文章目录
- webpack5 构建性能的极致优化
- 一、使用最新版`webpack`
- 二、使用 `lazyCompilation`
- 三、约束 Loader 执行范围
- 四、使用 `noParse/externals` 跳过文件编译
- 五、开发模式禁用产物优化
- 六、最小化 `watch` 监控范围
- 七、跳过 TS 类型检查
- 八、优化 ESLint 性能
- 九、`source-map`简化
- 十、设置 `resolve` 缩小搜索范围
- 十一、`webpack`持久化缓存
- Webpack5 中的持久化缓存
- Webpack4 借助第三方库实现缓存
- 1.使用 `cache-loader`
- 2.使用`hard-source-webpack-plugin`
- 3.使用组件自带的缓存功能
- 十二、并行构建优化
- 使用 HappyPack
- 使用 Thread-loader
- 使用 Parallel-Webpack
- 并行压缩
- 十三、Dll 处理
- 打包 DLL 库
- 使用 DLL 库
- 应用性能优化
- 一、SplitChunks 产物优化
- 二、代码压缩
- 三、动态加载
- 四、合理配置hash利用HTTP 缓存优化
- 五、使用externals外置依赖
- 六、使用 Tree-Shaking 删除多余模块导出
- 七、使用 Scope Hoisting 合并模块
- 监控产物体积
- 总结
- webpack 的核心流程
- 打包功能的底层实现
webpack5 构建性能的极致优化
一、使用最新版webpack
例如:
- V3 到 V4 重写 Chunk 依赖逻辑,将原来的父子树状关系调整为
ChunkGroup表达的有序图关系,提升代码分包效率; - V4 到 V5 引入
cache功能,支持将模块、模块关系图、产物等核心要素持久化缓存到硬盘,减少重复工作。
其次,新版本通常还会引入更多性能工具,例如 Webpack5 的 cache(持久化缓存)、lazyCompilation(按需编译,下面展开介绍) 等。因此,开发者应该保持时刻更新 Webpack 以及 Node、NPM or Yarn 等基础环境,尽量使用最新稳定版本完成构建工作。
二、使用 lazyCompilation
Webpack 5.17.0 之后引入实验特性 lazyCompilation,用于实现 entry 或异步引用模块的按需编译,这是一个非常实用的新特性!
试想一个场景,你的项目中有一个入口(entry)文件及若干按路由划分的异步模块,Webpack 启动后会立即将这些入口与异步模块全部一次性构建好 —— 即使页面启动后实际上只是访问了其中一两个异步模块, 这些花在异步模块构建的时间着实是一种浪费!lazyCompilation 的出现正是为了解决这一问题。用法很简单:
// webpack.config.js
module.exports = {
// ...
experiments: {
lazyCompilation: true,
},
};
启动 lazyCompilation 后,代码中通过异步引用语句如 import('./xxx') 导入的模块(以及未被访问到的 entry)都不会被立即编译,而是直到页面正式请求该模块资源(例如切换到该路由)时才开始构建,效果与 Vite 相似,能够极大提升冷启速度。
此外,lazyCompilation 支持如下参数:
backend: 设置后端服务信息,一般保持默认值即可;entries:设置是否对entry启动按需编译特性;imports:设置是否对异步模块启动按需编译特性;test:支持正则表达式,用于声明对那些异步模块启动按需编译特性。
不过,lazyCompilation 还处于实验阶段,无法保证稳定性,接口形态也可能发生变更,建议只在开发环境使用。
三、约束 Loader 执行范围
Loader 组件用于将各式文件资源转换为可被 Webpack 理解、构建的标准 JavaScript 代码,正是这一特性支撑起 Webpack 强大的资源处理能力。不过,Loader 在执行内容转换的过程中可能需要比较密集的 CPU 运算,如 babel-loader、eslint-loader、vue-loader 等,需要反复执行代码到 AST,AST 到代码的转换。
因此开发者可以根据实际场景,使用 module.rules.include、module.rules.exclude 等配置项,限定 Loader 的执行范围 —— 通常可以排除 node_module 文件夹,如:
// webpack.config.js
module.exports = {
// ...
module: {
rules: [
{
test: /\.js$/,
exclude: /node_modules/,
use: ["babel-loader", "eslint-loader"],
},
],
},
};
配置 exclude: /node_modules/ 属性后,Webpack 在处理 node_modules 中的 js 文件时会直接跳过这个 rule 项,不会为这些文件执行 Loader 逻辑
四、使用 noParse/externals 跳过文件编译
有不少 NPM 库已经提前做好打包处理(文件合并、Polyfill、ESM 转 CJS 等),不需要二次编译就可以直接放在浏览器上运行,例如:
- Vue2 的
node_modules/vue/dist/vue.runtime.esm.js文件; - React 的
node_modules/react/umd/react.production.min.js文件; - Lodash 的
node_modules/lodash/lodash.js文件。
对我们来说,这些资源文件都是独立、内聚的代码片段,没必要重复做代码解析、依赖分析、转译等操作,此时可以使用 module.noParse 配置项跳过这些资源,例如:
// webpack.config.js
module.exports = {
//...
module: {
noParse: /lodash|react/,
},
};
提示:
noParse支持正则、函数、字符串、字符串数组等参数形式,具体可查阅官网。
配置后,所有匹配该正则的文件都会跳过前置的构建、分析动作,直接将内容合并进 Chunk,从而提升构建速度。不过,使用 noParse 时需要注意:
- 由于跳过了前置的 AST 分析动作,构建过程无法发现文件中可能存在的语法错误,需要到运行(或 Terser 做压缩)时才能发现问题,所以必须确保
noParse的文件内容正确性; - 由于跳过了依赖分析的过程,所以文件中,建议不要包含
import/export/require/define等模块导入导出语句 —— 换句话说,noParse文件不能存在对其它文件的依赖,除非运行环境支持这种模块化方案; - 由于跳过了内容分析过程,Webpack 无法标记该文件的导出值,也就无法实现 Tree-shaking。
综上,建议在使用 noParse 配置 NPM 库前,先检查 NPM 库默认导出的资源满足要求,例如 React@18 默认定义的导出文件是 index.js:
// react package.json
{
"name": "react",
// ...
"main": "index.js"
}
但 node_module/react/index.js 文件包含了模块导入语句 require:
// node_module/react/index.js
'use strict';
if (process.env.NODE_ENV === 'production') {
module.exports = require('./cjs/react.production.min.js');
} else {
module.exports = require('./cjs/react.development.js');
}
此时,真正有效的代码被包含在 react.development.js(或 react.production.min.js)中,但 Webpack 只会打包这段 index.js 内容,也就造成了产物中实际上并没有真正包含 React。针对这个问题,我们可以先找到适用的代码文件,然后用 resolve.alias 配置项重定向到该文件:
// webpack.config.js
module.exports = {
// ...
module: {
noParse: /react|lodash/,
},
resolve: {
alias: {
react: path.join(
__dirname,
process.env.NODE_ENV === "production"
? "./node_modules/react/cjs/react.production.min.js"
: "./node_modules/react/cjs/react.development.js"
),
},
},
};
提示:使用 externals 也能将部分依赖放到构建体系之外,实现与
noParse类似的效果,详情可查阅官网。
五、开发模式禁用产物优化
Webpack 提供了许多产物优化功能,例如:Tree-Shaking、SplitChunks、Minimizer 等,这些能力能够有效减少最终产物的尺寸,提升生产环境下的运行性能,但这些优化在开发环境中意义不大,反而会增加构建器的负担(都是性能大户)。
因此,开发模式下建议关闭这一类优化功能,具体措施:
- 确保
mode='development'或mode = 'none',关闭默认优化策略; optimization.minimize保持默认值或false,关闭代码压缩;optimization.concatenateModules保持默认值或false,关闭模块合并;optimization.splitChunks保持默认值或false,关闭代码分包;optimization.usedExports保持默认值或false,关闭 Tree-shaking 功能;- ……
最终,建议开发环境配置如:
module.exports = {
// ...
mode: "development",
optimization: {
removeAvailableModules: false,
removeEmptyChunks: false,
splitChunks: false,
minimize: false,
concatenateModules: false,
usedExports: false,
},
};
六、最小化 watch 监控范围
在 watch 模式下(通过 npx webpack --watch 命令启动),Webpack 会持续监听项目目录中所有代码文件,发生变化时执行 rebuild 命令。
不过,通常情况下前端项目中部分资源并不会频繁更新,例如 node_modules ,此时可以设置 watchOptions.ignored 属性忽略这些文件,例如:
// webpack.config.js
module.exports = {
//...
watchOptions: {
ignored: /node_modules/
},
};
七、跳过 TS 类型检查
JavaScript 本身是一门弱类型语言,这在多人协作项目中经常会引起一些不必要的类型错误,影响开发效率。随前端能力与职能范围的不断扩展,前端项目的复杂性与协作难度也在不断上升,TypeScript 所提供的静态类型检查能力也就被越来越多人所采纳。
不过,类型检查涉及 AST 解析、遍历以及其它非常消耗 CPU 的操作,会给工程化流程带来比较大的性能负担,因此我们可以选择关闭 ts-loader 的类型检查功能:
module.exports = {
// ...
module: {
rules: [{
test: /\.ts$/,
use: [
{
loader: 'ts-loader',
options: {
// 设置为“仅编译”,关闭类型检查
transpileOnly: true
}
}
],
}],
}
};
有同学可能会问:“没有类型检查,那还用 TypeScript 干嘛?”,很简单,我们可以:
- 可以借助编辑器的 TypeScript 插件实现代码检查(推荐);
- 使用
fork-ts-checker-webpack-plugin插件将类型检查能力剥离到 子进程 执行,例如:
const ForkTsCheckerWebpackPlugin = require('fork-ts-checker-webpack-plugin');
module.exports = {
// ...
module: {
rules: [{
test: /\.ts$/,
use: [
{
loader: 'ts-loader',
options: {
transpileOnly: true
}
}
],
}, ],
},
plugins:[
// fork 出子进程,专门用于执行类型检查
new ForkTsCheckerWebpackPlugin()
]
};
这样,既可以获得 Typescript 静态类型检查能力,又能提升整体编译速度。
八、优化 ESLint 性能
ESLint 能帮助我们极低成本发现代码风格问题,维护代码质量,但若使用不当 —— 例如在开发模式下使用 eslint-loader 实现实时代码检查,会带来比较高昂且不必要的性能成本,我们可以选择其它更聪明的方式接入 ESLint。
例如,使用新版本组件 eslint-webpack-plugin 替代旧版 eslint-loader,两者差异在于,eslint-webpack-plugin 在模块构建完毕(compilation.hooks.succeedModule 钩子)后执行检查,不会阻断文件加载流程,性能更优,用法:
- 安装依赖:
yarn add -D eslint-webpack-plugin
- 添加插件:
const ESLintPlugin = require('eslint-webpack-plugin');
module.exports = {
// ...
plugins: [new ESLintPlugin(options)],
// ...
};
或者,可以选择在特定条件、场景下执行 ESLint,减少对构建流程的影响,如:
-
使用编辑器插件完成 ESLint 检查、错误提示、自动 Fix,如 VS Code 的 dbaeumer.vscode-eslint 插件(推荐);
-
使用
husky,仅在代码提交前执行 ESLint 代码检查(推荐); -
仅在
production构建中使用 ESLint,能够有效提高开发阶段的构建效率。
九、source-map简化
source-map 是一种将经过编译、压缩、混淆的代码映射回源码的技术,它能够帮助开发者迅速定位到更有意义、更结构化的源码中,方便调试。不过,source-map 操作本身也有很大构建性能开销,建议读者根据实际场景慎重选择最合适的 source-map 方案。
针对 source-map 功能,Webpack 提供了 devtool 选项,可以配置 eval、source-map、cheap-source-map 等值,不考虑其它因素的情况下,最佳实践:
开发环境 适合使用:
- eval:速度极快,但只能看到原始文件结构,看不到打包前的代码内容(不需要调试源码使用)
- eval-cheap-source-map:速度比较快,可以看到打包前的代码内容,但看不到 loader 处理之前的源码
- eval-cheap-module-source-map:速度比较快,可以看到 loader 处理之前的源码,不过定位不到列级别(推荐)
- eval-source-map:初次编译较慢,但定位精度最高
生产环境 适合使用:
- source-map:信息最完整,但安全性最低,外部用户可轻易获取到压缩、混淆之前的源码
- hidden-source-map:信息较完整,安全性较低,外部用户获取到 .map 文件地址时依然可以拿到源码
十、设置 resolve 缩小搜索范围
Webpack 默认提供了一套同时兼容 CMD、AMD、ESM 等模块化方案的资源搜索规则 —— enhanced-resolve,它能将各种模块导入语句准确定位到模块对应的物理资源路径。例如:
import 'lodash'这一类引入 NPM 包的语句会被enhanced-resolve定位到对应包体文件路径node_modules/lodash/index.js;import './a'这类不带文件后缀名的语句,则可能被定位到./a.js文件;import '@/a'这类化名路径的引用,则可能被定位到$PROJECT_ROOT/src/a.js文件。
需要注意,这类增强资源搜索体验的特性背后涉及许多 IO 操作,本身可能引起较大的性能消耗,开发者可根据实际情况调整 resolve 配置,缩小资源搜索范围,包括:
1. resolve.extensions 配置:
例如,当模块导入语句未携带文件后缀时,如 import './a' ,Webpack 会遍历 resolve.extensions 项定义的后缀名列表,尝试在 './a' 路径追加后缀名,搜索对应物理文件。
在 Webpack5 中,resolve.extensions 默认值为 ['.js', '.json', '.wasm'] ,这意味着 Webpack 在针对不带后缀名的引入语句时,可能需要执行三次判断逻辑才能完成文件搜索,针对这种情况,可行的优化措施包括:
-
修改
resolve.extensions配置项,减少匹配次数; -
代码中尽量补齐文件后缀名;
-
设置
resolve.enforceExtension = true,强制要求开发者提供明确的模块后缀名,不过这种做法侵入性太强,不太推荐。
2. resolve.modules 配置:
类似于 Node 模块搜索逻辑,当 Webpack 遇到 import 'lodash' 这样的 npm 包导入语句时,会先尝试在当前项目 node_modules 目录搜索资源,如果找不到,则按目录层级尝试逐级向上查找 node_modules 目录,如果依然找不到,则最终尝试在全局 node_modules 中搜索。
在一个依赖管理良好的系统中,我们通常会尽量将 NPM 包安装在有限层级内,因此 Webpack 这一逐层查找的逻辑大多数情况下实用性并不高,开发者可以通过修改 resolve.modules 配置项,主动关闭逐层搜索功能,例如:
// webpack.config.js
const path = require('path');
module.exports = {
//...
resolve: {
modules: [path.resolve(__dirname, 'node_modules')],
},
};
3. resolve.mainFiles 配置:
与 resolve.extensions 类似,resolve.mainFiles 配置项用于定义文件夹默认文件名,例如对于 import './dir' 请求,假设 resolve.mainFiles = ['index', 'home'] ,Webpack 会按依次测试 ./dir/index 与 ./dir/home 文件是否存在。
因此,实际项目中应控制 resolve.mainFiles 数组数量,减少匹配次数。
十一、webpack持久化缓存
Webpack5 中的持久化缓存
持久化缓存 算得上是 Webpack 5 最令人振奋的特性之一,它能够将首次构建的过程与结果数据持久化保存到本地文件系统,在下次执行构建时跳过解析、链接、编译等一系列非常消耗性能的操作,直接复用上次的 Module/ModuleGraph/Chunk 对象数据,迅速构建出最终产物。
配置 babel-loader、eslint-loader 后,在我机器上测试,未使用 cache 特性时构建耗时大约在 11000ms 到 18000ms 之间;启动 cache 功能后,第二次构建耗时降低到 500ms 到 800ms 之间,两者相差接近 50 倍!
而这接近 50 倍的性能提升,仅仅需要在 Webpack5 中设置 cache.type = 'filesystem' 即可开启:
module.exports = {
//...
cache: {
type: 'filesystem'
},
//...
};
Webpack4 借助第三方库实现缓存
Webpack5 的持久化缓存用法简单,效果出众,但可惜在Webpack4 及之前版本原生还没有相关实现,只能借助一些第三方组件实现类似效果,包括:
- 使用
[cache-loader](https://www.npmjs.com/package/cache-loader); - 使用
[hard-source-webpack-plugin](https://github.com/mzgoddard/hard-source-webpack-plugin); - 使用 Loader(如
babel-loader、eslint-loader))自带的缓存能力。
1.使用 cache-loader
先从 cache-loader 说起,cache-loader 能够将 Loader 处理结果保存到硬盘,下次运行时若文件内容没有发生变化则直接返回缓存结果,用法:
- 安装依赖:
yarn add -D cache
- 修改配置,注意必须将
cache-loader放在loader数组首位,例如:
module.exports = {
// ...
module: {
rules: [{
test: /\.js$/,
use: ['cache-loader', 'babel-loader', 'eslint-loader']
}]
},
// ...
