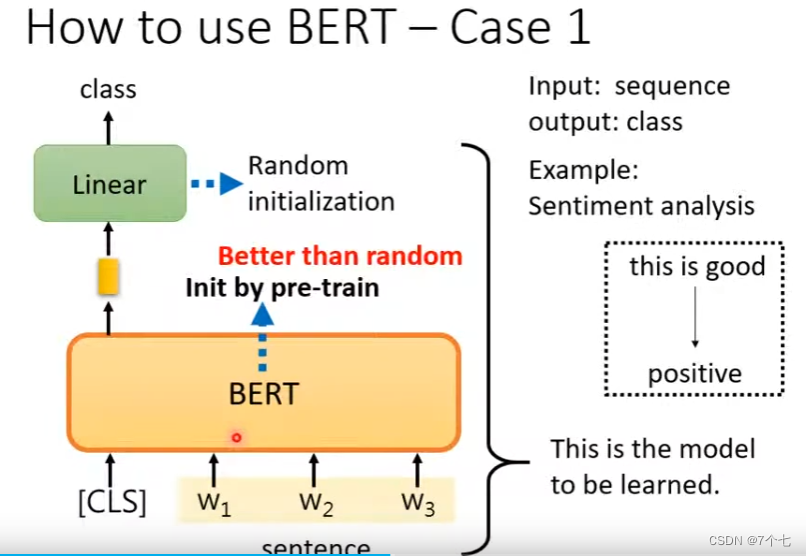
在经过大量的数据训练后我们就得了一个预训练模型 Bert,模型的参数是已经训练完毕了。然后根据下游任务的不同,我们再对这些参数进行微调Fine-tune
3. bert的一些用法
3.1情感分析
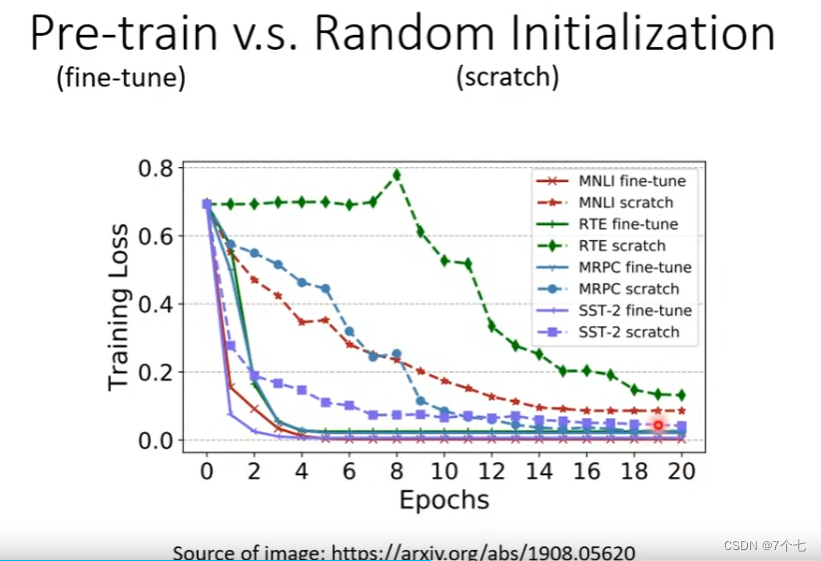
实验表明,在经过Bert预训练后的参数比随机初始化参数,loss下降的比较快也比较小。
