目录
- 1. 多表查询示例
- 2. 多表查询分类
- 2.1 等/非等值连接
- 2.1.1 等值连接
- 2.1.2非等值连接
- 2.2 自然/非自然连接
- 2.3 内/外连接
- 2.3.1 内连接
- 2.3.2 外连接
- 3.UNION的使用
- 3.1 合并查询结果
- 3.1.1 UNION操作符
- 3.1.2 UNION ALL操作符
- 4. 7种JOIN操作
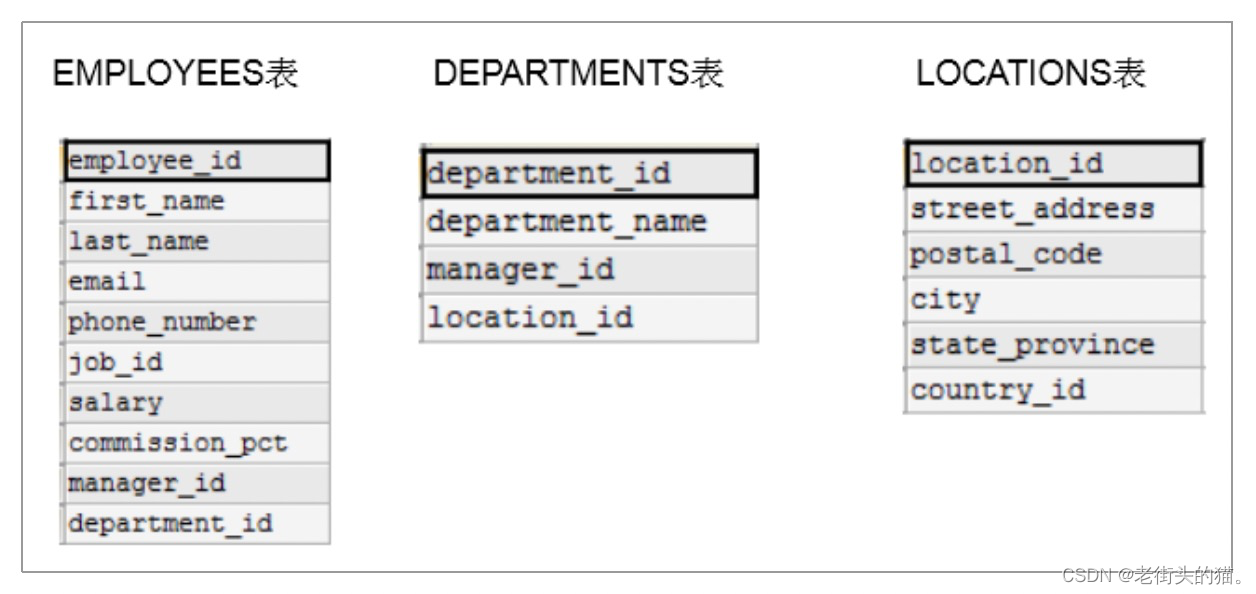
多表查询,也称为关联查询,指两个或更多个表一起完成查询操作。
- 如果查询语句中出现了多个表中都存在的字段,则必须指明此字段所在的表。
SELECT tb_a.id, tb_b.id FROM tb_a,tb_b WHERE tb_a.id=tb_b.id;
- 可以给表起别名,在SELECT和WHERE中使用表的别名
SELECT t1.id, t2.id FROM tb_a as t1,tb_b as t2 WHERE t1.id=t2.id;
- 如果给表起了别名,一旦在SELECT或WHERE中使用表名的话,则必须使用表的别名,而不是使用表的原名。
- 如果有n个表实现多表的查询,则需要至少n-1个连接条件
1. 多表查询示例
新建表:
SELECT e.employee_id as '员工id',
e.last_name as '员工名称',
d.department_name as '员工所在部门',
l.city as '部门所在城市'
FROM employees e, departments d, locations l
WHERE e.department_id=d.department_id
AND d.location_id=l.location_id;
结果:
| 员工id | 员工名称 | 员工所在部门 | 部门所在城市 |
|---|---|---|---|
| 200 | Whalen | Administration | Seattle |
| 201 | Hartstein | Marketing | Toronto |
| 202 | Fay | Marketing | Toronto |
| 114 | Raphaely | Purchasing | Seattle |
| 115 | Khoo | Purchasing | Seattle |
2. 多表查询分类
2.1 等/非等值连接
2.1.1 等值连接
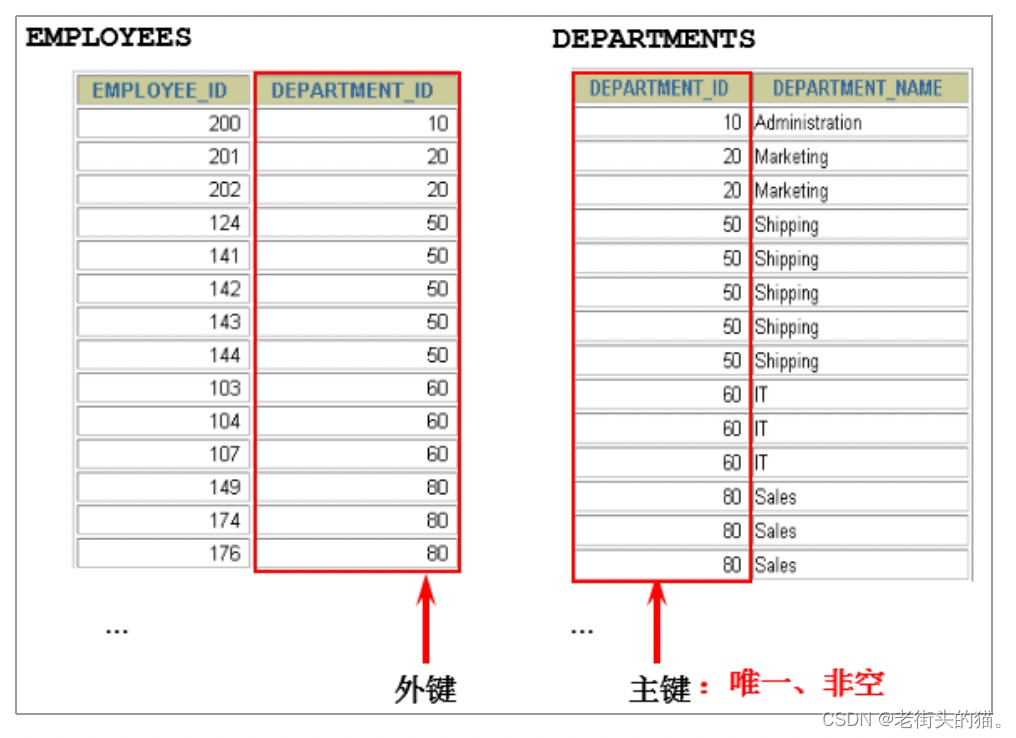
SELECT employees.employee_id as '员工id',
employees.last_name as '员工名称',
employees.department_id as '部门id',
