目录
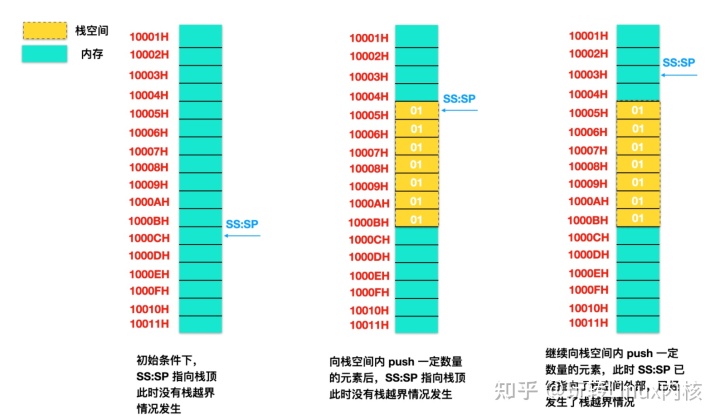
分桶(Bucket)
设定属性
定义分桶
案例
建表语句
表数据
上传到数据
创建分桶语句
加载数据
分桶抽样(Sampling)
随机抽样---整行数据
随机抽样---指定列
随机抽样---百分比
随机抽样---抽取行数
Hive视图(View)
视图概述
应用场景
创建视图
查看视图定义
删除视图
更改视图属性
更改视图定义
Hive侧视图(Lateral View)
分桶(Bucket)
分桶对应于HDFS中的文件
- 更高的查询处理效率
- 使抽样(sampling)更高效
- 一般根据"桶列"的哈希函数将数据进行分桶
设定属性
SET hive.enforce.bucketing = true;
定义分桶
clustered by(employee) into 2 buckets
分桶只有动态分桶
必须使用INSERT方式加载数据
案例
建表语句
create table employee_id
(
name string,
employee_id int,
work_place array<string>,
gender_age struct<gender:string,age:int>,
skills_score map<string,int>,
depart_title map<string,array<string>>
)
row format delimited
fields terminated by '|'
collection items terminated by ','
map keys terminated by ':'
lines terminated by '\n';表数据
Michael|100|Montreal,Toronto|Male,30|DB:80|Product:DeveloperLead
Will|101|Montreal|Male,35|Perl:85|Product:Lead,Test:Lead
Steven|102|New York|Female,27|Python:80|Test:Lead,COE:Architect
Lucy|103|Vancouver|Female,57|Sales:89,HR:94|Sales:Lead
Mike|104|Montreal|Male,35|Perl:85|Product:Lead,Test:Lead
Shelley|105|New York|Female,27|Python:80|Test:Lead,COE:Architect
Luly|106|Vancouver|Female,57|Sales:89,HR:94|Sales:Lead
Lily|107|Montreal|Male,35|Perl:85|Product:Lead,Test:Lead
Shell|108|New York|Female,27|Python:80|Test:Lead,COE:Architect
Mich|109|Vancouver|Female,57|Sales:89,HR:94|Sales:Lead
Dayong|110|Montreal|Male,35|Perl:85|Product:Lead,Test:Lead
Sara|111|New York|Female,27|Python:80|Test:Lead,COE:Architect
Roman|112|Vancouver|Female,57|Sales:89,HR:94|Sales:Lead
Christine|113|Montreal|Male,35|Perl:85|Product:Lead,Test:Lead
Eman|114|New York|Female,27|Python:80|Test:Lead,COE:Architect
Alex|115|Vancouver|Female,57|Sales:89,HR:94|Sales:Lead
Alan|116|Montreal|Male,35|Perl:85|Product:Lead,Test:Lead
Andy|117|New York|Female,27|Python:80|Test:Lead,COE:Architect
Ryan|118|Vancouver|Female,57|Sales:89,HR:94|Sales:Lead
Rome|119|Montreal|Male,35|Perl:85|Product:Lead,Test:Lead
Lym|120|New York|Female,27|Python:80|Test:Lead,COE:Architect
Linm|121|Vancouver|Female,57|Sales:89,HR:94|Sales:Lead
Dach|122|Montreal|Male,35|Perl:85|Product:Lead,Test:Lead
Ilon|123|New York|Female,27|Python:80|Test:Lead,COE:Architect
Elaine|124|Vancouver|Female,57|Sales:89,HR:94|Sales:Lead
上传到数据
load data local inpath '/opt/stufile/employee_id.txt' overwrite into table employee_id;
创建分桶语句
create table employee_id_buckets
(
name string,
employee_id int,
work_place array<string>,
gender_age struct<gender:string,age:int>,
skills_score map<string,int>,
depart_title map<string,array<string>>
) clustered by (employee_id) into 2 buckets
row format delimited
fields terminated by '|'
collection items terminated by ','
map keys terminated by ':';clustered by (employee_id) into 2 buckets 含义是:把employee_id设置两个分桶
加载数据
insert overwrite table employee_id_buckets select * from employee_id;分桶抽样(Sampling)
随机抽样---整行数据
select *
from employee_id_buckets tablesample (bucket 1 out of 2 on rand());随机抽样---指定列
(使用分桶列更高效)
select *
from employee_id_buckets tablesample (bucket 1 out of 2 on employee_id);随机抽样---百分比
select *
from employee_id_buckets tablesample (10 percent);随机抽样---抽取行数
select *
from employee_id_buckets tablesample (10 rows);Hive视图(View)
视图概述
- 通过隐藏子查询、连接和函数来简化查询的逻辑结构
- 只保存定义,不存储数据
- 如果删除或更改基础表,则查询视图将失败
- 视图是只读的,不能插入或装载数据
应用场景
- 将特定的列提供给用户,保护数据隐私
- 用于查询语句复杂的场景
创建视图
支持 CTE, ORDER BY, LIMIT, JOIN等
create view view_name as select statement;
查看视图定义
show create table view_name;
删除视图
drop view_name;
更改视图属性
alter view view_name set tblproperties ('comment' = 'This is a view');
更改视图定义
alter view view_name as select statement;
Hive侧视图(Lateral View)
与表生成函数结合使用,将函数的输入和输出连接
OUTER关键字:即使output为空也会生成结果
select name, workplace, loc
from employee lateral view outer explode(split(null, ',')) a as loc;
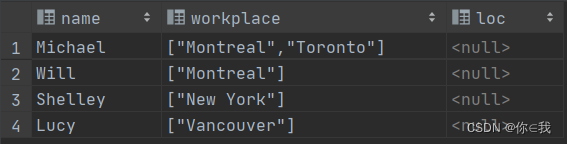
支持多层级
select name,wps,gender_age.gender, gender_age.age,skill,score,depart,title
from employee
lateral view explode(workplace) work_place as wps
lateral view explode(skills_score) sks as skill, score
lateral view explode(depart_title) ga as depart, title;