第十一章 - 模糊匹配(like)、正则匹配(REGEXP)、文本处理函数、时间处理函数
- 模糊匹配和正则匹配
- like
- `%`通配符
- `_`通配符
- REGEXP 正则匹配
- 文本拼接
- concat()
- substring()
- substring_index()
- 一些文本处理函数
- 时间处理函数
- from_unixtime()
- adddate(日期,增加天数) 增加日期
- datediff() 两个日期相差的天数
- curdate() 获取当前日期
- dayofweek()
- year() 获取日期中的年分
- month() 获取日期中的月份
- day() 获取日期中的天
- hour() 获取时间中的小时数
- 偏移函数 lead() & lag()
模糊匹配和正则匹配
如何通过关键字来搜索出需要的数据来。用简单的比较操作或者用where来筛选是不行的。下面介绍两种匹配方法。
like
可以通过like操作符来使用通配符操作,从而实现模糊匹配的效果。
使用注意:
1.通配符搜索处理的时间要比一般搜索的时间要长。
2.如果其他操作符能达到相同的效果,应该使用其他操作符。
3.在需要使用通配符时,非必须的情况下,不要把他们用在搜索的开始处。
4.要注意通配符的位置,如果位置放错,返回的数据就不一定准确。
%通配符
%表示任何字符出现任意次数
%通配符是最经常使用的。
%在字符的右边如:ka%表示匹配所有以结尾的数据
%在字符的左边如:%ka表示匹配所有以结尾的数据
%在字符的两边如:%ka%表示匹配所有包含ka字符的数据
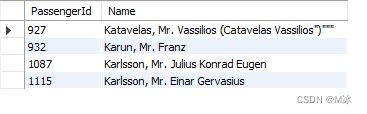
举个例子:找出以Ka开头的名字
select
PassengerId,
Name
from
test.titanic
where
Name like "ka%"
输出结果:
举个例子:找出所有包含Miss的名字
select
PassengerId,
Name
from
test.titanic
where
name like '%Miss%'
输出结果:
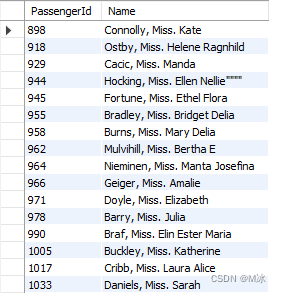
所有name列中包含Miss的数据
_通配符
_表示任何字符出现任意次数
_通配符是最经常使用的。
_在字符的右边如:ka_表示匹配所有以ka开头的三位字符
_在字符的左边如:_ka表示匹配所有以ka结尾的三位字符
_在字符的两边如:9_1表示匹配所有以9开头以1结尾的三位字符
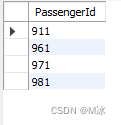
举个例子: 找出所有以9开始以1结尾的三位数的用户ID
select
PassengerId
from
test.titanic
where
PassengerId like '9_1'
输出结果:
REGEXP 正则匹配
正则表达式是用来匹配搜索文本的强大的工具,能够实现比like更复杂的文本匹配。比如需要匹配邮箱格式的数据,需要匹配电话号码,或者是匹配一个网址的链接等,都可以用正则表达式来实现。
下面通过几个案例来介绍MySQL中的正则匹配的用法:
举个例子:找出所有以M开头的人名
select
*
from
test.titanic
where
Name regexp '^M'
输出结果:
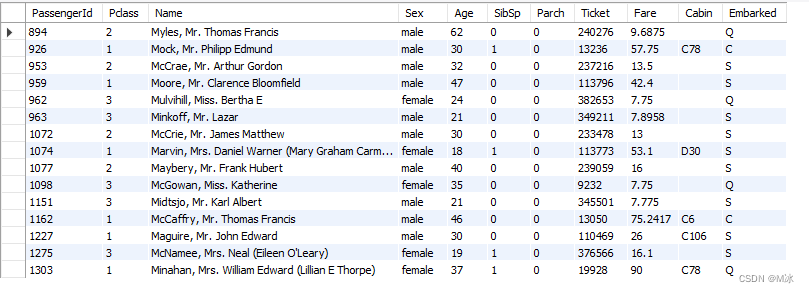
举个例子:找出年龄为40岁或者50岁的数据
select
*
from
test.titanic
where
age regexp '40|50'

举个例子:只匹配age年龄中有小数的数据
select
age
from
test.titanic
where
# '^[0-9]*\\.'表示所有以数字开始的,且包含.的字符。
age regexp '^[0-9]*\\.'