};
cache-loader 只缓存了 Loader 执行结果,缓存范围与精度不如 Webpack5 内置的缓存功能,所以性能效果相对较低
2.使用hard-source-webpack-plugin
hard-source-webpack-plugin 也是一种实现缓存功能的第三方组件,与 cache-loader 不同的是,它并不仅仅缓存了 Loader 运行结果,还保存了 Webpack 构建过程中许多中间数据,包括:模块、模块关系、模块 Resolve 结果、Chunks、Assets 等,效果几乎与 Webpack5 自带的 Cache 对齐。用法:
- 安装依赖:
yarn add -D hard-source-webpack-plugin
- 添加配置:
const HardSourceWebpackPlugin = require("hard-source-webpack-plugin");
module.exports = {
// ...
plugins: [
new HardSourceWebpackPlugin(),
],
};
首次运行时,hard-source-webpack-plugin 会在缓存文件夹 node_module/.cache 写入一系列日志文件
下次运行时,hard-source-webpack-plugin 插件会复用缓存中记录的数据,跳过一系列构建步骤,从而提升构建性能。
hard-source-webpack-plugin 插件的底层逻辑与 Webpack5 的持久化缓存很相似,但优化效果稍微差一些
3.使用组件自带的缓存功能
除了上面介绍的持久化缓存、cache-loader、hard-source-webpack-plugin 方案外,我们还可以使用 Webpack 组件自带的缓存能力提升特定领域的编译性能,这一类组件有:
- babel-loader;
- eslint-loader:旧版本 ESLint Webpack 组件,官方推荐使用 eslint-webpack-plugin 代替;
- eslint-webpack-plugin;
- stylelint-webpack-plugin。
例如使用 babel-loader 时,只需设置 cacheDirectory = true 即可开启缓存功能,例如:
module.exports = {
// ...
module: {
rules: [{
test: /\.m?js$/,
loader: 'babel-loader',
options: {
cacheDirectory: true,
},
}]
},
// ...
};
以 Three.js 为例,开启缓存后生产环境构建耗时从 3500ms 降低到 1600ms;开发环境构建从 6400ms 降低到 4500ms,性能提升约 30% ~ 50% 。
默认情况下,缓存内容会被保存到 node_modules/.cache/babel-loader 目录,你也可以通过 cacheDirectory = 'dir' 属性设置缓存路径。
此外,ESLint 与 Stylelint 这一类耗时较长的 Lint 工具也贴心地提供了相应的缓存能力,只需设置 cache = true 即可开启,如:
// webpack.config.js
module.exports = {
plugins: [
new ESLintPlugin({ cache: true }),
new StylelintPlugin({ files: '**/*.css', cache: true }),
],
};
依然以 Three.js 为例,开启 ESLint 缓存后生产环境构建耗时从 6400ms 降低到 1400ms;开发环境构建从 7000ms 降低到 2100ms,性能提升达到 70% ~ 80%。
十二、并行构建优化
受限于 Node.js 的单线程架构,原生 Webpack 对所有资源文件做的所有解析、转译、合并操作本质上都是在同一个线程内串行执行,CPU 利用率极低,因此,理所当然地,社区出现了一些以多进程方式运行 Webpack,或 Webpack 构建过程某部分工作的方案(从而提升单位时间利用率),例如:
- HappyPack:多进程方式运行资源加载(Loader)逻辑;
- Thread-loader:Webpack 官方出品,同样以多进程方式运行资源加载逻辑;
- Parallel-Webpack:多进程方式运行多个 Webpack 构建实例;
- TerserWebpackPlugin:支持多进程方式执行代码压缩、uglify 功能。
这些方案的核心设计都很类似:针对某种计算任务创建子进程,之后将运行所需参数通过 IPC 传递到子进程并启动计算操作,计算完毕后子进程再将结果通过 IPC 传递回主进程,寄宿在主进程的组件实例,再将结果提交给 Webpack。
使用 HappyPack
HappyPack 能够将耗时的文件加载(Loader)操作拆散到多个子进程中并发执行,子进程执行完毕后再将结果合并回传到 Webpack 进程,从而提升构建性能。不过,HappyPack 的用法稍微有点难以理解,需要同时:
- 使用
happypack/loader代替原本的 Loader 序列; - 使用
HappyPack插件注入代理执行 Loader 序列的逻辑。
基本用法:
- 安装依赖:
yarn add -D happypack
- 将原有
loader配置替换为happypack/loader,如:
module.exports = {
// ...
module: {
rules: [
{
test: /\.js$/,
use: "happypack/loader",
// 原始配置如:
// use: [
// {
// loader: 'babel-loader',
// options: {
// presets: ['@babel/preset-env']
// }
// },
// 'eslint-loader'
// ]
},
],
},
};
- 创建
happypack插件实例,并将原有 loader 配置迁移到插件中,完整配置:
const HappyPack = require("happypack");
module.exports = {
// ...
module: {
rules: [
{
test: /\.js$/,
use: "happypack/loader",
// 原始配置如:
// use: [
// {
// loader: 'babel-loader',
// options: {
// presets: ['@babel/preset-env']
// }
// },
// 'eslint-loader'
// ]
},
],
},
plugins: [
new HappyPack({
// 将原本定义在 `module.rules.use` 中的 Loader 配置迁移到 HappyPack 实例中
loaders: [
{
loader: "babel-loader",
option: {
presets: ["@babel/preset-env"],
},
},
"eslint-loader",
],
}),
],
};
配置完毕后,再次启动 npx webpack 命令,即可使用 HappyPack 的多进程能力提升构建性能。
上述示例仅演示了使用 HappyPack 加载单一资源类型的场景,实践中我们还可以创建多个 HappyPack 插件实例,来加载多种资源类型 —— 只需要用 id 参数做好 Loader 与 Plugin 实例的关联即可,例如:
const HappyPack = require('happypack');
module.exports = {
// ...
module: {
rules: [{
test: /\.js?$/,
// 使用 `id` 参数标识该 Loader 对应的 HappyPack 插件示例
use: 'happypack/loader?id=js'
},
{
test: /\.less$/,
use: 'happypack/loader?id=styles'
},
]
},
plugins: [
new HappyPack({
// 注意这里要明确提供 id 属性
id: 'js',
loaders: ['babel-loader', 'eslint-loader']
}),
new HappyPack({
id: 'styles',
loaders: ['style-loader', 'css-loader', 'less-loader']
})
]
};
这里的重点是:
js、less资源都使用happypack/loader作为唯一加载器,并分别赋予id = 'js' | 'styles'参数;- 创建了两个
HappyPack插件实例并分别配置id属性,以及用于处理 js 与 css 的loaders数组; - 启动后,
happypack/loader与HappyPack插件实例将通过id值产生关联,以此实现对不同资源执行不同 Loader 序列。
上面这种多实例模式虽然能应对多种类型资源的加载需求,但默认情况下,HappyPack 插件实例 自行管理 自身所消费的进程,需要导致频繁创建、销毁进程实例 —— 这是非常昂贵的操作,反而会带来新的性能损耗。
为此,HappyPack 提供了一套简单易用的共享进程池接口,只需要创建 HappyPack.ThreadPool 对象,并通过 size 参数限定进程总量,之后将该例配置到各个 HappyPack 插件的 threadPool 属性上即可,例如:
const os = require('os')
const HappyPack = require('happypack');
const happyThreadPool = HappyPack.ThreadPool({
// 设置进程池大小
size: os.cpus().length - 1
});
module.exports = {
// ...
plugins: [
new HappyPack({
id: 'js',
// 设置共享进程池
threadPool: happyThreadPool,
loaders: ['babel-loader', 'eslint-loader']
}),
new HappyPack({
id: 'styles',
threadPool: happyThreadPool,
loaders: ['style-loader', 'css-loader', 'less-loader']
})
]
};
使用 HappyPack.ThreadPool 接口后,HappyPack 会预先创建好一组工作进程,所有插件实例的资源转译任务会通过内置的 HappyThread 对象转发到空闲进程做处理,避免频繁创建、销毁进程。
HappyPack 虽然确实能有效提升 Webpack 的打包构建速度,但它有一些明显的缺点:
- 作者已经明确表示不会继续维护,扩展性与稳定性缺乏保障,随着 Webpack 本身的发展迭代,可以预见总有一天 HappyPack 无法完全兼容 Webpack;
- HappyPack 底层以自己的方式重新实现了加载器逻辑,源码与使用方法都不如 Thread-loader 清爽简单,而且会导致一些意想不到的兼容性问题,如
awesome-typescript-loader;- HappyPack 主要作用于文件加载阶段,并不会影响后续的产物生成、合并、优化等功能,性能收益有限。
使用 Thread-loader
Thread-loader 与 HappyPack 功能类似,都是以多进程方式加载文件的 Webpack 组件,两者主要区别:
- Thread-loader 由 Webpack 官方提供,目前还处于持续迭代维护状态,理论上更可靠;
- Thread-loader 只提供了一个 Loader 组件,用法简单很多;
- HappyPack 启动后会创建一套 Mock 上下文环境 —— 包含
emitFile等接口,并传递给 Loader,因此对大多数 Loader 来说,运行在 HappyPack 与运行在 Webpack 原生环境相比没有太大差异;但 Thread-loader 并不具备这一特性,所以要求 Loader 内不能调用特定上下文接口,兼容性较差。
说一千道一万,先来看看基本用法:
- 安装依赖:
yarn add -D thread-loader
- 将 Thread-loader 放在
use数组首位,确保最先运行,如:
module.exports = {
module: {
rules: [
{
test: /\.js$/,
use: ["thread-loader", "babel-loader", "eslint-loader"],
},
],
},
};
启动后,Thread-loader 会在加载文件时创建新的进程,在子进程中使用 loader-runner 库运行 thread-loader 之后的 Loader 组件,执行完毕后再将结果回传到 Webpack 主进程,从而实现性能更佳的文件加载转译效果。
以 Three.js 为例,使用 Thread-loader 前,构建耗时大约为 11000ms 到 18000ms 之间,开启后耗时降低到 8000ms 左右,提升约37%。
此外,Thread-loader 还提供了一系列用于控制并发逻辑的配置项,包括:
workers:子进程总数,默认值为require('os').cpus() - 1;workerParallelJobs:单个进程中并发执行的任务数;poolTimeout:子进程如果一直保持空闲状态,超过这个时间后会被关闭;poolRespawn:是否允许在子进程关闭后重新创建新的子进程,一般设置为false即可;workerNodeArgs:用于设置启动子进程时,额外附加的参数。
使用方法跟其它 Loader 一样,都是通过 use.options 属性传递,如:
module.exports = {
module: {
rules: [
{
test: /\.js$/,
use: [
{
loader: "thread-loader",
options: {
workers: 2,
workerParallelJobs: 50,
// ...
},
},
"babel-loader",
"eslint-loader",
],
},
],
},
};
不过,Thread-loader 也同样面临着频繁的子进程创建、销毁所带来的性能问题,为此,Thread-loader 提供了 warmup 接口用于前置创建若干工作子进程,降低构建时延,用法:
const threadLoader = require("thread-loader");
threadLoader.warmup(
{
// 可传入上述 thread-loader 参数
workers: 2,
workerParallelJobs: 50,
},
[
// 子进程中需要预加载的 node 模块
"babel-loader",
"babel-preset-es2015",
"sass-loader",
]
);
执行效果与 HappyPack.ThreadPool 相似,此处不再赘述。
与 HappyPack 相比,Thread-loader 有两个突出的优点,一是产自 Webpack 官方团队,后续有长期维护计划,稳定性有保障;二是用法更简单。但它不可避免的也存在一些问题:
- 在 Thread-loader 中运行的 Loader 不能调用
emitAsset等接口,这会导致style-loader这一类加载器无法正常工作,解决方案是将这类组件放置在thread-loader之前,如['style-loader', 'thread-loader', 'css-loader'];- Loader 中不能获取
compilation、compiler等实例对象,也无法获取 Webpack 配置。这会导致一些 Loader 无法与 Thread-loader 共同使用,大家需要仔细加以甄别、测试。
使用 Parallel-Webpack
Thread-loader、HappyPack 这类组件所提供的并行能力都仅作用于文件加载过程,对后续 AST 解析、依赖收集、打包、优化代码等过程均没有影响,理论收益还是比较有限的。对此,社区还提供了另一种并行度更高,以多个独立进程运行 Webpack 实例的方案 —— Parallel-Webpack,基本用法:
- 安装依赖:
yarn add -D parallel-webpack
- 在
webpack.config.js配置文件中导出多个 Webpack 配置对象,如:
module.exports = [{
entry: 'pageA.js',
output: {
path: './dist',
filename: 'pageA.js'
}
}, {
entry: 'pageB.js',
output: {
path: './dist',
filename: 'pageB.js'
}
}];
- 执行
npx parallel-webpack命令。
Parallel-Webpack 会为配置文件中导出的每个 Webpack 配置对象启动一个独立的构建进程,从而实现并行编译的效果。底层原理很简单,基本上就是在 Webpack 上套了个壳:
- 根据传入的配置项数量,调用
worker-farm创建复数个工作进程; - 工作进程内调用 Webpack 执行构建;
- 工作进程执行完毕后,调用
node-ipc向主进程发送结束信号。
这种方式在需要同时执行多份配置的编译时特别有效,但若配置文件本身只是导出了单个配置对象则意义不大。
为了更好地支持多种配置的编译,Parallel-Webpack 还提供了 createVariants 函数,用于根据给定变量组合,生成多份 Webpack 配置对象,如:
const createVariants = require('parallel-webpack').createVariants
const webpack = require('webpack')
const baseOptions = {
entry: './index.js'
}
// 配置变量组合
// 属性名为 webpack 配置属性;属性值为可选的变量
// 下述变量组合将最终产生 2*2*4 = 16 种形态的配置对象
const variants = {
minified: [true, false],
debug: [true, false],
target: ['commonjs2', 'var', 'umd', 'amd']
}
function createConfig (options) {
const plugins = [
new webpack.DefinePlugin({
DEBUG: JSON.stringify(JSON.parse(options.debug))
})
]
return {
output: {
path: './dist/',
filename: 'MyLib.' +
options.target +
(options.minified ? '.min' : '') +
(options.debug ? '.debug' : '') +
'.js'
},
plugins: plugins
}
}
module.exports = createVariants(baseOptions, variants, createConfig)
上述示例使用 createVariants 函数,根据 variants 变量搭配出 16 种不同的 minified、debug、target 组合,最终生成如下产物:
[WEBPACK] Building 16 targets in parallel
[WEBPACK] Started building MyLib.umd.js
[WEBPACK] Started building MyLib.umd.min.js
[WEBPACK] Started building MyLib.umd.debug.js
[WEBPACK] Started building MyLib.umd.min.debug.js
[WEBPACK] Started building MyLib.amd.js
[WEBPACK] Started building MyLib.amd.min.js
[WEBPACK] Started building MyLib.amd.debug.js
[WEBPACK] Started building MyLib.amd.min.debug.js
[WEBPACK] Started building MyLib.commonjs2.js
[WEBPACK] Started building MyLib.commonjs2.min.js
[WEBPACK] Started building MyLib.commonjs2.debug.js
[WEBPACK] Started building MyLib.commonjs2.min.debug.js
[WEBPACK] Started building MyLib.var.js
[WEBPACK] Started building MyLib.var.min.js
[WEBPACK] Started building MyLib.var.debug.js
[WEBPACK] Started building MyLib.var.min.debug.js
虽然,parallel-webpack 相对于 Thread-loader、HappyPack 有更高的并行度,但进程实例之间并没有做任何形式的通讯,这可能导致相同的工作在不同进程 —— 或者说不同 CPU 核上被重复执行。
例如需要对同一份代码同时打包出压缩和非压缩版本时,在 parallel-webpack 方案下,前置的资源加载、依赖解析、AST 分析等操作会被重复执行,仅仅最终阶段生成代码时有所差异。
