1.3 业务需求
对广告数据进行初步ETL处理和业务报表统计分析,整体业务需求如下图所示:
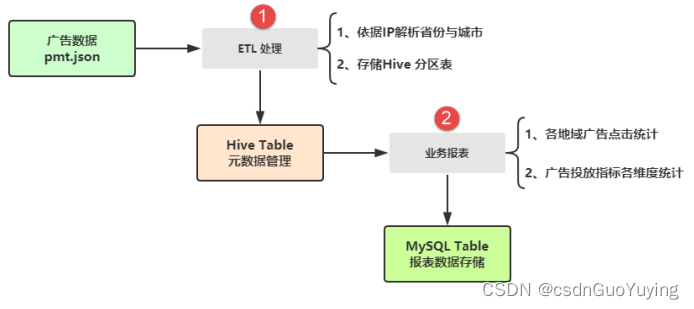
两个主要方面的业务:
第一个、数据【ETL 处理】
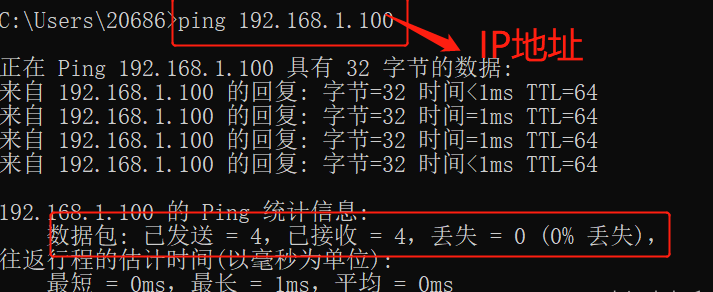
- 依据IP地址,调用第三方库解析为省份province和城市city;
- 将ETL后数据保存至PARQUET文件(分区)或Hive 分区表中;
第二个、数据【业务报表】
- 读取Hive Table中广告数据,按照业务报表需求统计分析,使用DSL编程或SQL编程;
- 将业务报表数据最终存储MySQL Table表中,便于前端展示;
上述两个业务功能的实现,使用SparkSQL进行完成,最终使用Oozie和Hue进行可视化操作调用程序ETL和Report自动执行。
1.4 环境搭建
整个综合实战主要结合广告业务数据及简单报表需求,熟悉SparkCore和SparkSQL如何进行离线数据处理分析,整合其他大数据框架综合应用,需要准备大数据环境及应用开发环境。
大数据环境
通过上述业务需求分析可知,涉及到如下软件安装,全部安装在一台虚拟机中,部署伪分布式环境,建议虚拟机内存大小至少为4GB。
1)、基础软件:jdk1.8.0_241、scala-2.12.10、MySQL-8.0.19
2)、大数据软件: hadoop-2.6.0-cdh5.16.2 、 hive-1.1.0-cdh5.16.2 、 spark-2.4.5-bin-cdh5.16.2-2.11 、oozie-4.1.0-cdh5.16.2、hue-3.9.0-cdh5.16.2
针对此离线综合实战来说,大数据环境已经部署完成,打开虚拟机【spark-node01】,进入快照管理,选择恢复至【7、Spark 离线综合实战】即可。
启动各个框架服务命令如下,开发程序代码时为本地模式LocalMode运行,测试生产部署为YARN集群模式运行,集成Hive用于进行表的元数据管理,使用Oozie和Hue调度执行程序:
# Start HDFS
hadoop-daemon.sh start namenode
hadoop-daemon.sh start datanode
# Start YARN
yarn-daemon.sh start resourcemanager
yarn-daemon.sh start nodemanager
# Start MRHistoryServer
mr-jobhistory-daemon.sh start historyserver
# Start Spark HistoryServer
/export/server/spark/sbin/start-history-server.sh
# Start Oozie和Hue
oozied.sh start
hue-daemon.sh start
# Start HiveMetaStore 和 HiveServer2
hive-daemon.sh metastore
# Start Spark JDBC/ODBC ThriftServer
/export/server/spark/sbin/start-thriftserver.sh \
--hiveconf hive.server2.thrift.port=10000 \
--hiveconf hive.server2.thrift.bind.host=node1.itcast.cn \
--master local[2]
# Start Beeline
/export/server/spark/bin/beeline -u jdbc:hive2://node1.itcast.cn:10000 -n root -p 123456
启动SparkSQL JDBC/ODBC ThriftServer 分布式SQL引擎,使用beeline命令行客户端连接(也可以使用其他可视化工具连接),方便对Hive表数据管理及开发测试。
应用开发环境
在前面创建Maven Project工程,创建Maven Module模块,pom.xml文件中添加相关依赖:
<repositories>
<repository>
<id>aliyun</id>
<url>http://maven.aliyun.com/nexus/content/groups/public/</url>
</repository>
<repository>
<id>cloudera</id>
<url>https://repository.cloudera.com/artifactory/cloudera-repos/</url>
</repository>
<repository>
<id>jboss</id>
<url>http://repository.jboss.com/nexus/content/groups/public</url>
</repository>
</repositories>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<scala.version>2.11.12</scala.version>
<scala.binary.version>2.11</scala.binary.version>
<spark.version>2.4.5</spark.version>
<hadoop.version>2.6.0-cdh5.16.2</hadoop.version>
<mysql.version>8.0.19</mysql.version>
