原文链接:https://www.techbeat.net/article-info?id=4212
作者:颜旭
点云作为一种基本的三维表征形式,活跃在自动驾驶、机器人感知等多种任务上。尽管三维点云分析在近年来取得了良好的发展,但由于点云其本身往往是无序、无纹理以及稀疏的存在,故基于单模态的点云分析正逐渐走向瓶颈。为了获得具备更强辨识能力的表征,有些方法引入了额外的二维图像信息(例如纹理、颜色和阴影等),然而这类方法严重增加模型的复杂性和计算量,且在应用场景中额外的图像信息往往是不存在的。
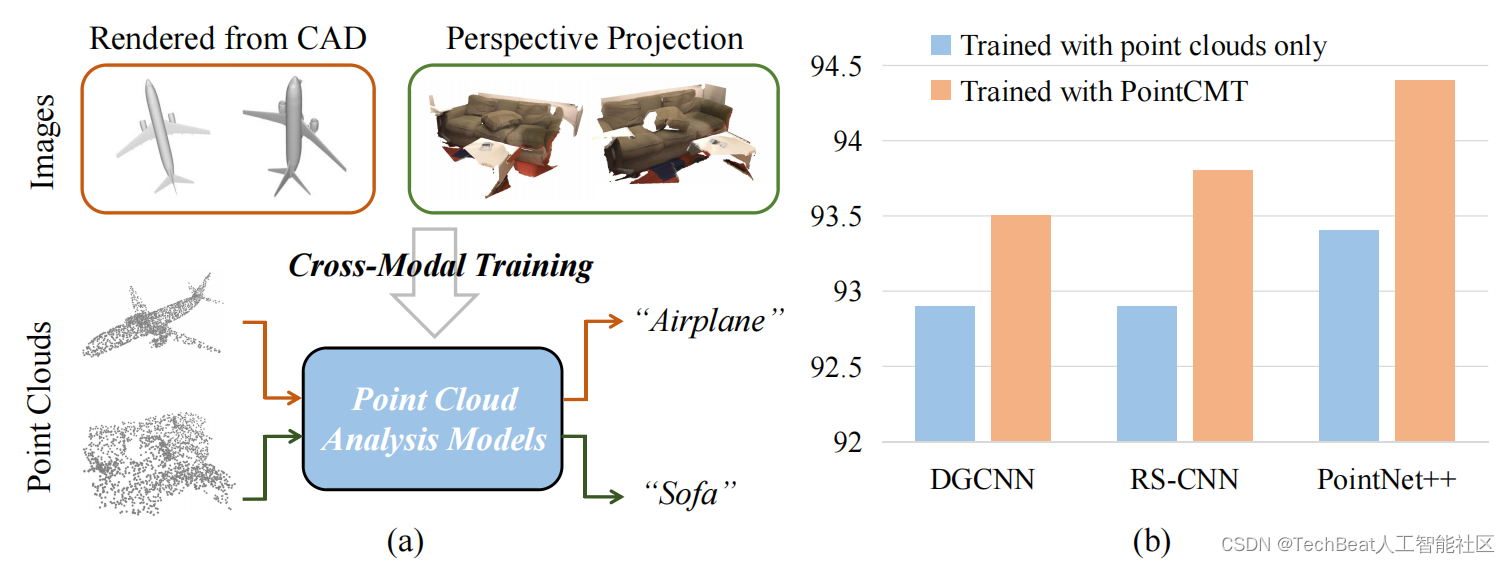
为了解决上述问题,香港中文大学深圳深度比特实验室提出了基于点云分析的跨模态知识蒸馏框架PointCMT作为点云多模态表征学习的新范式。PointCMT仅需要在训练阶段使用额外的图像数据,就能有效提升模型的表征能力,在测试阶段中被强化的模型可以单模态部署。在PointCMT的训练范式下,仅使用非常早期的基线模型PointNet++便可以在多个数据集上得到巨大提升,甚至在ModelNet40数据集上达到最先进的水平(94.4%)。不仅如此,更强的基线模型(例如PointMLP等)依然可以被PointCMT有效提升。该工作目前已发表在机器学习顶级会议NeurIPS 2022上。

论文地址:
https://arxiv.org/abs/2210.04208
GitHub:
https://github.com/ZhanHeshen/PointCMT
一、研究动机和方法
点云的跨模态学习
点云与图像的表征有明显差异——前者由三维空间中稀疏且无序的散点组成,而后者则由密集且规整的矩阵表示。其中,点云擅长描绘物体的空间信息与几何形状,但却常常稀疏且无纹理;图像有着丰富的颜色与纹理信息,但在深度与形状感知上却不如点云。因此,在改进点云分析时,我们自然会有疑问:是否可以利用图像中特有的信息来帮助点云进行表征学习?
