如果觉得我的分享有一定帮助,欢迎关注我的微信公众号 “码农的科研笔记”,了解更多我的算法和代码学习总结记录。或者点击链接扫码关注【2023/图对比/增强】MA-GCL: Model Augmentation Tricks for Graph Contrastive Learning
【2023/图对比/增强】MA-GCL: Model Augmentation Tricks for Graph Contrastive Learning
原文:https://arxiv.org/pdf/2212.07035.pdf
源码:https://paperswithcode.com/paper/ma-gcl-model-augmentation-tricks-for-graph#code
1 动机
图对比学习中,图增强可以获得图的不同视图,这在很多任务中被广泛运用,特别是在推荐系统、视觉任务。然而,在图中生成对比视图是一个非常有挑战的工作,因为我们没有太多的先验知识来指导我们如何增强图的同时保证labels的不变。典型的图增强方式,例如边的移除可以有效对抗噪声的影响,但是也存在不能生成足够的对比视图等问题。因此,本文提出了一种新的范式(MA-GCL),聚焦操作encoders的实现而不是其输入。具体来说,作者展示了三种简单的模型增强的技巧,分别是非对称,随机和洗牌策略。
2 方法
对比学习(Contrastive Learning)是一种无监督的表示学习方法,对比学习中InfoNCE是典型的损失函数,其通过增大正样本对之间的相似度和减少负样本对之间的相似度获得更好表征。本文以典型 GNN 作为 encoder 从而阐述对比学习中三种不同的模型增强技巧。
2.1【形式化GNN】
GNNs will stack multiple propagation layers and transformation layers, and then apply them to the raw features X. Here we denote the operators of propagation layer and the transformation layer as g and h.
本文以典型 GNN 作为 view encoder,但是作者使用了一种新的方式来形式化GNN。GNN可以形式化为传播和转换两个过程。在图神经网络(GNN)中,
- “propagation layer”(传播层)是用来传递节点信息的层,其输入是上一层节点的特征(也称为"embedding"),输出是每个节点的聚合邻居信息的向量。传播层的目的是将每个节点的邻居信息合并到节点特征中,以便更好地描述节点的属性和关系。
- 而"transformation layer"(转换层)则是对节点特征进行非线性变换的层。这些变换可以帮助学习到更丰富和复杂的节点特征,以提高图神经网络的性能。转换层通常由多个全连接层或卷积层组成,并使用激活函数(如ReLU)来增加网络的非线性能力。
当我们处理图数据时,通常将每个节点看作图的一个元素。例如,在社交网络中,每个节点可以表示一个人,每个边可以表示人与人之间的关系(如朋友关系、家庭关系等)。对于每个节点,我们都会有一些与之相关的特征,例如该人的年龄、性别、职业等等。我们可以将这些特征存储在一个特征向量中,例如X=[年龄,性别,职业]。在图神经网络中,我们的目标是通过这些特征来学习节点之间的关系,以便更好地了解整个图的结构和特征。
-
在这个例子中,我们可以将传播层看作是将每个节点的邻居信息合并到节点特征中的层。例如,我们可以定义传播函数为取邻居节点特征的均值,将其与节点自身特征连接起来,作为新的节点表示。这个新的节点表示将更好地描述节点的特征和邻居之间的关系。
-
对于转换层,我们可以将其看作是对节点特征进行非线性变换的层。例如,我们可以定义一个全连接层来将节点特征投影到一个高维空间中,并应用一个ReLU激活函数,以增加网络的非线性能力。这个变换可以帮助网络学习到更复杂的节点特征,以更好地描述节点之间的关系。
通过将多个传播层和转换层堆叠在一起,并将它们应用于原始特征X,我们可以构建一个强大的图神经网络,以更好地分析和理解图数据。
则利用 h 算子和 g 算子形式化了GCN和SGC两种常用的GNN encoders。
G
C
N
(
X
)
=
h
L
∘
g
∘
h
L
−
1
∘
g
∘
⋯
∘
h
1
∘
g
(
X
)
S
G
C
(
X
)
=
h
∘
g
[
L
]
(
X
)
\begin{array}{l} G C N(\boldsymbol{X})=h_{L} \circ g \circ h_{L-1} \circ g \circ \cdots \circ h_{1} \circ g(\boldsymbol{X}) \\ S G C(\boldsymbol{X})=h \circ g^{[L]}(\boldsymbol{X}) \end{array}
GCN(X)=hL∘g∘hL−1∘g∘⋯∘h1∘g(X)SGC(X)=h∘g[L](X)
GCN(Graph Convolutional Network)和SGC(Simplifying Graph Convolutional Networks)都是图神经网络中的经典模型,它们的主要区别在于它们的聚合函数不同。