departments.department_id as '部门id',
departments.department_name as '部门名称',
departments.location_id as '位置id'
FROM employees, departments
WHERE employees.department_id = departments.department_id;
| 员工id | 员工名称 | 部门id | 部门id | 部门名称 | 位置id |
|---|---|---|---|---|---|
| 200 | Whalen | 10 | 10 | Administration | 1700 |
| 201 | Hartstein | 20 | 20 | Marketing | 1800 |
| 202 | Fay | 20 | 20 | Marketing | 1800 |
| 114 | Raphaely | 30 | 30 | Purchasing | 1700 |
| … |
2.1.2非等值连接
SELECT e.last_name as '员工名称',
e.salary as '员工薪资',
j.grade_level as '员工级别'
FROM employees e, job_grades j
WHERE e.salary BETWEEN j.lowest_sal AND j.highest_sal;
-- 或者
WHERE e.salary >= j.lowest_sal AND e.salary <= j.highest_sal;
| 员工名称 | 员工工资 | 员工级别 |
|---|---|---|
| King | 24000 | E |
| Kochhar | 17000 | E |
| De Haan | 17000 | E |
| Hunold | 9000 | C |
| Ernst | 6000 | C |
| Austin | 4800 | B |
2.2 自然/非自然连接
SELECT emp.employee_id as '员工id',
emp.last_name as '员工名称',
mgr.employee_id as '管理者id',
mgr.last_name as '管理者名称'
FROM employees emp, employees mgr
WHERE emp.manager_id = mgr.employee_id;
或者
SELECT CONCAT(worker.last_name ,' works for ' , manager.last_name)
FROM employees worker, employees manager
WHERE worker.manager_id = manager.employee_id ;
| 员工id | 员工名称 | 管理者id | 管理者名称 |