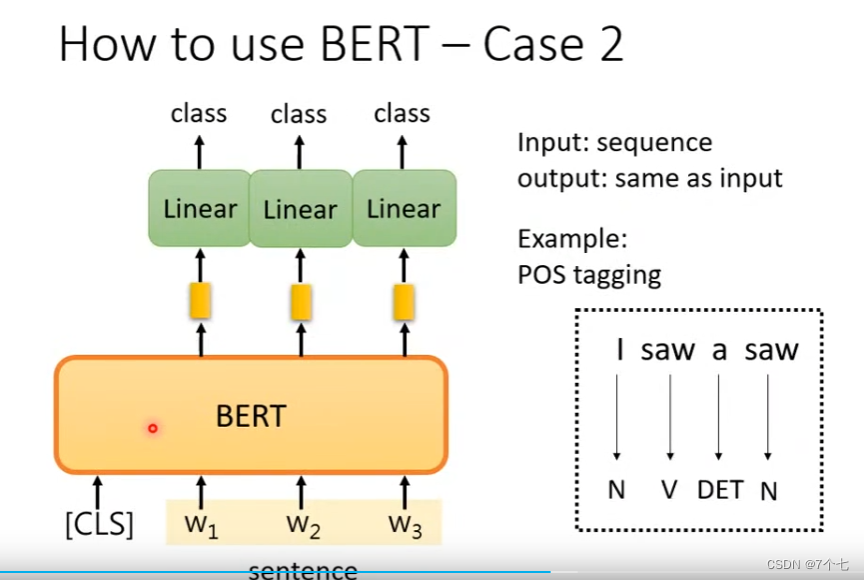
3.2词性标注
3.3常识推理和NLI
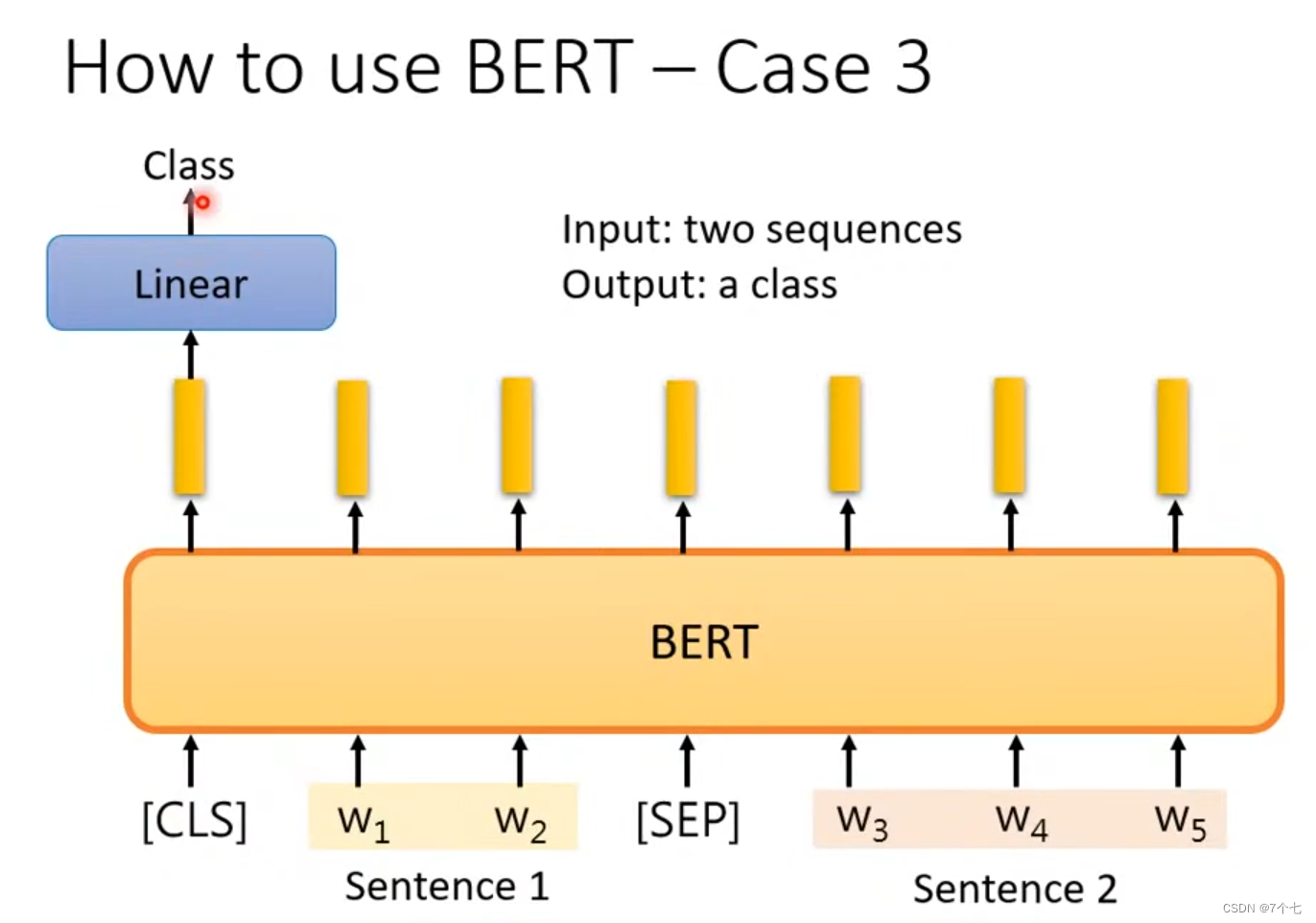
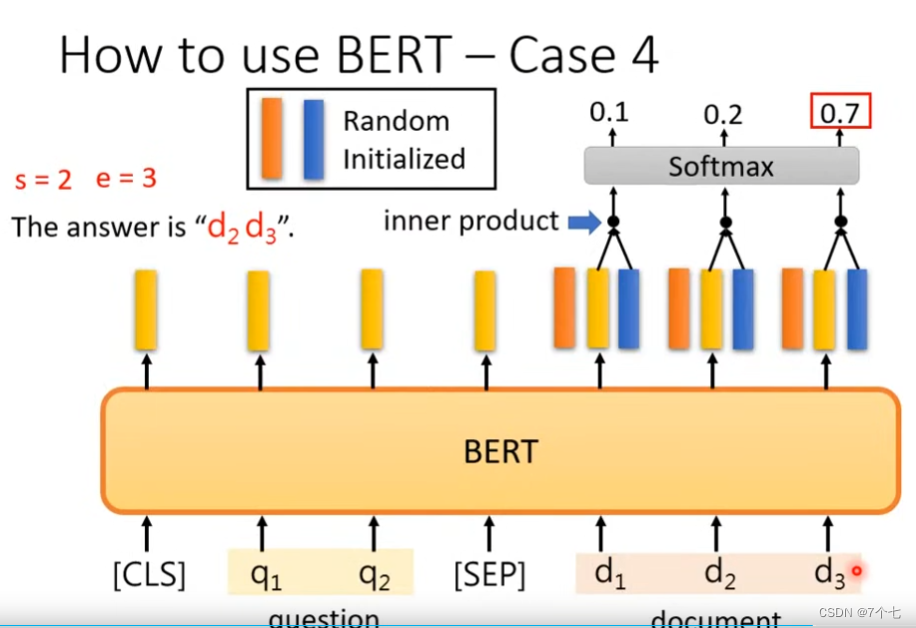
3.4 QA问题
如下QA问题得到的答案是单词的序号(要保证答案一定在文章内)

随机初始化2个向量,蓝色和橙色,参数可学习。
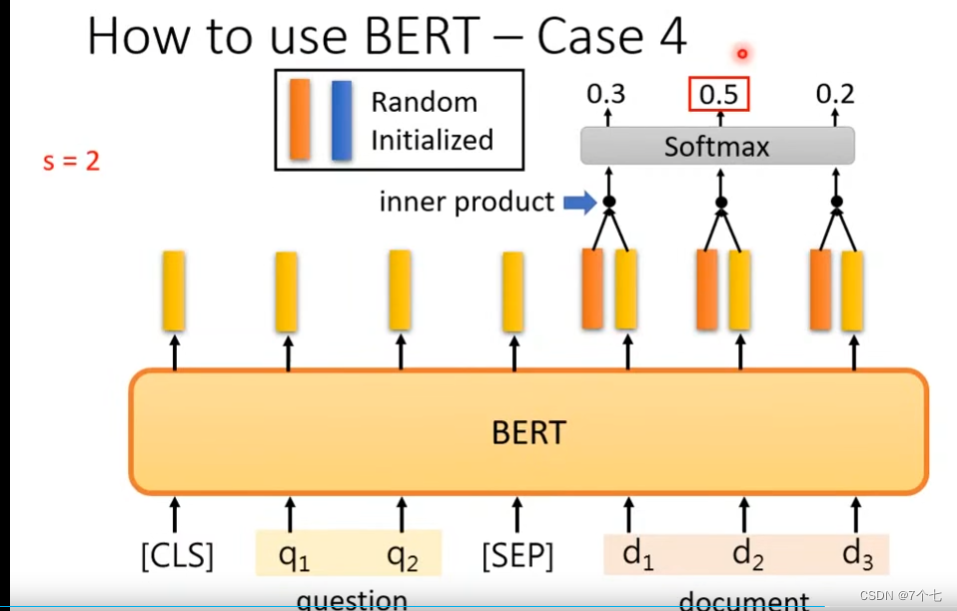 将橙色向量和输出的向量做内积,在进行Softmax函数得出answer的开始序号d2
将橙色向量和输出的向量做内积,在进行Softmax函数得出answer的开始序号d2
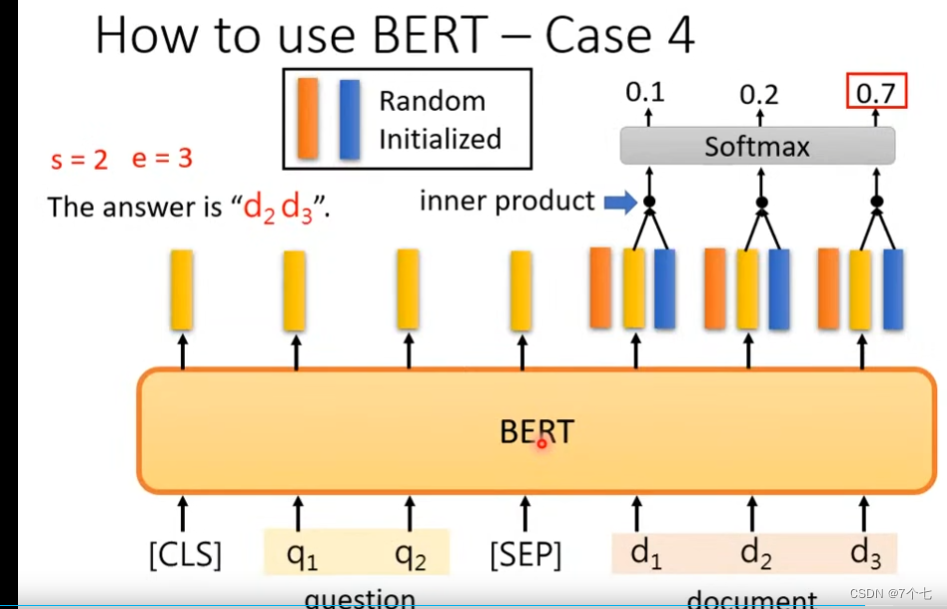
将蓝色向量和输出的向量做内积,在进行Softmax函数得出answer的开始序号d3
4.bert的工作原理解释
bert能够如此高效是因为他的训练是建立在特别庞大的数据基础上,使用预训练好的BERT,只需加载预训练好的模型作为自己当前任务的词嵌入层,后续针对特定任务构建后续模型结构即可,不需对代码做大量修改或优化。
其工作原理也就是为什么训练后的bert会如此适用大部分任务,这里李宏毅老师视频里给出了解释(8:30前),同时也提出了几个有意思的现象
Why does bert work?


![数组(二)-- LeetCode[303][304] 区域和检索 - 数组不可变](https://img-blog.csdnimg.cn/fe21a1cc648045e395a5b4d1eae42cc4.png#pic_center)