输出结果:

正则匹配中一些常用的匹配字符:
|表示或的意思,使用效果同 or
^文本开始
$文本结尾
.匹配任意一个字符
*0个或多个匹配
?0个或1个匹配,等同于{0,1}
+1个或多个匹配,等同于{1,}
{n}指定数目的匹配
{n,}不少于指定数目的匹配
{n,m}匹配数目的范围 m不超过255
[0-9]匹配任意数字
[A-Z]匹配任意大写字母
[a-z]匹配任意小写字母
[a-zA-Z]匹配任意字母
[a-zA-Z0-9]皮皮任意字母和数字
文本拼接
concat()
在数据查询时,如果想把两个字段内的信息拼接为一个新的字段,这时候可以通过使用concat()来实现文本的拼接功能。
举个例子:把两列的数据合并为一个新的列
使用concat()函数,以逗号为分割符,把sex和age的数据拼接为新的一列数据sex&age
select
select
sex,
age,
concat(sex,',',age) as 'sex&age'
from
test.titanic
输出结果:
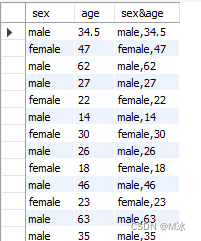
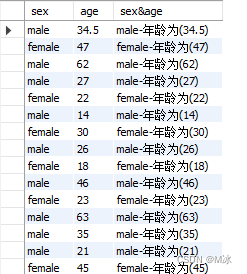
concat()中可以用多个逗号,自定义设置不同的拼接样式。如下面所示:
select
sex,
age,
concat(sex,'-年龄为','(',age,')') as 'sex&age'
from
test.titanic
输出结果:
substring()
在SQL中不光能实现数据的拼接,还可以实现数据的截取。
substring()是可以通过设置实现从指定的位置截取指定位数的数据。
substring(字段名称,起始位数,截取位数)
举个例子:有时候会需要把日期和时间区分开如2014/9/18 15:03这种样式,当我们只需要其中的年月日的时候该如何提取?
通过观察2014/9/18 15:03数据可以看出,获取年月日的信息只需要提取前面9位字符就够了
可以通过substring()来截取需要的日期,下面例子表示截取vtime字段中,从第一位开始,截取前9位数字
select
vtime,
# 截取vtime字段,从第1个字符开始,截取9位字符。
substring(vtime,1,9) as '日期'
from
rectmall.log
输出结果:
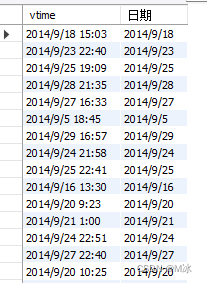
substring_index()
前面截取的是日期格式,字符的位置是一致的,可以通过固定的位数进行截取。但是当我们遇到字符长短不一样的时候该怎么提取呢,如下面这样字段中包含多个信息,但是只需要提取前面的名字:
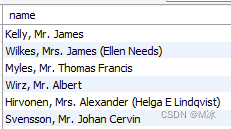
这个时候就不能用固定位数的方式来提取了,可以通过关键字来提取。
substring_index(字段名称,关键字,出现次数)
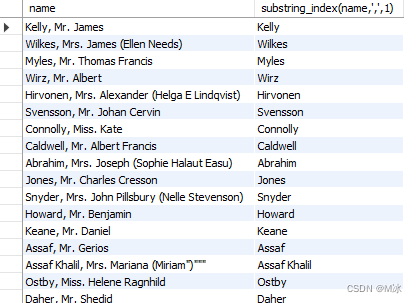
举个例子:
select
name,
# 当关键字 , 出现第一次的时候,截取前面的数据。如果写位-1就是截取关键字后面的数据
substring_index(name,',',1)
from
test.titanic
输出结果:
一些文本处理函数
upper() 将字符转换位大写
left() 截取左边的字符
lenght() 返回字符的长度
lower()将字符转换为小写
ltrim() 去除左边的空格
right()截取右边的字符
rtrim()去除右边的空格
时间处理函数
from_unixtime()
把 UNIX 时间戳转换为普通格式的日期时间值。在查询数据时,会遇到时间戳格式的时间,这时候就需要把时间戳转换为需要的日期。
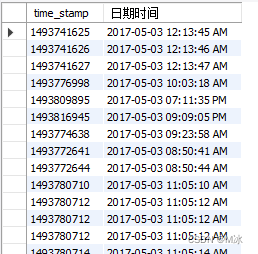
举个例子:
select
time_stamp,
# '%Y-%m-%d %r'可以根据需要自己选择需要获取的时间,下面有不同的表示代码
from_unixtime(time_stamp, '%Y-%m-%d %r' ) as "日期时间"
from
behavior_log
转换的日期格式代码
%M 月名字(January……December)
%W 星期名字(Sunday……Saturday)
%Y 年, 数字, 4 位 %y 年, 数字, 2 位