|---|---|---|---|
| 101 | Kochhar | 100 | King |
| 102 | De Haan | 100 | King |
| 103 | Hunold | 102 | De Haan |
| 104 | Ernst | 103 | Hunold |
| 105 | Austin | 103 | Hunold |
| 106 | Pataballa | 103 | Hunold |
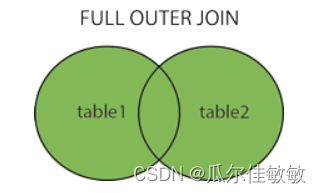
2.3 内/外连接
- 内连接: 合并具有同一列的两个以上的表的行, 结果集中不包含一个表与另一个表不匹配的行
- 外连接: 两个表在连接过程中除了返回满足连接条件的行以外**还返回左(或右)表中不满足条件的行,这种连接称为左(或右)外连接。**没有匹配的行时, 结果表中相应的列为空(NULL)。
- 如果是左外连接,则连接条件中左边的表也称为主表,右边的表称为从表。
- 如果是右外连接,则连接条件中右边的表也称为主表,左边的表称为从表。
2.3.1 内连接
SELECT e.employee_id, d.department_id, l.city
FROM employees e
INNER JOIN departments d
ON e.department_id = d.department_id
INNER JOIN locations l
ON d.location_id = l.location_id;
-- 返回 employees_id和department_id都不为NULL的数据
2.3.2 外连接
-- 左外连接
SELECT e.employee_id, d.department_id
FROM employees e
LEFT OUTER JOIN departments d
ON e.department_id = d.department_id;
-- 右外连接
SELECT e.employee_id, d.department_id
FROM employees e
RIGHT OUTER JOIN departments d
ON e.department_id = d.department_id;
3.UNION的使用
3.1 合并查询结果
利用UNION关键字,可以给出多条SELECT语句,并将它们的结果组合成单个结果集。合并时两个表对应的列数和数据类型必须相同,并且相互对应,各个SELECT语句之间使用UNION或UNION ALL关键字分隔。
语法格式:
SELECT column,... FROM table1
UNION [ALL]
SELECT column,... FROM table2
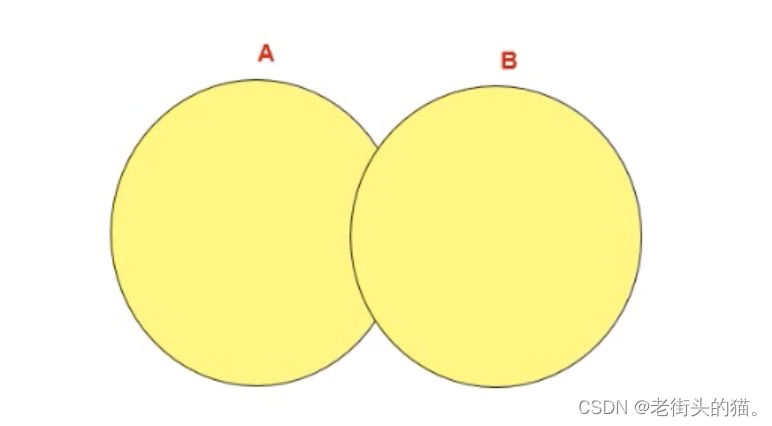
