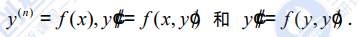1. 函数指针
1.1 函数类型
通过什么来区分两个不同的函数?
一个函数在编译时被分配一个入口地址,这个地址就称为函数的指针,函数名代表函数的入口地址。
函数三要素: 名称、参数、返回值。C语言中的函数有自己特定的类型。
c语言中通过typedef为函数类型重命名:
typedef int f(int, int); // f 为函数类型
typedef void p(int); // p 为函数类型这一点和数组一样,因此我们可以用一个指针变量来存放这个入口地址,然后通过该指针变量调用函数。
注意:通过函数类型定义的变量是不能够直接执行,因为没有函数体。只能通过类型定义一个函数指针指向某一个具体函数,才能调用。
typedef int(p)(int, int);
void my_func(int a,int b){
printf("%d %d\n",a,b);
}
void test(){
p p1;
//p1(10,20); //错误,不能直接调用,只描述了函数类型,但是并没有定义函数体,没有函数体无法调用
p* p2 = my_func;
p2(10,20); //正确,指向有函数体的函数入口地址
}1.2 函数指针(指向函数的指针)
函数指针定义方式:
先定义函数类型,根据类型定义指针变量;
先定义函数指针类型,根据类型定义指针变量;
直接定义函数指针变量;
int my_func(int a,int b){
printf("ret:%d\n", a + b);
return 0;
}
//1. 先定义函数类型,通过类型定义指针
void test01(){
typedef int(FUNC_TYPE)(int, int);
FUNC_TYPE* f = my_func;
//如何调用?
(*f)(10, 20);
f(10, 20);
}
//2. 定义函数指针类型
void test02(){
typedef int(*FUNC_POINTER)(int, int);
FUNC_POINTER f = my_func;
//如何调用?
(*f)(10, 20);
f(10, 20);
}
//3. 直接定义函数指针变量
void test03(){
int(*f)(int, int) = my_func;
//如何调用?
(*f)(10, 20);
f(10, 20);
}1.3 函数指针数组
函数指针数组,每个元素都是函数指针。
void func01(int a){
printf("func01:%d\n",a);
}
void func02(int a){
printf("func02:%d\n", a);
}
void func03(int a){
printf("func03:%d\n", a);
}
void test(){
#if 0
//定义函数指针
void(*func_array[])(int) = { func01, func02, func03 };
#else
void(*func_array[3])(int);
func_array[0] = func01;
func_array[1] = func02;
func_array[2] = func03;
#endif
for (int i = 0; i < 3; i ++){
func_array[i](10 + i);
(*func_array[i])(10 + i);
}
}1.4 函数指针做函数参数(回调函数)
函数参数除了是普通变量,还可以是函数指针变量。
//形参为普通变量
void fun( int x ){}
//形参为函数指针变量
void fun( int(*p)(int a) ){}函数指针变量常见的用途之一是把指针作为参数传递到其他函数,指向函数的指针也可以作为参数,以实现函数地址的传递。
int plus(int a, int b){
return a + b;
}
int sub(int a, int b){
return a - b;
}
int mul(int a, int b){
return a * b;
}
int division(int a, int b){
return a / b;
}
//函数指针 做函数的参数 --- 回调函数
void Calculator(int(*myCalculate)(int, int), int a, int b)
{
int ret = myCalculate(a, b); //dowork中不确定用户选择的内容,由后期来指定运算规则
printf("ret = %d\n", ret);
}
void test01()
{
printf("请输入操作符\n");
printf("1、+ \n");
printf("2、- \n");
printf("3、* \n");
printf("4、/ \n");
int select = -1;
scanf("%d", &select);
int num1 = 0;
printf("请输入第一个操作数:\n");
scanf("%d", &num1);
int num2 = 0;
printf("请输入第二个操作数:\n");