这种技术实现,对单 entry 的项目没有任何收益,只会徒增进程创建成本;但特别适合 MPA 等多 entry 场景,或者需要同时编译出 esm、umd、amd 等多种产物形态的类库场景。
并行压缩
Webpack4 默认使用 Uglify-js 实现代码压缩,Webpack5 之后则升级为 Terser —— 一种性能与兼容性更好的 JavaScript 代码压缩混淆工具,两种组件都原生实现了多进程并行压缩能力。
以 Terser 为例,TerserWebpackPlugin 插件默认已开启并行压缩,开发者也可以通过 parallel 参数(默认值为 require('os').cpus() - 1)设置具体的并发进程数量,如:
const TerserPlugin = require("terser-webpack-plugin");
module.exports = {
optimization: {
minimize: true,
minimizer: [new TerserPlugin({
parallel: 2 // number | boolean
})],
},
};
上述配置即可设定最大并行进程数为 2。此外,Webpack4 所使用的 uglifyjs-webpack-plugin 也提供了类似的功能,用法与 Terser 相同,此处不再赘述。
对于vue-cli5和webpack5中,设置mode为production即可实现并行压缩
十三、Dll 处理
当 webpack 打包引入第三方模块的时候,每一次引入,它都会去从 node_modules 中去分析,这样肯定会影响 webpack 打包的一些性能,如果我们能在第一次打包的时候就生成一个第三方打包文件,在接下去的过程中应用第三方文件的时候,就直接使用这个文件,这样就会提高 webpack 的打包速度。
使用 DllPlugin 进行分包,使用 DllReferencePlugin(索引链接) 对manifest.json 引用,让一些基本不会改动的代码先打包成静态资源,避免反复编译浪费时间。
打包 DLL 库
const path = require('path');
const webpack = require('webpack');
const TerserPlugin = require('terser-webpack-plugin');
module.exports = {
entry: {
react: ["echarts"]
},
output: {
path: path.resolve(__dirname, "./dll"),
filename: "dll_[name].js",
library: 'dll_[name]'
},
optimization: {
minimizer: [
new TerserPlugin({
extractComments: false
})
]
},
plugins: [
new webpack.DllPlugin({
name: "dll_[name]",
path: path.resolve(__dirname, "./dll/[name].manifest.json")
})
]
}
使用 DLL 库
- 第一步:通过 DllReferencePlugin 插件告知要使用的 DLL 库;
- 第二步:通过 HtmlWebpackExternalsPlugin 插件,将我们打包的 DLL 库引入到 Html 模块中
plugins: [
new webpack.DllReferencePlugin({
context: resolveApp("./"),
manifest: resolveApp("./dll/echarts.manifest.json")
}),
new HtmlWebpackExternalsPlugin ({
externals: [
{
module: 'echart',
entry: resolveApp('./dll/dll_echarts.js'),
global: 'echarts',
},
],
})
],
应用性能优化
一、SplitChunks 产物优化
Webpack 默认会将尽可能多的模块代码打包在一起,优点是能减少最终页面的 HTTP 请求数,但缺点也很明显:
- 页面初始代码包过大,影响首屏渲染性能;
- 无法有效应用浏览器缓存,特别对于 NPM 包这类变动较少的代码,业务代码哪怕改了一行都会导致 NPM 包缓存失效。
为此,Webpack 提供了 SplitChunksPlugin 插件,专门用于根据产物包的体积、引用次数等做分包优化,规避上述问题,特别适合生产环境使用。
SplitChunksPlugin 支持的配置项:
minChunks:用于设置引用阈值,被引用次数超过该阈值的 Module 才会进行分包处理;maxInitialRequest/maxAsyncRequests:用于限制 Initial Chunk(或 Async Chunk) 最大并行请求数,本质上是在限制最终产生的分包数量;minSize: 超过这个尺寸的 Chunk 才会正式被分包;maxSize: 超过这个尺寸的 Chunk 会尝试继续做分包;maxAsyncSize: 与maxSize功能类似,但只对异步引入的模块生效;maxInitialSize: 与maxSize类似,但只对entry配置的入口模块生效;enforceSizeThreshold: 超过这个尺寸的 Chunk 会被强制分包,忽略上述其它 size 限制;cacheGroups:用于设置缓存组规则,为不同类型的资源设置更有针对性的分包策略。
结合这些特性,业界已经总结了许多惯用的最佳分包策略,包括:
- 针对
node_modules资源:- 可以将
node_modules模块打包成单独文件(通过cacheGroups实现),防止业务代码的变更影响 NPM 包缓存,同时建议通过maxSize设定阈值,防止 vendor 包体过大; - 更激进的,如果生产环境已经部署 HTTP2/3 一类高性能网络协议,甚至可以考虑将每一个 NPM 包都打包成单独文件,具体实现可查看小册示例;
- 可以将
- 针对业务代码:
- 设置
common分组,通过minChunks配置项将使用率较高的资源合并为 Common 资源; - 首屏用不上的代码,尽量以异步方式引入;
- 设置
optimization.runtimeChunk为true,将运行时代码拆分为独立资源。
- 设置
不过,现实世界很复杂,同样的方法放在不同场景可能会有完全相反的效果,建议你根据自己项目的实际情况(代码量、基础设施环境),择优选用上述实践。
二、代码压缩
-
使用 TerserWebpackPlugin 压缩 JS
-
使用 CssMinimizerWebpackPlugin 压缩 CSS
-
使用 HtmlMinifierTerser 压缩 HTML
三、动态加载
Webpack 默认会将同一个 Entry 下的所有模块全部打包成一个产物文件 —— 包括那些与页面 关键渲染路径 无关的代码,这会导致页面初始化时需要花费多余时间去下载这部分暂时用不上的代码,影响首屏渲染性能,例如:
import someBigMethod from "./someBigMethod";
document.getElementById("someButton").addEventListener("click", () => {
someBigMethod();
});
逻辑上,直到点击页面的 someButton 按钮时才会调用 someBigMethod 方法,因此这部分代码没必要出现在首屏资源列表中,此时我们可以使用 Webpack 的动态加载功能将该模块更改为异步导入,修改上述代码:
document.getElementById("someButton").addEventListener("click", async () => {
// 使用 `import("module")` 动态加载模块
const someBigMethod = await import("./someBigMethod");
someBigMethod();
});
此时,重新构建将产生额外的产物文件 src_someBigMethod_js.js,这个文件直到执行 import 语句时 —— 也就是上例 someButton 被点击时才被加载到浏览器,也就不会影响到关键渲染路径了。
动态加载是 Webpack 内置能力之一,我们不需要做任何额外配置就可以通过动态导入语句(import、require.ensure)轻易实现。但请 注意,这一特性有时候反而会带来一些新的性能问题:一是过度使用会使产物变得过度细碎,产物文件过多,运行时 HTTP 通讯次数也会变多,在 HTTP 1.x 环境下这可能反而会降低网络性能,得不偿失;二是使用时 Webpack 需要在客户端注入一大段用于支持动态加载特性的 Runtime:
段代码即使经过压缩也高达 2.5KB 左右,如果动态导入的代码量少于这段 Runtime 代码的体积,那就完全是一笔赔本买卖了。
因此,请务必慎重,多数情况下我们没必要为小模块使用动态加载能力!目前社区比较常见的用法是配合 SPA 的前端路由能力实现页面级别的动态加载,例如在 Vue 中:
import { createRouter, createWebHashHistory } from "vue-router";
const Home = () => import("./Home.vue");
const Foo = () => import(/* webpackChunkName: "sub-pages" */ "./Foo.vue");
const Bar = () => import(/* webpackChunkName: "sub-pages" */ "./Bar.vue");
// 基础页面
const routes = [
{ path: "/bar", name: "Bar", component: Bar },
{ path: "/foo", name: "Foo", component: Foo },
{ path: "/", name: "Home", component: Home },
];
const router = createRouter({
history: createWebHashHistory(),
routes,
});
export default router;
示例中,Home/Foo/Bar 三个组件均通过 import() 语句动态导入,这使得仅当页面切换到相应路由时才会加载对应组件代码。另外,Foo 与 Bar 组件的导入语句比较特殊:
import(/* webpackChunkName: "sub-pages" */ "./Bar.vue");
webpackChunkName 用于指定该异步模块的 Chunk 名称,相同 Chunk 名称的模块最终会打包在一起,这一特性能帮助开发者将一些关联度较高,或比较细碎的模块合并到同一个产物文件,能够用于管理最终产物数量。
四、合理配置hash利用HTTP 缓存优化
注意,Webpack 只是一个工程化构建工具,没有能力决定应用最终在网络分发时的缓存规则,但我们可以调整产物文件的名称(通过 Hash)与内容(通过 Code Splitting),使其更适配 HTTP 持久化缓存策略。
提示:Hash 是一种将任意长度的消息压缩到某一固定长度的消息摘要的函数,不同明文计算出的摘要值不同,所以常常被用作内容唯一标识。
Hash 占位符,包括:
[fullhash]:整个项目的内容 Hash 值,项目中任意模块变化都会产生新的fullhash;[chunkhash]:产物对应 Chunk 的 Hash,Chunk 中任意模块变化都会产生新的chunkhash;[contenthash]:产物内容 Hash 值,仅当产物内容发生变化时才会产生新的contenthash,因此实用性较高。
之后,使用下述配置:
module.exports = {
// ...
output: {
filename: "[name]-[contenthash].js",
path: path.resolve(__dirname, "dist"),
}
};
五、使用externals外置依赖
externals 的主要作用是将部分模块排除在 Webpack 打包系统之外,例如:
module.exports = {
// ...
externals: {
lodash: "_",
},
};
使用上述配置后,Webpack 会 预设 运行环境中已经内置 Lodash 库 —— 无论是通过 CDN 还是其它方式注入,所以不需要再将这些模块打包到产物中
注意,使用
externals时必须确保这些外置依赖代码已经被正确注入到上下文环境中虽然结果上看浏览器还是得消耗这部分流量,但结合 CDN 系统特性:
一是能够就近获取资源,缩短网络通讯链路;二是能够将资源分发任务前置到节点服务器,减轻原服务器 QPS 负担;三是用户访问不同站点能共享同一份 CDN 资源副本。所以网络性能效果往往会比重复打包好很多。
六、使用 Tree-Shaking 删除多余模块导出
Tree-Shaking 较早前由 Rich Harris 在 Rollup 中率先实现,Webpack 自 2.0 版本开始接入,是一种基于 ES Module 规范的 Dead Code Elimination 技术,它会在运行过程中静态分析模块之间的导入导出,判断哪些模块导出值没有被其它模块使用 —— 相当于模块层面的 Dead Code,并将其删除。
在 Webpack 中,启动 Tree Shaking 功能必须同时满足两个条件:
- 一、配置
optimization.usedExports为true,标记模块导入导出列表; - 二、启动代码优化功能,可以通过如下方式实现:
- 配置
mode = production - 配置
optimization.minimize = true - 提供
optimization.minimizer数组
- 配置
例如:
// webpack.config.js
module.exports = {
mode: "production",
optimization: {
usedExports: true,
},
};
之后,Webpack 会对所有使用 ESM 方案的模块启动 Tree-Shaking。
七、使用 Scope Hoisting 合并模块
默认情况下 Webpack 会将模块打包成一个个单独的函数,例如:
// common.js
export default "common";
// index.js
import common from './common';
console.log(common);
经过 Webpack 打包后会生成:
"./src/common.js":
((__unused_webpack_module, __webpack_exports__, __webpack_require__) => {
const __WEBPACK_DEFAULT_EXPORT__ = ("common");
__webpack_require__.d(__webpack_exports__, {
/* harmony export */
"default": () => (__WEBPACK_DEFAULT_EXPORT__)
/* harmony export */
});
}),
"./src/index.js":
((__unused_webpack_module, __webpack_exports__, __webpack_require__) => {
var _common__WEBPACK_IMPORTED_MODULE_0__ = __webpack_require__( /*! ./common */ "./src/common.js");
console.log(_common__WEBPACK_IMPORTED_MODULE_0__)
})
这种处理方式需要将每一个模块都包裹进一段相似的函数模板代码中,好看是好看,但浪费网络流量啊。为此,Webpack 提供了 Scope Hoisting 功能,用于 将符合条件的多个模块合并到同一个函数空间 中,从而减少产物体积,优化性能。例如上述示例经过 Scope Hoisting 优化后,生成代码:
((__unused_webpack_module, __webpack_exports__, __webpack_require__) => {
;// CONCATENATED MODULE: ./src/common.js
/* harmony default export */ const common = ("common");
;// CONCATENATED MODULE: ./src/index.js
console.log(common);
})
Webpack 提供了三种开启 Scope Hoisting 的方法:
- 使用
mode = 'production'开启生产模式; - 使用
optimization.concatenateModules配置项; - 直接使用
ModuleConcatenationPlugin插件。
const ModuleConcatenationPlugin = require('webpack/lib/optimize/ModuleConcatenationPlugin');
module.exports = {
// 方法1: 将 `mode` 设置为 production,即可开启
mode: "production",
// 方法2: 将 `optimization.concatenateModules` 设置为 true
optimization: {
concatenateModules: true,
usedExports: true,
providedExports: true,
},
// 方法3: 直接使用 `ModuleConcatenationPlugin` 插件
plugins: [new ModuleConcatenationPlugin()]
};
三种方法最终都会调用 ModuleConcatenationPlugin 完成模块分析与合并操作。
与 Tree-Shaking 类似,Scope Hoisting 底层基于 ES Module 方案的 静态特性,推断模块之间的依赖关系,并进一步判断模块与模块能否合并,因此在以下场景下会失效:
- 非 ESM 模块
遇到 AMD、CMD 一类模块时,由于导入导出内容的动态性,Webpack 无法确保模块合并后不会产生意料之外的副作用,因此会关闭 Scope Hoisting 功能。这一问题在导入 NPM 包尤其常见,许多框架都会自行打包后再上传到 NPM,并且默认导出的是兼容性更佳的 CommonJS 包,因而无法使用 Scope Hoisting 功能,此时可通过 mainFileds 属性尝试引入框架的 ESM 版本:
module.exports = {
resolve: {
// 优先使用 jsnext:main 中指向的 ES6 模块化语法的文件
mainFields: ['jsnext:main', 'browser', 'main']
},
};
- 模块被多个 Chunk 引用
如果一个模块被多个 Chunk 同时引用,为避免重复打包,Scope Hoisting 同样会失效,例如:
// common.js
export default "common"
// async.js
import common from './common';
// index.js
import common from './common';
import("./async");
示例中,入口 index.js 与异步模块 async.js 同时依赖 common.js 文件,common.js 无法被合并入任一 Chunk,而是作为生成为单独的作用域,最终打包结果:
"./src/common.js":
(() => {
var __WEBPACK_DEFAULT_EXPORT__ = ("common");
}),
"./src/index.js":
(() => {
var _common__WEBPACK_IMPORTED_MODULE_0__ = __webpack_require__( /*! ./common */ "./src/common.js");
__webpack_require__.e( /*! import() */ "src_async_js").then(__webpack_require__.bind(__webpack_require__, /*! ./async */ "./src/async.js"));
}),
监控产物体积
综合最近几章讨论的 Code Splitting、压缩、缓存优化、Tree-Shaking 等技术,不难看出所谓的应用性能优化几乎都与网络有关,这是因为现代计算机网络环境非常复杂、不稳定,虽然有堪比本地磁盘吞吐速度的 5G 网络,但也还存在大量低速 2G、3G 网络用户,整体而言通过网络实现异地数据交换依然是一种相对低效的 IO 手段,有可能成为 Web 应用执行链条中最大的性能瓶颈。
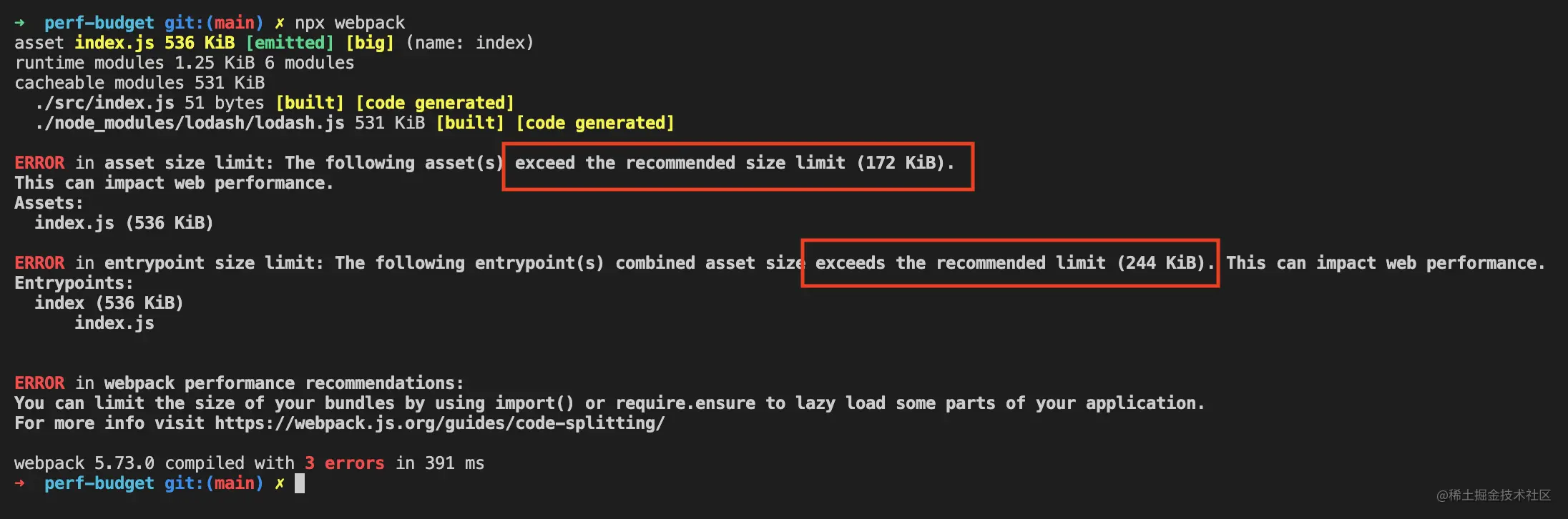
因此,站在生产者角度我们有必要尽可能优化代码在网络上分发的效率,用尽可能少的网络流量交付应用功能。所幸 Webpack 专门为此提供了一套 性能监控方案,当构建生成的产物体积超过阈值时抛出异常警告,以此帮助我们时刻关注资源体积,避免因项目迭代增长带来过大的网络传输,用法:
module.exports = {
// ...
performance: {
// 设置所有产物体积阈值
maxAssetSize: 172 * 1024,
// 设置 entry 产物体积阈值
maxEntrypointSize: 244 * 1024,
// 报错方式,支持 `error` | `warning` | false
hints: "error",
// 过滤需要监控的文件类型
assetFilter: function (assetFilename) {
return assetFilename.endsWith(".js");
},
},
};
若此时产物体积超过 172KB,则报错:
提示:这里的报错不会阻断构建功能, 依然能正常打包出应用产物。
那么我们应该设置多大的阈值呢?这取决于项目具体场景,不过,一个比较好的 经验法则 是确保 关键路径 资源体积始终小于 170KB,超过这个体积就应该使用上面介绍的若干方法做好裁剪优化。
总结
压缩、Tree-Shaking、Scope Hoisting 都在减少产物体积;Code Splitting、外置依赖、[hash] 则有助于提升 HTTP 缓存效率;动态加载则能够确保关键路径最小资源依赖。种种措施各自从不同角度努力优化应用代码在网络上的分发效率,毕竟网络通讯有时候真的很贵!
webpack 的核心流程
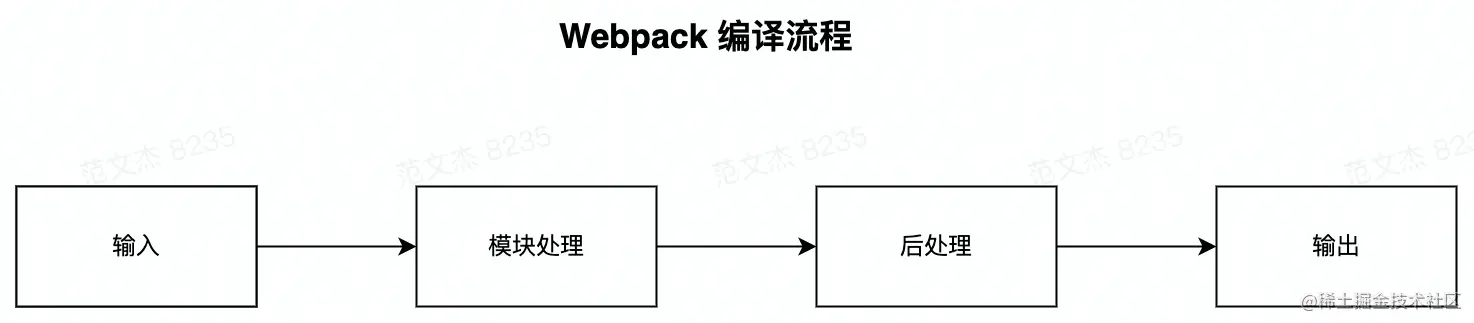
- 输入:从文件系统读入代码文件;
- 模块递归处理:调用 Loader 转译 Module 内容,并将结果转换为 AST,从中分析出模块依赖关系,进一步递归调用模块处理过程,直到所有依赖文件都处理完毕;
- 后处理:所有模块递归处理完毕后开始执行后处理,包括模块合并、注入运行时、产物优化等,最终输出 Chunk 集合;
- 输出:将 Chunk 写出到外部文件系统;
从上述打包流程角度,Webpack 配置项大体上可分为两类:
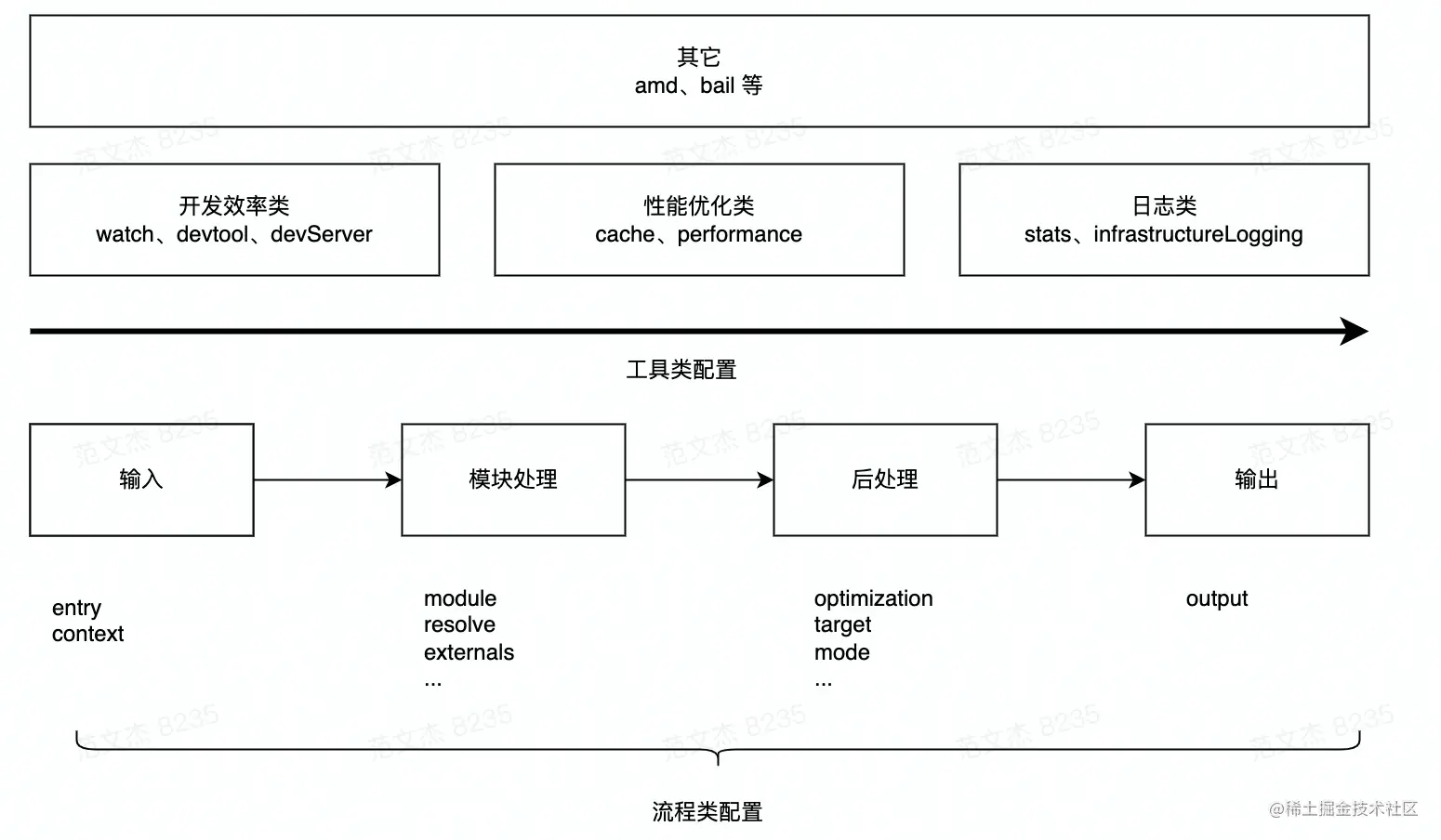
- 流程类:作用于打包流程某个或若干个环节,直接影响编译打包效果的配置项
- 工具类:打包主流程之外,提供更多工程化工具的配置项
流程类配置项综述
与打包流程强相关的配置项有:
- 输入输出:
entry:用于定义项目入口文件,Webpack 会从这些入口文件开始按图索骥找出所有项目文件;context:项目执行上下文路径;output:配置产物输出路径、名称等;
- 模块处理:
resolve:用于配置模块路径解析规则,可用于帮助 Webpack 更精确、高效地找到指定模块module:用于配置模块加载规则,例如针对什么类型的资源需要使用哪些 Loader 进行处理externals:用于声明外部资源,Webpack 会直接忽略这部分资源,跳过这些资源的解析、打包操作
- 后处理:
optimization:用于控制如何优化产物包体积,内置 Dead Code Elimination、Scope Hoisting、代码混淆、代码压缩等功能target:用于配置编译产物的目标运行环境,支持 web、node、electron 等值,不同值最终产物会有所差异mode:编译模式短语,支持development、production等值,可以理解为一种声明环境的短语