%d 月份中的天数, 数字(00……31)
%m 月, 数字(01……12)
%c 月, 数字(1……12)
%b 缩写的月份名字(Jan……Dec)
%j 一年中的天数(001……366)
%H 小时(00……23)
%h 小时(01……12)
%I 小时(01……12)
%l 小时(1……12)
%r 时间,12 小时(hh:mm:ss [AP]M)
%S 秒(00……59)
%s 秒(00……59)
%p AM或PM
%U 星期(0……52), 这里星期天是星期的第一天
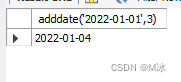
adddate(日期,增加天数) 增加日期
select
adddate('2022-01-01',3)
输出结果:
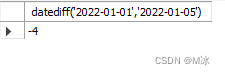
datediff() 两个日期相差的天数
datediff(日期1,日期2) #结果为 日期1 - 日期2 的天数
select
datediff('2022-01-01','2022-01-05')
输出结果:
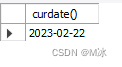
curdate() 获取当前日期
直接获取当天的日期。
select
curdate()
输出结果:
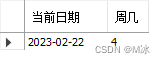
dayofweek()
输入日期,返回日期是周几。默认1为周日,2为周一
select
curdate() as '当前日期',
dayofweek(curdate()) as '周几'
输出结果:
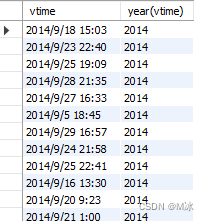
year() 获取日期中的年分
select
vtime,
year(vtime)
from
rectmall.log
输出结果:
month() 获取日期中的月份
select
vtime,
month(vtime)
from
rectmall.log
输出结果:
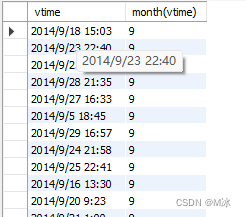
day() 获取日期中的天
select
vtime,
day(vtime)
from
rectmall.log
输出结果:
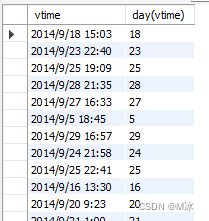
hour() 获取时间中的小时数
select
vtime,
hour(vtime)
from
rectmall.log
输出结果:
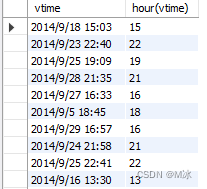
偏移函数 lead() & lag()
lead()是 把指定列的数据向上移动指定行数,空出来的行用null填充。
lag()是 把指定列的数据向下移动指定行数,空出来的行用null填充。
lead()和lag()的参数设置是一样的,只是移动的方向不一样。
举个例子:把action列的数据向上移动两行。
在over()中不设置参数,可实现使整列数据偏移指定的行数。
select
action,
lead(action,2) over()
from
rectmall.log
输出结果:
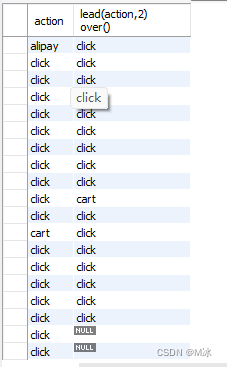
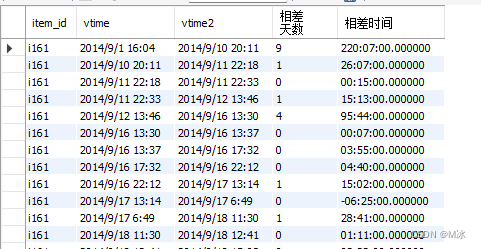
举个例子:计算商品id为i161 的商品,两次点击之间的间隔时间。
步骤:
- 新建一列时间数据,把
vitme的时间全部向上移动一行,实现,实现前后点击时间在同一行中,方便后续计算 - 在前面建立的查询结果上,在通过
datediff()进行日期的计算,或者timediff()时间的计算 - 得出相差的天数(
相差天数),或者相差的小时数(相差时间)
当在over()中指定参数是,可以实现窗口函数的控制效果。
select
*,
datediff(vtime2,vtime) as '相差天数',
timediff(vtime2,vtime) as '相差时间'
from
(select
item_id,
vtime,
lead(vtime,1) over(partition by item_id order by vtime) as vtime2
from
rectmall.log
where
item_id = 'i161') as temp
输出结果: