Java8引入了@Contented这个新的注解来减少伪共享(False Sharing)的发生。
@sun.misc.Contended注解是被设计用来解决伪共享问题的
文章目录
- 1.缓存行
- 2.伪共享(False Sharing)
- 2.1 CPU的缓存机制
- 3.填充(Padding)
- 4.@Contended方式
- 4.总结
1.缓存行
CPU读取内存数据时并非一次只读一个字节,而是会读一段64字节长度的连续的内存块(chunks of memory),这些块我们称之为缓存行(Cache line)。
假设你有两个线程(Thread1和Thread2)都会修改同一个volatile变量x:

如果Thread1先改变x的值,然后Thread2又去读它:

那么x所在缓存行上的所有64个字节的值都要被重新加载,因为CPU核心间交换数据是以缓存行为最小单位的。当然Thread1和Thread2是有可能在同一个核心上运行的,但我们此处假设两个线程在不同的核心上运行。
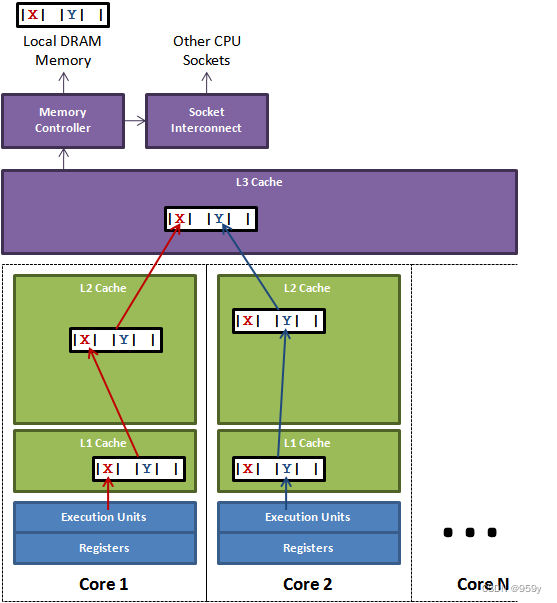
已知long类型占8个字节,缓存行长度为64个字节,那么一个缓存行可以保存8个long型变量,我们已经有了一个long型的x,假设x所在缓存行里还有其他7个long型变量,v1到v7:

缓存行:
2.伪共享(False Sharing)
这个缓存行可以被许多线程访问。如果其中一个修改了v2,那么会导致Thread1和Thread2都会重新加载整个缓存行。你可能会疑惑为什么修改了v2会导致Thread1和Thread2重新加载该缓存行,毕竟只是修改了v2的值啊。虽然说这些修改逻辑上是互相独立的,但同一缓存行上的数据是统一维护的,一致性的粒度并非体现在单个元素上。这种不必要的数据共享就称之为“伪共享”(False Sharing)。
2.1 CPU的缓存机制
学过计算机的人都知道,CPU是计算机的大脑,所有的程序,最终都要变成CPU指令在CPU中去执行。CPU的计算速度是非常快的,但是,我们知道,程序必须存储在存储介质中,程序启动之后被加载到内存中才能执行。但是内存的读取速度和CPU的计算速度之间存在非常大的差异。那么为了解决这个计算速度之间的差异,就在CPU上增加了缓存来解决这个问题。通常情况下,CPU是三级缓存结构
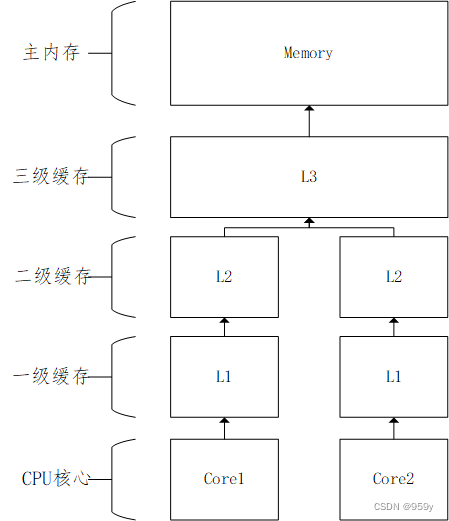
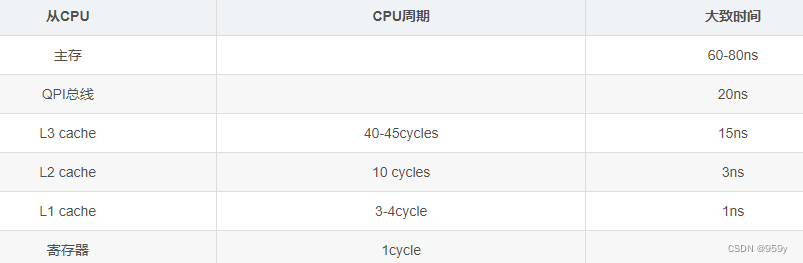
越靠近CPU的缓存,其容量就越小,但是其速度就越快。所以实际上L1的容量是最小的,这取决于CPU的具型号。
当CPU在执行计算的时候,先去L1查找数据,然后再去L2、L3,如果都没有数据则需要到主存中去加载。走得越远运算耗费的时间就越长。所以,对于一些高CPU的计算,尽量确保数据都能在L1中,降低加载次数。
3.填充(Padding)
一个CPU核心在加载一个缓存行时要执行上百条指令。如果一个核心要等待另外一个核心来重新加载缓存行,那么他就必须等在那里,称之为stall(停止运转)。减少伪共享也就意味着减少了stall的发生,其中一个手段就是通过填充(Padding)数据的形式,来保证本应有可能位于同一个缓存行的两个变量,在被多线程访问时必定位于不同的缓存行。
我们定义两个变量,分别在两个线程中各自增加到10亿次
不做处理
public class FalseSharingTest {
public static void main(String[] args) throws InterruptedException {
testPointer(new Pointer());
}
private static void testPointer(Pointer pointer) throws InterruptedException{
long start = System.currentTimeMillis();
Thread t1 = new Thread(() -> {
for(int i=0;i<1000000000;i++){
pointer.x++;
}
});
Thread t2 = new Thread(() -> {
for(int i=0;i<1000000000;i++){
pointer.y++;
}
});
t1.start();
t2.start();
t1.join();
t2.join();
System.out.println("cost ["+(System.currentTimeMillis()-start)+"] ms");
System.out.println(pointer);
}
static class Pointer{
volatile long x;
volatile long y;
@Override
public String toString() {
return "Pointer{" +
"x=" + x +
", y=" + y +
'}';
}
}
}
cost [35885] ms
Pointer{x=1000000000, y=1000000000}
采用填充的方式
public class FalseSharingTest {
public static void main(String[] args) throws InterruptedException {
testPointer(new Pointer());
}
private static void testPointer(Pointer pointer) throws InterruptedException{
long start = System.currentTimeMillis();
Thread t1 = new Thread(() -> {
for(int i=0;i<1000000000;i++){
pointer.x++;
}
});
Thread t2 = new Thread(() -> {
for(int i=0;i<1000000000;i++){
pointer.y++;
}
});
t1.start();
t2.start();
t1.join();
t2.join();
System.out.println("cost ["+(System.currentTimeMillis()-start)+"] ms");
System.out.println(pointer);
}
static class Pointer{
volatile long x;
long p1, p2, p3, p4, p5, p6, p7;
volatile long y;
@Override
public String toString() {
return "Pointer{" +
"x=" + x +
", y=" + y +
'}';
}
}
}
cost [5218] ms
Pointer{x=1000000000, y=1000000000}
性能有了大幅提升
4.@Contended方式
除了对字段进行填充之外,还有一个比较清爽的方法,那就是对需要避免陷入伪共享的字段进行注解,这个注解暗示JVM应当将字段放入不同的缓存行。通过@Contended
public class FalseSharingTest {
//-XX:-RestrictContended
public static void main(String[] args) throws InterruptedException {
testPointer(new Pointer());
}
private static void testPointer(Pointer pointer) throws InterruptedException{
long start = System.currentTimeMillis();
Thread t1 = new Thread(() -> {
for(int i=0;i<1000000000;i++){
pointer.x++;
}
});
Thread t2 = new Thread(() -> {
for(int i=0;i<1000000000;i++){
pointer.y++;
}
});
t1.start();
t2.start();
t1.join();
t2.join();
System.out.println("cost ["+(System.currentTimeMillis()-start)+"] ms");
System.out.println(pointer);
}
static class Pointer{
@sun.misc.Contended
volatile long x;
@sun.misc.Contended
volatile long y;
@Override
public String toString() {
return "Pointer{" +
"x=" + x +
", y=" + y +
'}';
}
}
}
@Contented注解将x和y移动到远离对象头部的地方
cost [5230] ms
Pointer{x=1000000000, y=1000000000}
4.总结
jdk7之前是填充方式, 本质是一种空间换时间的做法。
@sun.misc.Contended注解, 通过原理对象头的方式实现达到填充方式的效果。
也是ConcurrentHashMap中为了性能提升所采取的一个优化措施。自然,这个注解会因为添加了一些无用的变量而带来了内存的浪费。