scanf("%d", &num2);
switch (select)
{
case 1:
Calculator(plus, num1, num2);
break;
case 2:
Calculator(sub, num1, num2);
break;
case 3:
Calculator(mul, num1, num2);
break;
case 4:
Calculator(division, num1, num2);
break;
default:
break;
}
}注意:函数指针和指针函数的区别:
函数指针是指向函数的指针;
指针函数是返回类型为指针的函数;
2. 预处理
2.1 预处理的基本概念
C语言对源程序处理的四个步骤:预处理、编译、汇编、链接。
预处理是在程序源代码被编译之前,由预处理器(Preprocessor)对程序源代码进行的处理。这个过程并不对程序的源代码语法进行解析,但它会把源代码分割或处理成为特定的符号为下一步的编译做准备工作。
2.2 文件包含指令(#include)
2.2.1 文件包含处理
文件包含处理”是指一个源文件可以将另外一个文件的全部内容包含进来。C语言提供了#include命令用来实现“文件包含”的操作。
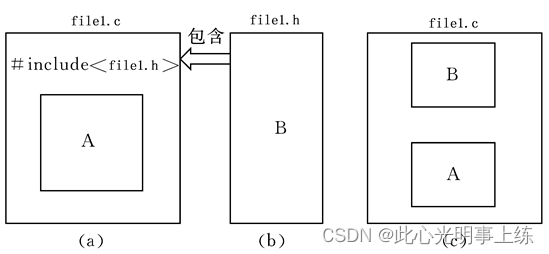
2.2.2 #incude<>和#include""区别
"" 表示系统先在file1.c所在的当前目录找file1.h,如果找不到,再按系统指定的目录检索。
< > 表示系统直接按系统指定的目录检索。
注意:
1.#include <>常用于包含库函数的头文件;
2.#include ""常用于包含自定义的头文件;
3. 理论上#include可以包含任意格式的文件(.c .h等) ,但一般用于头文件的包含;
2.3 宏定义
2.3.1 无参数的宏定义(宏常量)
如果在程序中大量使用到了100这个值,那么为了方便管理,我们可以将其定义为:
const int num =100; 但是如果我们使用num定义一个数组,在不支持c99标准的编译器上是不支持的,因为num不是一个编译器常量,如果想得到了一个编译器常量,那么可以使用:
#define num 100
在编译预处理时,将程序中在该语句以后出现的所有的num都用100代替。这种方法使用户能以一个简单的名字代替一个长的字符串,在预编译时将宏名替换成字符串的过程称为“宏展开”。宏定义,只在宏定义的文件中起作用。
#define PI 3.1415
void test(){
double r = 10.0;
double s = PI * r * r;
printf("s = %lf\n", s);
}说明:
宏名一般用大写,以便于与变量区别;
宏定义可以是常数、表达式等;
宏定义不作语法检查,只有在编译被宏展开后的源程序才会报错;
宏定义不是C语言,不在行末加分号;
宏名有效范围为从定义到本源文件结束;
可以用#undef命令终止宏定义的作用域;
在宏定义中,可以引用已定义的宏名;
2.3.2 带参数的宏定义(宏函数)
在项目中,经常把一些短小而又频繁使用的函数写成宏函数,这是由于宏函数没有普通函数参数压栈、跳转、返回等的开销,可以调高程序的效率。
宏通过使用参数,可以创建外形和作用都与函数类似地类函数宏(function-likemacro). 宏的参数也用圆括号括起来。
#define SUM(x,y) (( x )+( y ))
void test(){
//仅仅只是做文本替换 下例替换为 int ret = ((10)+(20));
//不进行计算
int ret = SUM(10, 20);
printf("ret:%d\n",ret);
}注意:
宏的名字中不能有空格,但是在替换的字符串中可以有空格。ANSI C允许在参数列表中使用空格;
用括号括住每一个参数,并括住宏的整体定义。
用大写字母表示宏的函数名。
如果打算宏代替函数来加快程序运行速度。假如在程序中只使用一次宏对程序的运行时间没有太大提高。
2.4 条件编译
2.4.1 基本概念
一般情况下,源程序中所有的行都参加编译。但有时希望对部分源程序行只在满足一定条件时才编译,即对这部分源程序行指定编译条件。
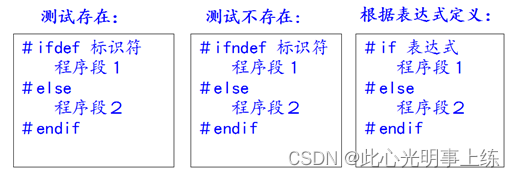
2.4.2 条件编译
防止头文件被重复包含引用;
#ifndef _SOMEFILE_H
#define _SOMEFILE_H
//需要声明的变量、函数
//宏定义
//结构体
#endif2.5 一些特殊的预定宏
C编译器,提供了几个特殊形式的预定义宏,在实际编程中可以直接使用,很方便。
// __FILE__ 宏所在文件的源文件名
// __LINE__ 宏所在行的行号
// __DATE__ 代码编译的日期
// __TIME__ 代码编译的时间
void test()
{
printf("%s\n", __FILE__);
printf("%d\n", __LINE__);
printf("%s\n", __DATE__);
printf("%s\n", __TIME__);
}3. 动态库的封装和使用
3.1 库的基本概念
库是已经写好的、成熟的、可复用的代码。每个程序都需要依赖很多底层库,不可能每个人的代码从零开始编写代码,因此库的存在具有非常重要的意义。
在我们的开发的应用中经常有一些公共代码是需要反复使用的,就把这些代码编译为库文件。
库可以简单看成一组目标文件的集合,将这些目标文件经过压缩打包之后形成的一个文件。像在Windows这样的平台上,最常用的c语言库是由集成按开发环境所附带的运行库,这些库一般由编译厂商提供。
3.2 windows下静态库创建和使用
3.2.1 静态库的创建
创建一个新项目,在已安装的模板中选择“常规”,在右边的类型下选择“空项目”,在名称和解决方案名称中输入staticlib。点击确定。
在解决方案资源管理器的头文件中添加,mylib.h文件,在源文件添加mylib.c文件(即实现文件)。
在mylib.h文件中添加如下代码:
#ifndef TEST_H
#define TEST_H
int myadd(int a,int b);
#endif在mylib.c文件中添加如下代码:
#include"test.h"
int myadd(int a, int b){
return a + b;
}配置项目属性。因为这是一个静态链接库,所以应在项目属性的“配置属性”下选择“常规”,在其下的配置类型中选择“静态库(.lib)。
编译生成新的解决方案,在Debug文件夹下会得到mylib.lib (对象文件库),将该.lib文件和相应头文件给用户,用户就可以使用该库里的函数了。
3.2.2 静态库的使用
方法一:配置项目属性
添加工程的头文件目录:工程---属性---配置属性---c/c++---常规---附加包含目录:加上头文件存放目录。
添加文件引用的lib静态库路径:工程---属性---配置属性---链接器---常规---附加库目录:加上lib文件存放目录。
然后添加工程引用的lib文件名:工程---属性---配置属性---链接器---输入---附加依赖项:加上lib文件名。
方法二:使用编译语句
#pragma comment(lib,"./mylib.lib")方法三:添加工程中
就像你添加.h和.c文件一样,把lib文件添加到工程文件列表中去.
切换到"解决方案视图",--->选中要添加lib的工程-->点击右键-->"添加"-->"现有项"-->选择lib文件-->确定.
3.2.3 静态库优缺点
静态库对函数库的链接是放在编译时期完成的,静态库在程序的链接阶段被复制到了程序中,和程序运行的时候没有关系;
程序在运行时与函数库再无瓜葛,移植方便。
浪费空间和资源,所有相关的目标文件与牵涉到的函数库被链接合成一个可执行文件。
内存和磁盘空间
静态链接这种方法很简单,原理上也很容易理解,在操作系统和硬件不发达的早期,绝大部门系统采用这种方案。随着计算机软件的发展,这种方法的缺点很快暴露出来,那就是静态链接的方式对于计算机内存和磁盘空间浪费非常严重。特别是多进程操作系统下,静态链接极大的浪费了内存空间。在现在的linux系统中,一个普通程序会用到c语言静态库至少在1MB以上,那么如果磁盘中有2000个这样的程序,就要浪费将近2GB的磁盘空间。
程序开发和发布
空间浪费是静态链接的一个问题,另一个问题是静态链接对程序的更新、部署和发布也会带来很多麻烦。比如程序中所使用的mylib.lib是由一个第三方厂商提供的,当该厂商更新容量mylib.lib的时候,那么我们的程序就要拿到最新版的mylib.lib,然后将其重新编译链接后,将新的程序整个发布给用户。这样的做缺点很明显,即一旦程序中有任何模块更新,整个程序就要重新编译链接、发布给用户,用户要重新安装整个程序。
3.3 windows下动态库创建和使用
要解决空间浪费和更新困难这两个问题,最简单的办法就是把程序的模块相互分割开来,形成独立的文件,而不是将他们静态的链接在一起。简单地讲,就是不对哪些组成程序的目标程序进行链接,等程序运行的时候才进行链接。也就是说,把整个链接过程推迟到了运行时再进行,这就是动态链接的基本思想。
3.3.1 动态库的创建
创建一个新项目,在已安装的模板中选择“常规”,在右边的类型下选择“空项目”,在名称和解决方案名称中输入mydll。点击确定。
在解决方案资源管理器的头文件中添加,mydll.h文件,在源文件添加mydll.c文件(即实现文件)。
在mydll.h文件中添加如下代码:
#ifndef TEST_H
#define TEST_H
__declspec(dllexport) int myminus(int a, int b);
#endif在mydll.c文件中添加如下代码:
#include"test.h"
__declspec(dllexport) int myminus(int a, int b){
return a - b;
}配置项目属性。因为这是一个动态链接库,所以应在项目属性的“配置属性”下选择“常规”,在其下的配置类型中选择“动态库(.dll)。
编译生成新的解决方案,在Debug文件夹下会得到mydll.dll (对象文件库),将该.dll文件、.lib文件和相应头文件给用户,用户就可以使用该库里的函数了。
疑问一:__declspec(dllexport)是什么意思?
