前言:CLIP工作拓展-利用文本-图像对的信息进行图像语义分割(CVPR2022)
论文:【here】
代码:【here】
GroupViT: Semantic Segmentation Emerges from Text Supervision
引言
传统分割方法采用自底而上的架构,深度学习方法是端到端的,自顶而下的为每个像素分配标签:
缺点有:标记数据繁琐,以及不能拓展到标签以外的类别
受到如今一些采用zero-shot方式取得成功方法的启发,这样可以针对下游任务微调模型,还可以拓展到没有出现过的类别
因此我们提出了一种方法,groupvit
方法
pipeline如下
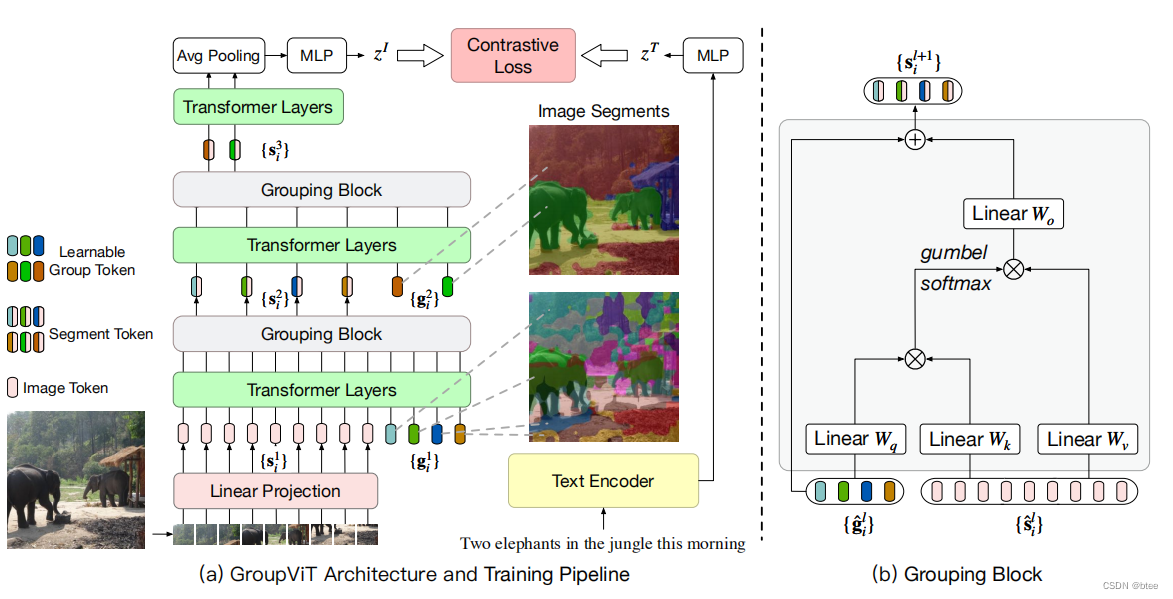
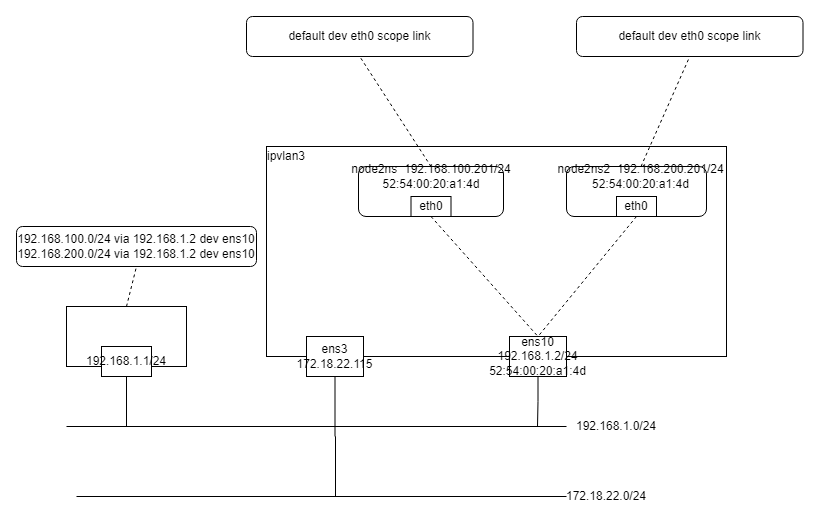
首先是将图像打成16 * 16的小patch一共196个patch送入网络,和vision transformer是一样的,但是加了64个可学习的patch与图像patch合并concat起来送入网络,然后进行transformer,过6层transformer后,进行group block
然后是group_block的设计
原本concat起来的两种patch,196 * 384图像patch 和64 * 384的类别patch进行transformer,通过一个attention 196 * 64 ,可以将原本的图像不同patch的信心合并到不同的类别patch中,因此就实现了group
gumble_softmax
这里引用了一个新的gumble_softmax[可以参考这篇知乎]
简而言之就是将前向推理中的权重变成了取最大值后onehot编码的0或1,后向传播则仍然采用softmax后的概率(不然没法求导),同时加上一个gumble分布,加上一个不确定的值稀释掉原有的概率比,模拟随机采用的过程
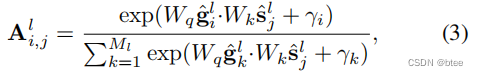
原文的解释为
where Wq and Wk are the weights of the learned linear projections for the group and segment tokens, respectively, and{γi} are i.i.d random samples drawn from the Gumbel(0,1) distribution. We compute the group to assign a segment token to by taking the one-hot operation of it argmax over all the groups. Since the one-hot assignment operation via argmax is not differentiable, we instead use the straight through trick in [60] to compute the assignment matrix as
With the straight through trick, ˆAl has the one-hot value of assignment to a single group, but its gradient is equal to the gradient of Al, which makes the Grouping Block differentiable and end-to-end trainable. We call this one-hot assignment strategy as hard assignment.

