一.应用层协议
对于应用层而言,协议是开发者自己进行定义的,开发者根据自定义的格式规范对数据进行编码和解析。
但是从原理上进行分析,其核心主要包括两点内容:
①确定客户端和服务端交互的内容(协议的内容)
②确定传输数据的组织方式
我们使用当下主流的应用层协议进行举例说明:
①HTTP协议
类似于百度的网址,前域名中会包括http的固定格式
https://www.baidu.com/?tn=44004473_52_oem_dg
②XML

我们通过观察xml的文件格式,我们可以发现:其可读性较高,但是我们在传输数据时,其内容中伴随的各种数据头,在网络传输过程中比较复杂,数据在网络传输过程相对比较冗余,效率较低
③JSON
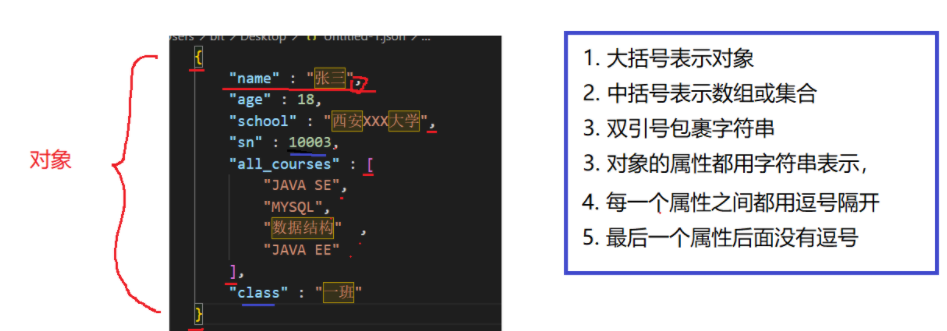
JSON相对于xml对数据头信息做了一定的优化,其相对xml文件内容更美观,可读性高,扩展性也相对较高,数据头信息简化很多,传输效率也较高。
④其他协议
Google:protobuf协议
IBM:MQTT协议,消息队列遥测传输,针对物联网设计的协议:消息以字节的格式传输,不同字节大小的消息代表着不同的含义,省略了多余的字符,大量减少了报文的长度,大幅减少了网络传输中宽带的长度,但是编码和解析的过程相对比较复杂。
传输层协议:由操作系统实现并给上面的应用层提供API接口
二.UDP协议
我们将从UDP协议的几个特点对其进行讲述:
①无连接
按照UDP协议进行数据的传输,只要直到目的ip和端口,就能进行数据的传输。就类似于发短信的过程我们在发短信时,不需要事先与对方进行连接
②不可靠传输
类似于我们发短信的过程,我们负责发短信,并不负责短信是否被接收方收到,也不对数据的正确性进行校验,如果数据错误UDP协议层也不会给应用层返回任何错误信息
③以数据报形式进行数据的传输
应用层传输给UDP多大的报文,UDP就必须按照多大的报文进行完整传输,不能对报文内容进行分批循环传输
④大小受限
UDP首部有一个16位的最大长度限制,也就是说,一次UDP传输,只能传输64kb的数据(包含UDP首部)
⑤缓冲区
UDP没有发送缓存区,只有接收缓存区
发送的数据会直接交给内核,然后由内核传输给网络层进行下一步的数据传输。
虽然UDP有接受数据的缓存区,但是缓存区有一定的范围大小,一旦缓存区满了,再发送的数据将会被丢失;同时,缓存区无法保证发送的UDP报和接收到的UDP报一致。
UDP的socket既可以发送数据,也能接收数据,这个概念叫做双全工。
UDP协议的格式:
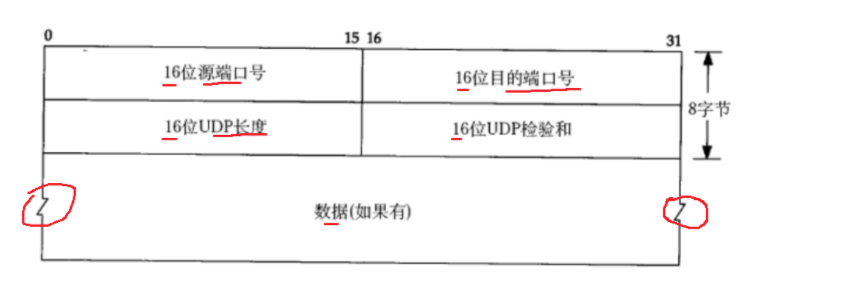