动态链接库中定义有两种函数:导出函数(export function)和内部函数(internal function)。 导出函数可以被其它模块调用,内部函数在定义它们的DLL程序内部使用。
疑问二:动态库的lib文件和静态库的lib文件的区别?
使用动态库的时候,往往提供两个文件:一个引入库(.lib)文件(也称“导入库文件”)和一个DLL(.dll)文件。虽然引入库的后缀名也是“lib”,但是,动态库的引入库文件和静态库文件有着本质的区别, 对一个DLL文件来说,其引入库文件(.lib)包含该DLL导出的函数和变量的符号名,而.dll文件包含该DLL实际的函数和数据。在使用动态库的情况下,在编译链接可执行文件时,只需要链接该DLL的引入库文件,该DLL中的函数代码和数据并不复制到可执行文件,直到可执行程序运行时,才去加载所需的DLL,将该DLL映射到进程的地址空间中,然后访问DLL中导出的函数。
3.3.2 动态库的使用
方法一:隐式调用
创建主程序TestDll,将mydll.h、mydll.dll和mydll.lib复制到源代码目录下。
(P.S:头文件Func.h并不是必需的,只是C++中使用外部函数时,需要先进行声明)
在程序中指定链接引用链接库 : #pragmacomment(lib,"./mydll.lib")
方法二:显式调用
HANDLE hDll; //声明一个dll实例文件句柄
hDll = LoadLibrary("mydll.dll"); //导入动态链接库
MYFUNC minus_test; //创建函数指针
//获取导入函数的函数指针
minus_test = (MYFUNC)GetProcAddress(hDll, "myminus");4.递归函数
4.1 递归函数基本概念
C通过运行时堆栈来支持递归函数的实现。递归函数就是直接或间接调用自身的函数。
注意:递归函数必须要有结束条件,否则进入死循环
4.2 普通函数调用
void funB(int b){
printf("b = %d\n", b);
}
void funA(int a){
funB(a - 1);
printf("a = %d\n", a);
}
int main(void){
funA(2);
printf("main\n");
return 0;
}函数的调用流程如下:
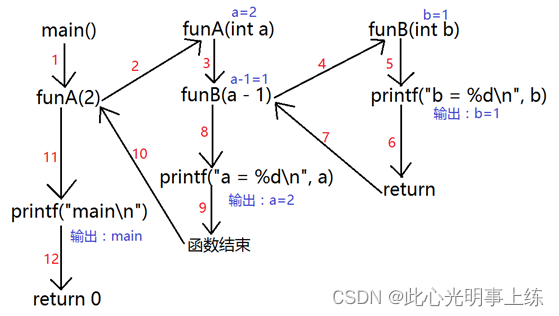
4.3 递归函数调用
递归实现给出一个数8793,依次打印千位数字8、百位数字7、十位数字9、个位数字3。
void recursion(int val){
if (val == 0){
return;
}
int ret = val / 10;
recursion(ret);
printf("%d ",val % 10);
}4.4 递归实现字符串反转
int reverse1(char *str){
if (str == NULL)
{
return -1;
}
if (*str == '\0') // 函数递归调用结束条件
{
return 0;
}
reverse1(str + 1);
printf("%c", *str);
return 0;
}4.5 斐波那契数列 案例
int fibonacci(int pos){
if(pos == 1 || pos == 2) {
return 1;
}
return fibonacci(pos -2) + fibonacci(pos -1);
}