</properties>
<dependencies>
<!-- 依赖Scala语言 -->
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-library</artifactId>
<version>${scala.version}</version>
</dependency>
<!-- Spark Core 依赖 -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_${scala.binary.version}</artifactId>
<version>${spark.version}</version>
</dependency>
<!-- Spark SQL 依赖 -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_${scala.binary.version}</artifactId>
<version>${spark.version}</version>
</dependency>
<!-- Spark SQL 与 Hive 集成 依赖 -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-hive_${scala.binary.version}</artifactId>
<version>${spark.version}</version>
</dependency>
<!-- Hadoop Client 依赖 -->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>${hadoop.version}</version>
</dependency>
<!-- MySQL Client 依赖 -->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>${mysql.version}</version>
</dependency>
<!-- 根据ip转换为省市区 -->
<dependency>
<groupId>org.lionsoul</groupId>
<artifactId>ip2region</artifactId>
<version>1.7.2</version>
</dependency>
<!-- 管理配置文件 -->
<dependency>
<groupId>com.typesafe</groupId>
<artifactId>config</artifactId>
<version>1.2.1</version>
</dependency>
<dependency>
<groupId>com.squareup.okhttp3</groupId>
<artifactId>okhttp</artifactId>
<version>3.14.2</version>
</dependency>
</dependencies>
<build>
<outputDirectory>target/classes</outputDirectory>
<testOutputDirectory>target/test-classes</testOutputDirectory>
<resources>
<resource>
<directory>${project.basedir}/src/main/resources</directory>
</resource>
</resources>
<!-- Maven 编译的插件 -->
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.0</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
<encoding>UTF-8</encoding>
</configuration>
</plugin>
<plugin>
<groupId>net.alchim31.maven</groupId>
<artifactId>scala-maven-plugin</artifactId>
<version>3.2.0</version>
<executions>
<execution>
<goals>
<goal>compile</goal>
<goal>testCompile</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
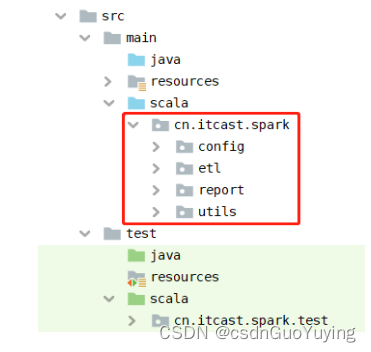
按照应用开发分层结构,需要在src源码目录下创建相关目录和包,具体如下:
在使用IDEA开发应用时,建议从本地文件系统LocalFS加载数据和应用运行在本地模式LocalMode,开发完成以后测试时从HDFS加载数据和应用运行YARN集群,所以需要通过属性配置文件:【config.properties】,控制应用程序数据加载与运行模式。
1.5 项目初始化
如上述业务分析所示,构建Spark应用的项目,首先需要考虑两个方面初始化:
第一个方面、构建SparkSession实例对象,数据加载、运行模式及集成Hive;
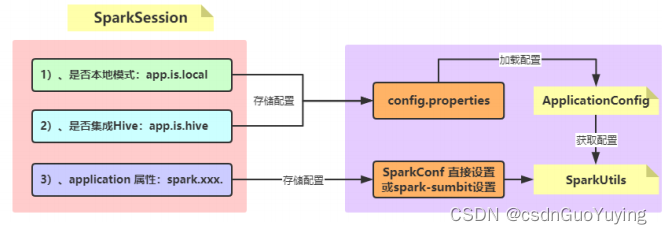
第二个方面、属性配置文件,存储应用中相关配置,方便开发、测试及生产环境修改;
接下来首先加载获取属性文件中属性值,再构建SparkSession实例对象,为后续业务开发做好基础。
加载属性文件
对于一个完整的工程来说,如果所有的配置都指定到代码里,就会造成:

综上所述,需要一个配置文件工具类,来专门获取配置文件的内容。Typesafe的Config库,纯Java写成、零外部依赖、代码精简、功能灵活、API友好。支持Java properties、JSON、JSON超集格式以及环境变量,它也是Akka的配置管理库。默认加载classpath下的application.conf,application.json和application.properties文件,通过ConfigFactory.load()加载,也可指定文件地址,添加Maven依赖至pom.xml文件:
<!-- 管理配置文件 -->
<dependency>
<groupId>com.typesafe</groupId>
<artifactId>config</artifactId>
<version>1.2.1</version>
</dependency>
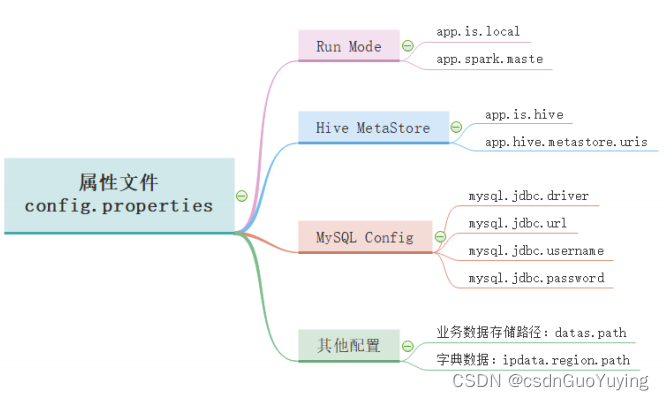
属性配置文件【config.properties】内容如下:
# local mode
app.is.local=true
app.spark.master=local[4]
## Hive MetaStore
app.is.hive=true
app.hive.metastore.uris=thrift://node1.itcast.cn:9083
# mysql config
mysql.jdbc.driver=com.mysql.cj.jdbc.Driver
mysql.jdbc.url=jdbc:mysql://node1.itcast.cn:3306/?serverTimezone=UTC&characterEncoding=utf8&useUnicod
e=true
mysql.jdbc.username=root
mysql.jdbc.password=123456
# 广告业务数据存储路径
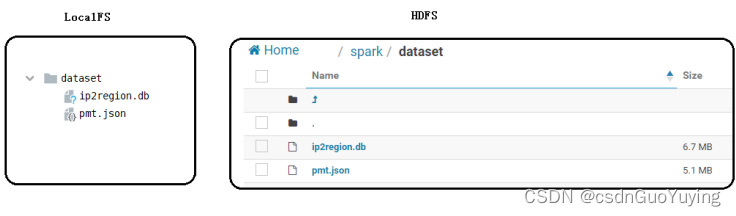
datas.path=dataset/pmt.json
##datas.path=hdfs://node1.itcast.cn:8020/spark/dataset/pmt.json
# 字典数据
ipdata.region.path=dataset/ip2region.db
##ipdata.region.path=hdfs://node1.itcast.cn:8020/spark/dataset/ip2region.db
其中应用开发本地模式运行时,从本地文件系统【当前工程目录下dataset】加载数据,测试生产时从HDFS文件系统【/spark/dataset】加载数据。
编写加载属性文件工具类:ApplicationConfig,位于【cn.itcast.spark.config】包,具体代码如下:
package cn.itcast.spark.config
import com.typesafe.config.{Config, ConfigFactory}
/**
* 加载应用Application属性配置文件config.properties获取属性值
*/
object ApplicationConfig {
// 加载属性文件
private val config: Config = ConfigFactory.load("config.properties")
/*
运行模式,开发测试为本地模式,测试生产通过--master传递
*/
lazy val APP_LOCAL_MODE: Boolean = config.getBoolean("app.is.local")
lazy val APP_SPARK_MASTER: String = config.getString("app.spark.master")
/*
是否集成Hive及Hive MetaStore地址信息
*/
lazy val APP_IS_HIVE: Boolean = config.getBoolean("app.is.hive")
lazy val APP_HIVE_META_STORE_URLS: String = config.getString("app.hive.metastore.uris")
/*
数据库连接四要素信息
*/
lazy val MYSQL_JDBC_DRIVER: String = config.getString("mysql.jdbc.driver")
lazy val MYSQL_JDBC_URL: String = config.getString("mysql.jdbc.url")
lazy val MYSQL_JDBC_USERNAME: String = config.getString("mysql.jdbc.username")
lazy val MYSQL_JDBC_PASSWORD: String = config.getString("mysql.jdbc.password")
// 数据文件存储路径
lazy val DATAS_PATH: String = config.getString("datas.path")
// 解析IP地址字典数据文件存储路径
lazy val IPS_DATA_REGION_PATH: String = config.getString("ipdata.region.path")
}
每个属性变量前使用lazy,当第一次使用变量时,才会进行初始化。