再过了group_BLock后,再叠了9层transformer,这次加了8个类别patch,将64个类别patch聚合成8个个大类别,然后也过了一个group_block,将64合并到8个patch上,最后将8 * C的向量进行 AVG——pooling,得到整张图片的特征
损失函数
作者利用了两种损失函数,图-文本对的对比损失,利用的文本来自与对整幅图像的解释(左下角第一行)
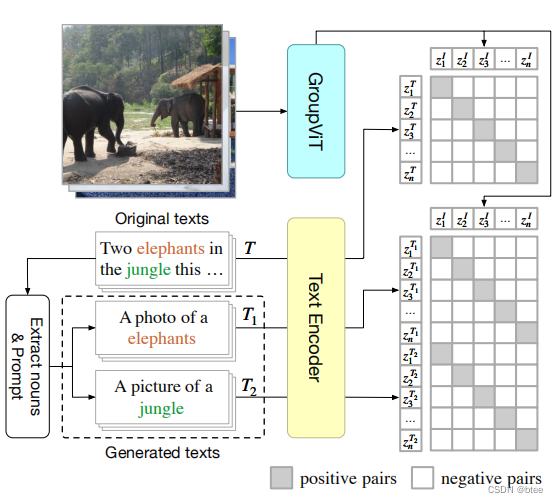
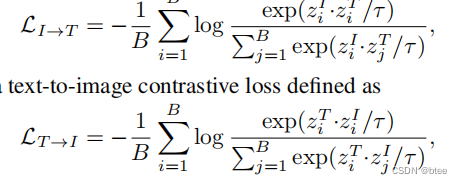
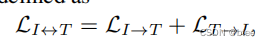
第二种的图-多文本对,来自数据集的分割标签,并把单词扩展成了一句话(来自图左下角第二三行)
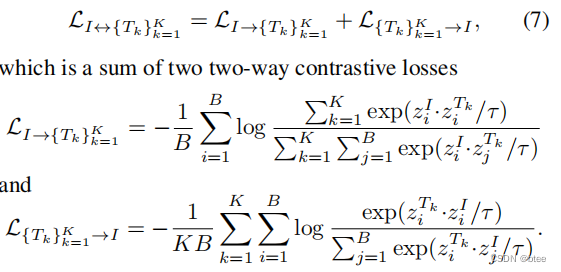
以上就是文章方法和设计部分的介绍了,这里沐神的课讲得很清楚,我也是看完他的视频过来的
补充一个文中没有提到的分割位置复原的过程,可以利用group_block中的attention图进行位置分割类别的像素位置复原,比如:第一层的attention为196 * 64
并用gumble_softmax,即最后得到一个onehot编码,实际上就是为这196个像素块分了64个类
可以将它可视化,文中的可视化结果如下