65535个字节长度的数据也就是

所以UDP每次最多传输64kb的数据
我们对16位UDP检验和进行一定的说明:
数据被转化为字节之后会按照自己的方式进行相加,在数据发出时将结果进行保存,在接收端时数据会重新按照同样的方式进行相加,如果两次校验和数据相同,那么数据是正确的,如果两次校验和不相同,那么说明数据在传输过程中被篡改了,这种数据校验的方式是CRC循环冗余校验

三.TCP协议
3.1TCP的可靠传输
①确认应答
我们思考这样一个场景:当我们进行聊天时,我们通过对方的回应来确定对方收到了我们发送的消息
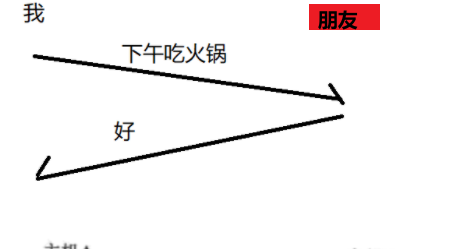
如果是在一问一答的情境下,这种回应并不会产生问题,但是如果是在网络乱序的情况下,我们发送了两条消息,对方回应了我们两条消息,我们如何区分对方的回应是针对那条消息的呢?
其实有一个相对简单的方法,对请求和回应都加上序号:

那么在网络传输中,TCP又是如何保证大量数据的正确传输呢?
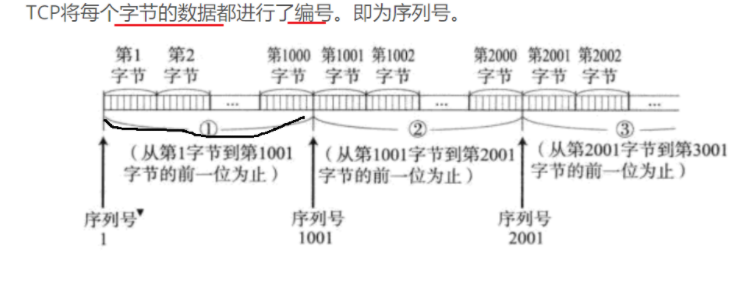
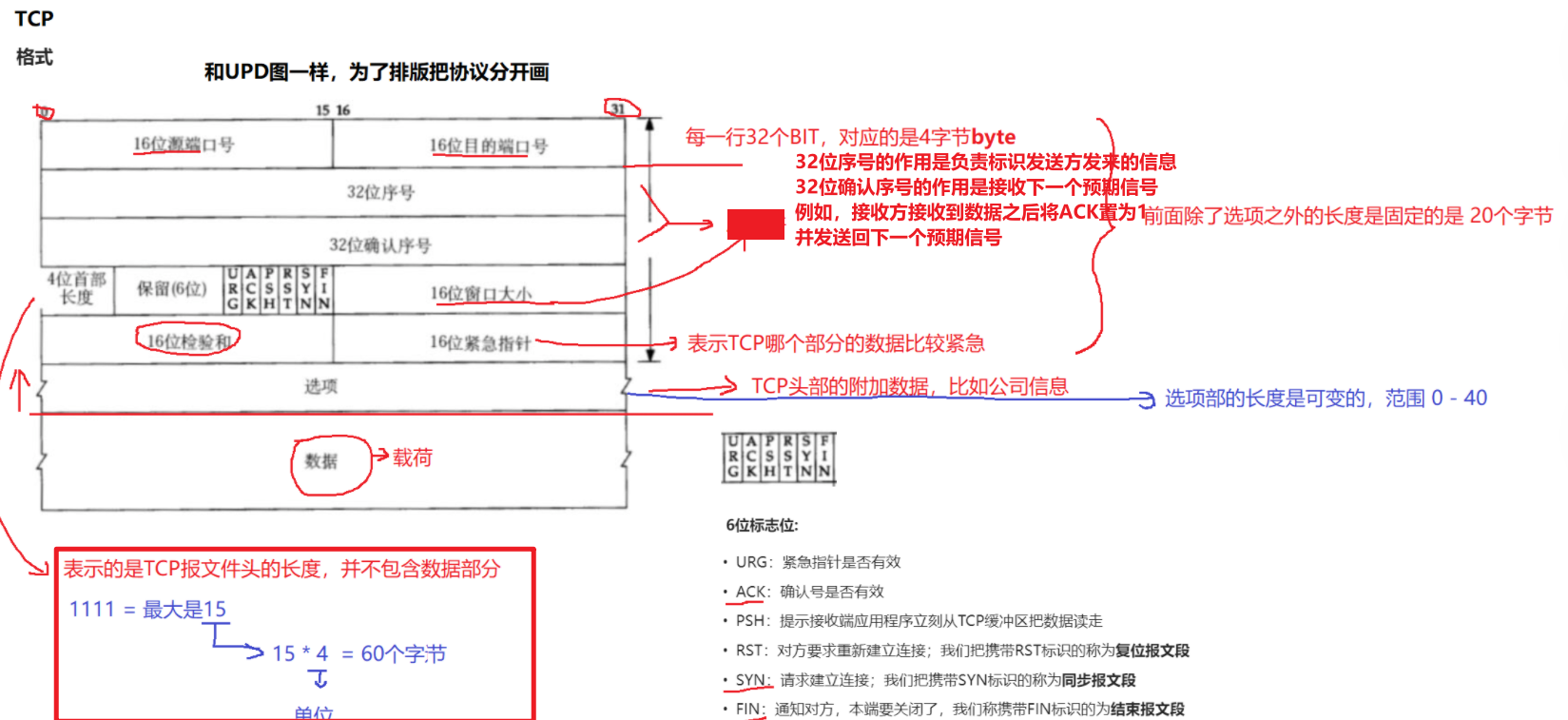
TCP是按照字节流的方式进行数据的传输,也就是说,任何数据在网络传输过程中都会被转化为字节,TCP通过给每个字节添加序列号来达到多条数据的正确传输,具体如下:
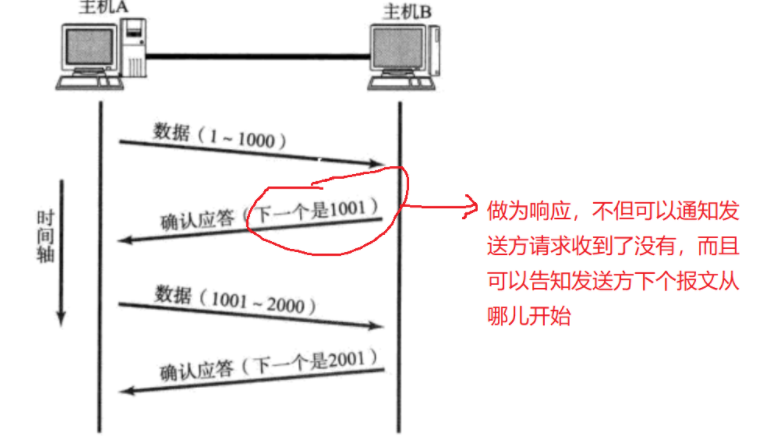
比如在第一次传输过程中,请求方发送了1-1000序号的字节流,然后接收方就返回1001的序号,用来提示请求方下次数据的发送从序号为1001的字节开始,如此反复,直至通信结束。
而这些标识数据的方式,就保存在32位序号和确认序号中。

②超时重传
数据在网络传输过程中会经过很多的网络设备,但是网络设备的储存容量都是一定的,一旦某台网络设备超过了其能储存数据容量的极限,就会将新接收的数据进行丢弃,而对于数据接收方而言,在一定时间内没有接收到请求的数据,我们称之为数据传输超时。
数据传输超时主要包括以下情况:

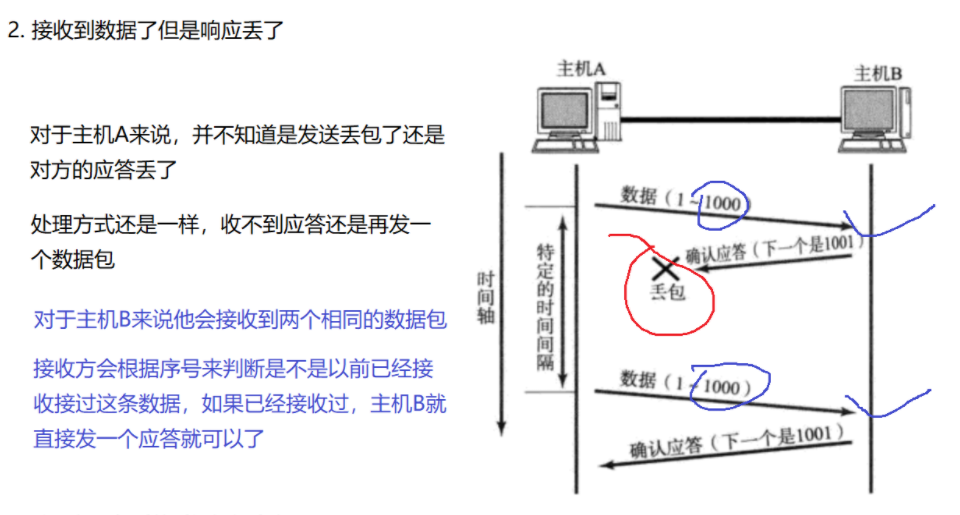
TCP超时重传机制就是为了解决数据丢失问题:对于数据的发送方而言,如果发送了数据,在请求时间内没有接收到回应,就会重新再发送一遍数据,但是对于接收方而言,如果是因为在发送回应数据时出现了丢包问题,那么其接收数据是不是就重复了呢?
事实并非如此,对于数据接收方而言,其存在一个数据缓存区(我们可以将其理解为一个阻塞队列),数据放入时我们首先会检查缓存区中是否存在这些数据,如果存在就将新数据丢弃,不存在则加入,这样就保证了socket api拿到的为不重复的数据。
那么超时时间又该如何确定呢?

③连接管理
目的:在发送方和请求方初次建立连接的时候,保证双方具有收发数据的能力,换句话说,要通过连接管理来确保网络数据传输的稳定性和有效性
①三次握手
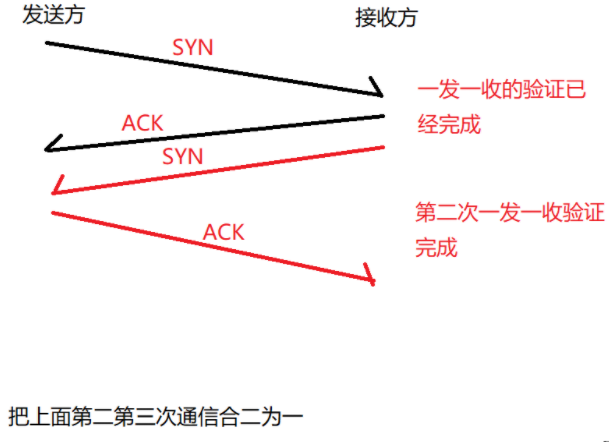

三次握手的过程可以这样理解:发送方发送数据给接收方,接收方受到数据给出回应,同时接收方也主动发送数据给发送方,最后发送方回应接收方的请求(我们通常把接收方的第一次的回应主动发送请求理解为一次数据传输,所以称为三次握手)
三次握手的目的是为了检测网络进行数据传输的可靠性,如果三次握手没有满足,那么双方需要重新协商一些其他信息。
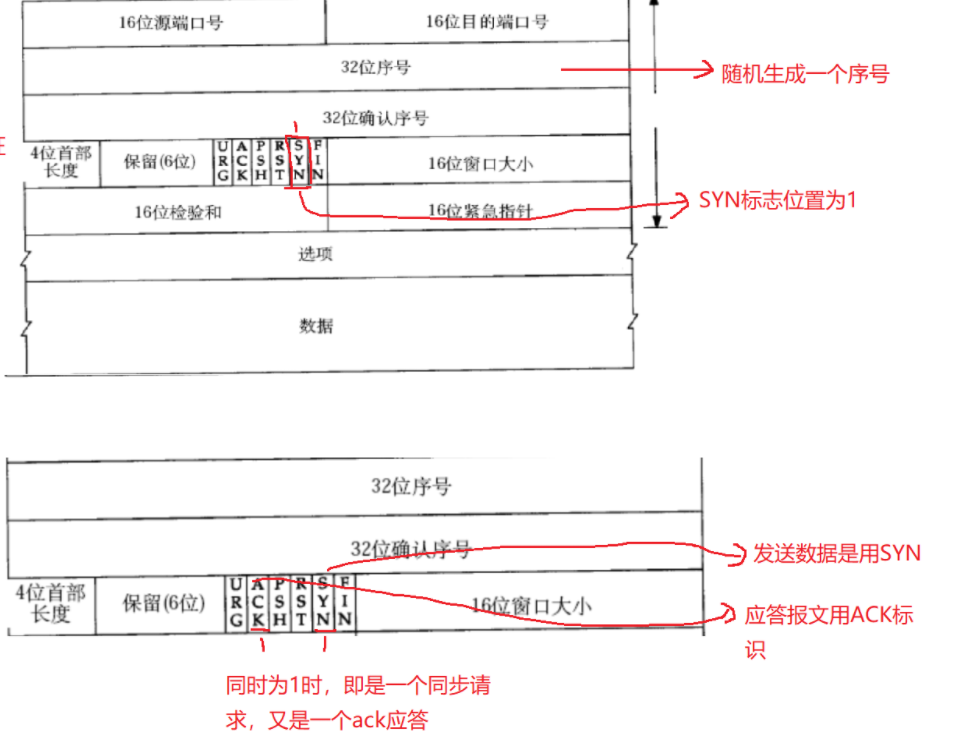
当发送方给接收方发送数据时,syn置为1,当接收方发送回应给发送方时,ack置为1,当两者同时置为1时我们称之为同步请求
在三次握手时状态的变化:

②四次挥手
保证发送方和接收方进行有效的断开连接

发送方发起断开连接请求,接收方回应请求,同时接收方也发起断开请求,最后发送方给出ACK回应

四次挥手服务端状态分析:
CLOSE_WAIT:四次挥手挥了了两次之后出现的状态,这个状态就是在等待代码中调用socket.close()方法来进行后续的挥手过程~正常情况下,一个服务器上不应该存在大量的CLOSE_WAIT。如果存在,说明大概率是代码存在bug,close没有被执行到
TIME_WAIT:谁主动发起FIN,谁就进入TIME_WAIT.起到的效果就是给最后一次ACK提供重传机会,表面上看起来A发送完ACK之后就没有A的事了,按理说A此时就应该销毁连接释放资源了,但是并没有直接释放,而是会进入TIME_WAIT状态等待一段时间,一段时间之后再进行释放,目的是,怕最后一个ACK丢包,如果最后一个ACK丢包了就意味着B会重传FIN,这时则需要发起者重新回应ACK
TIME_WAIT应该持续多久:2*MSL
为什么呢?
TIME_WAIT状态是为了防止最后一个ACK在传输过程中的丢包问题,正常接收端接收到ACK的时间是MSL,但是由于在这个时间内没有收到ACK,那么接收端则重新发起FIN请求,这时FIN传输到发送端也需要FIN的时间,所以为了避免ACK的丢包问题,TIME_WAIT时间应该存在2*MSL













![[python入门(51)] - python时间日期格式time和datetime](https://img-blog.csdnimg.cn/df610f8954064a3ba9a8ebace394bfed.png)