3.1.1 UNION操作符
UNION 操作符返回两个查询的结果集的并集,去除重复记录。
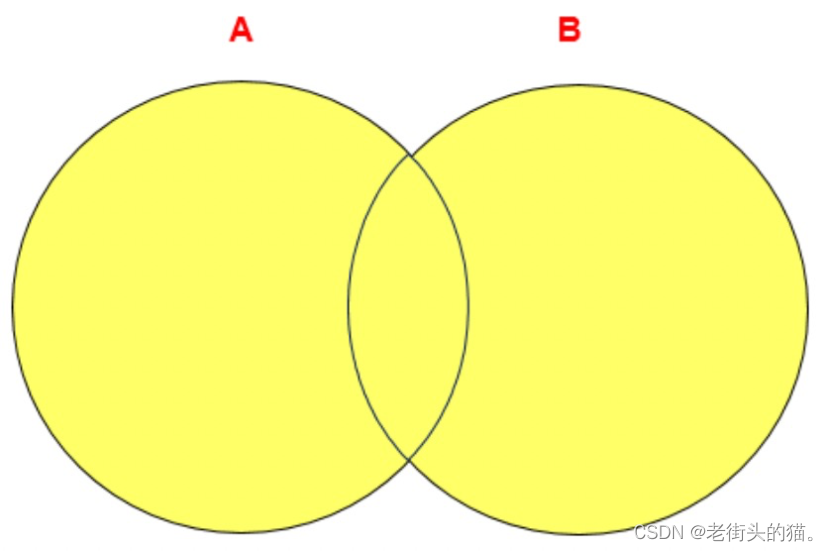
3.1.2 UNION ALL操作符
UNION ALL操作符返回两个查询的结果集的并集。对于两个结果集的重复部分,不去重。
select 'newMember' as "memberType",
count(distinct full_union_id) as "memberCount"
from XXX.XXX
where XX_id = cast(66666666 as varchar)
and XX_time >= '2021-06-16 00:00:00'
and XX_time <= '2022-06-16 00:00:00'
union all
select 'oldMember' as "memberType",
count(distinct full_union_id) as "memberCount"
from XXX.XXX
where XX_id = cast(66666666 as varchar)
and XX_time <'2021-06-16 00:00:00'
| memberType | memberCount |
|---|---|
| oldMember | 2,666,888 |
| newMember | 1,888,666 |
注意:执行UNION ALL语句时所需要的资源比UNION语句少。如果明确知道合并数据后的结果数据不存在重复数据,或者不需要去除重复的数据,则尽量使用UNION ALL语句,以提高数据查询的效率。
4. 7种JOIN操作
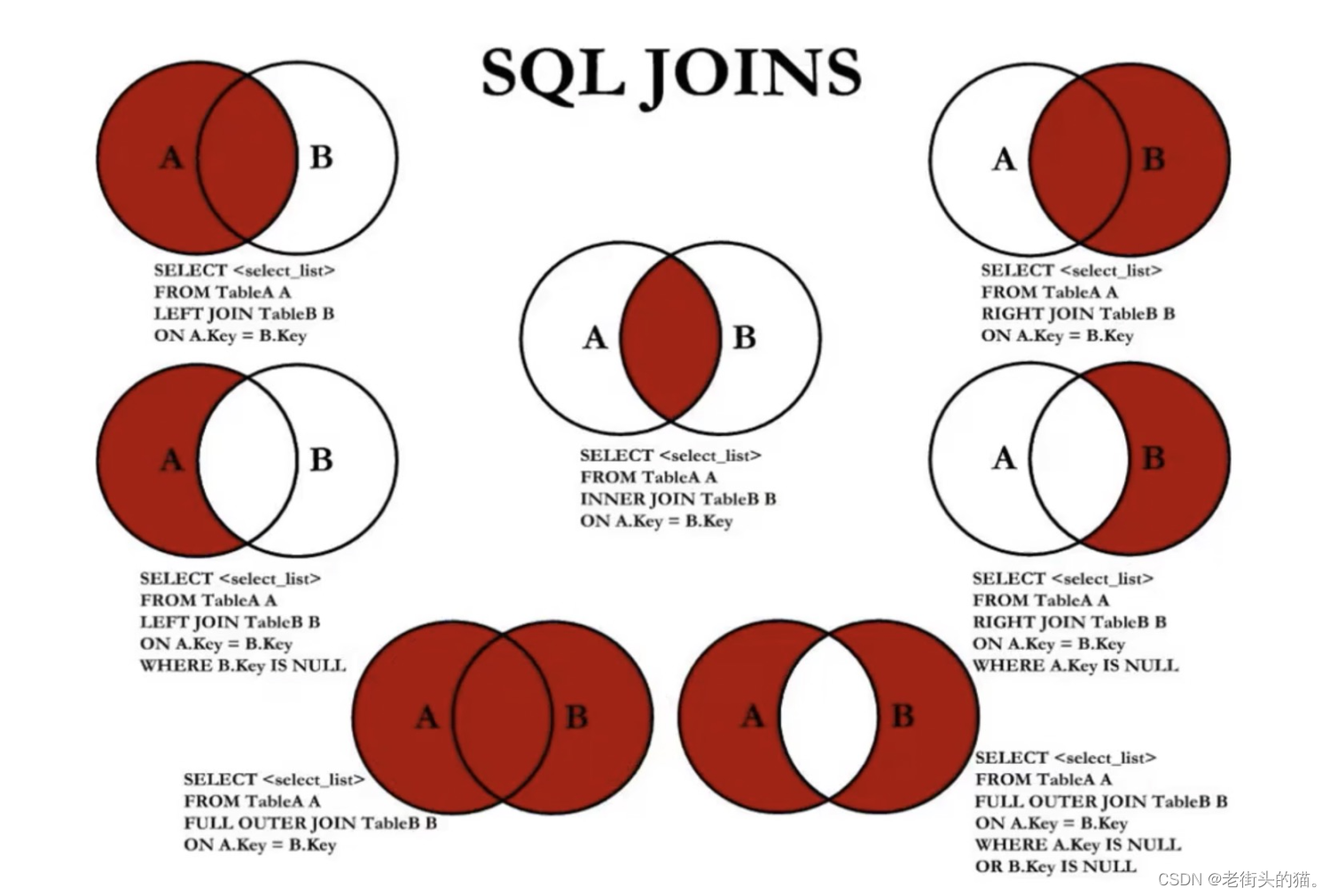
中图:内连接
SELECT employee_id, last_name, department_name
FROM employees e
JOIN departments d
ON e.department_id = d.department_id;
左上图:左外连接
SELECT employee_id, last_name, department_name
FROM employees e
LEFT JOIN departments d
ON e.department_id = d.department_id;
右上图:右外连接
SELECT employee_id,last_name,department_name
FROM employees e
RIGHT JOIN departments d
ON e.department_id = d.department_id;
左中图
SELECT employee_id, last_name, department_name