上述问题被定义为点云的跨模态学习,而解决该问题的直接方法是对上述两种模态的信息进行融合。然而,直接融合不仅需要设计新的多模态模型,在测试阶段也需要成对的数据并进行更复杂的计算。本篇工作采用知识蒸馏作为基础的跨模态训练,该方法可以有效避免上述问题。
作为全新的多模态学习范式,PointCMT具有以下优势:
- 通用性: PointCMT可以应用于任意的点云分析模型,并不需要对模型结构进行修改;
- 有效性: PointCMT可以有效地提升数个基线方法在多个数据集上的效果;
- 高效性: PointCMT只在训练阶段使用额外的图像数据,在测试阶段中被强化的模型可以单模态独立部署;
- 灵活性: PointCMT可以通过简单的投影点云生成额外图片数据,不依赖于自然图像。
二、基于知识蒸馏
知识蒸馏是获取高效小规模网络的一种新兴方法,其主要思想是将学习能力强的复杂教师模型中的“知识”迁移到简单的学生模型中。传统的知识蒸馏往往假设学生模型与教师模型的训练数据有着相同的分布,甚至是相同的数据。但如果将传统的知识蒸馏放在跨模态的设定中,由于点云与图像在数据表征上有较大的差异且点云和图像的特征提取网络往往具有较大的差别,使得其很难直接被应用。
该工作首先从理论上证明了完成跨模态知识蒸馏的概率下确界(推导请参见原文)。