然后第二层的64 * 8的groupblock的attention也是同理,将64个类别分到了8个大类中,对应到上一层的64个小类,8个大类的可视化如下

最后一层进行与文本配对,将8个大类中与文本配对的类进行可视化则为

实验
消融实验
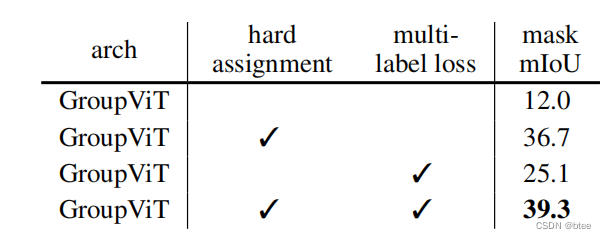
用hard assignament比soft assignment要提高很多,作者解释这是因为可以不用关注那些被hard assignamen附零的不相关区域
mutil-label loss也能提高性能
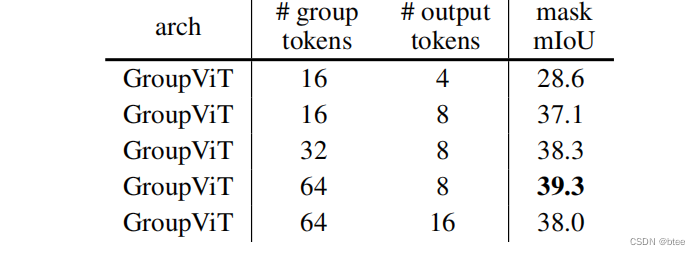
token数的选择
对比实验
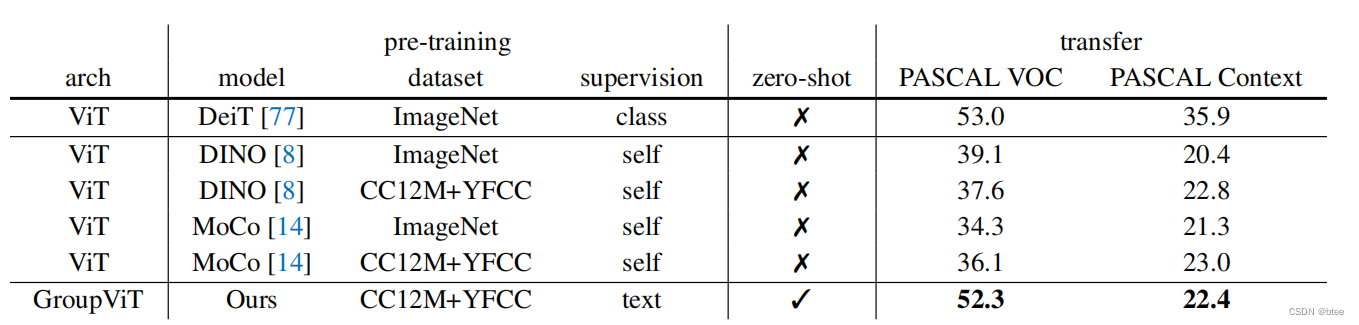
由于不是做分割任务的,对这些方法不是很了解,看表中的显示并没有跑过带标签数据的fine-tune模型,不过也很不错了
总结
看到沐神的视频里介绍用transformer利用可学习的token来给图像块分配标签,这个思路被惊艳到了,感觉特别巧妙,(当然我也不清楚这是不是分割任务中的常见手段)
最后的AVGpooling合并8个类别,感觉设计得不是特别好,将多个区域的特征杂糅到一起与多种的文本匹配,有种暴力训练的感觉,最后的mask 的分类效果也证明分类得不好,不知道作者今后会不会将这块设计改进以下,或者将训练集改进一下,一张图中只留一个分割对象








![【项目设计】高并发内存池(一)[项目介绍|内存池介绍|定长内存池的实现]](https://img-blog.csdnimg.cn/082dab52de4a46318aaf6171d621ac38.png)