-
GCN使用的聚合函数是基于邻居节点特征的加权平均,即将每个邻居节点的特征乘以一个可学习的权重,然后将所有乘积相加并除以邻居节点的数量。这个聚合函数能够考虑到节点的邻居特征,并将其合并到节点的特征表示中。
-
而SGC则采用一种更简单的聚合函数,即直接对节点的邻居特征取平均。与GCN不同的是,SGC中的聚合函数没有可学习的权重参数,因此模型更加简单和易于实现。虽然SGC的表现通常不如GCN,但在某些场景下,SGC的性能可能会更好。
2.2【非对称策略】
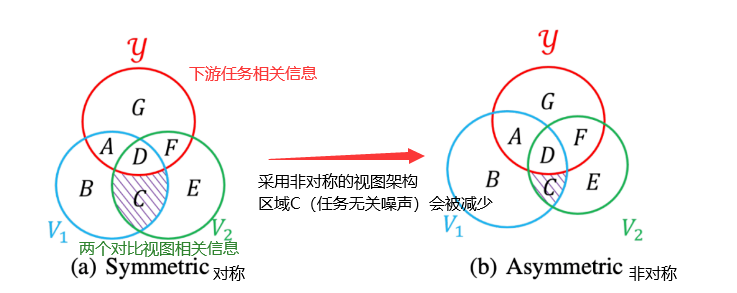
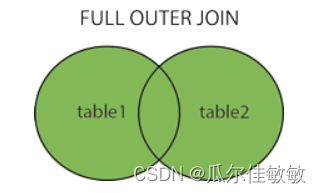
由以上韦恩图所示,红色的圈为与下游任务相关的信息,蓝色和绿色的圈则是对比学习生成的两个视图所包含的信息。当用对称的编码器时,在InfoNCE loss的作用下两个视图的互信息(区域C+D会被最大化),但是和任务相关的信息只有区域D,C也会变大是我们不想要的,而当我们采用非对称的视图架构时,如b所示区域C也就是和任务无关的噪声会被减少。
本文提出了一种不对称策略(asymmetric strategy),使用具有共享参数但不同传播层数的编码器可以减轻高频噪声。文章认为对比学习(contrastive learning)可以提取不同视角之间共享的信息,从而过滤出仅出现在单个视角的与任务无关的噪声。对称的 GCL 方法中的两个视角过于接近,无法生成足够多样的增强,并且两个视角的编码器具有完全相同的神经架构和绑定参数,这会加强视角之间的接近程度。为解决这个问题,文章提出了使用具有共享参数但不同传播层数的不对称视角编码器。这样一来,GCL 中的噪声可以减轻。
这个策略的核心是使用具有共享参数但不同传播层数的编码器,以减轻高频噪声的影响。假设我们有两个视图 V 1 V_1 V1 和 V 2 V_2 V2,并且它们的编码器共享参数,但传播层数不同。例如, V 1 V_1 V1 的编码器有两层传播,而 V 2 V_2 V2 的编码器有三层传播。这将使得两个视图在抽取任务相关信息的同时,保持一定的距离,从而避免了噪声的影响。简单来说,这个策略就是让编码器的不同视图在深度上有所差异,从而使得它们抽取的信息更加丰富和多样化,同时可以去除任务不相关的噪声。
2.3【随机策略】
这个方法是针对图神经网络中的编码器模块提出的。具体来说,该方法是在训练过程中随机改变编码器中传播操作符的数量,以增加训练样本的多样性。在文章中,作者以SGC(Simplifying Graph Convolutional Networks)编码器为例,该编码器采用了一种简单的聚合函数对节点的邻居特征进行平均汇聚。编码器的输入是节点的特征矩阵 X X X,经过多个传播操作符和转换操作符的堆叠,输出节点的特征表示 Z Z Z。
作者提出,在每个epoch中随机改变编码器中传播操作符的数量,而不是采用固定的数量。具体来说,他们在每个epoch中随机采样一个数量 L L L,用于构造 L L L 层的传播操作符。这样,就可以得到多个具有不同传播深度的编码器,从而扩大训练样本的多样性。通过这种方法,作者认为可以增加训练样本的多样性,从而提高模型的性能。实验结果也表明,这种方法可以在多个图神经网络模型中得到显著的性能提升。
假设我们有一个包含10个节点的图,并且我们想要使用SGC编码器来对这个图进行节点分类任务。传统的SGC编码器会使用固定的传播操作符数量(比如说L=2),然后通过多次迭代来训练模型。然而,使用固定的L值可能会导致过拟合,因为模型只能看到有限数量的计算树,而且这些计算树都是相对较浅的。现在,我们可以尝试使用本文提出的方法来改进模型的训练。具体来说,我们可以在每个epoch中随机改变传播操作符的数量,比如说在第一个epoch中使用L=2,而在第二个epoch中使用L=3,第三个epoch中使用L=1。这样做的好处是可以增加训练样本的多样性,因为每个传播操作符都对应着一个不同深度的计算树。
2.4【洗牌策略】
洗牌策略则是在训练过程中,随机打乱传播算子和转换算子的排列。通过混洗传播和转换操作的顺序,不会改变输入图形的语义,但会扰动编码表示,从而提供更安全的增强。洗牌策略是指在每次训练时对数据增广过程中的算子进行随机排列,以得到不同的数据增广视图,从而提高模型的鲁棒性和泛化能力。
下面以一个简单的图像分类任务为例子,假设有一个包含 100 张猫和 100 张狗的图像数据集。传统的数据增广方法可能会对图像进行翻转、旋转、裁剪等操作,但是这些操作可能会影响图像的语义信息,比如翻转可能会将狗的左右区分反过来,从而影响模型的分类能力。而采用洗牌策略,则可以在不改变图像的语义信息的前提下,通过对算子进行随机排列来得到不同的数据增广视图。例如,可以将每次训练时使用的卷积核和池化算子的顺序随机排列,从而得到不同的图像特征提取方式,提高模型的鲁棒性和泛化能力。
3 总结
作者从模型层面对view 进行增强。




![[python入门(51)] - python时间日期格式time和datetime](https://img-blog.csdnimg.cn/df610f8954064a3ba9a8ebace394bfed.png)