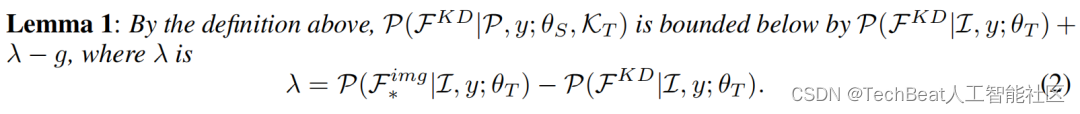
基于以上的问题定义,该工作设计了全新的跨模态知识蒸馏训练范式,可以让点云网络有效地获得来自图片信息的增益。
点云跨模态训练新范式
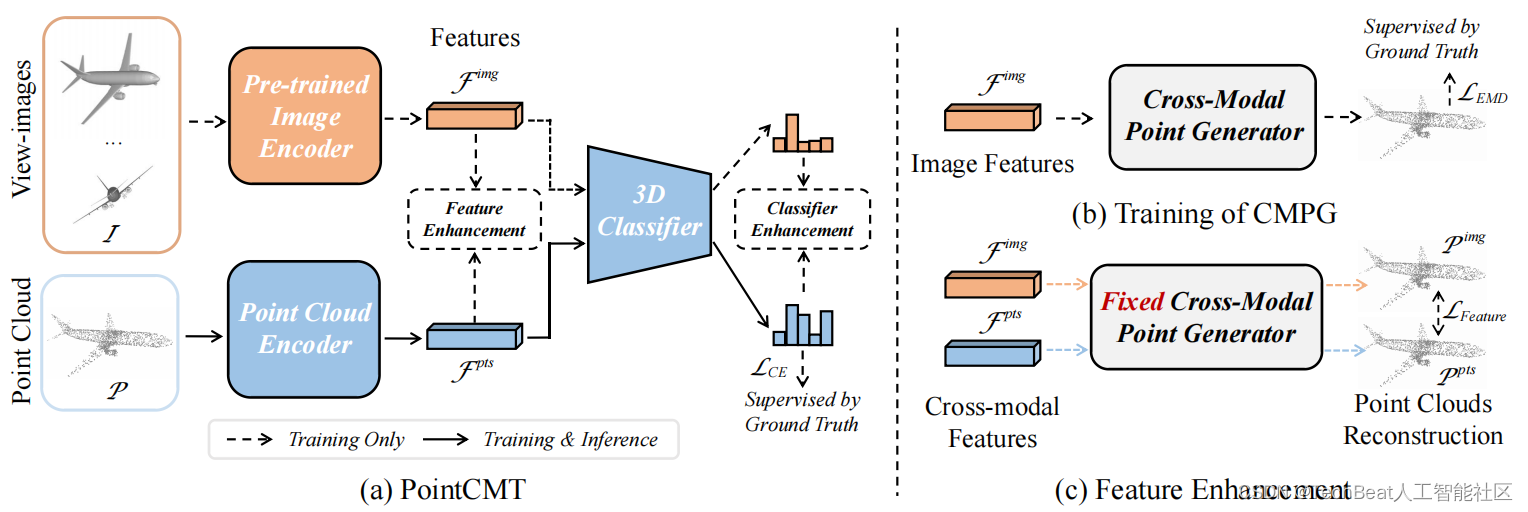
该工作提出的点云跨模态训练新范式PointCMT如上图所示。总体来说,PointCMT采取知识蒸馏常用的老师-学生框架。考虑到应用于点云和图片的网络结构往往在特征提取上完全不同,但都使用类似的线性层作为分类器,基于这个观察,PointCMT分别设计了两个损失项:特征增强(Feature Enhancement)和分类器增强(Classifier Enhancement)。其训练流程分为三个阶段:
阶段1: 训练图片网络
要利用图像对点云网络进行知识蒸馏,首先要获得具有强大先验的图片网络。针对每一个三维物体点云,PointCMT使用多视角图像作为额外数据——该图像既可以是通过渲染得到的自然图像,也可以是由点云投影得到的深度图。其通过共享权重的卷积神经网络得到逐个视角的图像特征,然后通过聚合函数得到该物体的全局特征,该全局特征通过分类器进行分类得到最终的分类结果。
阶段2: 训练跨模态点云生成器
跨模态点云生成器(CMPG)是该工作的核心之一,它的作用是将一个物体的全局特征重建成三维点云。在实验中,它可以仅仅由数个线性层组成。如上图(b)中所示,PointCMT使用预训练的图片网络提取三维物体的全局特征,并送入CMPG中生成原始点云,其中Earth Mover’s distance (EMD)作为损失函数来监督。
阶段3: 图像辅助点云训练
跨模态训练的过程如上图(a)所示,其中点云网络特征提取器得到的全局特征将被特征增强所强化;最终的分类概率除了受到物体类别标签的监督之外,还会受到分类器增强的监督。
特征增强
如上图(c)所示,利用阶段2中预训练的CMPG作为媒介,PointCMT对齐分别由点云和图像全局特征通过CMPG后重建的两个点云,其中EMD作为监督。

分类器增强
除了特征增强之外,PointCMT还利用图片网络得到的全局特征来增强点云的分类器。受到Hinton知识蒸馏的启发,PointCMT将图像与点云的特征分别输入点云网络的分类器,并用KL散度对齐两个特征得到的概率分布。这个部分,梯度会回传给点云的分类器,使得点云分类器能够处理两种模态的特征。两种损失的对比如下:
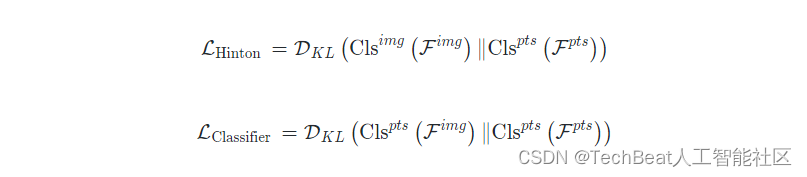
通过以上的设计,PointCMT不仅避免了传统知识蒸馏在跨模态场景中直接特征对齐而引入的知识负迁移影响,还可以同时提升特征提取器和分类器的性能。
三、实验结果
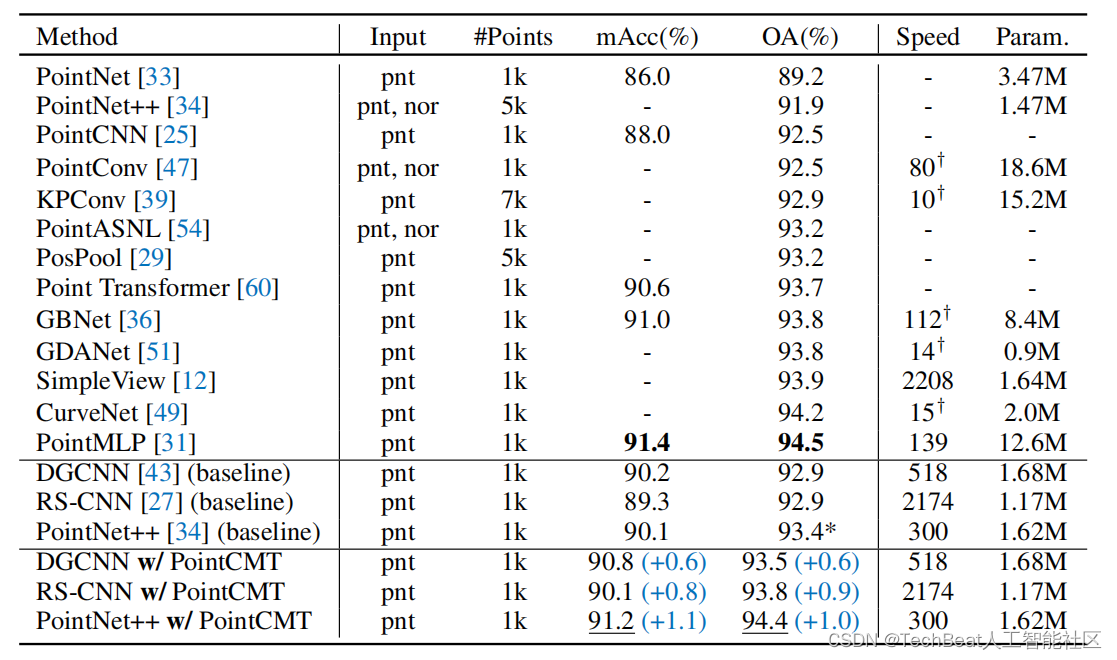
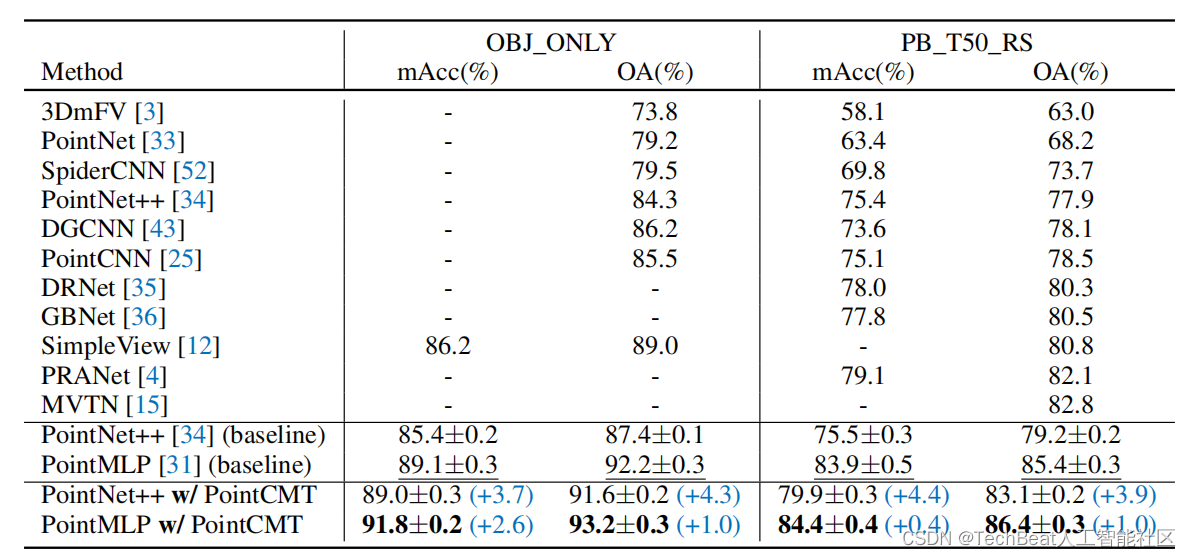
在PointCMT的训练范式下,PointNet++和PointMLP可以在多个基准(ModelNet40,ScanObjectNN)上达到最先进的水平。
图片输入
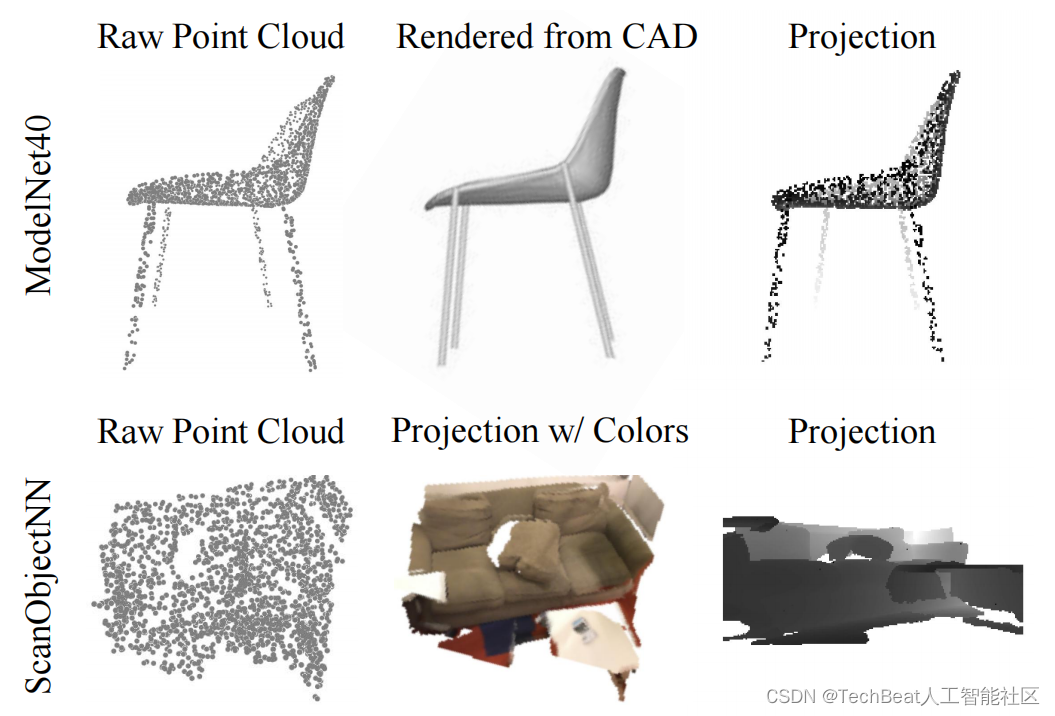
值得注意的是,由于ModelNet40中每一个物体的CAD模型可以获得,在该数据上额外的图片信息可以通过渲染CAD模型而获得。而在ScanObjectNN数据上(包含OBJ_ONLY和PB_T50_RS),图片信息仅能通过投影点云而获得(如下图所示)。
点云分类
以下为PointCMT在ModelNet40和ScanObjectNN上的实验结果。
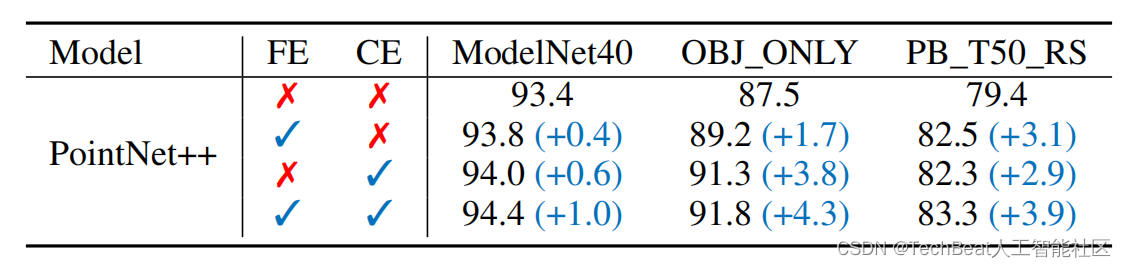
性能分析
特征增强和分类器增强均对模型具有极大的提升作用,尤其是在更加困难的ScanObjectNN数据上。