这里的重点是,Webpack 首先需要根据输入配置(entry/context) 找到项目入口文件;之后根据按模块处理(module/resolve/externals 等) 所配置的规则逐一处理模块文件,处理过程包括转译、依赖分析等;模块处理完毕后,最后再根据后处理相关配置项(optimization/target 等)合并模块资源、注入运行时依赖、优化产物结构等。
这些配置项与打包流程强相关,建议学习时多关注它们对主流程的影响,例如 entry 决定了项目入口,而 output 则决定产物最终往哪里输出;resolve 决定了怎么找到模块,而 module 决定了如何解读模块内容,等等。
工具类配置项综述
除了核心的打包功能之外,Webpack 还提供了一系列用于提升研发效率的工具,大体上可划分为:
- 开发效率类:
watch:用于配置持续监听文件变化,持续构建devtool:用于配置产物 Sourcemap 生成规则devServer:用于配置与 HMR 强相关的开发服务器功能
- 性能优化类:
cache:Webpack 5 之后,该项用于控制如何缓存编译过程信息与编译结果performance:用于配置当产物大小超过阈值时,如何通知开发者
- 日志类:
stats:用于精确地控制编译过程的日志内容,在做比较细致的性能调试时非常有用infrastructureLogging:用于控制日志输出方式,例如可以通过该配置将日志输出到磁盘文件
- 等等
逻辑上,每一个工具类配置都在主流程之外提供额外的工程化能力,例如 devtool 用于配置产物 Sourcemap 生成规则,与 Sourcemap 强相关;devServer 用于配置与 HMR 相关的开发服务器功能;watch 用于实现持续监听、构建。
综上,虽然 Webpack 提供了上百项复杂配置,但大体上都可以归类为流程类配置或工具类配置,对于流程类配置应该多关注它们对编译主流程的影响;而工具类则更加内聚,基本上一种配置项解决一种工程化问题。
打包功能的底层实现
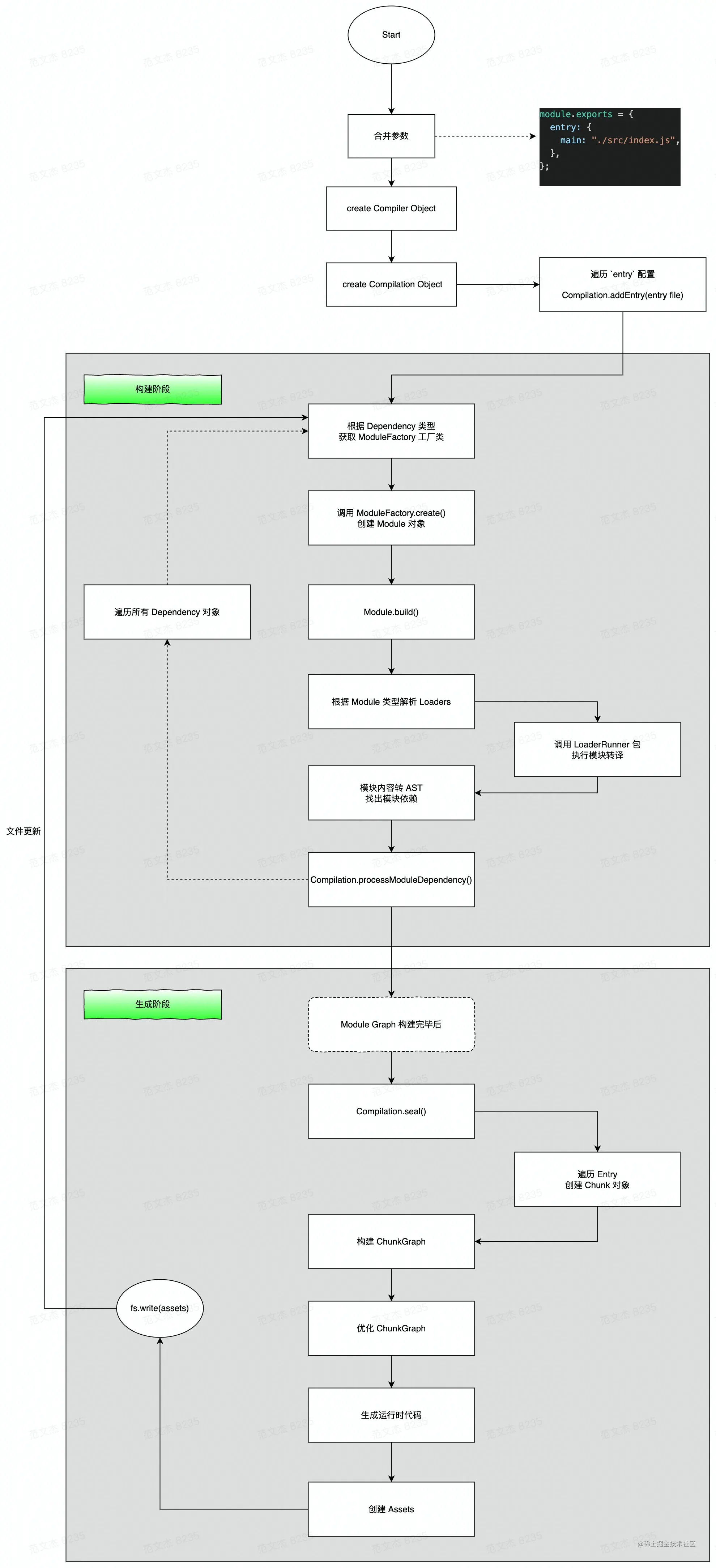
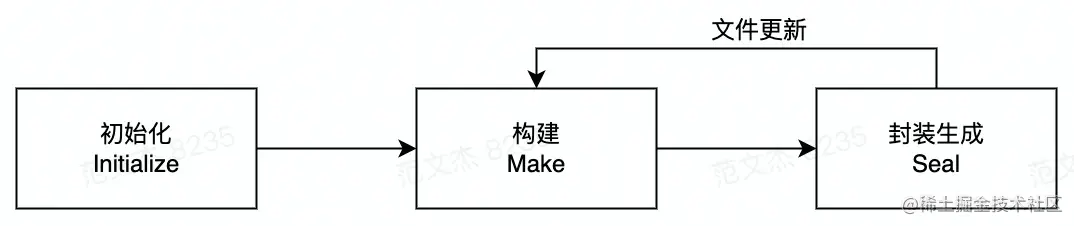
为了方便理解,我把上述过程划分为三个阶段:
- 初始化阶段:修整配置参数,创建 Compiler、Compilation 等基础对象,并初始化插件及若干内置工厂、工具类,并最终根据
entry配置,找到所有入口模块; - 构建阶段:从
entry文件开始,调用loader将模块转译为 JavaScript 代码,调用 Acorn 将代码转换为 AST 结构,遍历 AST 从中找出该模块依赖的模块;之后 递归 遍历所有依赖模块,找出依赖的依赖,直至遍历所有项目资源后,构建出完整的 模块依赖关系图; - 生成阶段:根据
entry配置,将模块组装为一个个 Chunk 对象,之后调用一系列 Template 工厂类翻译 Chunk 代码并封装为 Asset,最后写出到文件系统。
提示:单次构建过程自上而下按顺序执行,如果启动了
watch,则构建完成后不会退出 Webpack 进程,而是持续监听文件内容,发生变化时回到「构建」阶段重新执行构建。
三个阶段环环相扣,「初始化」的重点是根据用户配置设置好构建环境;「构建阶段」则重在解读文件输入与文件依赖关系;最后在「生成阶段」按规则组织、包装模块,并翻译为适合能够直接运行的产物包。三者结合,实现 Webpack 最核心的打包能力,其它功能特性也几乎都是在此基础上,通过 Hook 介入、修改不同阶段的对象状态、流程逻辑等方式实现。