FROM employees e
LEFT JOIN departments d
ON e.department_id = d.department_id
WHERE d.department_id IS NULL;
右中图
SELECT employee_id, last_name, department_name
FROM employees e
RIGHT JOIN departments d
ON e.department_id = d.department_id
WHERE e.department_id IS NULL;
左下图: 左中图 + 右上图
SELECT employee_id,last_name,department_name
FROM employees e
LEFT JOIN departments d
ON e.department_id = d.department_id
WHERE d.department_id IS NULL
UNION ALL #没有去重操作,效率高
SELECT employee_id,last_name,department_name
FROM employees e
RIGHT JOIN departments d
ON e.department_id = d.department_id;
右下图:左中图 + 右中图
SELECT employee_id,last_name,department_name
FROM employees e
LEFT JOIN departments d
ON e.department_id = d.department_id
WHERE d.department_id IS NULL
UNION ALL
SELECT employee_id,last_name,department_name
FROM employees e
RIGHT JOIN departments d
ON e.department_id = d.department_id
WHERE e.department_id IS NULL
注意:
我们要控制连接表的数量。多表连接就相当于嵌套 for 循环一样,非常消耗资源,会让 SQL 查询性能下降得很严重,因此不要连接不必要的表。在许多 DBMS 中,也都会有最大连接表的限制。
【强制】超过三个表禁止 join。需要 join 的字段,数据类型保持绝对一致;多表关联查询时,保证被关联的字段需要有索引。
说明:即使双表 join 也要注意表索引、SQL 性能。
来源:阿里巴巴《Java开发手册》



![[python入门(51)] - python时间日期格式time和datetime](https://img-blog.csdnimg.cn/df610f8954064a3ba9a8ebace394bfed.png)