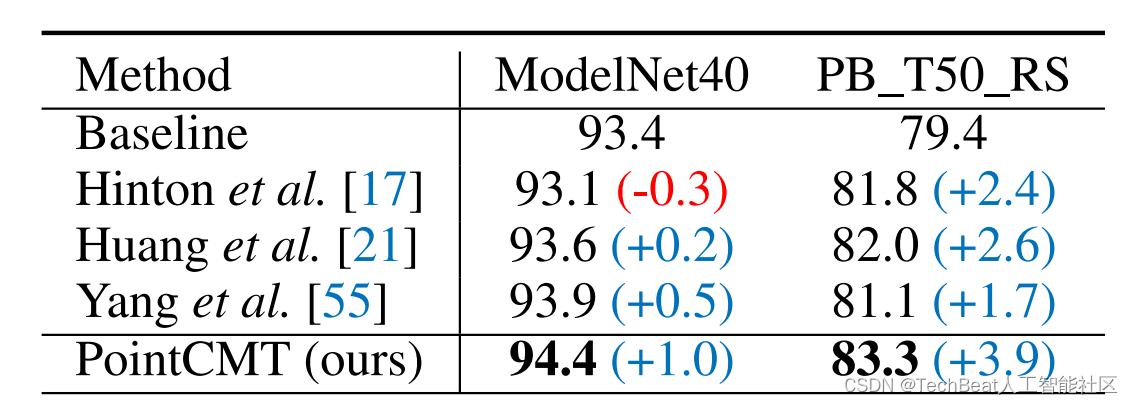
对比传统知识蒸馏
由于数据分布和模型差异,直接使用传统的知识蒸馏在点云跨模态学习这个情景下很难有效地提升模型性能,甚至会出现负迁移,而PointCMT在各数据上都获得了更大的提升。
更多实验与细节可以参见原文。
四、结语
本文介绍了一种由图像辅助的跨模态三维点云学习新范式(PointCMT)。该方法利用知识蒸馏来进行跨模态训练,从而在不改变网络结构、不引入额外模态测试样本的情况下有效提高点云网络的分类效果。该方法在多个基准上达到了最先进结果。
Illustration by Manypixels Gallery from IconScout
-The End-
关于我“门”
▼
将门是一家以专注于发掘、加速及投资技术驱动型创业公司的新型创投机构,旗下涵盖将门创新服务、将门-TechBeat技术社区以及将门创投基金。
将门成立于2015年底,创始团队由微软创投在中国的创始团队原班人马构建而成,曾为微软优选和深度孵化了126家创新的技术型创业公司。
如果您是技术领域的初创企业,不仅想获得投资,还希望获得一系列持续性、有价值的投后服务,欢迎发送或者推荐项目给我“门”:
bp@thejiangmen.com