目录
1. dateadd(datepart,number,date)函数是在日期中添加或减去指定的时间间隔
2. DML数据库操作语言负责数据的增删查改
3. 修改表结构的关键字都是alter table 表名,再加修改的语句
4. between and条件查询范围前闭后闭
5. 使用索引 in 范围查询,like是用作模糊查询的
6. group by子句进行分组,having进行行条件筛选
7. 字符串通配符
8. 参数解析
9. 关系数据库六种范式
10. 数据库系统特点:高共享、低冗余、独立性高、具有完整性等
11. 实体之间多对多联系在关系模型中的实现方式是 建立新的关系
12.sum只能用于数值类型的列,Avg/Max/Min/Count都不是求和函数
13. 关系操作:自然连接、交、并、除
14. 关系数据库所采用的数据存放形式是 二维表
15. 员工编号有重复:不同部门,有相同的员工编号
16. 计算日期到天数转换
1. dateadd(datepart,number,date)函数是在日期中添加或减去指定的时间间隔

在MySQL中没有getdate()这样的函数,但是有dateadd()函数,但里面却是两个参数的
而在SQL Server中是有getdate() 和 dateadd()函数
dateadd(datepart,number,date)函数是在日期中添加或减去指定的时间间隔
datapart参数的取值范围{yy/yyyy , mm/m , dd/d}
number 是希望添加的间隔数 (往前是负数,往后是正数)
date 参数是合法的日期格式
getdate()函数从SQL Server 返回当前的时间和日期
而在MySQL中获取当前日期和时间的函数为now()
MySQL中的dateadd(date , initerval expr type)函数
date 参数是合法的日期表达式
expr 参数是希望添加的时间间隔
2. DML数据库操作语言负责数据的增删查改


3. 修改表结构的关键字都是alter table 表名,再加修改的语句
修改表结构的关键字都是alter table 表名,再跟具体修改的语句
(1)添加表字段
alter table table_name add 字段名称 字段类型
(2)删除表字段
alter table table_name drop 字段名称
(3)修改表字段
alter table table_name change 旧字段名称 新字段名称 字段类型
alter table table_name modify 字段名称 字段类型
4. between and条件查询范围前闭后闭

题中需要的是[1,10)
(1)使用between and 表示的查找范围是 【前闭后闭的】,所以A对
(2)interval
a)当做函数时,它被当做比较函数interval(),
比如interval(4,0,1,2,3,4,5,6)在这个函数中第一个数字4作为被比较数,后面的0 1 2 3 4 5 6当做比较数,将4和后面的数字进行比较,返回 <= 4的个数,所以这里返回5
(要将4后面的数字从小到大排序,interval才能正常使用,不然结果可能会错误)
b)当做关键字时,表示时间间隔,常用在data_add()、data_sub()函数中,
常用于时间的加减法,
比如查询当前时间之前2个小时的日期:select now()-interval 2 hours;
now()用来表示当前日期
5. 使用索引 in 范围查询,like是用作模糊查询的

条件查询根据范围这里使用in比较合适

like是依赖一些通配符来表示要匹配的值是啥样的
% 代替任意个任意字符 _代替一个任意字符

6. group by子句进行分组,having进行行条件筛选

group by 子句进行分组后,如果要对分组结果进行条件筛选时,不可以使用where语句,而要使用having ,进行 行筛选
7. 字符串通配符
题目链接:字符串通配符_牛客题霸_牛客网 (nowcoder.com)
题目要求:


题目分析:
一般动态规划的问题都可以通过穷举的方式得到答案,既然可以穷举,我们就可以将这个问题抽象成树形结构问题,然后通过回溯来解决
这块的思路是在力扣中看到【狗大王】写的,极为清晰,感兴趣的也可以点这个去了解一下
一个棋盘看懂动态规划(DP)思路;附Python代码 - 通配符匹配 - 力扣(LeetCode)
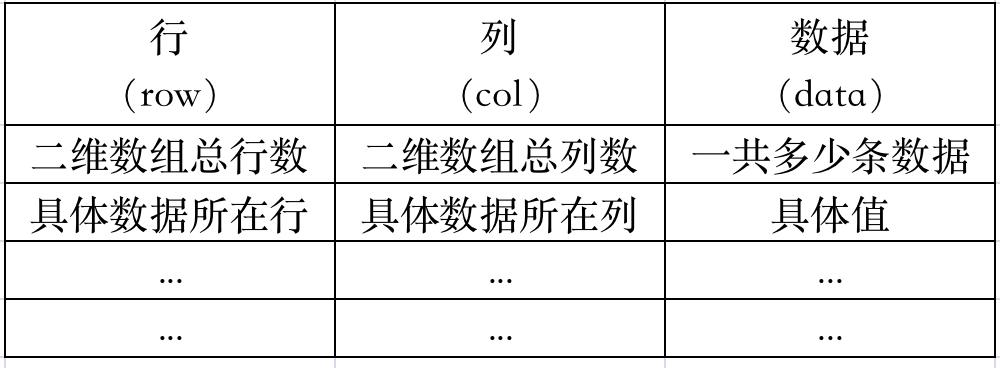
先看这样一般表
横轴为string s,纵轴为pattern p
这个表第(m,n)个格子所要表示的是,【p从0位置到m位置】这样一段
是否能与【s从0位置到n位置】这一整段匹配

此时在(start,start)位置放了一个T,这就是开始行走的位置
只有在T时才可以继续往下走,那T往这个表格哪里走?
这个题是一个字符串匹配题,那么字符串匹配肯定是从前往后匹配啊,对应到这个表格中,那就是往右下角走(也可以是往右走、往下走)
往右下角走,比如从刚才的初始位置出发,往右下角走一格,来到(a,a)的位置,发现这两个字母匹配,那就在这里记录一个“T”

就是这么走,如果p和s里只有字母,没有“ * ” 和 “ ? ” 这两个东西,那就是每次只要从原来T的某个格子往右下角走一格,如果新引入的两个字母正好匹配,那就可以在新的格子里记录一格T
注意:只能从T的格子走,如果某个格子没有东西(F),是不可以从那里走的
下面来看 “ * ” 和 “ ?”
可以将这个表格和象棋棋盘进行对比,普通字母如a、b就像是小兵角色,遇到他们只能右下走一格,走完这一步后判断新入的两个字母是否匹配才能记录T;而 “ * ” 和 “ ?”就像是有特殊技能的角色
“ * ” :如果这一行是 “ * ” ,可以从上一行的任意T出发,向下、往右来走(T)
“ * ”可以从原来T向正下方走的原因:*可以匹配空串
“ * ”可以往右走的原因:*可以匹配任意长度字符串

然后接着走,遇到一个b,这个是一个普通字母,所以只能从上一行某个T往右下角走到达,而且字母匹配才能记录T,于是可以这样走
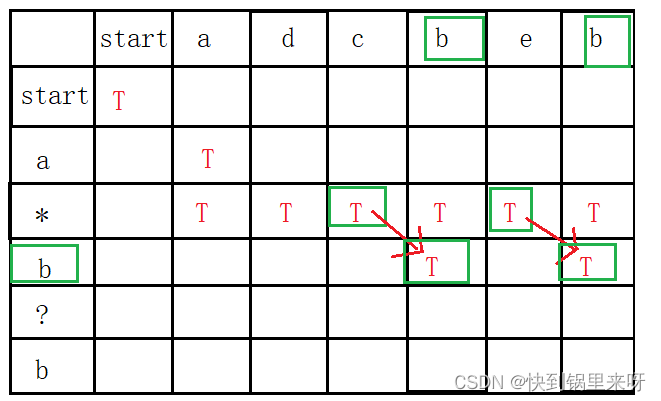
下面就是 “ ?”
“ ?”:如果这一行是“ ?”,从上一行某个T也只能往右下角走,但不必匹配字母就能记录T
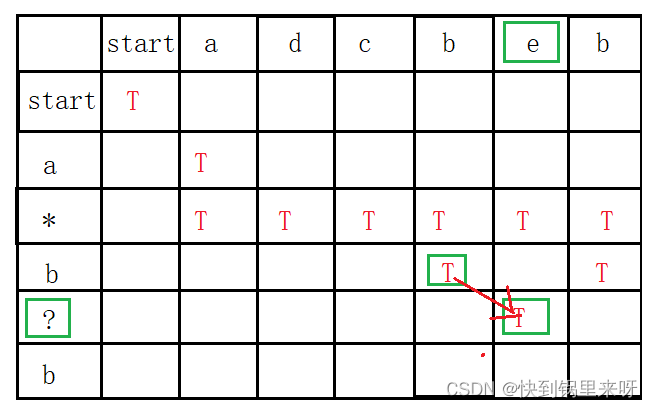
这样就到了最后一格,普通字母小兵,匹配

要判断是否匹配成功,此时只要看一个格子,如果最右下角的格子是T,那就是匹配成功了
力扣中这道题:44. 通配符匹配 - 力扣(LeetCode)
代码
class Solution {
public boolean isMatch(String s, String p) {
int m = s.length();
int n = p.length();
boolean[][] matchMap = new boolean[m+1][n+1];
matchMap[0][0] = true;
for (int i = 0;i<=m;i++){
for (int j = 1;j<=n;j++){
if (p.charAt(j-1)!='*'){
if (i>=1&&(p.charAt(j-1)==s.charAt(i-1)||p.charAt(j-1)=='?'))
matchMap[i][j] = matchMap[i-1][j-1];
}else
matchMap[i][j] = i==0?matchMap[i][j-1]:matchMap[i-1][j]||matchMap[i][j-1];
}
}
return matchMap[m][n];
}
}上代码(牛客)
import java.util.Locale;
import java.util.Scanner;
public class Main {
public static void main(String[] args) {
Scanner scan = new Scanner(System.in);
String s = scan.nextLine();
String t = scan.nextLine();
System.out.println(wildcard(s,t));
}
private static boolean wildcard(String t, String s) {
char[] ct = t.toCharArray();
char[] cs = s.toCharArray();
int lt = ct.length;;
int ls = cs.length;
boolean[][] dp = new boolean[ls+1][lt+1];
dp[0][0] = true;
for (int i = 0; i <= ls; i++) {
for (int j = 1; j <= lt; j++) {
if(ct[j-1] == '*') {
if(i == 0) {
dp[i][j] = dp[i][j-1];
}else {
if(cs[i-1] == '.' || (cs[i-1] >= 'A' && cs[i-1] <= 'Z') ||
(cs[i-1] >= 'a' && cs[i-1] <= 'z') ||
(cs[i-1] >= '0' && cs[i-1] <= '9')) {
dp[i][j] = dp[i-1][j] || dp[i][j-1];
}
}
} else {
if(i > 0 && defs(ct[j-1],cs[i-1])) {
dp[i][j] = dp[i-1][j-1];
}
}
}
}
return dp[ls][lt];
}
private static boolean defs(char t, char s) {
if(t == '?') return true;
if(t >= 'a' && t <= 'z') {
t = (char)(t-'a'+'A');
}
if(s >= 'a' && s <= 'z') {
s = (char)(s-'a'+'A');
}
return s == t;
}
}
8. 参数解析
题目链接:参数解析_牛客题霸_牛客网 (nowcoder.com)
题目要求:


题目分析:
参数打印,空格换行,双引号中的除外
可以用一个标识位来识别是不是在双引号中,比如定义一个flag =1.遇到双引号就flag^1
也就是此时flag为0,意味着已经进入双引号中,不再根据空格来换行打印了,直到遇到后一个双引号再异或一次,以为着此时已经出了双引号了,可以继续执行空格换行打印了
上代码
import java.util.Scanner;
public class Main {
public static void main(String[] args) {
Scanner scan = new Scanner(System.in);
String str = scan.nextLine();
int count = 0;
for (int i = 0; i < str.length(); i++) {
//遇到双引号时,就一直遍历,直到找到第二个双引号
if(str.charAt(i) == '"') {
do {
i++;
}while (str.charAt(i) != '"');
}
//双引号以外的空格 count++;
if(str.charAt(i) == ' ') {
count++;
}
}
//count是空格的个数,参数个数为count+1
System.out.println(count+1);
int flag = 1;
for (int i = 0; i < str.length(); i++) {
//遇到双引号异或,来标识此时进入了双引号中
if(str.charAt(i) == '\"') {
flag ^= 1;
}
if(str.charAt(i) != ' ' && str.charAt(i) != '\"') {
System.out.print(str.charAt(i));
}
//flag=0时,一直在遍历双引号中的参数
if(str.charAt(i) == ' ' && flag == 0) {
System.out.print(str.charAt(i));
}
//遇到双引号以外的空格就需要换行
if(str.charAt(i) == ' ' && flag == 1) {
System.out.println();
}
}
}
}
9. 关系数据库六种范式

 先来了解一下什么叫范式
先来了解一下什么叫范式
范式是符合某一级别关系模式的集合
关系数据库的关系必须满足一定的要求,满足不同程度要求的不同范式,目前关系数据库有六种范式
第一范式(1NF)、第二范式(2NF)、第三范式(3NF)、Boyce-Codd范式(BCNF)、第四范式(4NF)和第五范式(5NF)
满足最低要求的范式是第一范式(1NF),在第一范式的基础上进一步满足更多的称为第二范式(2NF),其余范式依次类推。一般来说,数据库只需满足第三范式(3NF)就可以了
第一范式(1NF):列不可再分
第一范式是最基本的范式,如果数据库中的所有字段值都是不可分解的原子值,就说明该数据库表满足了第一范式
第二范式(2NF):属性完全依赖于主键
第二范式是在第一范式的基础上建立起来的,也就是满足第二范式必须先满足第一范式。
第二范式要求数据库表中的每个实例或行必须可以被唯一的区分
每一行的数据只能与其中一列相关,即一行数据只做一件事。只要数据列中出现数据重复,就要把表拆分开
第三范式(3NF)属性不依赖于其他非主属性 属性直接依赖于主键
数据不能存在传递关系,即每个属性都跟主键有直接关系而不是间接关系
比如Student表(学号,姓名,年龄,性别,所在院校,院校地址,院校电话)
学号--》所在院校--》(院校地址,院校电话)
拆开(学号,姓名,年龄,性别,所在院校)-- (所在院校,院校地址,院校电话)
BCFN范式:所有属性都不传递依赖于关系的任何后选键
题目中关系模式满足第二范式,但在学生表S中,学生所在系(Sd)依赖学号(S#),而所在系的系主任(Dc)又依赖于学生所在系(Sd),存在传递依赖,不满足第三范式。
10. 数据库系统特点:高共享、低冗余、独立性高、具有完整性等

数据冗余度高就表示数据重复性高,而在设计数据库时对于冗余度是要求比较小的,具体做法是可以用主外键来进行关联到几张表中,从而减少数据冗余度
数据库系统特点:高共享、低冗余、独立性高、具有完整性等
11. 实体之间多对多联系在关系模型中的实现方式是 建立新的关系

实体-联系图(ER图),是一种以直观的图示化方式描述实体(集)及其之间联系的语义模型。
ER图中有四个基本成分
(1)矩形框,表示实体类型(研究问题的对象),矩形框中写明实体名
(2)菱形框,表示联系类型,菱形框内写明联系名
(3)椭圆形框,表示实体类型和联系类型的属性,椭圆内写明属性名
(4)直线,联系类型与其设计的实体类型之间以直线连接,表示它们之间的联系(1:1或1:N或M:N)
比如每个专业设置有多门课程,某些课程可被多个专业设置。专业实体集与课程实体集之间的联系在ER图中表示为多对多联系
但在关系模型中,要通过中间表来表达他们的多对多关系,所以选A

12.sum只能用于数值类型的列,Avg/Max/Min/Count都不是求和函数

B avg不属于求和函数,并且avg不能使用日期型的列
C Max和Min不属于求和函数,并且只能用于数值型的列
D Count属于不求和函数,可以用于字符型的列(count中可以使用任意类型的字段,常量也可)
13. 关系操作:自然连接、交、并、除

先来看一下这四个概念
自然连接:如果关系R与S具有相同的属性组B,且该属性组的值相等时的连接称为自然连接,结果关系的属性集合为R的属性并上S减去属性B的属性集合,自然连接也可看作是在广义笛卡尔积R*S中选出同名属性上符合相等条件元组,再进行投影,去掉重复的同名属性,组成新的关系
交:关系R与关系S的交运算结果由既属于R又属于S的元组(即R与S中相同的元组)组成一个新关系,如果两个关系没有相同的元组,那么它们的交为空
除:设关系R除以关系S的结果为关系T,则T包含所有在R但不再S中属性及其值,且T的元组与S的元组的所有组合都在R中
并:关系R与关系S的交运算结果既属于R或属于S的元组(即R和S的所有元组合并),删去重复元组,组成一个新关系,其结果仍为n元关系
本道题的过程是这样的
(1)求S中重复字段: A c B 3
(2)R中有,但S没有的字段 C:{2,1}
(3)R中,C = 2 :{a,1} C = 1:{ {b,2} , {c,3} }
对比后发现(1)中的S重复字段在 (3)的C=1中,所以这个是除
14. 关系数据库所采用的数据存放形式是 二维表

15. 员工编号有重复:不同部门,有相同的员工编号

根据业务来设计表:
(1)员工编号:可以标识数据(员工编号唯一,主键就是员工编号)
(2)员工编号有重复:不同部门,有相同的员工编号:主键就是员工编号+部门编号
16. 计算日期到天数转换
题目链接:计算日期到天数转换_牛客题霸_牛客网 (nowcoder.com)
题目要求:

题目分析:
这里需要分析的是,输入的年份是不是闰年,因为在闰年中二月是29天(正常2月是28天)
然后就是根据对应月份来计算天数,注意在计算月份中对应天数累加求和时,当月的不要计算,当月的要单独加输入的天数
上代码
import java.util.Scanner;
public class Main {
public static void main(String[] args) {
Scanner scan = new Scanner(System.in);
int n = scan.nextInt();
int y = scan.nextInt();
int r = scan.nextInt();
int[] array1 = new int[]{31,28,31,30,31,30,31,31,30,31,30,31};
int[] array2 = new int[]{31,29,31,30,31,30,31,31,30,31,30,31};//润年
int sum = 0;
//1.先判断闰年
if((n%4==0 && n%100 != 0) || (n%400 == 0)) {
//为闰年,2月29天
for (int i = 0; i < y-1; i++) {
sum += array2[i];
}
System.out.println(sum+r);
}else {
for (int i = 0; i < y-1; i++) {
sum += array1[i];
}
System.out.println(sum+r);
}
}
}